Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Untuk membangun aplikasi klien yang tangguh dan sukses, sangat penting untuk memahami failover di Azure Managed Redisservice. Kegagalan bisa menjadi bagian dari operasi manajemen yang direncanakan, atau mungkin disebabkan oleh kegagalan perangkat keras atau jaringan yang tidak direncanakan. Penggunaan umum failover cache datang ketika layanan manajemen menambal biner Azure Managed Redis.
Dalam artikel ini, Anda akan menemukan informasi berikut:
- Apa itu kegagalan?
- Bagaimana kegagalan terjadi selama penambalan.
- Cara untuk membangun aplikasi klien yang tangguh.
Apa itu kegagalan?
Mari kita mulai dengan gambaran umum failover untuk Azure Managed Redis.
Ringkasan singkat arsitektur tembolokan
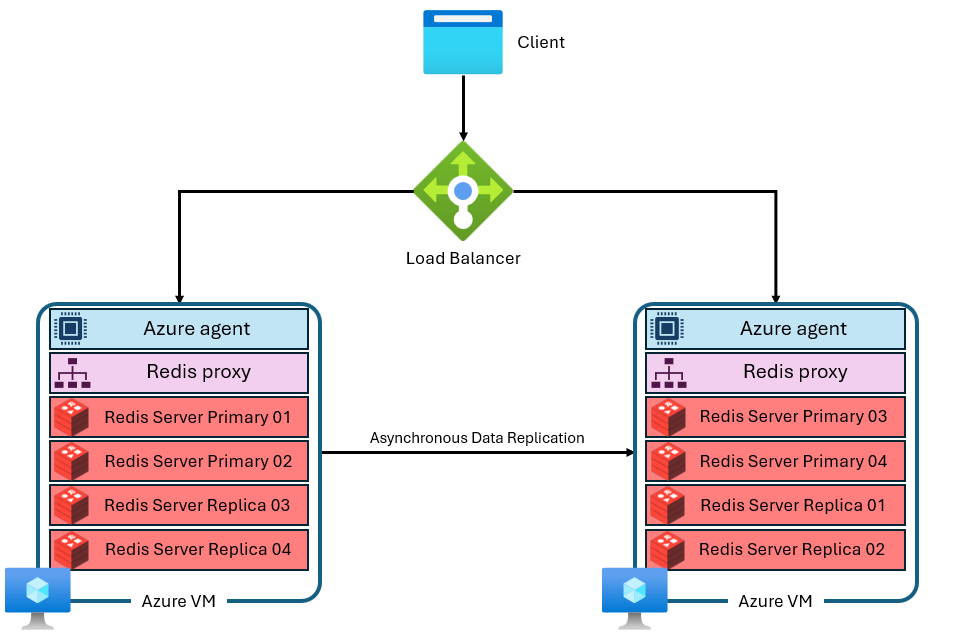
Cache tersusun dari beberapa mesin virtual dengan alamat IP privat yang terpisah. Setiap mesin virtual (atau "node") menjalankan beberapa proses server Redis (disebut "partisi") secara paralel. Beberapa pecahan memungkinkan pemanfaatan vCPU yang lebih efisien pada setiap komputer virtual dan performa yang lebih tinggi. Tidak semua shard Redis utama berada di VM/node yang sama. Sebaliknya, pecahan primer dan replika didistribusikan di kedua simpul. Karena pecahan utama menggunakan lebih banyak sumber daya CPU daripada pecahan replika, pendekatan ini memungkinkan lebih banyak pecahan utama dijalankan secara paralel. Setiap simpul memiliki proses proksi berkinerja tinggi untuk mengelola pecahan, menangani manajemen koneksi, dan memicu penyembuhan diri. Satu pecahan mungkin tidak berfungsi sementara yang lain tetap tersedia.
Detail mendalam Arsitektur Azure Managed Redis dapat ditemukan di sini.
Penjelasan tentang kegagalan
Failover terjadi ketika satu atau beberapa pecahan replika mempromosikan diri mereka untuk menjadi pecahan utama, dan pecahan utama lama menutup koneksi yang ada. Failover mungkin direncanakan atau tidak terencana.
Kegagalan yang direncanakan terjadi dalam dua waktu yang berbeda:
- Pembaruan sistem, misalnya penambalan Redis atau peningkatan OS.
- Operasi manajemen, misalnya penskalaan dan reboot.
Karena simpul-simpul menerima pemberitahuan sebelumnya tentang pembaruan, mereka dapat secara kooperatif bertukar peran dan dengan cepat memperbarui penyeimbang beban sehubungan dengan perubahan tersebut. Kegagalan yang direncanakan biasanya selesai dalam waktu kurang dari 1 detik.
Kegagalan yang tidak direncanakan mungkin terjadi karena kegagalan perangkat keras, kegagalan jaringan, atau pemadaman tak terduga lainnya ke satu atau beberapa simpul dalam kluster. Pecahan replika pada simpul yang tersisa akan mempromosikan diri mereka ke primer untuk mempertahankan ketersediaan, tetapi prosesnya membutuhkan waktu lebih lama. Shard replika harus terlebih dahulu mendeteksi shard utamanya tidak tersedia sebelum dapat memulai proses failover. Pecahan replika juga harus memverifikasi kegagalan yang tidak direncanakan ini bukan sementara atau lokal, untuk menghindari failover yang tidak perlu. Penundaan dalam deteksi ini berarti bahwa kegagalan yang tidak direncanakan biasanya selesai dalam 10 hingga 15 detik.
Bagaimana penambalan terjadi?
