Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() SQL Server
SQL Server
Saat meningkatkan instans SQL Server yang menghosting grup ketersediaan Always On (AG) ke versi SQL Server baru, ke paket layanan atau pembaruan kumulatif SQL Server baru, atau saat menginstal paket layanan atau pembaruan kumulatif Windows baru, Anda dapat mengurangi waktu henti replika utama menjadi hanya satu kali failover manual dengan melakukan peningkatan bergulir (atau dua kali failover manual jika kembali ke kondisi semula).
Selama proses peningkatan, replika sekunder tidak akan tersedia untuk failover atau untuk operasi baca-saja, dan setelah peningkatan, mungkin perlu beberapa waktu bagi replika sekunder untuk mengejar ketinggalan dengan simpul replika utama tergantung pada volume aktivitas pada simpul replika utama (jadi mengharapkan lalu lintas jaringan yang tinggi).
Perlu diketahui juga bahwa setelah failover awal ke replika sekunder yang menjalankan versi SQL Server yang lebih baru, database di AG tersebut akan berjalan melalui proses peningkatan untuk membawanya ke versi terbaru. Selama waktu ini, tidak akan ada replika yang dapat dibaca untuk salah satu database ini. Waktu henti setelah failover awal tergantung pada jumlah database di AG. Jika Anda berencana untuk gagal kembali ke primer asli, langkah ini tidak akan diulang saat Anda gagal kembali.
Catatan
Artikel ini membatasi diskusi untuk peningkatan SQL Server itu sendiri. Ini tidak mencakup peningkatan sistem operasi yang berisi Kluster Failover Windows Server (WSFC). Meningkatkan sistem operasi Windows yang menghosting kluster failover tidak didukung untuk sistem operasi sebelum Windows Server 2012 R2. Untuk meningkatkan node kluster yang berjalan di Windows Server 2012 R2, lihat Peningkatan Bergulir Sistem Operasi Kluster.
Prasyarat
Sebelum memulai, tinjau informasi penting berikut:
Peningkatan versi dan edisi yang didukung: Verifikasi bahwa Anda dapat meningkatkan ke versi terbaru SQL Server dari versi sistem operasi Windows dan versi SQL Server Anda. Misalnya, jika Anda meningkatkan langsung dari instans SQL Server 2005, tingkat kompatibilitas database Anda akan ditingkatkan.
Pilih metode peningkatan mesin database: Untuk meningkatkan dalam urutan yang benar, pilih metode dan langkah-langkah peningkatan yang sesuai berdasarkan ulasan Anda tentang peningkatan versi dan edisi yang didukung, dan juga berdasarkan komponen lain yang diinstal di lingkungan Anda.
Merencanakan dan menguji rencana peningkatan mesin database: Tinjau catatan rilis dan masalah peningkatan yang diketahui, daftar periksa pra-tingkat, dan kembangkan dan uji rencana peningkatan.
Persyaratan perangkat keras dan perangkat lunak untuk menginstal SQL Server: Tinjau persyaratan perangkat lunak untuk menginstal SQL Server. Jika perangkat lunak tambahan diperlukan, instal pada setiap simpul sebelum Anda memulai proses peningkatan untuk meminimalkan waktu henti.
Periksa apakah pengambilan atau replikasi data perubahan digunakan untuk database AG apa pun: Jika ada database di AG yang diaktifkan untuk mengubah pengambilan data (CDC), selesaikan instruksi ini.
Catatan
- Menggabungkan versi instans SQL Server dalam Grup Ketersediaan (Availability Group) yang sama tidak didukung di luar proses peningkatan bergulir dan seharusnya tidak dibiarkan dalam kondisi tersebut untuk jangka waktu lama, karena peningkatan harus dilakukan dengan cepat. Opsi lain untuk meningkatkan SQL Server 2016 (13.x) dan versi yang lebih baru adalah melalui penggunaan grup ketersediaan terdistribusi.
- Menggunakan fitur WindowsCluster-Aware Update (CAU) untuk memperbarui grup ketersediaan AlwaysOn tidak didukung.
Peningkatan bergulir dasar untuk grup ketersediaan
Amati panduan berikut saat melakukan peningkatan atau pembaruan server untuk meminimalkan waktu henti dan kehilangan data untuk AG Anda:
Sebelum Anda memulai peningkatan bergulir:
Lakukan praktik failover manual pada setidaknya salah satu instans replika synchronous-commit Anda.
Lindungi data Anda dengan melakukan pencadangan database lengkap pada setiap database ketersediaan.
Jalankan
DBCC CHECKDBpada setiap database ketersediaan.
