Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Databricks merekomendasikan penggunaan MLflow 3 untuk mengevaluasi dan memantau aplikasi GenAI. Halaman ini menjelaskan Evaluasi Agen MLflow 2.
- Untuk pengenalan evaluasi dan pemantauan pada MLflow 3, lihat Mengevaluasi dan memantau agen AI.
- Untuk informasi tentang migrasi ke MLflow 3, lihat Migrasi ke MLflow 3 dari Evaluasi Agen.
- Untuk informasi MLflow 3 tentang topik ini, lihat Tutorial: Mengevaluasi dan meningkatkan aplikasi GenAI.
Artikel ini menjelaskan cara menjalankan evaluasi dan melihat hasilnya saat Anda mengembangkan aplikasi AI Anda. Untuk informasi tentang cara memantau agen yang telah diterapkan, lihat Memantau aplikasi GenAI pada masa produksi.
Untuk mengevaluasi agen, Anda harus menentukan kumpulan evaluasi. Paling tidak, sekumpulan permintaan evaluasi adalah set permintaan ke aplikasi Anda yang dapat berasal dari serangkaian permintaan evaluasi yang dikumpulkan, atau jejak interaksi dari pengguna agen. Untuk detail selengkapnya, lihat Set evaluasi (MLflow 2) dan skema input Evaluasi Agen (MLflow 2).
Menjalankan evaluasi
Untuk menjalankan evaluasi, gunakan metode mlflow.evaluate() dari API MLflow, yang menentukan model_type sebagai databricks-agent untuk mengaktifkan Evaluasi Agen pada Databricks dan hakim AI bawaan.
Contoh berikut menentukan serangkaian pedoman respons global untuk pedoman global hakim AI yang menyebabkan evaluasi gagal ketika respons tidak mematuhi pedoman. Anda tidak perlu mengumpulkan label per permintaan untuk mengevaluasi agen Anda dengan pendekatan ini.
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = {
"rejection": ["If the request is unrelated to Databricks, the response must should be a rejection of the request"],
"conciseness": ["If the request is related to Databricks, the response must should be concise"],
"api_code": ["If the request is related to Databricks and question about API, the response must have code"],
"professional": ["The response must be professional."]
}
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
Hasil tersedia di tab Jejak di halaman Eksekusi MLflow:
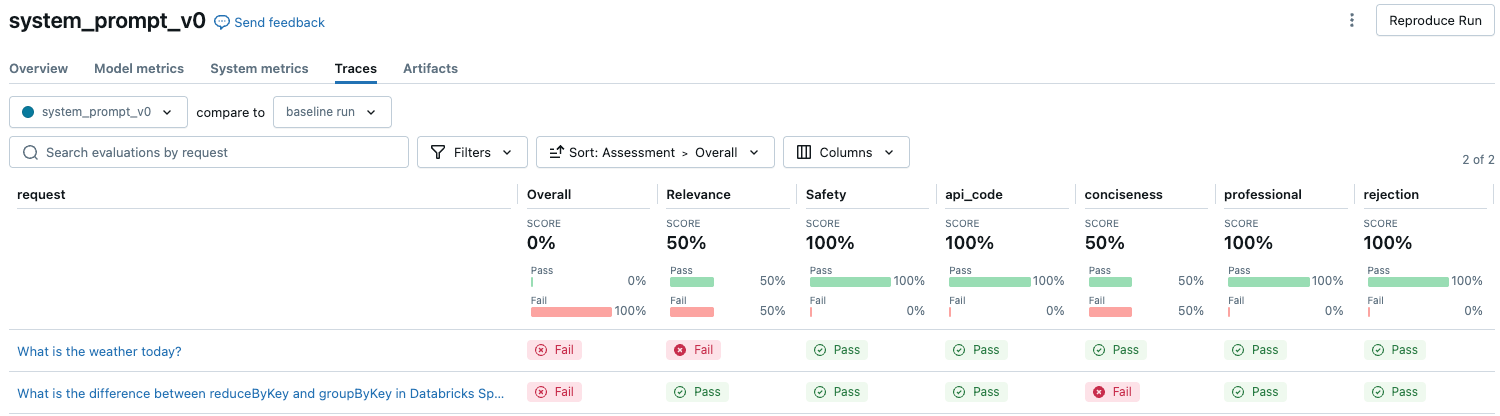
Contoh ini menjalankan penilaian berikut yang tidak memerlukan label kebenaran dasar: Kepatuhan terhadap pedoman, Relevansi terhadap kueri, Keamanan.