Layanan Azure Managed Redis secara teratur memperbarui cache Anda dengan fitur dan perbaikan platform terbaru. Untuk menambal tembolokan, layanan mengikuti langkah-langkah berikut:
- Layanan ini membuat VM terbaru untuk menggantikan semua VM yang sedang di-patch.
- Kemudian mempromosikan salah satu VM baru sebagai pemimpin kluster.
- Satu per satu, semua simpul yang di-patch dihapus dari kluster. Setiap pecahan pada VM ini akan diturunkan dan dimigrasikan ke salah satu VM baru.
- Akhirnya, semua VM yang diganti akan dihapus.
Setiap pecahan cache berkluster di-patch secara terpisah dan tidak menutup koneksi ke shard lain.
Nota
Beberapa cache di wilayah yang sama mungkin di-patch secara bersamaan. Jika ini memengaruhi aplikasi Anda, konfigurasikan jadwal pemeliharaan sedih sehingga setiap cache di-patch pada waktu yang berbeda.
Karena sinkronisasi data penuh terjadi sebelum proses berulang, kehilangan data tidak mungkin terjadi untuk cache Anda. Anda dapat mencegah hilangnya data dengan mengekspor data dan mengaktifkan persistensi.
Beban tembolokan tambahan
Setiap kali failover terjadi, cache perlu mereplikasi data dari satu simpul ke simpul lainnya. Replikasi ini menyebabkan sejumlah peningkatan beban pada memori server dan CPU. Jika instans tembolokan sudah sangat berbeban, aplikasi klien mungkin mengalami peningkatan latensi. Dalam kasus ekstrem, aplikasi klien mungkin menerima pengecualian waktu habis.
Bagaimana failover memengaruhi aplikasi klien saya?
Aplikasi klien dapat menerima beberapa kesalahan dari instans Azure Managed Redis mereka. Jumlah kesalahan yang dilihat oleh aplikasi klien tergantung seberapa banyak operasi yang tertunda pada koneksi tersebut saat kegagalan terjadi. Setiap koneksi yang dirutekan melalui simpul yang menutup koneksinya melihat kesalahan.
Banyak pustaka klien dapat melaporkan berbagai jenis kesalahan saat koneksi putus, termasuk:
- Pengecualian batas waktu habis
- Pengecualian koneksi
- Pengecualian soket
Jumlah dan jenis pengecualian tergantung letak permintaan pada jalur kode saat cache menutup koneksinya. Misalnya, operasi yang mengirimkan permintaan tetapi belum menerima respons ketika kegagalan terjadi mungkin mendapatkan pengecualian waktu habis. Permintaan baru pada objek koneksi tertutup akan menerima pengecualian koneksi hingga koneksi ulang berhasil tersambung.
Sebagian besar pustaka klien berusaha terkoneksi ulang ke tembolokan jika dikonfigurasi untuk melakukannya. Namun, bug yang tidak terduga kadang-kadang dapat menempatkan objek pustaka ke dalam kondisi yang tidak dapat dipulihkan. Jika kesalahan bertahan lebih lama dari durasi waktu yang telah dikonfigurasi sebelumnya, objek koneksi harus dibuat ulang. Dalam Microsoft.NET dan bahasa berorientasi objek lainnya, menciptakan koneksi kembali tanpa memulai ulang aplikasi dapat dilakukan dengan menggunakan pola ForceReconnect.
Apa saja pembaruan yang disertakan dalam pemeliharaan?
Pemeliharaan mencakup pembaruan ini:
- Pembaruan Redis Server: Setiap pembaruan atau patch biner server Redis.
- Pembaruan komputer virtual (VM): Pembaruan apa pun dari komputer virtual yang menghosting layanan Redis. Pembaruan VM termasuk patching komponen perangkat lunak di lingkungan hosting untuk meningkatkan komponen jaringan atau menonaktifkan.
Apakah pemeliharaan muncul dalam kesehatan layanan di portal Azure sebelum patch?
Tidak, pemeliharaan tidak muncul di bawah kesehatan layanan di portal atau tempat lain.
Perubahan konfigurasi-jaringan klien
Perubahan konfigurasi jaringan sisi klien tertentu dapat memicu Tidak ada kesalahan koneksi yang tersedia . Perubahan tersebut bisa mencakup:
- Menukar alamat IP virtual aplikasi klien antara slot penahapan dan slot produksi.
- Menskalakan ukuran atau jumlah instans aplikasi Anda.
Perubahan tersebut dapat menyebabkan masalah konektivitas yang biasanya berlangsung kurang dari satu menit. Aplikasi klien Anda mungkin kehilangan koneksinya ke sumber daya jaringan eksternal lainnya, tetapi juga ke layanan Azure Managed Redis.
Membangun ketahanan
Anda tidak dapat menghindari failover sepenuhnya. Sebagai gantinya, tulis aplikasi klien Anda agar tahan terhadap jeda koneksi dan permintaan yang gagal. Sebagian besar pustaka klien secara otomatis tersambung kembali ke titik akhir cache, tetapi hanya beberapa yang berusaha mencoba lagi permintaan yang gagal. Tergantung skenario aplikasi, mungkin masuk akal untuk menggunakan logika coba lagi dengan backoff.
Bagaimana cara menjadikan aplikasi saya tangguh?
Lihat pola desain ini untuk membangun klien yang tangguh, terutama pemutus sirkuit dan pola percobaan ulang:
- Pola keandalan - Pola Desain Cloud
- Panduan mencoba kembali untuk layanan Azure - Praktik terbaik untuk aplikasi cloud
- Menerapkan percobaan ulang dengan backoff eksponensial