Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() SQL Server 2017 (14.x) dan versi yang lebih baru
SQL Server 2017 (14.x) dan versi yang lebih baru
Artikel ini menjelaskan langkah-langkah untuk membuat grup ketersediaan AlwaysOn (AG) dengan satu replika di server Windows dan replika lainnya di server Linux.
Penting
Grup ketersediaan lintas platform SQL Server, yang mencakup replika heterogen dengan ketersediaan tinggi lengkap dan dukungan pemulihan bencana, tersedia dengan DH2i DxEnterprise. Untuk informasi selengkapnya, lihat Grup Ketersediaan SQL Server dengan Sistem Operasi Campuran.
Lihat video berikut untuk mengetahui tentang grup ketersediaan lintas platform dengan DH2i.
Konfigurasi ini lintas platform karena replika berada pada sistem operasi yang berbeda. Gunakan konfigurasi ini untuk migrasi dari satu platform ke platform lainnya atau pemulihan bencana (DR). Konfigurasi ini tidak mendukung ketersediaan tinggi.
Sebelum melanjutkan, Anda harus terbiasa dengan penginstalan dan konfigurasi untuk instans SQL Server di Windows dan Linux.
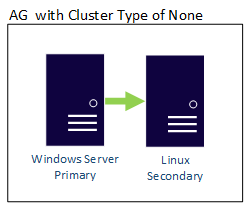
Skenario
Dalam skenario ini, dua server berada di sistem operasi yang berbeda. Windows Server 2022 bernama WinSQLInstance menghosting replika utama. Server Linux bernama LinuxSQLInstance menjalankan replika sekunder.
Konfigurasi AG
Langkah-langkah untuk membuat AG sama dengan langkah-langkah untuk membuat AG untuk beban kerja skala baca. Jenis kluster AG adalah NONE, karena tidak ada manajer kluster.
Untuk skrip dalam artikel ini, tanda kurung sudut < dan > menandai nilai yang harus Anda ganti sesuai dengan lingkungan Anda. Kurung sudut itu sendiri tidak diperlukan untuk skrip.
Instal SQL Server 2022 (16.x) di Windows Server 2022, aktifkan Grup Ketersediaan AlwaysOn dari Pengelola Konfigurasi SQL Server, dan atur autentikasi mode campuran.
Petunjuk
Jika Anda memvalidasi solusi ini di Azure, tempatkan kedua server dalam set ketersediaan yang sama untuk memastikan mereka dipisahkan di pusat data.
Aktifkan Grup Ketersediaan
Untuk petunjuknya, lihat Mengaktifkan atau menonaktifkan fitur grup ketersediaan AlwaysOn.
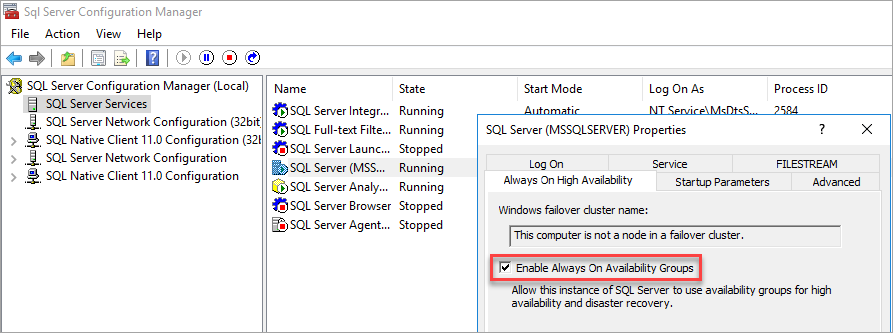
Pengelola Konfigurasi SQL Server mencatat bahwa komputer bukan node dalam kluster failover.
Setelah Anda mengaktifkan Grup Ketersediaan, mulai ulang SQL Server.
Mengatur autentikasi mode campuran
Untuk petunjuknya, lihat Mengubah mode autentikasi server.
Instal SQL Server 2022 (16.x) di Linux. Untuk petunjuknya, lihat Panduan penginstalan untuk SQL Server di Linux. Aktifkan
hadrdengan mssql-conf.Untuk mengaktifkan
hadrmelalui mssql-conf dari perintah shell, terbitkan perintah berikut:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Setelah Anda mengaktifkan
hadr, hidupkan ulang instans SQL Server:sudo systemctl restart mssql-server.serviceKonfigurasikan
hostsfile di kedua server, atau daftarkan nama server dengan DNS.Buka port firewall untuk TCP 1433 dan 5022 di Windows dan Linux.
Pada replika utama, buat login database dan kata sandi.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOPerhatian
Kata sandi Anda harus mengikuti kebijakan kata sandi default SQL Server. Secara default, kata sandi harus panjangnya minimal delapan karakter dan berisi karakter dari tiga dari empat set berikut: huruf besar, huruf kecil, digit dasar-10, dan simbol. Panjang kata sandi bisa hingga 128 karakter. Gunakan kata sandi yang panjang dan kompleks mungkin.
