Deep Dive: SQL Server AlwaysOn Availability Groups and Cross-Region Virtual Networks in Azure
SQL Server AlwaysOn Availability Group (AG) is a great technology for high-availability and disaster-recovery, and if you want to build an IaaS VM environment in Azure, you have to deal with it since Windows Server Failover Clustering (WSFC) is not supported here yet. Full support for AlwaysOn in Azure VMs has been announced last year, but only with the very recent support for Vnet-to-Vnet connectivity, the SQL Server team was able to test and officially support the usage of AG in a cross-datacenter scenario:
SQL Server AlwaysOn Availability Groups Supported between Microsoft Azure Regions
VNet-to-VNet: Connecting Virtual Networks in Azure across Different Regions
In order to include the new cross-datacenter scenario for AG, SQL Server Product Group updated the existing documentation on how to setup AlwaysOn Availability Group (AG) and its Listener, including details and steps specific to this new configuration, and this is what I want to cover in this blog post. Additionally, I want to add some value describing how you can eventually put in production a slightly more complex configuration able to provide you additional benefits. Finally, there are some steps in the documentation that, even if formally correct, need clarification on how must be interpreted when used in a multi-datacenter scenario. I will base my considerations on the following articles:
Configure AlwaysOn Availability Groups in Azure VM (GUI)
https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-sql-server-alwayson-availability-groups-gui
Configure an ILB listener for AlwaysOn Availability Groups in Azure
https://azure.microsoft.com/en-us/documentation/articles/virtual-machines-sql-server-configure-ilb-alwayson-availability-group-listener
Azure Virtual Network Bandwidth and Latency
This is always my primary concern, even on-premise, When I have to build a multi-site AlwaysOn consideration: the connectivity between different datacenters will provide enough network bandwidth and low latency? Remember that we are in Azure and the connectivity between datacenters is provided by connecting two (at least) Virtual Networks using a VPN tunnel that comes with capacity limits, then let me recap some basic considerations:
- Today, for each Virtual Network, you can have only one VPN Gateway;
- Each VPN Gateway is able to provide, at the very maximum, a theoretical limit of 100Mbits/sec;
- If you connect a VPN Gateway to multiple Virtual Networks, including on-premise local networks, each channel will share the same theoretical bandwidth limit of 100Mbits/sec;
- VPN Gateway is backed up by two “hidden” Azure VMs of a certain size in active-passive configuration, able to provide 99,90% availability SLA:
Cloud Services, Virtual Machines and Virtual Network SLA
http://www.microsoft.com/windowsazure/sla

Let me emphasize again the theoretical limit of 100Mbits/sec: this restriction comes from the size of the hidden VM used to implement the VPN Gateway. I don’t see yet an official confirmation on when that VM size will be increased to ensure higher bandwidth, but I’m pretty sure this will happen, sooner or later, to support bigger workloads in AG configurations. If this is not enough for your data replication requirements, you should evaluate Azure ExpressRoute for higher bandwidth and lower latency; a very nice comparison of all connectivity technologies in Azure is provided in the article below from Ganesh Srinivasan:
ExpressRoute or Virtual Network VPN – What’s right for me?
http://azure.microsoft.com/blog/2014/06/10/expressroute-or-virtual-network-vpn-whats-right-for-me
NOTE: In this blog post, I will not cover ExpressRoute, I didn’t test for AlwaysOn AG scenarios.
My Test Configuration
I started from the idea shown in the picture below but added the following configuration changes:
- I placed an Active Directory Domain Controller in REGION1 (R1) and REGION2 (R2) datacenters, each one with DNS installed onboard and fully replicated each other;
- In R1, I configured a Cluster File Share Witness (FSW) on the Domain Controller (DC1) in order to avoid using another SQL Server VM, then a little bit less expensive configuration; nothing on the Domain Controller in R2 (DC2);
- In R2 I used an additional SQL Server VM, then in total there I have 2 SQL Server VMs; At the end, my Windows Server Failover Cluster (WSFC) is composed by 4 nodes;
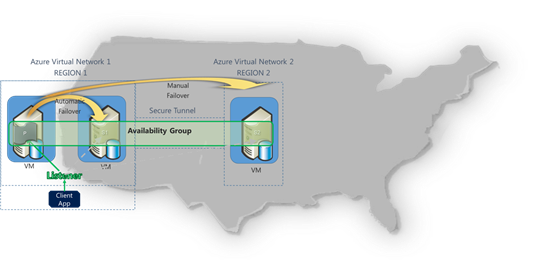
Now, let me emphasize some very important configuration and architectural aspects:
- Since a Cloud Service cannot span multiple Azure datacenters, I used a distinct Cloud Service (CS1) in R1 and a second distinct Cloud Service (CS2) in R2;
- Since a VNET cannot span multiple datacenters, I created a distinct Virtual Network in R1 (VNET1) and a distinct Virtual Network in R2 (VNET2);
- Since an Azure Availability Set cannot span multiple Cloud Services, I created one (AS1) in R1 and a second distinct one (AS2) in R2;
- Since an Azure Load Balanced Set cannot span different Cloud Services, I created one (LBS1) in R1 and a second distinct one (LBS2) in R2;
IMPORTANT: As you will see later in this post, I will adopt a different AG Listener configuration, compared to what is shown in the picture above and to what the SQL Server Product Group described in the documentation mentioned earlier in this post. My AG Listener will be able to failover also into R2 and provide transparent and automatic redirection to the primary SQL Serve instance even if the primary Azure datacenter (R1) will be completely down. Let me emphasize again: the procedure to create the AG Listener mentioned in “Tutorial:
Listener Configuration for AlwaysOn Availability Groups” will not allow this, you need to use a slightly different configuration process that I will describe later in this post.