Selalu tingkatkan instans replika sekunder jarak jauh terlebih dahulu, lalu instans replika sekunder lokal berikutnya, dan instans replika utama terakhir.
Pencadangan tidak dapat terjadi pada database yang sedang dalam proses dimutakhirkan. Sebelum meningkatkan replika sekunder, konfigurasikan preferensi pencadangan otomatis untuk menjalankan cadangan hanya pada replika utama. Selama peningkatan versi, tidak ada replika yang dapat dibaca atau tersedia untuk cadangan. Selama peningkatan nonversi, Anda dapat mengonfigurasi pencadangan otomatis untuk dijalankan pada replika sekunder sebelum meningkatkan replika utama.
Selama peningkatan versi, sekunder yang dapat dibaca menjadi tidak dapat diakses setelah sekunder yang dapat dibaca ditingkatkan dan sebelum replika utama dialihkan ke sekunder yang telah ditingkatkan, atau replika utama ditingkatkan.
Untuk mencegah AG dari failover yang tidak diinginkan selama proses peningkatan, hapus failover ketersediaan dari semua replika penerapan sinkron sebelum Anda mulai.
Jangan tingkatkan instans replika utama sebelum mengalihkan AG ke instans yang ditingkatkan dengan replika sekunder terlebih dahulu. Jika tidak, aplikasi klien mungkin mengalami waktu henti yang diperpanjang selama peningkatan pada instans replika utama.
Selalu lakukan failover AG ke instans replika sekunder dengan komit sinkron. Jika Anda melakukan failover ke instans replika sekunder dengan komitmen asinkron, database akan rentan terhadap kehilangan data, dan pergerakan data akan secara otomatis ditangguhkan hingga Anda melanjutkan pergerakan data itu secara manual.
Jangan tingkatkan instans replika utama sebelum meningkatkan atau memperbarui instans replika sekunder lainnya. Replika utama yang ditingkatkan tidak dapat lagi mengirim log ke replika sekunder yang instans SQL Server-nya belum ditingkatkan ke versi yang sama. Ketika pergerakan data ke replika sekunder ditangguhkan, tidak ada failover otomatis yang dapat terjadi untuk replika tersebut, dan database ketersediaan Anda rentan terhadap kehilangan data. Ini juga berlaku selama peningkatan bergulir di mana Anda melakukan failover secara manual dari primer lama ke primer baru. Dengan demikian, setelah meningkatkan primer lama, Anda mungkin perlu melanjutkan sinkronisasi.
Sebelum melakukan failover pada AG, verifikasi bahwa status sinkronisasi target failover adalah
SYNCHRONIZED.Peringatan
Menginstal instans baru atau versi baru SQL Server ke server yang memiliki versi SQL Server yang lebih lama yang diinstal mungkin secara tidak sengaja menyebabkan pemadaman untuk grup ketersediaan apa pun yang dihosting oleh versi SQL Server yang lebih lama. Ini karena selama penginstalan instans atau versi SQL Server, modul ketersediaan tinggi SQL Server (
RHS.EXE) akan ditingkatkan. Ini menyebabkan gangguan sementara dari grup ketersediaan Anda yang sudah ada dalam peran utama pada server. Oleh karena itu, kami sangat menyarankan Anda melakukan salah satu hal berikut saat menginstal versi SQL Server yang lebih baru ke sistem yang sudah menghosting versi SQL Server yang lebih lama dengan grup ketersediaan:Instal versi baru SQL Server selama jendela pemeliharaan.
Alihkan peran utama grup ketersediaan ke replika sekunder agar tidak berfungsi sebagai utama selama penginstalan instans SQL Server baru.
Proses peningkatan bergulir
Dalam praktiknya, proses yang tepat tergantung pada faktor-faktor seperti topologi penyebaran AG Anda dan mode penerapan setiap replika. Tetapi dalam skenario paling sederhana, peningkatan bergulir adalah proses multitahap yang dalam bentuk paling sederhana melibatkan langkah-langkah berikut:
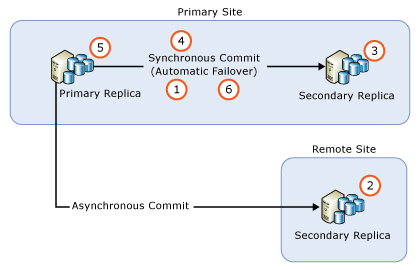
- Menghapus failover otomatis pada semua replika komit sinkron
- Tingkatkan semua instans replika sekunder dengan komitmen asinkron.
- Tingkatkan semua instans replika sekunder penerapan sinkron jarak jauh.
- Tingkatkan semua instans replika sekunder penerapan sinkron lokal.
