Динамический кворум кластера в Windows Server 2012
Не сомневаюсь, что всем читающим данный блог, знакомо понятие "кворум" применительно к кластерной инфраструктуре. Более года назад Алекс в своей заметке срывал покровы о возможностях высокодоступных решений с ассиметричными хранилищами и конфигурации узлов в качестве неголосующих в сценариях геораспределенного кластера на платформе Windows Server 2008 R2. В Windows Server 2012 эта возможность, помимо выноса в графическую оболочку, еще и несколько автоматизирована. Об этом сегодня и пойдет речь - функционирование динамического кворума в кластерах на базе Windows Server 2012.
В отличие от Windows Server 2008 R2, требующего установки обновления 2494036, в Windows Server 2012 выбор голосующих узлов есть в графическом мастере конфигурации кворума
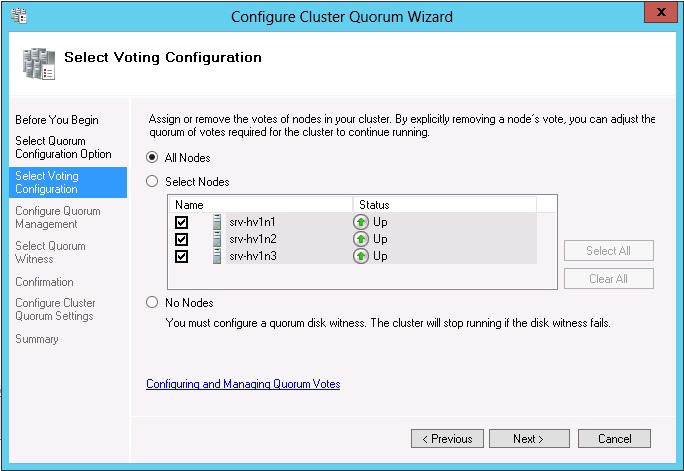
Динамический кворум кластера
Эта функция пересчитывает голосующих узлов в случае даже в случае выхода более 50% ресурсов кластера. Такие образом, концепция динамического кворума позволяет оставаться кластеру жизнеспособным при наличии хотя бы одного узла. Однако стоить отметить, что эта функция будет работать только в случае последовтельного выхода из строя узлов кластера, уже имеющего кворум, т.е. до момента аварии следующего узла служба кластера должна успеть пересчитать голосующие узлы.
Рассмотрим, как это работает на примере трехузлового кластера с моделью "Большинство узлов" и включенным динамическим кворумом
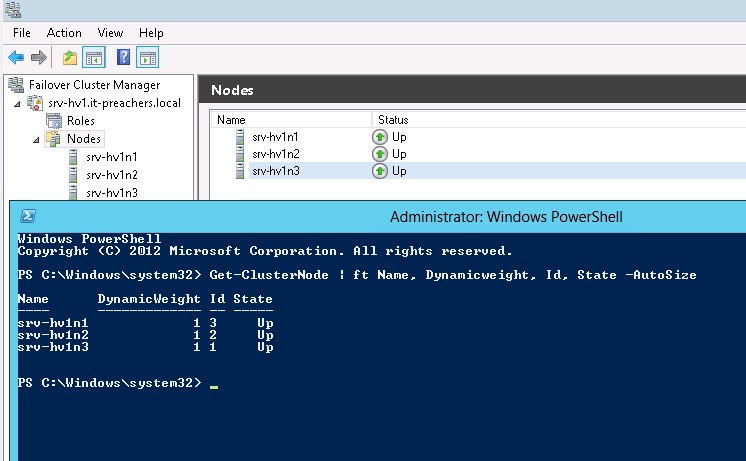
В полностью рабочем состоянии всех трех узлов с помощью командлета PowerShell Get-ClusterNode можно увидеть состояние и динамический вес серверов
Для демонстрации рекалькуляции голосов на узле srv-hv1n3 отключена служба кластера. Используя все тот же командлет, можно заметить, что у srv-hv1n2 значение DynamicWeight изменилось с 1 на 0.
