Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Kontrol akses terperinci memungkinkan Anda membatasi akses ke data tertentu menggunakan tampilan, filter baris, dan masker kolom. Halaman ini menjelaskan bagaimana komputasi tanpa server digunakan untuk menerapkan kontrol akses mendetail pada sumber daya komputasi khusus.
Nota
Komputasi khusus adalah komputasi semua tujuan atau pekerjaan yang dikonfigurasi dengan mode Akses khusus (sebelumnya mode akses pengguna tunggal). Lihat Mode akses.
Persyaratan
Untuk menggunakan komputasi khusus untuk mengkueri tampilan atau tabel dengan kontrol akses mendetail:
- Sumber daya komputasi khusus harus berada di Databricks Runtime 15.4 LTS atau lebih tinggi.
- Ruang kerja harus diaktifkan untuk komputasi tanpa server.
Jika sumber daya komputasi dan ruang kerja khusus Anda memenuhi persyaratan ini, maka pemfilteran data dijalankan secara otomatis.
Cara kerja pemfilteran data pada komputasi khusus
Setiap kali kueri mengakses objek database dengan kontrol akses halus, sumber daya komputasi khusus meneruskan kueri ke komputasi tanpa server ruang kerja Anda untuk melakukan pemfilteran data. Data yang difilter kemudian ditransfer antara komputasi tanpa server dan komputasi server khusus menggunakan file sementara pada penyimpanan cloud internal di dalam ruang kerja.
Azure Databricks mentransfer data yang difilter menggunakan Cloud Fetch, kemampuan yang menulis tataan hasil sementara ke penyimpanan ruang kerja internal ( akar DBFS ruang kerja Anda). Azure Databricks secara otomatis mengumpulkan file-file ini, menandainya untuk dihapus setelah 24 jam dan menghapusnya secara permanen setelah 24 jam tambahan.
Fungsionalitas ini berlaku untuk objek database berikut:
- tampilan dinamis
- Tabel dengan filter baris atau masker kolom
-
Tampilan yang dibangun di atas tabel di mana pengguna tidak memiliki
SELECThak istimewa - Tampilan materialisasi
- Tabel streaming
Dalam diagram berikut, pengguna memiliki SELECT hak istimewa pada table_1, view_2, dan table_w_rls, yang memiliki filter baris yang diterapkan. Pengguna tidak memiliki SELECT hak istimewa pada table_2, yang dirujuk oleh view_2.

Kueri pada table_1 ditangani sepenuhnya oleh sumber daya komputasi khusus, karena tidak diperlukan pemfilteran. Kueri pada view_2 dan table_w_rls memerlukan pemfilteran data untuk mengembalikan data yang dapat diakses pengguna. Kueri ini ditangani oleh kemampuan pemfilteran data pada komputasi tanpa server.
Dukungan untuk operasi penulisan
Di Databricks Runtime 16.3 ke atas, Anda dapat menulis ke tabel yang memiliki filter baris atau masker kolom yang diterapkan, menggunakan opsi berikut:
- Perintah MERGE INTO SQL, yang dapat Anda gunakan untuk mencapai fungsionalitas
INSERT,UPDATE, danDELETE. - Operasi penggabungan Delta.
- API
DataFrame.write.mode("append").
Untuk mencapai fungsionalitas INSERT, UPDATE, dan DELETE, Anda dapat menggunakan tabel penahapan dan pernyataan MERGE INTO serta klausa WHEN MATCHED dan WHEN NOT MATCHED.
Berikut ini adalah contoh UPDATE menggunakan MERGE INTO.
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET
t.column1 = s.column1,
t.column2 = s.column2;
Berikut ini adalah contoh INSERT menggunakan MERGE INTO.
