Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Halaman ini menjelaskan cara menggunakan Klasifikasi Databricks di Unity Catalog untuk mengklasifikasikan dan menandai data sensitif secara otomatis di katalog Anda.
Katalog data dapat memiliki sejumlah besar data, sering berisi data sensitif yang diketahui dan tidak diketahui. Sangat penting bagi tim data untuk memahami jenis data sensitif apa yang ada di setiap tabel sehingga mereka dapat mengatur dan mendemokratisasi akses ke data ini.
Untuk mengatasi masalah ini, Klasifikasi Databricks Data menggunakan agen AI untuk mengklasifikasikan dan menandai tabel secara otomatis di katalog Anda. Ini memungkinkan Anda menemukan data sensitif dan menerapkan kontrol tata kelola atas hasilnya, menggunakan alat seperti kontrol akses berbasis Atribut di Unity Catalog. Untuk daftar tag yang didukung, lihat Tag klasifikasi yang didukung.
Dengan fitur ini, Anda dapat:
- Mengklasifikasikan data: Mesin menggunakan sistem AI agenik untuk mengklasifikasikan dan menandai tabel apa pun secara otomatis di Katalog Unity.
- Optimalkan biaya melalui pemindaian cerdas: Sistem secara cerdas menentukan kapan harus memindai data Anda dengan memanfaatkan Katalog Unity dan Mesin Kecerdasan Data. Ini berarti bahwa pemindaian bertahap dan dioptimalkan untuk memastikan semua data baru diklasifikasikan tanpa konfigurasi manual.
- Tinjau dan lindungi data sensitif: Tampilan hasil membantu Anda melihat hasil klasifikasi dan melindungi data sensitif dengan menandai dan membuat kebijakan kontrol akses untuk setiap kelas.
Penting
Klasifikasi Databricks menggunakan penyimpanan default untuk menyimpan hasil klasifikasi. Anda tidak ditagih atas penyimpanan.
Klasifikasi Databricks menggunakan model bahasa besar (LLM) untuk membantu klasifikasi.
Persyaratan
Nota
Klasifikasi data adalah fitur pratinjau tingkat ruang kerja, dan hanya dapat dikelola oleh admin ruang kerja atau akun. Untuk petunjuknya, lihat Kelola pratinjau Azure Databricks.
- Ruang kerja Anda harus memiliki komputasi tanpa server yang tersedia (diaktifkan secara default di ruang kerja dengan Katalog Unity).
- Untuk mengaktifkan klasifikasi data, Anda harus memiliki katalog atau memiliki
USE CATALOGMANAGEhak istimewa di dalamnya. - Untuk mengaktifkan pemberian tag otomatis untuk katalog, Anda harus memiliki
USE CATALOGpada katalog,APPLY TAGpada katalog, danASSIGNpada tag yang diterapkan. - Untuk melihat hasil klasifikasi di UI, Anda harus memiliki
USE CATALOGdanMANAGEatau (SELECT+USE SCHEMA) pada katalog. Untuk melihat nilai sampel yang terkait dengan deteksi, Anda harus memilikiSELECTpada tabel Sistem hasil.
Nota
Secara bawaan, hanya admin akun yang memiliki perizinan MANAGE dan ASSIGN pada tag yang diatur oleh sistem klasifikasi data. Admin akun dapat memberikan MANAGE dan ASSIGN untuk tag yang dikelola secara individual kepada pengguna lain, perwakilan layanan, atau grup. Lihat Mengelola izin pada tag yang diatur.
Menggunakan klasifikasi data
Anda dapat mengaktifkan klasifikasi data untuk beberapa katalog sekaligus dari halaman hasil, atau mengonfigurasi katalog individual dengan kontrol tingkat skema yang lebih terperinci.
Mengaktifkan beberapa katalog
- Pada halaman hasil Klasifikasi Data, klik Konfigurasikan.
- Pilih katalog yang ingin Anda aktifkan, atau pilih semua katalog yang tersedia di ruang kerja.
- Klik Aktifkan.
Mengaktifkan semua katalog yang tersedia tidak secara otomatis mengaktifkan katalog di masa mendatang. Untuk mengklasifikasikan katalog baru, kembali ke dialog Konfigurasikan dan aktifkan.
Mengaktifkan satu katalog dengan pilihan skema
Untuk memilih skema tertentu dalam katalog:
Navigasi ke katalog dan klik tab Detail .