- Alihkan secara manual AG ke replika sekunder komit sinkron lokal (yang baru saja ditingkatkan).
- Tingkatkan atau perbarui instans replika lokal yang sebelumnya menghosting replika utama.
- Konfigurasikan mitra failover otomatis sesuai keinginan.
Jika perlu, Anda dapat melakukan failover manual tambahan untuk mengembalikan AG ke konfigurasi aslinya.
Meningkatkan replika penerapan sinkron dan membuatnya offline tidak akan menunda transaksi pada primer. Setelah replika sekunder terputus, transaksi dilakukan pada primer tanpa menunggu log mengeras pada replika sekunder.
Jika REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT diatur ke atau 12, replika Utama mungkin tidak tersedia untuk baca/tulis saat jumlah replika sekunder sinkronisasi yang sesuai tidak tersedia selama proses pembaruan.
Ketika Anda melakukan peningkatan langsung replika sekunder ke versi SQL Server yang lebih baru, database di dalam grup ketersediaan tetap berada dalam status Sinkronisasi / Dalam pemulihan atau Disinkronkan / Dalam Pemulihan hingga grup ketersediaan dialihkan secara manual, yang menyelesaikan pemulihan dan meningkatkan database. Replika utama yang ditingkatkan tidak dapat lagi mengirim log ke replika sekunder versi lebih rendah dan pergerakan data berhenti, tidak ada failover otomatis yang dapat terjadi untuk replika tersebut, dan database ketersediaan Anda rentan terhadap kehilangan data. Setelah memutakhirkan primer lama, Anda mungkin perlu melanjutkan sinkronisasi. Sebaiknya perbarui semua replika sekunder sebelum melakukan proses failover ke yang memiliki versi baru. Dengan begitu, Anda memiliki opsi untuk melakukan failover setelah database ditingkatkan ke format baru.
AG dengan satu replika sekunder jarak jauh
Jika Anda telah menyebarkan AG hanya untuk pemulihan bencana, Anda mungkin perlu mengalihkan AG ke replika sekunder penerapan asinkron. Gambar berikut mengilustrasikan konfigurasi seperti itu:
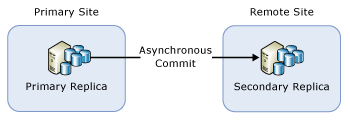
Dalam situasi ini, Anda harus melakukan failover AG ke replika sekunder komit asinkron selama upgrade bertahap. Untuk mencegah kehilangan data, ubah mode penerapan menjadi penerapan sinkron dan tunggu replika sekunder disinkronkan sebelum Anda melakukan failover pada AG. Oleh karena itu, proses peningkatan bergulir mungkin terlihat sebagai berikut:
- Mutakhirkan instans replika sekunder di situs jarak jauh.
- Ubah mode penerapan menjadi penerapan sinkron.
- Tunggu hingga status sinkronisasi adalah
SYNCHRONIZED. - Pindahkan Availability Group (AG) ke replika sekunder di lokasi jarak jauh.
- Mutakhirkan atau perbarui instans replika lokal (situs utama).
- Alihkan kembali AG ke situs utama.
- Ubah mode penerapan menjadi penerapan asinkron.
Karena mode penerapan sinkron bukan pengaturan yang direkomendasikan untuk sinkronisasi data ke situs jarak jauh, aplikasi klien mungkin melihat peningkatan latensi database segera setelah pengaturan berubah. Selain itu, melakukan alih fungsi (failover) menyebabkan semua pesan log yang belum terkonfirmasi dibuang. Jumlah pesan log yang dibuang dapat signifikan karena tingginya latensi jaringan antara kedua situs, menyebabkan klien mengalami volume kegagalan transaksi yang tinggi. Anda dapat meminimalkan efek pada aplikasi klien dengan melakukan tindakan berikut:
Selama lalu lintas klien rendah, pilih waktu pemeliharaan dengan hati-hati.
Saat memutakhirkan atau memperbarui SQL Server di situs utama, ubah mode ketersediaan kembali ke penerapan asinkron, lalu kembali ke penerapan sinkron ketika Anda siap untuk melakukan failover ke situs utama lagi.
AG dengan node kluster failover instans.
Jika AG berisi node instans kluster failover (FCI), Anda harus memutakhirkan node yang tidak aktif terlebih dahulu sebelum memutakhirkan node yang aktif. Gambar berikut mengilustrasikan skenario AG umum dengan FCI untuk ketersediaan tinggi lokal dan penerapan asinkron antara FCI untuk pemulihan bencana jarak jauh, dan urutan peningkatan.