Jika Anda menggunakan agen dengan retriever, maka pengujian berikut dijalankan: Groundedness, Chunk relevance
mlflow.evaluate() juga menghitung latensi dan metrik biaya untuk setiap catatan evaluasi, menggabungkan hasil dari semua input untuk suatu run tertentu. Ini disebut sebagai hasil evaluasi. Hasil evaluasi dicatat dalam eksekusi penutup, bersama dengan informasi yang dicatat oleh perintah lain seperti parameter model. Jika Anda memanggil mlflow.evaluate() di luar percobaan MLflow, percobaan baru akan dibuat.
Evaluasi dengan label kebenaran dasar
Contoh berikut menentukan label kebenaran dasar per baris: expected_facts dan guidelines yang akan menjalankan hakim kebenaran dan pedoman masing-masing. Evaluasi individual diperlakukan secara terpisah menggunakan label kebenaran dasar per baris.
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
Contoh ini menjalankan hakim yang sama seperti di atas, selain yang berikut: Kebenaran, Relevansi, Keamanan
Jika Anda menggunakan agen dengan retriever, penilaian berikut dijalankan: Kecukupan konteks
Persyaratan
Fitur AI yang didukung mitra harus diaktifkan untuk ruang kerja Anda.
Menyediakan input untuk pelaksanaan evaluasi
Ada dua cara untuk memberikan masukan dalam pelaksanaan evaluasi:
Berikan output yang dihasilkan sebelumnya untuk dibandingkan dengan kumpulan evaluasi. Opsi ini direkomendasikan jika Anda ingin mengevaluasi output dari aplikasi yang sudah disebarkan ke produksi, atau jika Anda ingin membandingkan hasil evaluasi antara konfigurasi evaluasi.
Dengan opsi ini, Anda menentukan kumpulan evaluasi seperti yang ditunjukkan dalam kode berikut. Kumpulan evaluasi harus menyertakan output yang dihasilkan sebelumnya. Untuk contoh yang lebih rinci, lihat Contoh: Cara meneruskan output yang dihasilkan sebelumnya ke Evaluasi Agen.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Berikan aplikasi sebagai argumen input.
mlflow.evaluate()memanggil aplikasi untuk setiap input dalam set evaluasi dan melaporkan penilaian kualitas dan metrik lainnya untuk setiap output yang dihasilkan. Opsi ini direkomendasikan jika aplikasi Anda dicatat menggunakan MLflow dengan MLflow Tracing diaktifkan, atau jika aplikasi Anda diimplementasikan sebagai fungsi Python dalam buku catatan. Opsi ini tidak disarankan jika aplikasi Anda dikembangkan di luar Databricks atau disebarkan di luar Databricks.Dengan opsi ini, Anda menentukan kumpulan evaluasi dan aplikasi dalam panggilan fungsi seperti yang ditunjukkan dalam kode berikut. Untuk contoh yang lebih rinci, lihat Contoh: Cara meneruskan aplikasi ke Evaluasi Agen.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Untuk detail tentang skema set evaluasi, lihat Skema input Evaluasi Agen (MLflow 2).
Evaluasi output
Evaluasi Agen mengembalikan outputnya dari mlflow.evaluate() sebagai dataframe dan juga merekam output ini ke run MLflow. Anda dapat memeriksa output di notebook atau dari halaman eksekusi MLflow yang sesuai.
Meninjau output di buku catatan
Kode berikut ini memperlihatkan beberapa contoh cara meninjau hasil evaluasi yang dijalankan dari buku catatan Anda.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Kerangka data per_question_results_df mencakup semua kolom dalam skema input dan semua hasil evaluasi khusus untuk setiap permintaan. Untuk detail selengkapnya tentang hasil komputasi, lihat Bagaimana kualitas, biaya, dan latensi dinilai oleh Evaluasi Agen (MLflow 2).
Meninjau output menggunakan UI MLflow
Hasil evaluasi juga tersedia di UI MLflow. Untuk mengakses UI MLflow, klik ![]() di bilah sisi kanan buku catatan lalu pada eksekusi yang sesuai, atau klik tautan yang muncul di hasil sel untuk sel buku catatan tempat Anda menjalankan
di bilah sisi kanan buku catatan lalu pada eksekusi yang sesuai, atau klik tautan yang muncul di hasil sel untuk sel buku catatan tempat Anda menjalankan mlflow.evaluate().