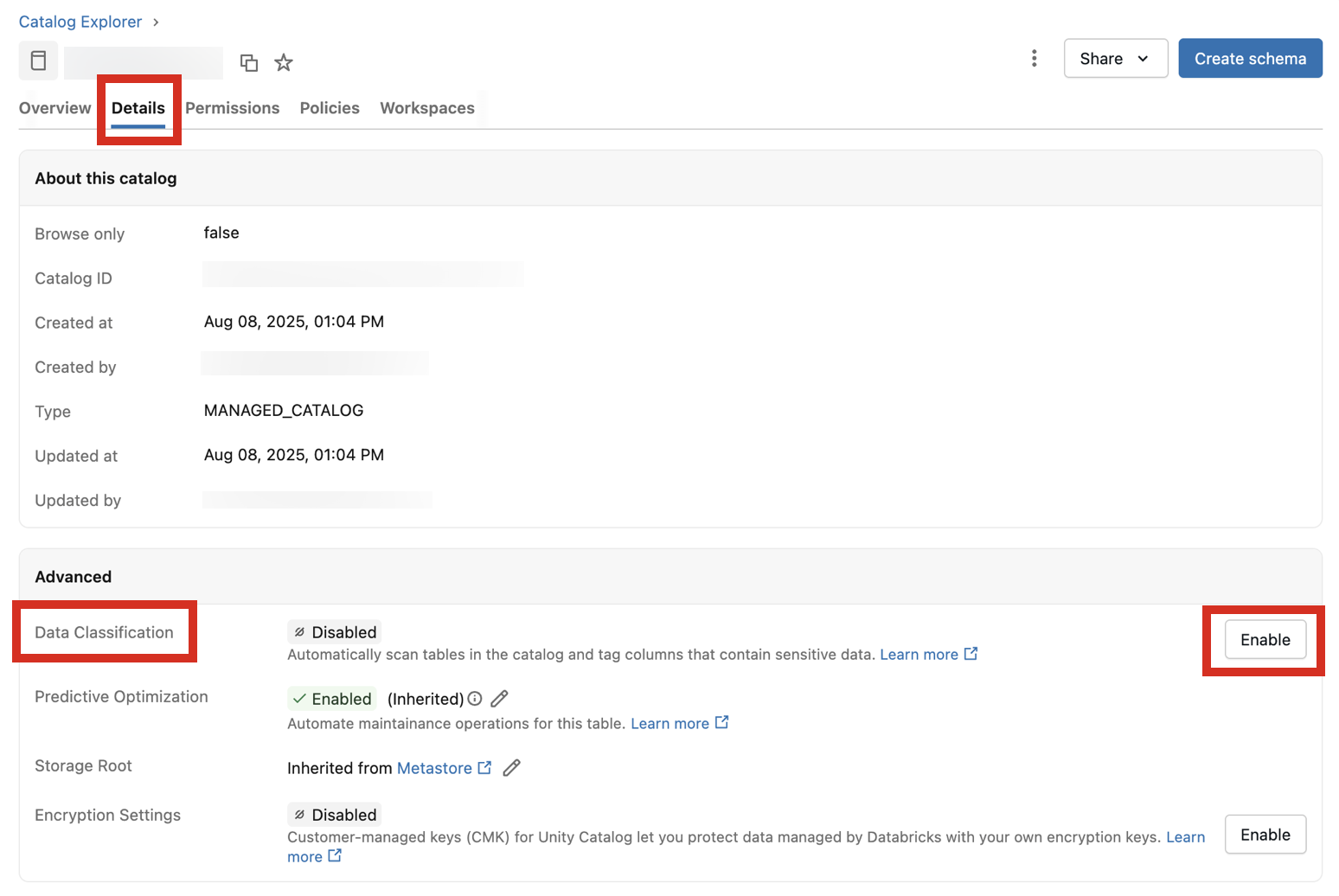
Di samping Klasifikasi Data, klik tombol Aktifkan .