Cluster Configuration: My Notes
As per SQL Server Product Group instructions, you need to follow the tutorial below to prepare the necessary Cluster configuration, including the SQL Server installation on each VM and creation of necessary Azure objects:
Tutorial: AlwaysOn Availability Groups in Azure (GUI)
http://msdn.microsoft.com/en-us/library/dn249504.aspx
You need to remember that we are in a multi-datacenter configuration, and then you need to follow steps contained in section “Create the Virtual Network and Domain Controller Server” two times, one for R1 and one for R2. Obviously, for the second Domain Controller you don’t have to create a new forest/domain but joining the previously created for R1. After completing the procedure for R1, you need to establish VPN tunnel between the two Virtual Network as described in the link below, then proceed with R2:
Configure a VNet to VNet Connection
http://azure.microsoft.com/documentation/articles/virtual-networks-configure-vnet-to-vnet-connection
Now you need to follow steps in section “Create the SQL Server VMs” to create the SQL VMs in R1 (using local Virtual Network, Cloud Service and Virtual Network): do not install the non-SQL third VM since we’ll use a File Share Witness created on the existing Domain
Controller (DC1). Now, you need to repeat the procedure to install the two SQL Server VM in R2 (using local Virtual Network, Cloud Service and Virtual Network), also this time install only the two SQL Server VMs and forget the third one.
Now you should follow steps in section “Create the WSFC Cluster”, but there is a problem with the procedure mentioned in the tutorial above. If you initially create a 1-node only Cluster, the setup procedure will not realize that this is a multi-datacenter/subnet installation
and will only create one IP, in the dependencies for the Cluster Network Name, for the local virtual network in R1! The final effect will be that the Cluster Network Name, and then the Cluster Core Resource Group, will not be able to go online in the secondary datacenter (R2). How to solve it? You can include all the VMs in the Cluster creation step or, if you already completed that procedure, you can add manually a second IP, for the second Virtual Network in R2, using Power Shell and the procedure mentioned in the link below:
Configuring IP Addresses and Dependencies for Multi-Subnet Clusters - Part III
http://blogs.msdn.com/b/clustering/archive/2011/08/31/10204142.aspx
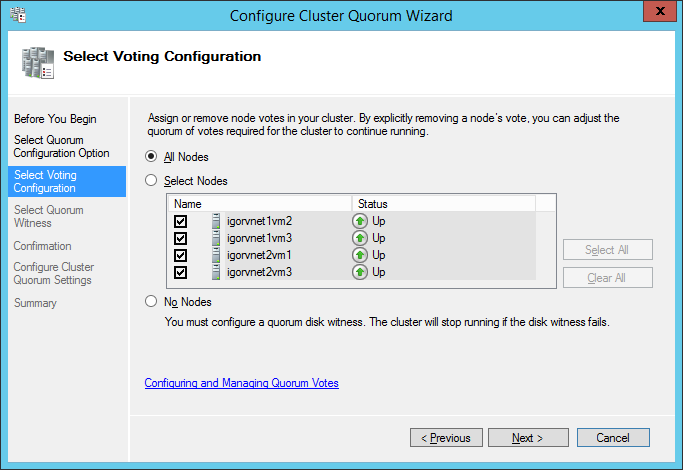