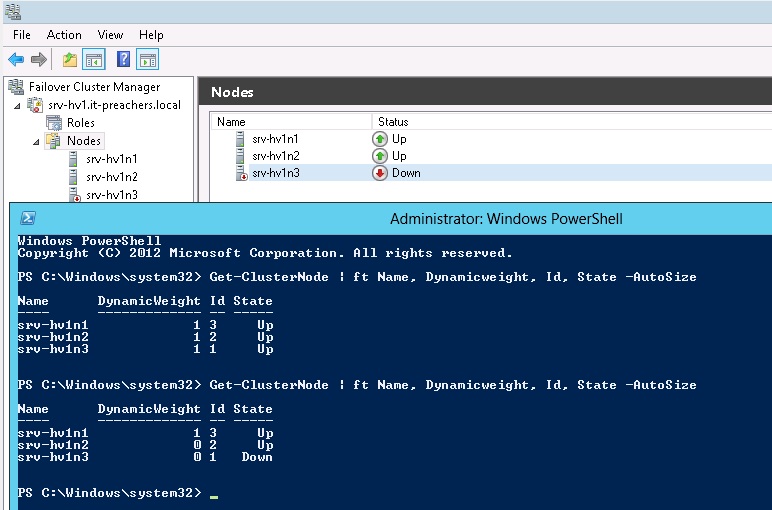
Динамическим кворумом, при понимании ситуации с выходом из строя одного из узлов, принято решение о лишении права голоса сервера с наименьшим ID. В качестве продолжения "опасного" эксперимента был выключен и второй сервер
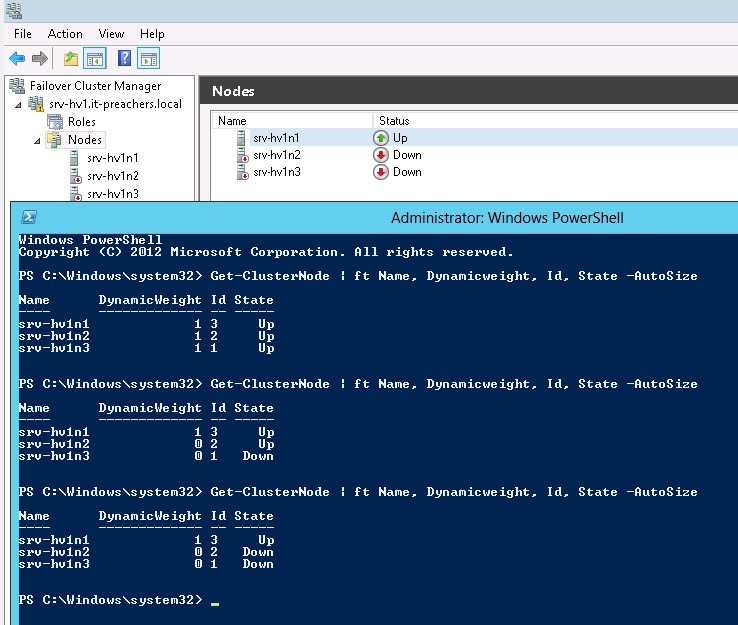
Кластер с кворумом в один голосующий узел продолжает работать. Стоить заметить еще раз, что для функционирования динамического кворума необходимо, что бы соблюдались два условия:
- Кластер должен иметь набранный кворум
- Узлы кластера выходят из строя последовательно для возможности перерасчета голосов
Comments
- Anonymous
January 01, 2003
Vital, модель разрабатывалась не для наколеночных домашних кластеров, а для промышленных многоузловых систем. Приведу простой математический рассчёт для кластеров от 16 узлов и ниже - увидим, что при количестве узлов более 10, смерть даже 80% узлов в 90% случаев не убивает кластер. Для 16 узлового кластера выход из строя последовательно:
- 8 узлов - 100% живой
- 9 узлов - 100% живой
- 10 узлов - 100% живой
- 11 узлов - 100% живой
- 12 узлов - 100% живой
- 13 узлов - 100% живой
- 14 узлов - 100% живой
- 15 узлов - 50% живой При выходе из строя 50% и более узлов кластер выживает в 93.75% случая. В отличии от 0% ранее. Для 15 узлового кластера выход из строя последовательно:
- 8 узлов - 100% живой
- 9 узлов - 100% живой
- 10 узлов - 100% живой
- 11 узлов - 100% живой
- 12 узлов - 100% живой
- 13 узлов - 100% живой
- 14 узлов - 50% живой При выходе из строя 50% и более узлов кластер выживает в 92.85% случая. В отличии от 0% ранее. Для 14 узлового кластера выход из строя последовательно:
- 7 узлов - 100% живой
- 8 узлов - 100% живой
- 9 узлов - 100% живой
- 10 узлов - 100% живой
- 11 узлов - 100% живой
- 12 узлов - 100% живой
- 13 узлов - 50% живой При выходе из строя 50% и более узлов кластер выживает в 92.85% случая. В отличии от 0% ранее. Для 13 узлового кластера выход из строя последовательно:
- 7 узлов - 100% живой
- 8 узлов - 100% живой
- 9 узлов - 100% живой
- 10 узлов - 100% живой
- 11 узлов - 100% живой
- 12 узлов - 50% живой При выходе из строя 50% и более узлов кластер выживает в 91.66% случая. В отличии от 0% ранее. ... 16 93.75% 15 92.85% 14 92.85% 13 91.66% 12 91.66% 11 90% 10 90% 9 87.5% 8 87.5% 7 83.33% 6 83.33% 5 75% 4 75% 3 50% Вспомним, что в 2012 мы делаем кластеры до 64 узлов. Там для 64 узлового кластера картинка будет 98.43% (сравнивая с 0% шансом выживания кластера в R2) Очевидно, что для трёх узлового кластера и 50% это большой шажок вперед. В промышленных внедрениях виртуализации трех-узловых кластеров я уже пару лет не встречал..