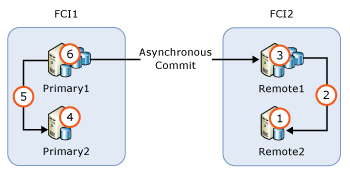
- Meningkatkan atau memperbarui
REMOTE2 - Alihkan FCI2 ke
REMOTE2 - Meningkatkan atau memperbarui
REMOTE1 - Meningkatkan atau memperbarui
PRIMARY2 - Alihkan FCI1 ke
PRIMARY2 - Meningkatkan atau memperbarui
PRIMARY1
Meningkatkan atau memperbarui instans SQL Server dengan beberapa AG
Jika Anda menjalankan beberapa AG dengan replika utama pada simpul server terpisah (konfigurasi Aktif/Aktif), jalur peningkatan melibatkan lebih banyak langkah failover untuk mempertahankan ketersediaan tinggi dalam proses. Misalkan Anda menjalankan tiga AG pada tiga simpul server dengan semua replika dalam mode penerapan sinkron seperti yang ditunjukkan dalam tabel berikut:
| AG | Node1 | Node2 | Node3 |
|---|---|---|---|
| AG1 | Primer | ||
| AG2 | Primer | ||
| AG3 | Primer |
Mungkin sesuai dalam situasi Anda untuk melakukan peningkatan bergulir yang seimbang beban dalam urutan berikut:
- Alihkan fungsi AG2 ke
Node3(untuk membebaskanNode2) - Meningkatkan atau memperbarui
Node2 - Failover dari AG1 ke
Node2(sebagai upaya untuk membebaskanNode1) - Meningkatkan atau memperbarui
Node1 - Failover AG2 dan AG3 ke
Node1(untuk membebaskanNode3) - Meningkatkan atau memperbarui
Node3 - Alihkan AG3 ke
Node3
Urutan peningkatan ini memiliki waktu henti rata-rata kurang dari dua failover per AG. Konfigurasi yang dihasilkan diperlihatkan dalam tabel berikut.
| AG | Node1 | Node2 | Node3 |
|---|---|---|---|
| AG1 | Primer | ||
| AG2 | Primer | ||
| AG3 | Primer |
Berdasarkan implementasi spesifik Anda, jalur peningkatan Anda mungkin bervariasi, dan waktu henti yang dialami aplikasi klien mungkin juga bervariasi.
Catatan
Dalam banyak kasus, setelah peningkatan bergulir selesai, Anda akan gagal kembali ke replika utama asli.
Pemutakhiran bergulir dari grup ketersediaan terdistribusi
Untuk melakukan peningkatan bergulir dari grup ketersediaan terdistribusi, pertama-tama tingkatkan semua replika sekunder. Selanjutnya, failover pada forwarder dan tingkatkan instans terakhir yang tersisa dari grup ketersediaan kedua. Setelah semua replika lain ditingkatkan, failover primer global dan tingkatkan instans terakhir yang tersisa dari grup ketersediaan pertama. Diagram terperinci dengan langkah-langkah disediakan di bagian selanjutnya.
Berdasarkan implementasi spesifik Anda, jalur peningkatan Anda mungkin bervariasi, dan waktu henti yang dialami aplikasi klien mungkin juga bervariasi.
Catatan
Dalam banyak kasus, setelah peningkatan bergulir selesai, Anda akan gagal kembali ke replika utama asli.
Langkah-langkah umum untuk meningkatkan grup ketersediaan terdistribusi
- Cadangkan seluruh database, termasuk database sistem dan database yang berpartisipasi dalam grup ketersediaan.
- Perbarui dan mulai ulang semua replika sekunder dari grup ketersediaan kedua (grup hilir).
- Tingkatkan dan reboot semua replika sekunder dari kelompok ketersediaan pertama (upstream).
- Alih peran primary forwarder ke replika sekunder yang telah ditingkatkan dari grup ketersediaan sekunder.
- Tunggu sinkronisasi data. Database harus muncul sebagai tersinkronisasi pada semua replika komit sinkron, dan primer global harus disinkronkan dengan penerus.
- Tingkatkan dan restart instance terakhir yang tersisa dari grup ketersediaan sekunder.
- Alihkan primary global ke sekunder yang sudah ditingkatkan pada grup ketersediaan pertama.
- Tingkatkan instans terakhir yang tersisa dari grup ketersediaan utama.
- Mulai ulang server yang baru dimutakhirkan.
- (opsional) Gagalkan kedua grup ketersediaan kembali ke replika utama aslinya.