Meninjau hasil evaluasi untuk satu pengujian
Bagian ini menjelaskan cara meninjau hasil evaluasi untuk pengujian individu. Untuk membandingkan hasil di seluruh eksekusi, lihat Membandingkan hasil evaluasi di seluruh eksekusi.
Gambaran umum penilaian kualitas oleh juri LLM
Penilaian hakim per permintaan tersedia dalam databricks-agents versi 0.3.0 ke atas.
Untuk melihat gambaran umum kualitas yang dinilai LLM dari setiap permintaan dalam kumpulan evaluasi, klik tab Jejak pada halaman Jalankan MLflow.
)
Gambaran umum ini menunjukkan penilaian juri yang berbeda untuk setiap permintaan dan status lulus/gagal kualitas dari setiap permintaan berdasarkan penilaian ini.
Untuk detail selengkapnya, klik baris dalam tabel untuk menampilkan halaman detail untuk permintaan tersebut. Dari halaman detail, Anda bisa mengklik Lihat tampilan jejak terperinci.
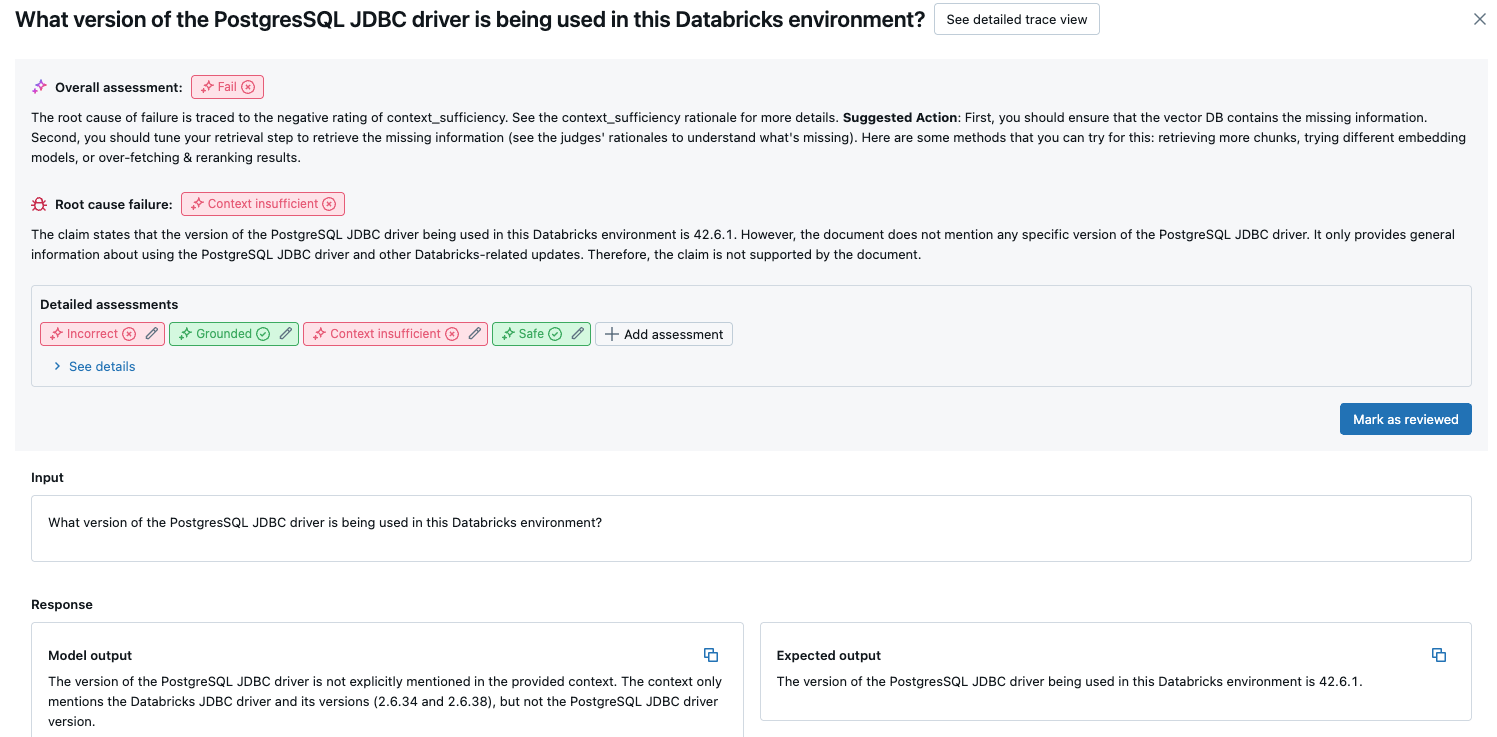
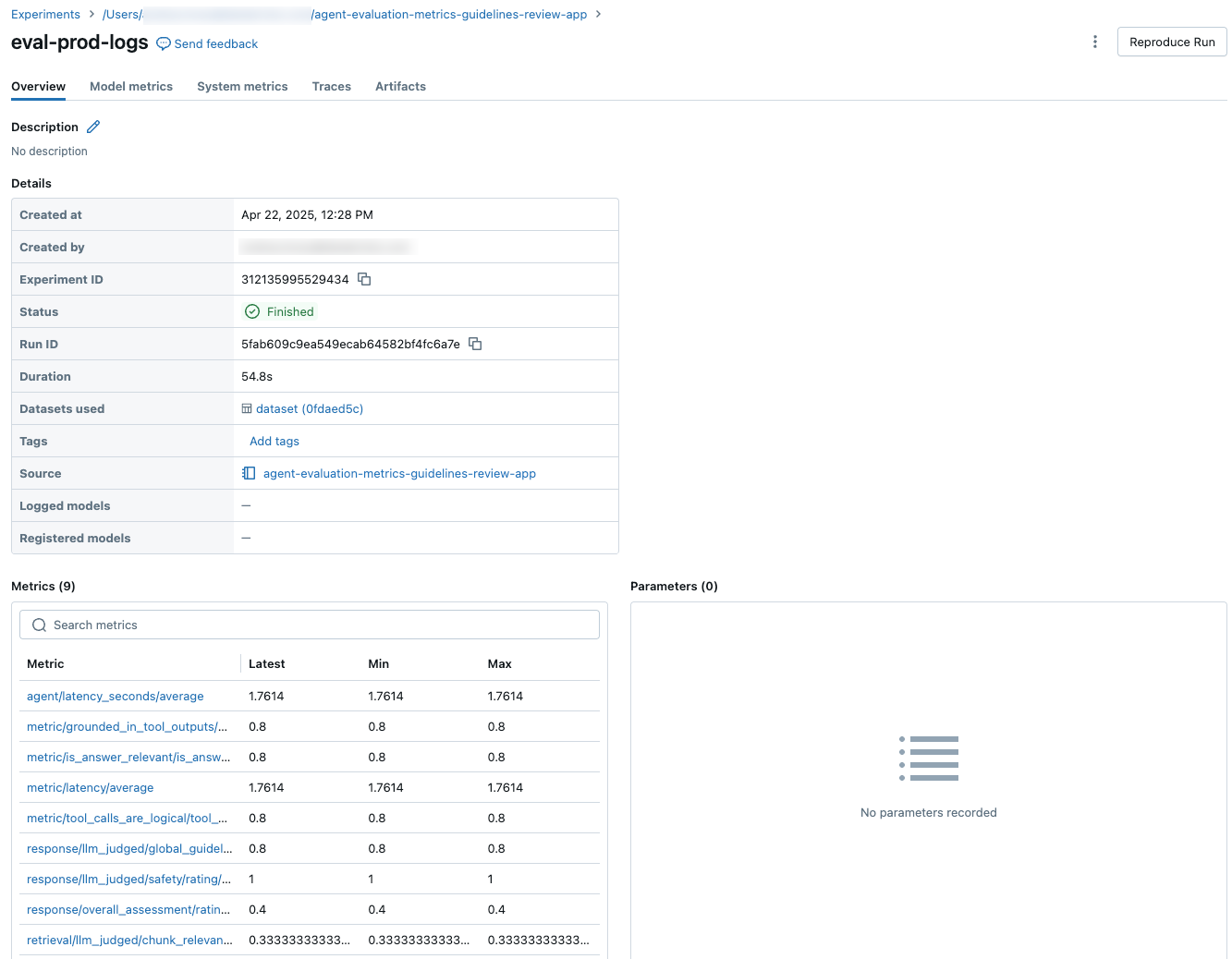
Hasil agregat di seluruh kumpulan evaluasi penuh
Untuk melihat hasil agregat di seluruh kumpulan evaluasi lengkap, klik tab Gambaran Umum
Membandingkan hasil evaluasi antar pengulangan
Penting untuk membandingkan hasil evaluasi di seluruh eksekusi untuk melihat bagaimana aplikasi agenik Anda merespons perubahan. Membandingkan hasil dapat membantu Anda memahami apakah perubahan Anda berdampak positif pada kualitas atau membantu Anda memecahkan masalah perubahan perilaku.