If you follow my recommendation correctly, in the Failover Cluster Manager console you should see something like this:
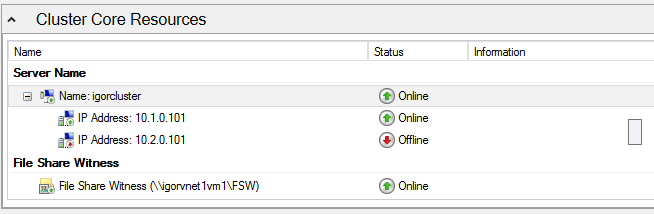
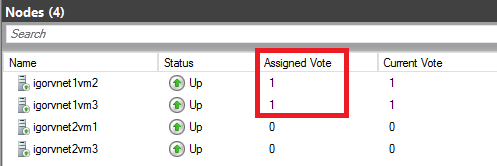
As you can see in the print screen above, I also configured a File Share Witness (FSW), you can do that very easily using the “Configure Cluster Quorum Wizard” from the context menu of the Cluster Name. In addition to that, I would also recommend removing “Votes” for
Cluster node SQL Server VMs in the secondary R2 site, the actual configuration links provided for the AlwaysOn in Azure documentation does not mention it. Why this? The reason is that you don’t want the secondary site to influence the availability of the primary site R1, this is typical Cluster configuration also used on-premise, you can read more about that in the link below (section “Voting and Non-Voting Nodes”):
WSFC Quorum Modes and Voting Configuration (SQL Server)
http://msdn.microsoft.com/en-us/library/hh270280.aspx
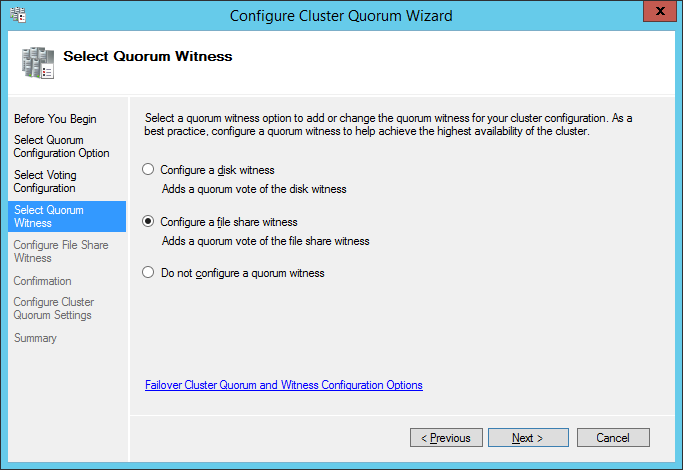
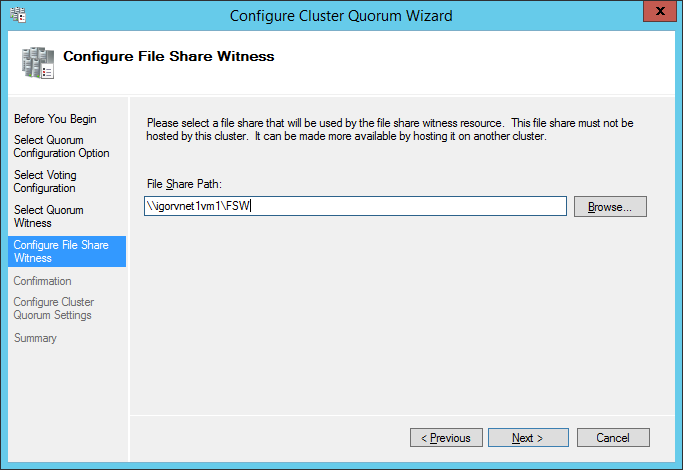
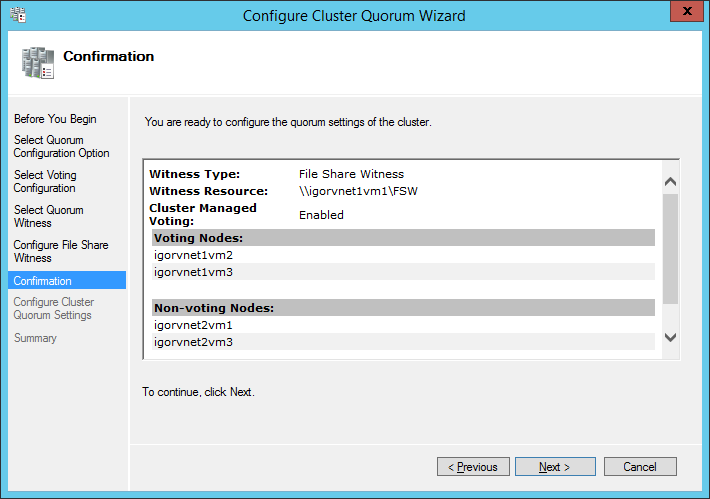
I will not go into full details, but below you can see the series of print screens and configuration selections you should use. You need to run over the wizard two times: one to select the quorum witness (and chose File Share Witness) and one for the advanced quorum
configuration (removing votes for secondary site nodes):

Creating the Availability Group: My Notes
Now that your cluster is ready, you can proceed with instructions to create Availability Group in the section “Create the Availability Group” of the afore mentioned link/document. The only difference here is that at Step(27) you need to add THREE replicas: one in the primary R1 site and two in the secondary R2 site:
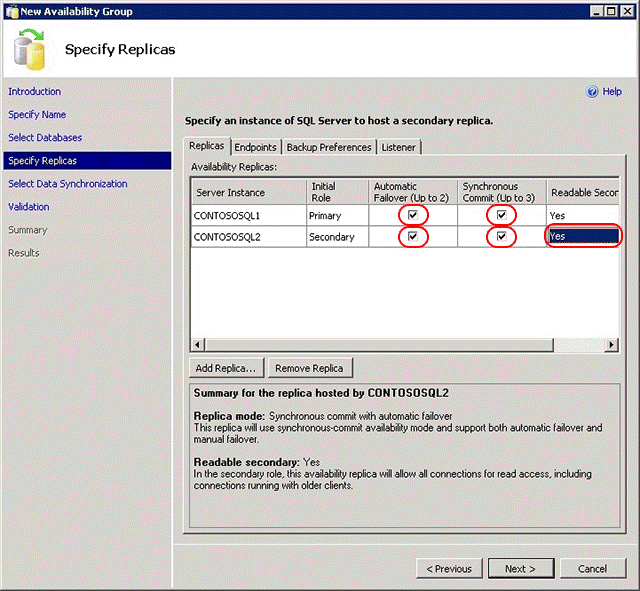
Since we have four SQL Server VMs, you may be tempted to configure one of the two SQL Server instances in the secondary Azure site with synchronous replication and/or automatic failover, but I would encourage you to think carefully about this possibility. This is a very confusing aspect in the SQL Server 2014 documentation: how many sync replicas are supported? Let me explain better: SQL Server 2014 supports up to three sync replicas, but including the primary, then the total number of supported sync secondary is two, not three. Secondly, sync replicas are different from automatic failover: SQL Server supports up to three sync replicas, but only two replicas for automatic failover!