Penting
Verifikasi sinkronisasi di antara setiap langkah. Sebelum melanjutkan ke langkah berikutnya, konfirmasikan bahwa replika komitmen sinkron Anda disinkronkan dalam grup ketersediaan, dan bahwa primer global Anda disinkronkan dengan pengarah di AG terdistribusi.
Rekomendasi: Setiap kali Anda memverifikasi sinkronisasi, refresh simpul database dan simpul AG terdistribusi di SQL Server Management Studio. Setelah semuanya disinkronkan, simpan cuplikan layar dari setiap status replika. Ini membantu Anda melacak langkah apa yang Anda jalankan, memberikan bukti bahwa semuanya berfungsi dengan benar sebelum langkah berikutnya, dan membantu Anda memecahkan masalah jika ada yang salah.
Contoh diagram untuk peningkatan bergulir grup ketersediaan terdistribusi
| Kelompok Ketersediaan | Replika utama | Replika Sekunder |
|---|---|---|
| AG1 | NODE1\SQLAG |
NODE2\SQLAG |
| AG2 | NODE3\SQLAG |
NODE4\SQLAG |
| DistributedAG | AG1 (global) | AG2 (pengirim barang) |
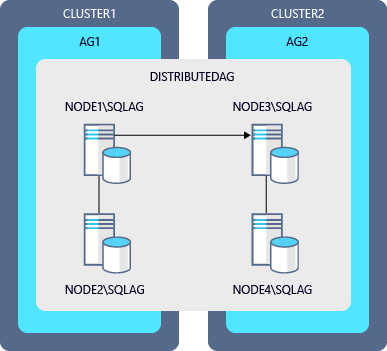
Langkah-langkah untuk meningkatkan instans dalam diagram ini:
- Cadangkan semua database, termasuk database sistem, dan database yang berpartisipasi dalam grup ketersediaan.
- Tingkatkan
NODE4\SQLAG(sekunder AG2) dan mulai ulang server. - Tingkatkan
NODE2\SQLAG(AG1 sekunder) dan mulai ulang server. - Fail AG2 dari
NODE3\SQLAGkeNODE4\SQLAG. - Mutakhirkan
NODE3\SQLAGdan mulai ulang server. - Fail AG1 dari
NODE1\SQLAGkeNODE2\SQLAG. - Mutakhirkan
NODE1\SQLAGdan mulai ulang server. - (opsional) Gagal kembali ke replika utama asli.
- Fail AG2 beralih dari
NODE4\SQLAGkeNODE3\SQLAG. - Alihkan AG1 dari
NODE2\SQLAGkembali keNODE1\SQLAG.
- Fail AG2 beralih dari
Jika terdapat replika ketiga di setiap grup ketersediaan, Anda akan memperbaruinya sebelum NODE3\SQLAG dan NODE1\SQLAG.
Penting
Verifikasi sinkronisasi di antara setiap langkah. Sebelum melanjutkan ke langkah berikutnya, konfirmasikan bahwa replika komitmen sinkron Anda disinkronkan dalam grup ketersediaan, dan bahwa primer global Anda disinkronkan dengan pengarah di AG terdistribusi.
Rekomendasi: Setiap kali Anda memverifikasi sinkronisasi, refresh simpul database dan simpul AG Terdistribusi di SQL Server Management Studio. Setelah semuanya disinkronkan, ambil cuplikan layar dan simpan. Ini membantu Anda melacak langkah apa yang Anda jalankan, memberikan bukti bahwa semuanya berfungsi dengan benar sebelum langkah berikutnya, dan membantu Anda memecahkan masalah jika ada yang salah.
Langkah khusus untuk mengubah penangkapan atau replikasi data
Bergantung pada pembaruan yang diterapkan, langkah tambahan mungkin diperlukan untuk database replika AG yang diaktifkan untuk mengubah tangkapan atau replikasi data. Lihat catatan rilis untuk pembaruan guna menentukan apakah langkah-langkah berikut diperlukan:
Tingkatkan setiap replika sekunder.
Setelah semua replika sekunder ditingkatkan, alihkan Grup Ketersediaan ke instans yang telah ditingkatkan.
Jalankan Transact-SQL berikut pada instans yang menghosting replika utama:
EXECUTE [master].[sys].[sp_vupgrade_replication];Catatan
Perintah ini mungkin perlu waktu beberapa menit untuk dijalankan. Lewati langkah ini jika Anda menggunakan SQL Server 2019 CU1 atau yang lebih baru. Untuk mempelajari lebih lanjut, tinjau KB4530283.
Tingkatkan instans yang awalnya merupakan replika utama.
Untuk informasi latar belakang, lihat Fungsionalitas CDC mungkin putus setelah meningkatkan ke CU terbaru.