Anonymous
January 01, 2003
Еще дам дельный совет - в 2012 всегда задавайте witness disk. В этом случае для трех узлового кластера при динамическом кворуме При смерти первого узла его голос станет нулевым, два оставшихся и диск получат по единице Смерть любого узла не приведет к остановке. Доведя цифры выше до 100% во всех конфигурациях.Anonymous
January 01, 2003
В случае выхода из строя узла, являющегося хост серверов - его задачи перейдут на другие оставшиеся в живых серверы. Нулевой вес узел приобрел потому, что для поддержания кворума кластерной службой проведен перерасчет. И теперь голосующих узлов - один, а не два. В случае, если бы было их два, и один из них вышел из строя - кворума бы не было, т.к. половина голосов его не обеспечивает.Anonymous
January 01, 2003
А сколько времени тратится на перерасчёт голосов? То есть каков минимальный возможный интервал времени между выключением узлов?Anonymous
January 01, 2003
@Stanislav Buldakov - если нужны конкретные цифры - информацию уточним у разработчиков. Но в лабораторной среде весь эксперимент занял не больше минуты.Anonymous
January 01, 2003
> Нулевой вес узел приобрел потому, что для поддержания кворума кластерной службой проведен перерасчет. И теперь голосующих узлов - один, а не два. В случае, если бы было их два, и один из них вышел из строя - кворума бы не было, т.к. половина голосов его не обеспечивает. А, тут да, понятно, это я не додумал. Но получается, что в случае последовательного выхода из строя 2 из 3 серверов, вероятность для кластера выжить - всего 50%. См. ниже. > В случае выхода из строя узла, являющегося хост серверов - его задачи перейдут на другие оставшиеся в живых серверы. В данном конкретном примере тоже? Узел srv-hv1n2 (с весом 0), останься он в живых, поднимет на себе кворум кластера? А как тогда быть в ситуации потери связи между srv-hv1n1 и srv-hv1n2? Они оба решат, что они последние и оба поднимут кворумы? Мне всё же кажется, что при последовательном выходе из строя srv-hv1n3, а затем srv-hv1n1 кластер ляжет, останется в живых только srv-hv1n2 с весом 0 и будет ждать кворума. 50% вероятность выжить в случае выхода из строя 2/3 кластера, это, конечно, лучше чем ничего, но этот элемент случайности нужно понимать. Если я неправ, раскажите пожалуйста поподробнее, желательно на этом же примере, в чем.Anonymous
January 01, 2003
Большое спасибо! Теперь всё на своих местах! Что касается "промышленного внедрения" 3-нодового кластера, то если понимать этот термин просто как production (а не как автоматизацию промышленности), то не стоит сбрасывать со счетов средний бизнес (порядка 1000 работников) - на современном оборудовании таким компаниям может вполне хватать 2-4 узла на сайт.Anonymous
January 01, 2003
А если в примере вторым по счету выйдет из строя srv-hv1n1, а не srv-hv1n2, то кластер умрёт? Почему после выхода из строя одного узла у двух узлов (включая один пока ещё живой) вес стал 0, а не только у вышедшего из строя?