MERGE INTO target_table AS t
USING source_table AS s
ON t.id = s.id
WHEN NOT MATCHED THEN
INSERT (id, column1, column2) VALUES (s.id, s.column1, s.column2);
Berikut ini adalah contoh DELETE menggunakan MERGE INTO:
MERGE INTO target_table AS t
USING source_table AS s ON t.id = s.id
WHEN MATCHED AND s.some_column = TRUE THEN DELETE;
Dukungan untuk perintah DDL, SHOW, DESCRIBE, dan lainnya
Dalam Databricks Runtime 17.1 ke atas, Anda dapat menggunakan perintah berikut dalam kombinasi dengan objek yang dikontrol akses terperinci pada komputasi khusus:
- Pernyataan DDL
- Pernyataan SHOW
- Pernyataan DESCRIBE
- OPTIMIZE
- DESCRIBE HISTORY
- FSCK REPAIR TABLE (Databricks Runtime 17.2 ke atas)
Jika diperlukan, perintah ini secara otomatis berjalan pada komputasi tanpa server.
Beberapa perintah tidak didukung, termasuk VACCUM, RESTORE, dan REORG TABLE.
Biaya komputasi tanpa server
Pelanggan dikenakan biaya untuk sumber daya komputasi tanpa server yang melakukan operasi pemfilteran data. Untuk informasi harga, lihat Tingkat Platform dan Tambahan.
Pengguna dengan akses dapat mengkueri system.billing.usage tabel untuk melihat berapa banyak mereka telah ditagih. Misalnya, kueri berikut memecah biaya komputasi berdasarkan pengguna:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Menampilkan performa kueri saat pemfilteran data terlibat
Antarmuka pengguna Spark untuk komputasi khusus menampilkan metrik yang dapat Anda gunakan untuk memahami performa kueri Anda. Untuk setiap kueri yang Anda jalankan pada sumber daya komputasi, tab SQL/Dataframe menampilkan representasi grafik kueri. Jika kueri terlibat dalam pemfilteran data, UI menampilkan simpul operator RemoteSparkConnectScan di bagian bawah grafik. Simpul tersebut menampilkan metrik yang bisa Anda gunakan untuk menyelidiki performa kueri. Lihat Menampilkan informasi komputasi di antarmuka pengguna Spark.
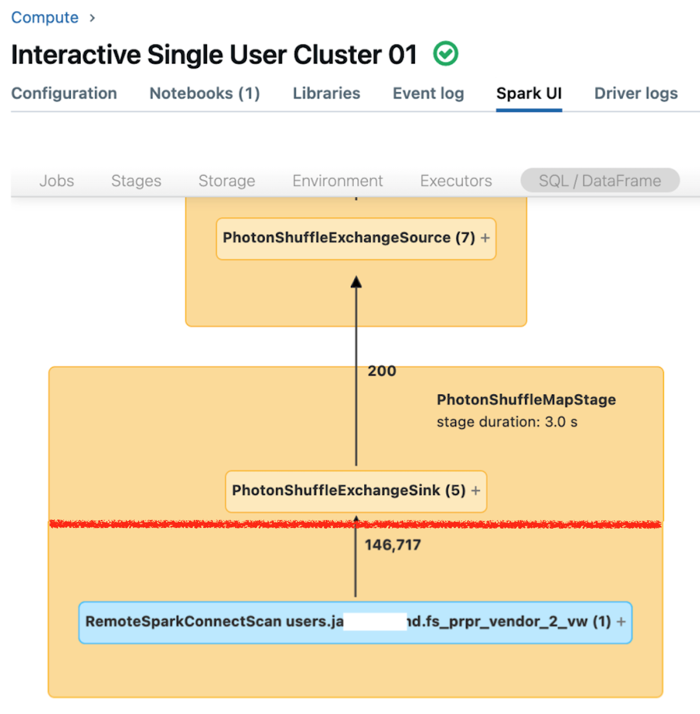
Perluas simpul operator RemoteSparkConnectScan untuk melihat metrik yang membahas pertanyaan seperti berikut:
- Berapa lama waktu yang dibutuhkan pemfilteran data? Lihat "total waktu eksekusi jarak jauh."
- Berapa banyak baris yang tersisa setelah pemfilteran data? Lihat "keluaran baris."
- Berapa banyak data (dalam byte) yang dikembalikan setelah pemfilteran data? Lihat "ukuran output baris."