Dialog Klasifikasi Data muncul. Secara default, semua skema disertakan. Untuk menyertakan hanya beberapa skema, pilih skema tersebut di menu dropdown Skema untuk disertakan . Anda juga dapat memilih Kebijakan penggunaan
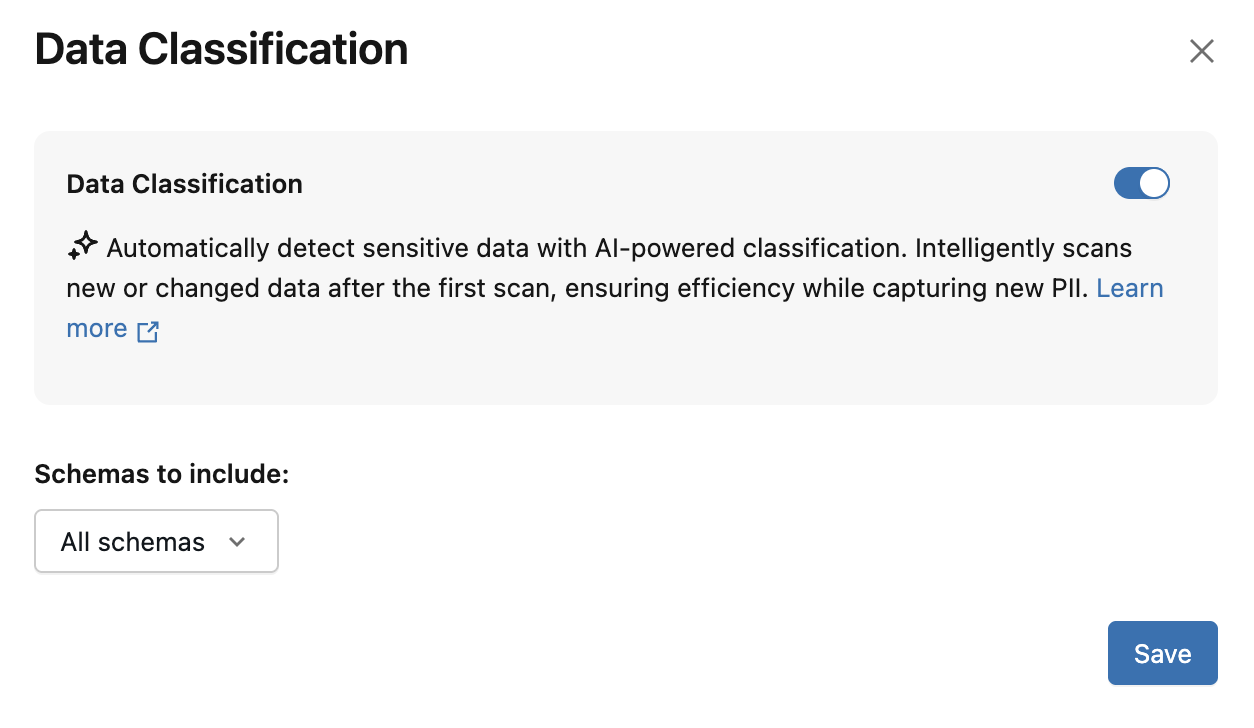
Kliklah Simpan.
Ini membuat pekerjaan latar belakang yang secara bertahap memindai semua tabel dalam katalog atau skema yang dipilih.
Mesin klasifikasi bergantung pada pemindaian cerdas untuk menentukan kapan harus memindai tabel. Tabel dan kolom baru dalam katalog biasanya dipindai dalam waktu 24 jam setelah dibuat.
Melihat hasil klasifikasi
Untuk melihat hasil klasifikasi, klik Tampilkan hasil di samping pengaturan Klasifikasi Data .
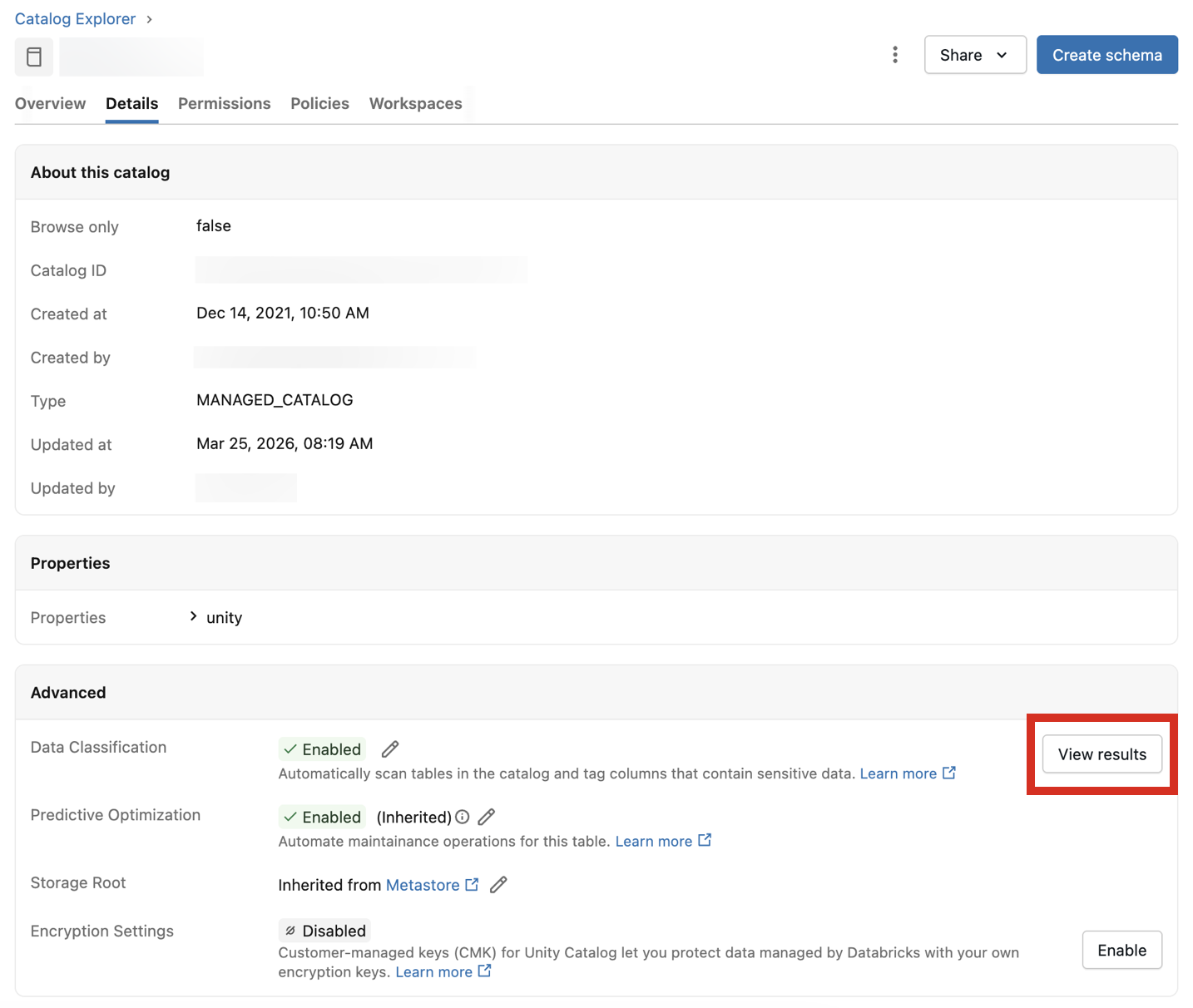
Ini membuka UI Klasifikasi Data untuk katalog. Untuk melihat hasil klasifikasi, gudang SQL tanpa server diperlukan.