Pada replika utama, buat kunci master dan sertifikat, lalu cadangkan sertifikat dengan kunci privat.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOPerhatian
Kata sandi Anda harus mengikuti kebijakan kata sandi default SQL Server. Secara default, kata sandi harus panjangnya minimal delapan karakter dan berisi karakter dari tiga dari empat set berikut: huruf besar, huruf kecil, digit dasar-10, dan simbol. Panjang kata sandi bisa hingga 128 karakter. Gunakan kata sandi yang panjang dan kompleks mungkin.
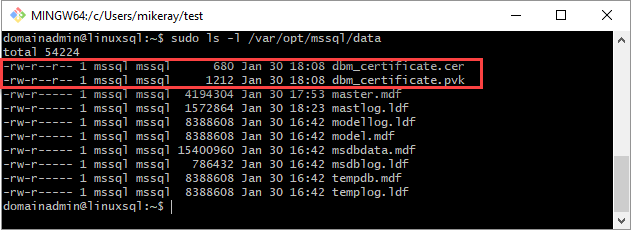
Salin sertifikat dan kunci privat ke server Linux (replika sekunder) di
/var/opt/mssql/data. Anda dapat menggunakanpscpuntuk menyalin file ke server Linux.Atur grup dan kepemilikan kunci privat dan sertifikat ke
mssql:mssql.Skrip berikut mengatur grup dan kepemilikan file.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerDalam diagram berikut, kepemilikan dan grup diatur dengan benar untuk sertifikat dan kunci.
Pada replika sekunder, buat login database dan kata sandi dan buat kunci master.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOPerhatian
Kata sandi Anda harus mengikuti kebijakan kata sandi default SQL Server. Secara default, kata sandi harus panjangnya minimal delapan karakter dan berisi karakter dari tiga dari empat set berikut: huruf besar, huruf kecil, digit dasar-10, dan simbol. Panjang kata sandi bisa hingga 128 karakter. Gunakan kata sandi yang panjang dan kompleks mungkin.
Pada replika sekunder, pulihkan sertifikat yang Anda salin ke
/var/opt/mssql/data.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GODalam contoh sebelumnya, ganti
<private-key-password>dengan kata sandi yang sama dengan yang Anda gunakan saat membuat sertifikat pada replika utama.Pada replika utama, buat titik akhir.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOPenting
Firewall harus membuka port TCP untuk pendengar. Dalam skrip sebelumnya, port adalah 5022. Gunakan port TCP yang tersedia.
Pada replika sekunder, buat titik akhir. Ulangi skrip sebelumnya pada replika sekunder untuk membuat titik akhir.
Pada replika utama, buat AG dengan
CLUSTER_TYPE = NONE. Contoh skrip menggunakanSEEDING_MODE = AUTOMATICuntuk membuat AG.Catatan
Ketika instans Windows SQL Server menggunakan jalur yang berbeda untuk file data dan log, penyemaian otomatis gagal ke instans Linux SQL Server, karena jalur ini tidak ada di replika sekunder. Untuk menggunakan skrip berikut untuk AG lintas platform, database memerlukan jalur yang sama untuk data dan file log di server Windows. Atau Anda dapat memperbarui skrip dengan
SEEDING_MODE = MANUAL, kemudian mencadangkan dan memulihkan database denganNORECOVERYuntuk mengisi database.Perilaku ini berlaku untuk gambar Marketplace Azure.
Untuk informasi selengkapnya tentang penyemaian otomatis, lihat Penyemaian Otomatis - Tata Letak Cakram.
Sebelum Anda menjalankan skrip, perbarui nilai untuk AG Anda.
Ganti
<WinSQLInstance>dengan nama server instans SQL Server replika utama.Ganti
<LinuxSQLInstance>dengan nama server instans SQL Server replika sekunder.
Untuk membuat AG, perbarui nilai dan jalankan skrip pada replika utama.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); );Untuk informasi selengkapnya, lihat MEMBUAT GRUP KETERSEDIAAN.
Pada replika sekunder, bergabunglah dengan AG.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOBuat database untuk AG. Contoh langkah-langkah menggunakan database bernama
TestDB. Jika Anda menggunakan seeding otomatis, atur jalur yang sama untuk data dan file log.Sebelum Anda menjalankan skrip, perbarui nilai untuk database Anda.
Mengganti
TestDBdengan nama database Anda.Ganti
<F:\Path>dengan jalur untuk database dan file log Anda. Gunakan jalur yang sama untuk database dan file log.
Anda juga dapat menggunakan jalur default.
Untuk membuat database Anda, jalankan skrip.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY (NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GOAmbil cadangan lengkap database.
Jika Anda tidak menggunakan seeding otomatis, pulihkan database di server replika sekunder (Linux). Migrasikan database SQL Server dari Windows ke Linux menggunakan pencadangan dan pemulihan. Pulihkan database
WITH NORECOVERYpada replika sekunder.Tambahkan database ke AG. Perbarui contoh skrip. Mengganti
TestDBdengan nama database Anda. Pada replika utama, jalankan kueri T-SQL untuk menambahkan database ke AG.ALTER AG [ag1] ADD DATABASE TestDB; GOVerifikasi bahwa database diisi pada replika sekunder.