- Berapa banyak file data yang dipangkas partisi dan tidak perlu dibaca dari penyimpanan? Lihat "File yang dipangkas" dan "Ukuran file yang dipangkas."
- Berapa file data yang tidak dapat dipangkas dan harus dibaca dari penyimpanan? Lihat "File dibaca" dan "Ukuran file yang dibaca."
- Dari file yang harus dibaca, berapa banyak yang sudah ada di cache? Lihat "Ukuran hit cache" dan "Cache melewatkan ukuran."
Batasan
Hanya pembacaan batch yang didukung pada tabel streaming. Tabel dengan filter baris atau masker kolom tidak mendukung beban kerja streaming pada komputasi khusus.
Katalog default (
spark.sql.catalog.spark_catalog) tidak dapat dimodifikasi.spark.catalog.listColumns()tidak didukung. Sebagai gantinya, Anda bisa menggunakanSHOW COLUMNS INuntuk mencantumkan nama kolom,SHOW PARTITIONSuntuk mencantumkan kolom partisi, atauDESCRIBE TABLE [EXTENDED [AS JSON]]untuk mendapatkan deskripsi tabel terperinci.Di Databricks Runtime 16.2 ke bawah, tidak ada dukungan untuk operasi tulis atau refresh tabel pada tabel yang menerapkan filter baris atau masker kolom.
Secara khusus, operasi DML, seperti
INSERT, ,DELETEUPDATE,REFRESH TABLE, danMERGE, tidak didukung. Anda hanya dapat membaca (SELECT) dari tabel ini.Dalam Databricks Runtime 16.3 ke atas, operasi tulis tabel seperti
INSERT,DELETE, danUPDATEtidak didukung, tetapi dapat dilakukan menggunakanMERGE, yang didukung.Saat menggunakan
DeltaTable.forName()atauDeltaTable.forPath()pada komputasi khusus dengan tabel berkemampuan FGAC, hanya operasimerge()dantoDF()yang didukung. Untuk operasi DeltaTable lainnya, gunakan perintah SQL yang sesuai sebagai gantinya. Misalnya, alih-alihhistory(), gunakanDESCRIBE HISTORYdan alih-alihclone(), gunakanSHALLOW CLONEatauDEEP CLONE.Di Databricks Runtime 16.2 dan versi sebelumnya, self-join diblokir secara default saat pemfilteran data diterapkan karena kueri ini mungkin mengembalikan cuplikan yang berbeda dari tabel yang sama di lokasi jauh. Namun, Anda dapat mengaktifkan kueri ini dengan mengatur
spark.databricks.remoteFiltering.blockSelfJoinskefalsepada komputasi tempat Anda menjalankan perintah ini.Di Databricks Runtime 16.3 ke atas, rekam jepret secara otomatis disinkronkan antara sumber daya komputasi khusus dan tanpa server. Karena sinkronisasi ini, kueri gabungan mandiri yang menggunakan fungsionalitas pemfilteran data mengembalikan rekam jepret yang identik dan diaktifkan secara default. Pengecualian adalah tampilan dan tabel streaming yang dibagikan menggunakan Delta Sharing, termasuk tampilan materialisasi. Untuk objek ini, gabungan mandiri diblokir secara default, tetapi Anda dapat mengaktifkan kueri ini dengan mengatur
spark.databricks.remoteFiltering.blockSelfJoinske false pada komputasi tempat Anda menjalankan perintah ini.Jika Anda mengaktifkan kueri gabungan mandiri untuk tampilan materialisasi dan tampilan apa pun, tampilan materialisasi, dan tabel streaming, Anda harus memastikan bahwa tidak ada penulisan bersamaan ke objek yang digabungkan.
- Tidak ada dukungan pada gambar Docker.
- Tidak ada dukungan saat menggunakan Layanan Kontainer Databricks.
- Anda harus membuka port 8443 dan 8444 untuk mengaktifkan kontrol akses halus pada komputasi khusus. Lihat Menyebarkan Azure Databricks di jaringan virtual Azure Anda (injeksi VNet).