Anda juga dapat melihat hasil agregat di semua katalog terklasifikasi di metastore dengan menggunakan pemilih katalog di kiri atas. Pilih Semua katalog dari menu drop-down.
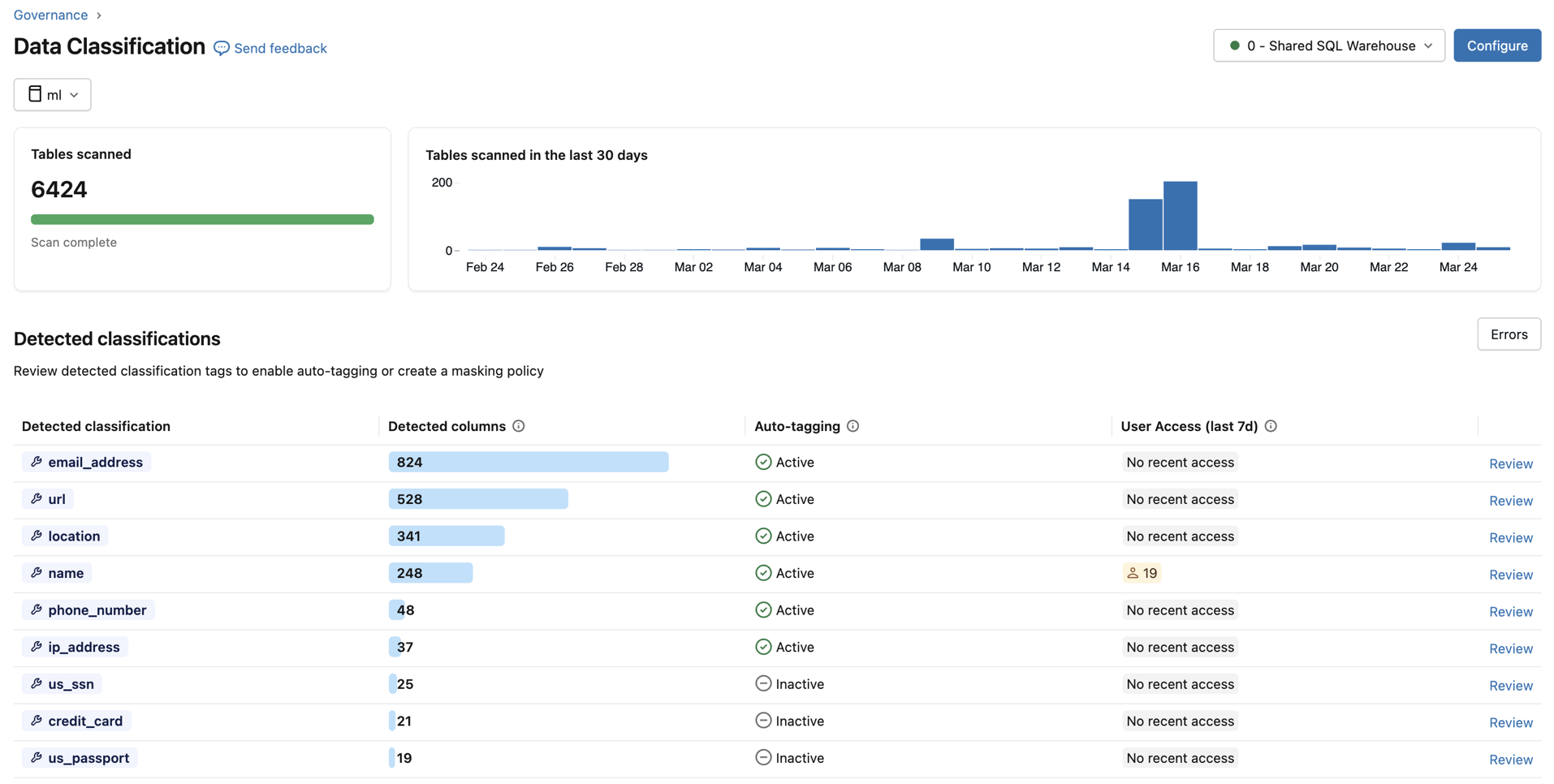
Untuk setiap jenis klasifikasi, tabel menunjukkan:
- Kolom yang terdeteksi: Jumlah kolom tempat klasifikasi terdeteksi.
- Penandaan otomatis: Status pemberian tag untuk klasifikasi tersebut — Aktif atau Tidak Aktif. Dalam tampilan metastore, status Sebagian Aktif menunjukkan bahwa pemberian tag diaktifkan di beberapa tetapi tidak semua katalog.
- Akses Pengguna (7d terakhir): Jumlah pengguna berbeda yang mengakses data yang tidak ditutupi vs. data yang ditutupi dari klasifikasi tersebut selama 7 hari terakhir. Gunakan ini untuk menilai paparan data sensitif di seluruh organisasi Anda.
Meninjau deteksi
Untuk meninjau hasil untuk jenis klasifikasi tertentu, klik Tinjau di kolom paling kanan. Panel muncul dengan dua tab:
- Kolom terdeteksi: Menampilkan kolom tempat tag klasifikasi terdeteksi dengan keyakinan tinggi, diurutkan berdasarkan deteksi terbaru terlebih dahulu. Juga menyertakan bagan Deteksi dari waktu ke waktu dan daftar kolom yang terdeteksi dengan nilai sampel. Klik bilah apa pun di bagan untuk melihat deteksi tertentu untuk tanggal tersebut. Nilai sampel hanya muncul jika Anda memiliki izin yang diperlukan untuk melihat hasil klasifikasi.
- Akses Pengguna: Mencantumkan semua pengguna yang mengakses kolom dengan tag klasifikasi ini, memperlihatkan email dan nama pengguna mereka bersama dengan apakah mereka memiliki akses terbatas atau tidak terbatas. Juga menunjukkan kebijakan kontrol akses berbasis atribut (ABAC) yang ditetapkan ke tag klasifikasi ini. Saat melihat hasil untuk satu katalog, Anda dapat membuat kebijakan ABAC baru langsung dari panel.