Lakukan failover pada replika utama
Setiap grup ketersediaan hanya memiliki satu replika utama. Replika utama memungkinkan baca dan tulis. Untuk mengubah replika mana yang menjadi utama, Anda dapat menjalankan failover. Dalam grup ketersediaan umum, manajer kluster mengotomatiskan proses failover. Pada grup ketersediaan dengan tipe kluster NONE, proses failover dilakukan secara manual.
Ada dua cara untuk melakukan failover pada replika utama dalam grup ketersediaan dengan jenis kluster NONE:
- Failover secara manual tanpa kehilangan data
- Failover manual yang dilakukan secara paksa dengan kehilangan data
Failover secara manual tanpa kehilangan data
Gunakan metode ini saat replika utama tersedia, tetapi Anda perlu mengubah sementara atau secara permanen instans mana yang menghosting replika utama. Untuk menghindari potensi kehilangan data, sebelum Anda mengeluarkan failover manual, pastikan bahwa replika sekunder target sudah diperbarui.
Untuk melakukan failover secara manual tanpa kehilangan data:
Buat replika
SYNCHRONOUS_COMMITsekunder primer dan target saat ini .ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Untuk mengidentifikasi bahwa transaksi aktif diterapkan ke replika utama dan setidaknya satu replika sekunder sinkron, jalankan kueri berikut:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;Replika sekunder disinkronkan ketika
synchronization_state_descadalahSYNCHRONIZED.Perbarui
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITke 1.Skrip berikut menetapkan
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITke 1 pada grup ketersediaan bernamaag1. Sebelum Anda menjalankan skrip berikut, gantiag1dengan nama grup ketersediaan Anda:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Pengaturan ini memastikan bahwa setiap transaksi aktif diterapkan ke replika utama dan setidaknya satu replika sekunder sinkron.
Catatan
Pengaturan ini tidak spesifik untuk failover dan harus ditetapkan berdasarkan persyaratan lingkungan.
Atur replika utama dan replika sekunder yang tidak berpartisipasi dalam failover offline untuk mempersiapkan perubahan peran:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEPromosikan replika sekunder target ke utama.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Perbarui peran primer lama dan sekunder lainnya ke
SECONDARY, jalankan perintah berikut pada instans SQL Server yang menghosting replika utama lama:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Catatan
Untuk menghapus grup ketersediaan, gunakan DROP AVAILABILITY GROUP. Untuk grup ketersediaan yang dibuat dengan jenis kluster NONE atau EXTERNAL, jalankan perintah pada semua replika yang merupakan bagian dari grup ketersediaan.
Lanjutkan pergerakan data, jalankan perintah berikut untuk setiap database dalam grup ketersediaan pada instans SQL Server yang menghosting replika utama:
ALTER DATABASE [db1] SET HADR RESUMEBuat ulang listener apa pun yang Anda buat untuk tujuan skala baca dan yang tidak dikelola oleh manajer kluster. Jika pendeteksi asli menunjuk ke primer lama, hapus dan buat kembali untuk menunjuk ke primer baru.
Failover manual yang dilakukan secara paksa dengan kehilangan data
Jika replika utama tidak tersedia dan tidak dapat segera dipulihkan, maka Anda perlu memaksa failover ke replika sekunder dengan kehilangan data. Namun, jika replika utama asli pulih setelah failover, replika tersebut akan mengasumsikan peran utama. Untuk menghindari setiap replika berada dalam status yang berbeda, hapus primary asli dari grup ketersediaan setelah failover paksa yang menyebabkan kehilangan data. Setelah server utama asli kembali online, hapus kelompok ketersediaan darinya sepenuhnya.
Untuk memaksa failover manual yang mengakibatkan kehilangan data dari replika utama N1 ke replika sekunder N2, lakukan langkah-langkah berikut:
Pada replika sekunder (N2), mulai failover paksa:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;Pada replika utama baru (N2), hapus primer asli (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Validasi bahwa semua lalu lintas aplikasi diarahkan ke pendengar dan/atau replika utama baru.
Jika sistem primer asli (N1) aktif, segera jadikan grup ketersediaan AGRScale offline pada sistem primer asli (N1).
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEJika ada data atau perubahan yang tidak disinkronkan, pertahankan data ini melalui cadangan atau opsi replikasi data lain yang sesuai dengan kebutuhan bisnis Anda.
Selanjutnya, hapus grup ketersediaan dari primer asli (N1):
DROP AVAILABILITY GROUP [AGRScale];Hilangkan database grup ketersediaan pada replika utama asli (N1):
USE [master] GO DROP DATABASE [AGDBRScale] GO(Opsional) Jika diinginkan, Anda sekarang dapat menambahkan N1 kembali sebagai replika sekunder baru ke grup ketersediaan AGRScale.
Artikel ini meninjau langkah-langkah untuk membuat AG lintas platform untuk mendukung migrasi atau beban kerja skala baca. Ini dapat digunakan untuk pemulihan bencana manual. Ini juga menjelaskan cara melakukan failover pada AG. AG lintas platform menggunakan jenis NONE kluster dan tidak mendukung ketersediaan tinggi.