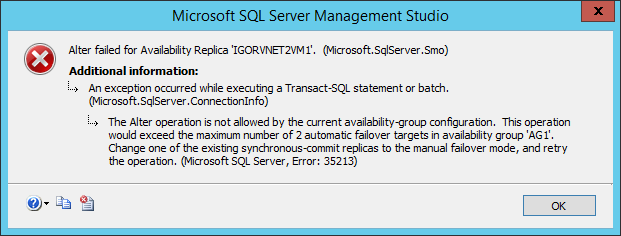
Why this is important? If you have the idea to change slightly the configuration to allow automatic failover between different Azure datacenters, in theory you can do that, but you will lose the possibility to have automatic failover inside the same datacenter. Additionally, automatic failover requires synchronous data replication, since each Azure datacenter is at least 400 miles far away from each other, latency will hurt your performances. Even worst, due to how the Windows Failover Cluster (WSFC) work, manual intervention is required to resume cluster functionalities in case of a complete primary datacenter disaster, then automatic failover at SQL Server AG level will not help. I will explain how to recover from a complete primary site disaster later in this post. At the end, this is how I configured my four nodes installation from an AG perspective:
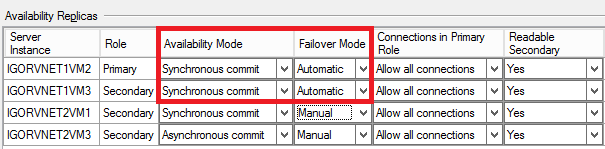
For the third SQL instance I configured “Synchronous Commit” only to test a scenario with zero data loss between multiple datacenter, let me recommend you again to test carefully the impact of synchronous data replication. If you are wondering why I decided to use two VMs in the secondary site, remember that there is no SLA support in Azure for single instance VMs: if you want 99,95 HA SLA, you need to have at least two VMs in the same Availability Set.
Creating the Listener: My Notes
Perfect, now it is time to create the AG Listener! The base instructions are contained in the following link:
Tutorial: Listener Configuration for AlwaysOn Availability Groups
http://msdn.microsoft.com/en-us/library/dn425027.aspx
This document has been originally written for single datacenter deployment, then some work and attention are needed to correctly translate in our current multi-datacenter context. First attention point in the script for Step(1.8) :
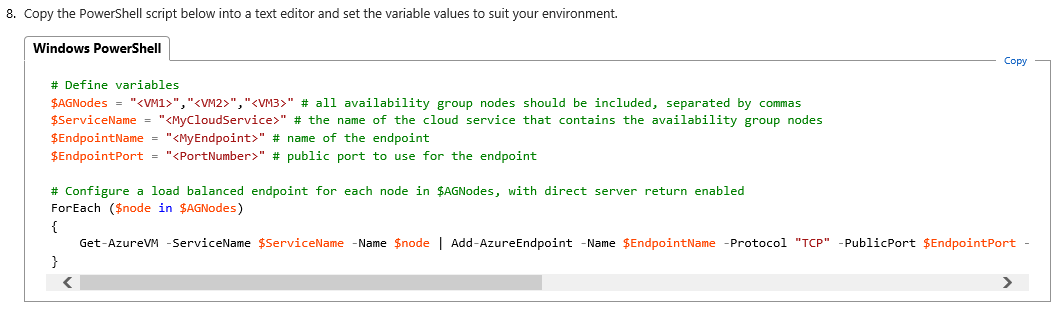