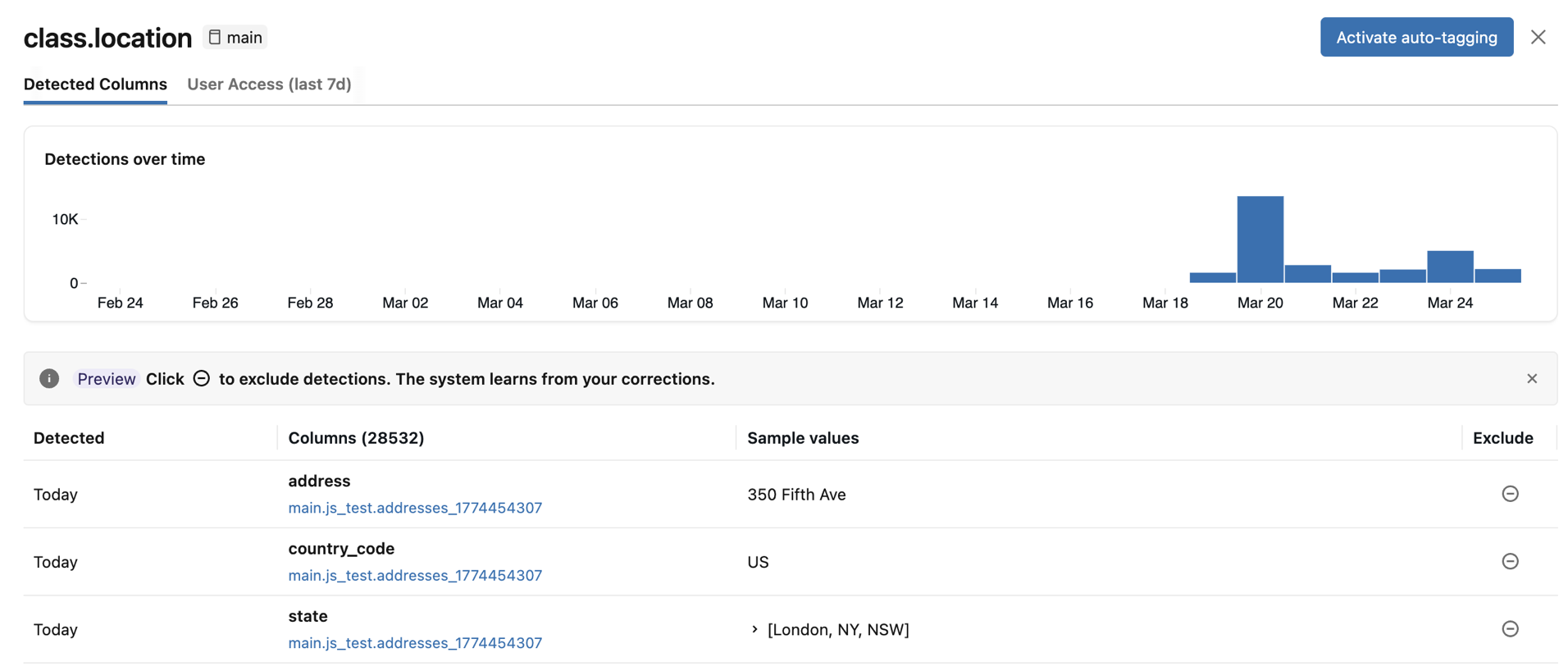
Jika ada kolom yang terdeteksi salah, Anda dapat mengklik ikon Kecualikan di sebelah kanan entri. Lihat Mengecualikan deteksi.
Aktifkan pemberian tag otomatis
Jika kolom yang diidentifikasi sesuai dengan harapan Anda, Anda dapat mengaktifkan pemberian tag otomatis untuk tag klasifikasi. Saat pemberian tag otomatis diaktifkan, semua deteksi klasifikasi ini yang ada dan di masa mendatang ditandai.
Anda dapat mengonfigurasi pemberian tag otomatis pada dua tingkat:
-
Tingkat metastore: Aktifkan atau nonaktifkan fungsi ini di semua katalog sekaligus. Anda harus menjadi admin metastore dan memiliki
ASSIGNtag yang diterapkan. -
Tingkat katalog: Aktifkan atau nonaktifkan untuk katalog saat ini saja. Pengaturan tingkat katalog lebih diutamakan daripada pengaturan tingkat metastore. Anda harus memiliki
USE CATALOGdanAPPLY TAGpada katalog, danASSIGNpada tag yang diterapkan.
Pada tingkat katalog, pemberian tag otomatis memiliki tiga status:
- Default (diwariskan): Katalog mewarisi pengaturan pemberian tag dari tingkat metastore.
- Aktif: Pemberian tag diaktifkan secara eksplisit untuk katalog ini, terlepas dari pengaturan tingkat metastore.
- Tidak aktif: Pemberian tag secara eksplisit dinonaktifkan untuk katalog ini, terlepas dari pengaturan tingkat metastore.
Saat Anda menonaktifkan pemberian tag, tidak ada tag mendatang yang diterapkan, tetapi tag yang ada tidak dihapus.
Nota
Saat Anda mengaktifkan pemberian tag otomatis, tag tidak segera diisi ulang. Data akan terisi pada pemindaian berikutnya, dan perubahan ini akan berlaku dalam waktu 24 jam. Klasifikasi berikutnya akan segera diberikan label.
Mengecualikan deteksi
Penting
Pengecualian deteksi beserta penggunaannya untuk meningkatkan akurasi klasifikasi ke depan berada di Beta.
Di panel ulasan, Anda dapat mengecualikan deteksi kolom individual. Tidak termasuk deteksi:
- Menghapus tag klasifikasi yang ada dari kolom tersebut.