Gunakan halaman Eksperimen MLflow untuk membandingkan hasil di seluruh eksekusi. Untuk mengakses halaman Eksperimen, klik ![]() di bar samping kanan buku catatan, atau klik tautan yang muncul di hasil sel untuk sel buku catatan tempat Anda menjalankan
di bar samping kanan buku catatan, atau klik tautan yang muncul di hasil sel untuk sel buku catatan tempat Anda menjalankan mlflow.evaluate().
Membandingkan hasil per permintaan dari setiap pelaksanaan
Untuk membandingkan data untuk setiap permintaan individual di seluruh eksekusi, klik ikon tampilan evaluasi artefak, yang diperlihatkan dalam cuplikan layar berikut. Tabel memperlihatkan setiap pertanyaan dalam kumpulan evaluasi. Gunakan menu drop-down untuk memilih kolom yang akan ditampilkan. Klik sel untuk menampilkan konten lengkapnya.
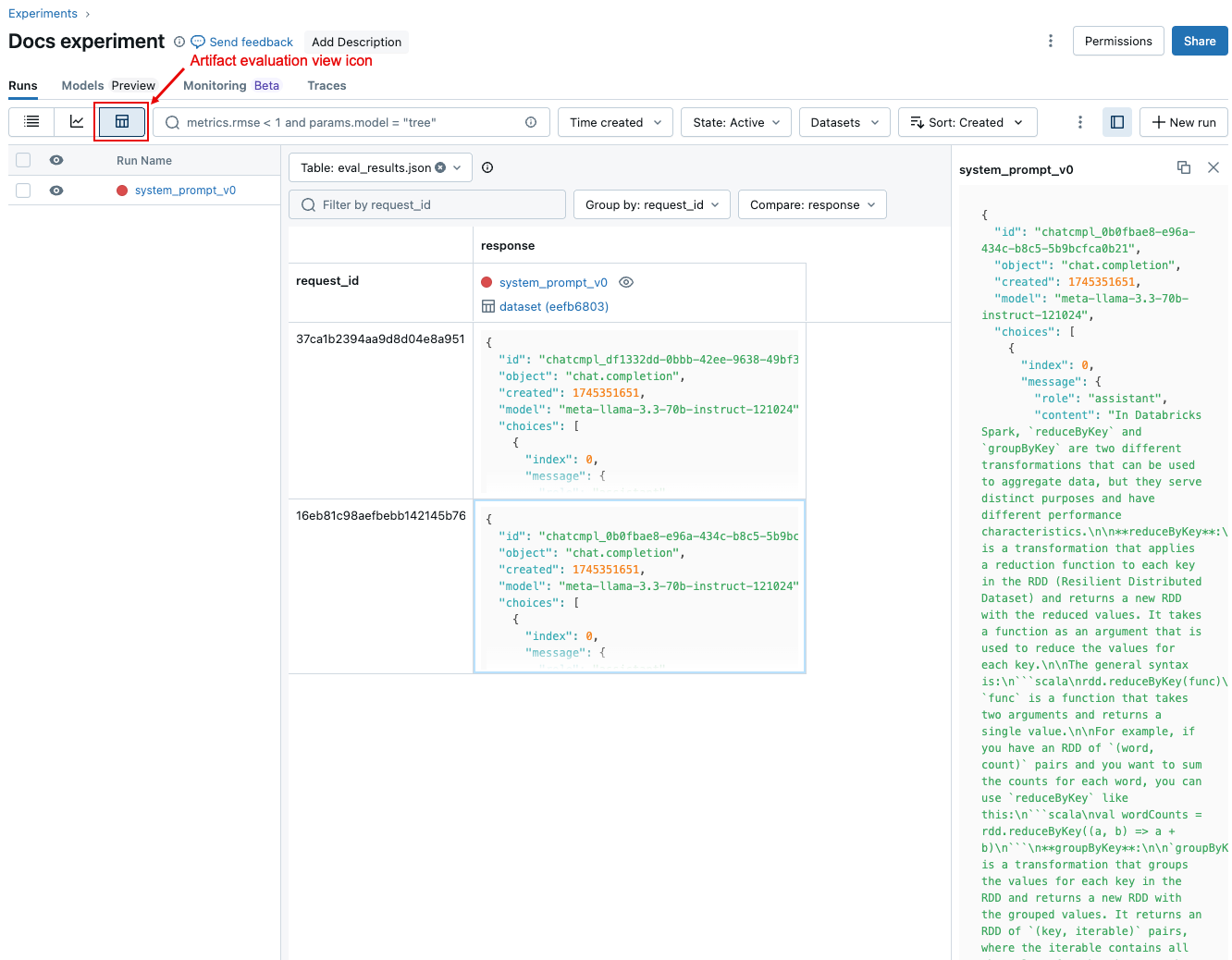
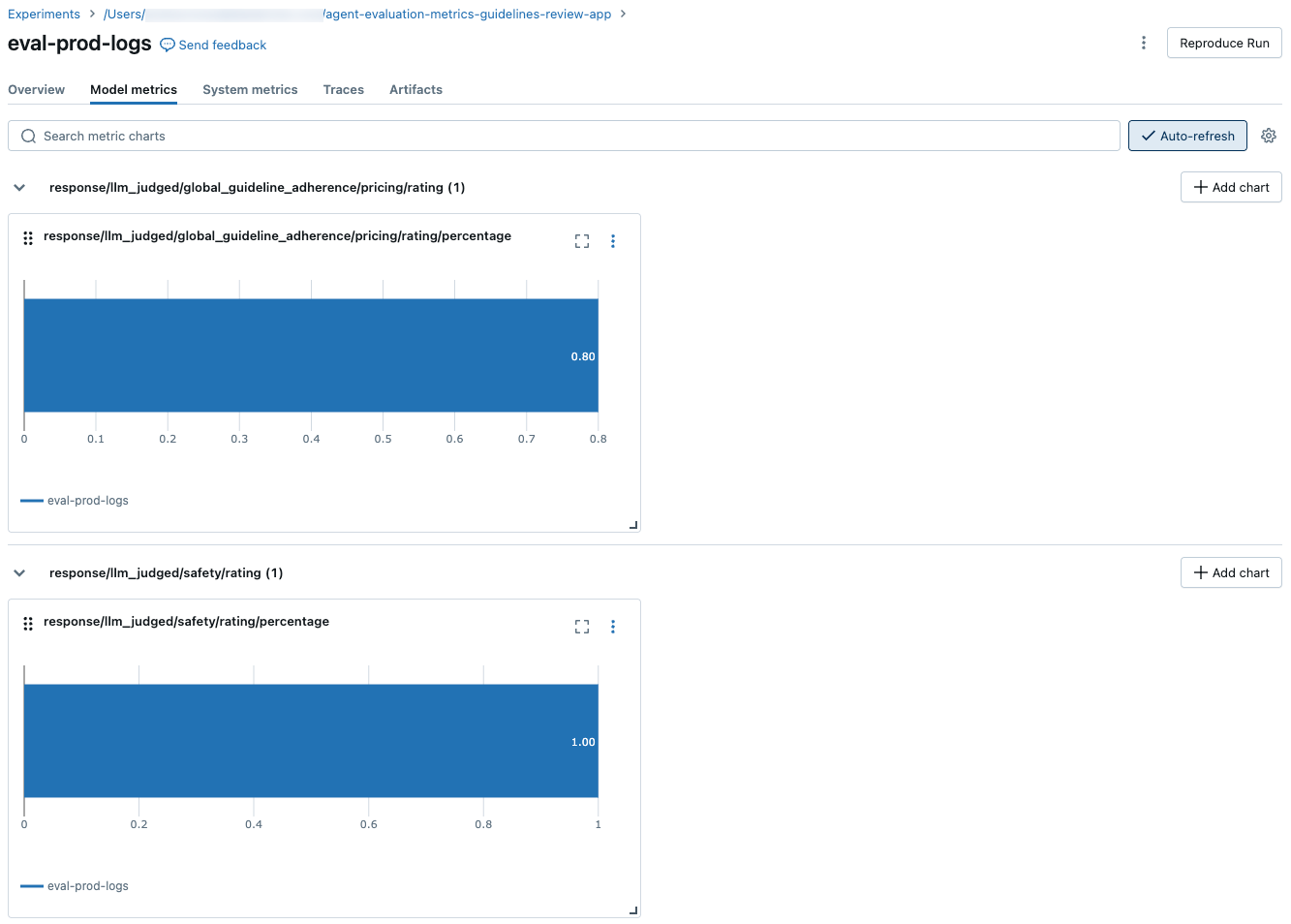
Bandingkan hasil agregat di seluruh percobaan
Untuk membandingkan hasil agregat untuk eksekusi atau di berbagai eksekusi, klik ikon tampilan bagan, yang diperlihatkan dalam cuplikan layar berikut. Ini memungkinkan Anda memvisualisasikan hasil agregat untuk eksekusi yang dipilih dan membandingkan dengan eksekusi sebelumnya.