The comments in the script must be evaluated in a multi-datacenter and multi-cloud service scenario: first, you need to execute the script two times, one for each Cloud-Service/Datacenter. Secondly, you need to include, in each execution, only the VMs that are part of that specific Cloud-Service/Datacenter. This is necessary to create two separate Load Balanced Endpoints. In the screen below, you can see the script that I used for my environment:
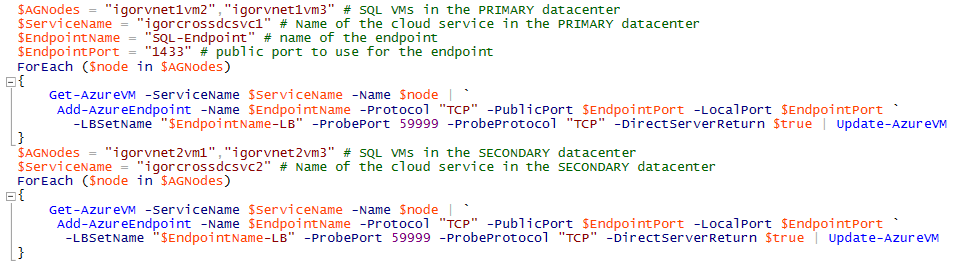
The second attention point is at Step(4.9) as shown below:
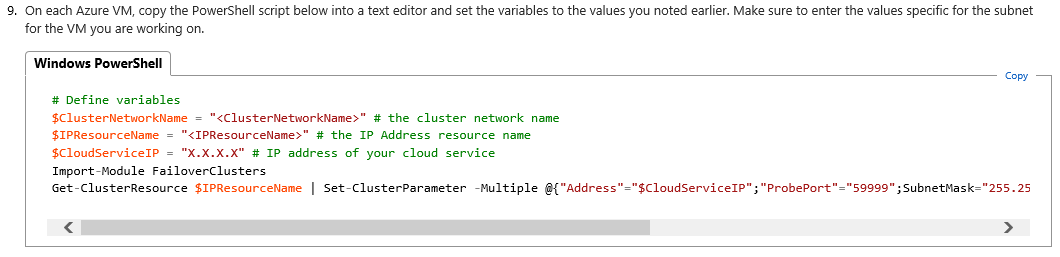
Also in this case, you need to execute the above script two times, one for each datacenter: for each execution, you need to specify the local cluster network name, IP address and Cloud Service public VIP. This is how I executed in my specific configuration:

Here, you don’t need to execute on all VMs since Cluster configuration is replicated among all nodes: it’s sufficient to execute the script above on only one VM. Once completed the entire procedure, this is what you should see in the Failover Cluster Manager tool for the Listener:
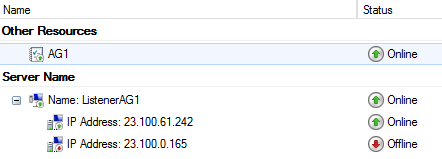
Finally, in the Azure Management Portal you will see that we now have two distinct Load Balanced Endpoints, one for each Datacenter/Cloud-Service, including only the SQL Server VMs in the local Datacenter/Cloud-Service.
What Happen if Primary Datacenter is Down?
Before going into the detailed steps you will need to run to recover your AlwaysOn Availability Group database, let me recap the current configuration I adopted for my tests:
- TWO SQL Server 2014 instances in the primary Azure datacenter with synchronous replica and automatic failover. Correspondent Cluster nodes have votes configured at the Cluster level and File Share Witness is located here on the Active Directory Domain Controller. The primary replica is running here.
- TWO SQL Server 2014 instances in the secondary Azure datacenter with ONE synchronous replica but no automatic failover. The second local SQL Server 2014 instance is configured with Asynchronous replica and obviously no automatic failover. No votes are assigned to these VMs in the cluster quorum configuration.
Now, imagine that the primary Azure datacenter is completely lost: what you will see trying to connect to the Cluster in the secondary Azure datacenter?