- Mencegah pemindaian di masa depan untuk menerapkan kembali tag ke kolom tersebut.
- Memberikan umpan balik yang meningkatkan akurasi hasil klasifikasi di masa mendatang.
Untuk mengecualikan deteksi, klik ikon Kecualikan untuk kolom terkait di panel tinjauan. Untuk menyertakan kembali deteksi, klik ikon lagi.
Tabel sistem hasil
Klasifikasi data membuat tabel sistem bernama system.data_classification.results untuk menyimpan hasil yang secara default hanya dapat diakses oleh admin akun. Admin akun dapat berbagi tabel ini. Tabel hanya dapat diakses saat Anda menggunakan komputasi tanpa server. Untuk detail tentang tabel ini, lihat Referensi tabel sistem klasifikasi data.
Penting
Tabel system.data_classification.results hasil berisi semua hasil klasifikasi di seluruh metastore dan menyertakan nilai sampel dari tabel di setiap katalog. Anda hanya boleh berbagi tabel ini dengan pengguna yang memiliki hak istimewa untuk melihat hasil klasifikasi di seluruh metastore, termasuk nilai sampel.
Pengguna dengan SELECT akses ke tabel ini juga dapat melihat nilai sampel yang terkait dengan deteksi di halaman hasil Klasifikasi Data.
Menyiapkan kontrol tata kelola berdasarkan hasil klasifikasi data
Menutupi data sensitif menggunakan kebijakan ABAC
Databricks merekomendasikan penggunaan kontrol akses berbasis Atribut di Unity Catalog untuk membuat kontrol tata kelola berdasarkan hasil klasifikasi data.
Untuk membuat kebijakan dari halaman hasil Klasifikasi Data, klik Tinjau untuk tag klasifikasi, buka tab Akses Pengguna , dan klik Kebijakan baru. Formulir kebijakan telah diisi sebelumnya untuk menutupi kolom dengan tag klasifikasi yang sedang ditinjau. Untuk menutupi data, tentukan fungsi masking apa pun yang terdaftar di Unity Catalog dan klik Simpan.
Anda juga dapat membuat kebijakan yang mencakup beberapa tag klasifikasi, dengan mengubah Kolom saatmemenuhi kondisi dan menyediakan beberapa tag.
Misalnya, untuk membuat kebijakan yang disebut "Rahasia" yang menutupi nama, email, atau nomor telepon apa pun, atur memenuhi kondisi ke has_tag("class.name") OR has_tag("class.email_address") OR has_tag("class.phone_number").
Penemuan dan penghapusan GDPR
Contoh buku catatan ini memperlihatkan bagaimana Anda bisa menggunakan klasifikasi data untuk membantu penemuan dan penghapusan data untuk kepatuhan GDPR.
Penemuan dan penghapusan GDPR menggunakan notebook klasifikasi data
Cara menangani tag yang salah
Jika klasifikasi salah, kecualikan deteksi dari panel tinjauan. Mengecualikan sebuah deteksi menghapus tag, mencegahnya diterapkan kembali, dan meningkatkan akurasi pemindaian di masa mendatang. Lihat Mengecualikan deteksi.
Kesalahan pemindaian
Jika terjadi kesalahan selama pemindaian, tombol Kesalahan muncul di kanan atas tabel hasil.
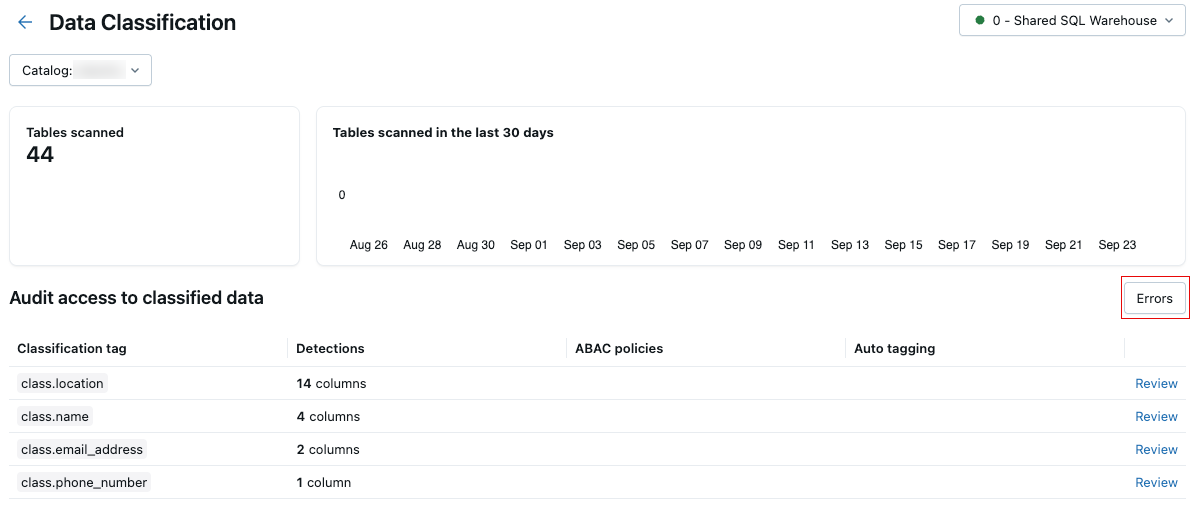
Klik tombol untuk menampilkan tabel yang gagal memindai dan pesan kesalahan terkait.