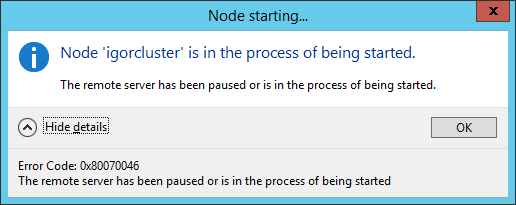
Even if the local Cluster service is running, you will see the above dialog: this is expected since the Cluster lost the quorum and will not be able to maintain online any clustered resource, including our AlwaysOn Availability Group Listener. In this state, the local Cluster service is
waiting and listening from something to happen that could permit to restore normal functionality, then it’s now time to start the disaster recovery process. First action you need to do is restart, on one of the local VM in the secondary Azure datacenter, the cluster service using “ForceQuorum” setting (can also be done in the Cluster console but I love the vintage approach):
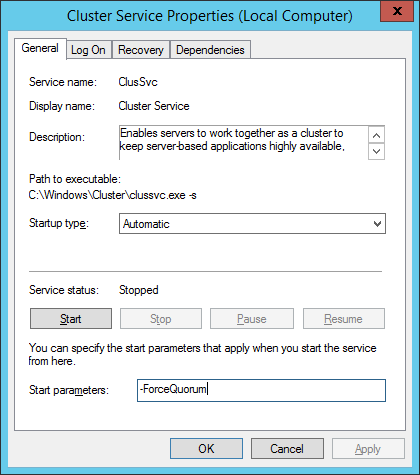
You will be now able to connect to the Cluster using the Cluster Network Name, if you configured the additional IP address resource for the Cluster network name as I suggested before in this post. The Cluster Resource Group will show as below and obviously, the AG resource group will be offline (see next print screens):
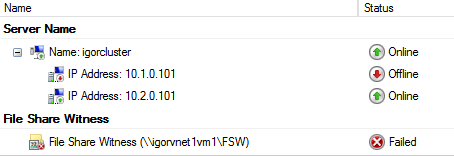
If the loss of the primary DC is permanent or expected to last for a long time, it’s recommended to change the Cluster quorum configuration assigning votes to the SQL VMs in the secondary site, then creating a new File Share Witness in the secondary Azure DC, finally evict the nodes in the primary Azure datacenter. Once you will finish changing the Cluster configuration, you can restart the Cluster service without the “ForceQuorum” switch.
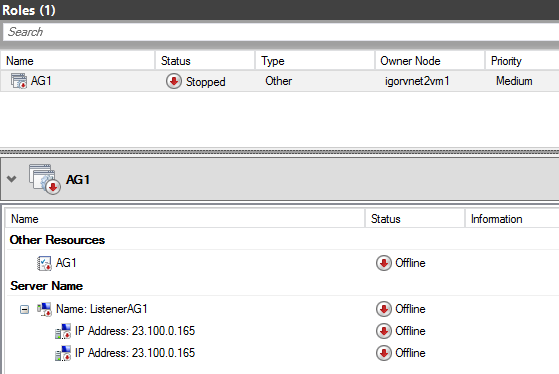
Note that SQL Server service itself is running since it does not depend on the Cluster, only the AG listener does, then let us connect using Management Studio to examine the Availability Group status:
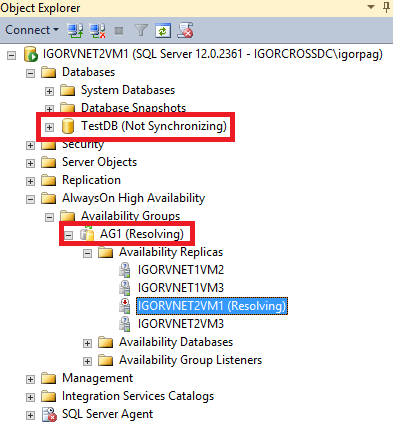
As you can see above, the database will be in “Not Synchronizing” state and Availability Group (AG) will show as “Resolving”. This is a very nice SQL Server 2014 new feature: even if the database is in “Not Synchronizing” state and Availability Group in “Resolving”, you can access data and run read-only queries. Cool! It’s time now to recover the AG and change the primary AG replica to one of the VM in the secondary site, then go there and use the “Failover Wizard” from the context menu in Management Studio:
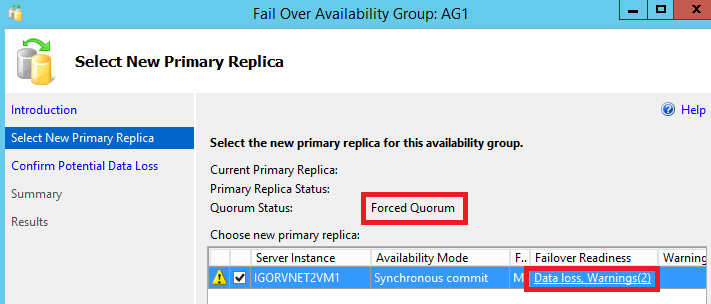
Two important things to note here:
- SQL Server detected that we started the Cluster in “ForceQuorum” mode;
- Even if the VM in the secondary site was configured with synchronous data replication, the wizard will advise you that a data loss can happen, and then you may wonder how is possible! In reality, there is no data loss here; the logic in the wizard generated this error
message since the Cluster is in “ForceQuorum” mode.
After confirming that you accepted a potential data loss, the wizard will trigger the AG primary replica change very quickly. Look at the warning sign in the final window:
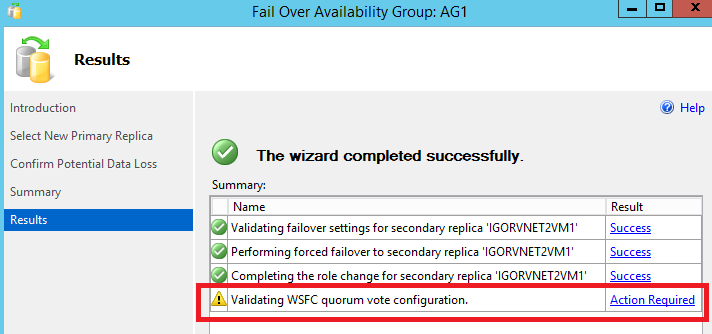
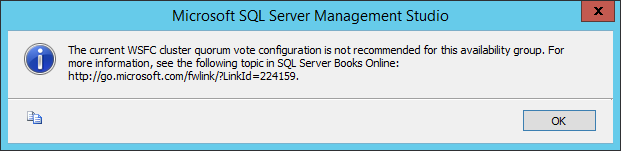
If you click on “Action Required” hyperlink, no surprise on what you will see, that’s exactly what I explained you before in my notes:
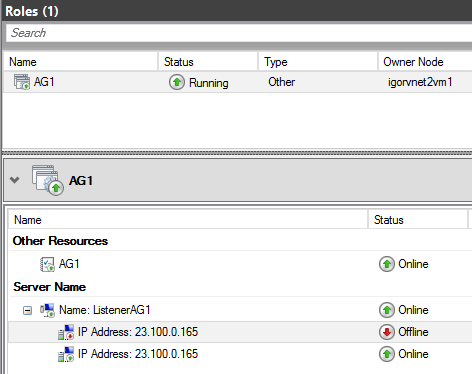
Now your database is fully accessible in read/write, and the AG resource group in the Cluster is back on-line:
Wait a moment! Your disaster recovery work is not finished. If you expect that the loss of SQL Server VMs in the primary Azure DC to be permanent or last for a long time, it’s highly recommended to remove that AG replicas, otherwise SQL Server will continue to maintain transaction log information to feed that replicas and growth at dangerous levels. Now, there is another problem to solve since the second SQL Server VM in the secondary site is not synchronizing with the new primary, why? When a forced AG failover is invoked, with a potential data loss, all the other replicas will stop receiving replicated data waiting for DBA intervention: if you are sure about what you have done so far, you can easily resume data replication traffic from the new primary:
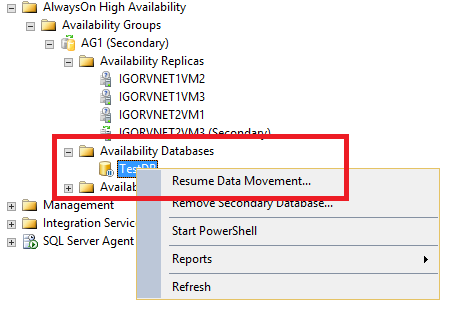
After completion, your database on the secondary VM will be healthy and accessible, the very last optional step that may want to perform, after removing failed replicas in the primary site, is changing the data replication to be synchronous with automatic failover. Well done! You just successfully recovered your SQL Server database from a terrific site disaster in Azure, hope you enjoyed the journey.
Finally, just to demonstrate you that I told you the truth, here is the print screen of my laptop’s SQL Server Management Studio: as you can see, I was able to connect to both primary (before the failure) and secondary Azure datacenters SQL instances, configured with AlwaysOn Availability Group, using public internet-facing *.CLOUDAPP.NET names:
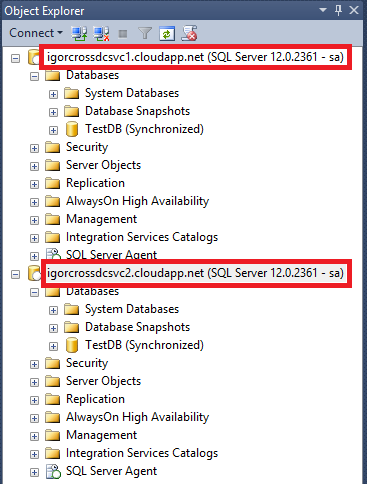
That’s all what I wanted to show you on SQL Server AlwaysOn Availability Group, based on my experience and deep testing in Azure Virtual Machine environment and cross-datacenter connectivity using Vnet-to-Vnet latest feature addition. Let me know if you
have any feedback or question, as usual you can follow me on Twitter ( @igorpag). Regards.