Secara default, kegagalan yang terjadi untuk tabel individual dilewati dan dicoba kembali pada hari berikutnya.
Melihat pengeluaran Klasifikasi Data
Untuk memahami bagaimana Klasifikasi Data dikenakan biaya, lihat halaman harga. Anda dapat melihat pengeluaran yang terkait dengan Klasifikasi Data baik dengan menjalankan kueri atau menampilkan dasbor penggunaan.
Nota
Pemindaian awal lebih mahal daripada pemindaian berikutnya pada katalog yang sama, karena pemindaian tersebut inkremental dan biasanya menimbulkan biaya yang lebih rendah.
Menampilkan penggunaan dari tabel sistem system.billing.usage
Anda dapat memeriksa biaya Klasifikasi Data dari system.billing.usage. Bidang created_by dan catalog_id dapat digunakan secara opsional untuk memecah biaya:
-
created_by: Sertakan untuk melihat biaya yang dikenakan oleh pengguna yang memulai penggunaan. -
catalog_id: Sertakan untuk melihat biaya menurut katalog. ID katalog ditampilkan dalamsystem.data_classification.resultstabel.
Contoh kueri selama 30 hari terakhir:
SELECT
usage_date,
identity_metadata.created_by,
usage_metadata.catalog_id,
SUM(usage_quantity) AS dbus
FROM
system.billing.usage
WHERE
usage_date >= DATE_SUB(CURRENT_DATE(), 30)
AND billing_origin_product = 'DATA_CLASSIFICATION'
GROUP BY
usage_date,
created_by,
catalog_id
ORDER BY
usage_date DESC,
created_by;
Untuk menghitung total biaya dalam dolar, gabungkan dengan system.billing.list_prices. Contoh kueri berikut menggunakan parameter bernama :add_on_rate sebagai pengali pada harga terdaftar. Atur ke 1 untuk menggunakan harga daftar secara langsung, atau ke nilai yang kurang dari 1 untuk mencerminkan diskon yang dinegosiasikan (misalnya, 0.9 untuk diskon 10%).
Contoh kueri untuk total biaya dolar selama 30 hari terakhir:
SELECT
u.usage_date,
SUM(u.usage_quantity * lp.pricing.effective_list.default) * :add_on_rate
AS `Data Classification Dollar Cost`
FROM system.billing.usage AS u
JOIN system.billing.list_prices AS lp
ON lp.sku_name = u.sku_name
WHERE
u.billing_origin_product = 'DATA_CLASSIFICATION'
AND u.usage_end_time >= lp.price_start_time
AND (lp.price_end_time IS NULL OR u.usage_end_time < lp.price_end_time)
AND u.usage_date >= DATE_ADD(CURRENT_DATE(), -30)
GROUP BY
u.usage_date
ORDER BY
u.usage_date DESC;
Menampilkan penggunaan dari dasbor laporan
Jika Anda sudah memiliki dasbor penggunaan yang dikonfigurasi di ruang kerja, Anda dapat menggunakannya untuk memfilter penggunaan dengan memilih Proyek Asal Penagihan berlabel 'Klasifikasi Data.' Jika Anda tidak memiliki dasbor penggunaan yang dikonfigurasi, Anda dapat mengimpornya dan menerapkan pemfilteran yang sama. Untuk detailnya, lihat Dasbor penggunaan.
Tag klasifikasi yang didukung
Untuk daftar lengkap tag yang didukung yang diatur oleh tag global, tag regional, dan kerangka kerja kepatuhan (PII, GDPR, HIPAA, DPDPA), lihat Tag klasifikasi yang didukung.
Keterbatasan
- Tampilan dan tampilan metrik tidak didukung. Jika tampilan didasarkan pada tabel yang ada, Databricks merekomendasikan untuk mengklasifikasikan tabel yang mendasar untuk melihat apakah tabel tersebut berisi data sensitif.