Comments
Anonymous
September 10, 2014
I'm using server 2012 R2 and SQL 2014, I created the DB replica fine, this failover correctly. However I can only connect to the AG listener from the machine that is the primary. Also I cannot connect from a remote machine. Now in the walk-though, it says that in SSMS you can see the listener and you should set the port, however I do not see the listener in SSMS. Now when I failover the DB's the IP does change accordingly.- Anonymous
March 23, 2016
The comment has been removed
- Anonymous
Anonymous
September 16, 2014
The comment has been removedAnonymous
November 12, 2014
Excellent! Thanks!Anonymous
January 19, 2015
Are there options to run multiple AG's (and associated listeners? so we can split the data load between 2 servers in DC1 with DC2 as a DR site? I'm concerned this isn't possible, because you'd need 2 different VIP's on the one machine? Thanks DWAnonymous
August 23, 2015
Hi, how can I have public ip of listener . my listener is only working within VPN but not from external world. please guide. Regards, HafizAnonymous
August 24, 2015
Hi Hafiz, Using public IPs is pretty simple an procedure is essentially the same except you will have to use Cloud Service VIPs (Azure SLB) instead of internal IPs (DIPs). You will still require 2 cloud services, one per datacenter, a VPN (or Express Route). You can start with the info contained in one of my older blog post: blogs.msdn.com/.../sql-server-2012-alwayson-availability-group-and-listener-in-azure-vms-notes-details-and-recommendations.aspx Regards.Anonymous
August 27, 2015
Hi Igor, Thanks for your reply. I already created public IP for listener when I was doing Always on withing same region for two different nodes and I'm done with that . But the issue occurs when I try to create public IP of listener for cords regions . Regards, HafizAnonymous
August 27, 2015
Hi Hafiz, We need to give a closer look to what you have done and errors encountered, but I cannot do that in person. For this reason, send me your mail address to IGORPAG@MICROSOFT.COM and I will give you a free voucher to open a ticket to Microsoft Support Service that will be able to assist you. Regards.- Anonymous
March 23, 2016
Hi Igor,Have a similar issue. Say we have two cloudservices CS1 and CS2. I added thier VIPs to CCR and i am able to connect to the SQL server with CSX.cloudapp.net,1433 anyways. My question is, is there a way we can connect to these servers hosted in Azure VMs with a Listner Name from public internet.Thanks- Anonymous
March 26, 2016
The comment has been removed- Anonymous
April 07, 2016
The comment has been removed- Anonymous
April 07, 2016
Very good question, that's the magic of new bits introduced some time ago in Windows Server: Cluster feature collaborates with the Azure Load Balancer to properly route traffic coming from the load balancer only to the Primary SQL Server instance. How? Look at my article and search for "The second attention point is at Step(4.9) as shown below" sentence. In the image you will notice "ProbPort=59999": Azure load balancer will "probe" SQL instances over these ports and will direct traffic only to the instance responding to this polling mechanism. As you can easily guess, the Cluster/SQL will ensure only the AlwaysOn AG Primary instance will respond to this probe, then only this instance will receive SQL traffic. Hope is now clear. Regards.
- Anonymous
- Anonymous
- Anonymous
- Anonymous
Anonymous
November 05, 2015
Can I use multiple File Share Witness servers? Can you help me with Pro's & Con's for single FSW and multiple FSW.Anonymous
November 05, 2015
Hi Praveen, don't understand the utility of using more than one File Share Witness, anyway Windows Server Cluster can only use one. Regards.Anonymous
November 09, 2015
Hi Igor, Thanks for quick revert back! We are planning to use 2 witness servers so in case one fs witness goes down SQL AlwaysOn uses other witness fs. my SQL AlwaysOn setup plan have 2 nodes (Primary and Secondary) and 2 witness fs. I heard that we can configure multiple file share witness in windows cluster and I configured it but not sure how it's working. I am still reading documents and trying to understand the setup. however can you help me answering my question:
- I have only 1 file share witness server on a 3rd system which is not part of AlwaysOn. Due to some reasons the witness server is down. What happens if Primary node fails? will primary switch to secondary or what happens?
- Same above question with 2 file share witness servers. Due to some reason first fs witness server is down. What happens if Primary node fails? will primary switch to secondary using the 2nd witness server. I am just a beginner and sorry for my dumb question.
Anonymous
November 10, 2015
To be honest with you, I've never seen two File Share Witness in a Windows Server cluster, I mean you can setup only one at time in Cluster Manager. Regards.Anonymous
February 18, 2016
The comment has been removedAnonymous
February 18, 2016
The comment has been removedAnonymous
February 23, 2016
What is the point of having complexity of internal LBs etc for multi-site setup if you can just use SQL Mirroring connection string specification where straight up names of both primary and secondary nodes can be used instead?Anonymous
February 24, 2016
Hi GS, I considered in the past this possibility but there are several drawbacks: you can only use 2 nodes while I consider 3 nodes as minimum for geo HA/DR, Mirroring is deprecated, does not support read-only routing, and other small things that at the end matter. Regards.- Anonymous
February 10, 2017
The comment has been removed
- Anonymous
Anonymous
September 28, 2016
Just curious what was the point of having the sync instance/no failover in region 2?For DR, couldn't you of just had 2 sync automatic failover in region 1 + file share witness and 1 async instance in region 2 for DR? (DR region having 0 quorum votes)- Anonymous
September 29, 2016
Hi BobbyBob,The instance in region 2 should be async, not sync, otherwise latency will hurt SQL Server performances. The 2 instances in Region 1 must be sync to ensure no data loss and automatic failover just in case of single VM failure.DR region has 0 quorum vote, not clear from the article?Regards.
- Anonymous