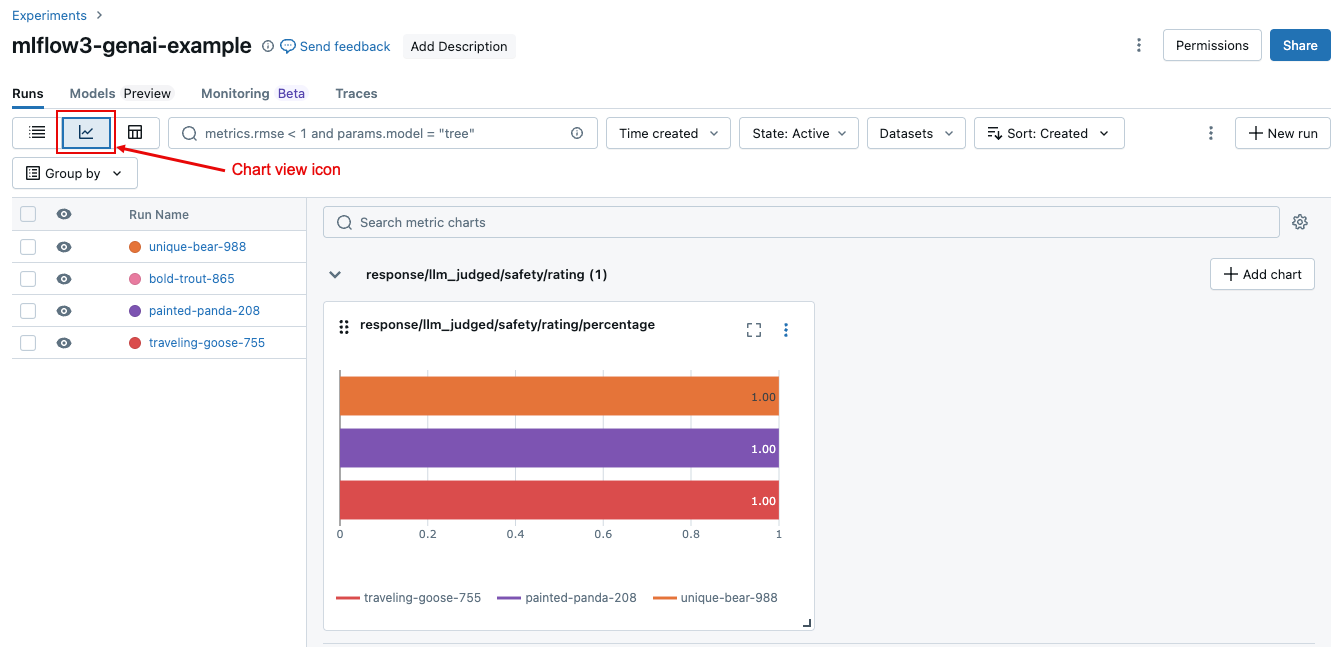
Hakim mana yang terlibat
Secara default, untuk setiap catatan evaluasi, Evaluasi Agen menerapkan subset hakim yang paling cocok dengan informasi yang ada dalam catatan. Khususnya:
- Jika catatan menyertakan jawaban acuan, Evaluasi Agen melibatkan penilai
context_sufficiency,groundedness,correctness,safety, danguideline_adherence. - Jika catatan tidak menyertakan jawaban sebenarnya, Pengkajian Agen menggunakan penilaian
chunk_relevance,groundedness,relevance_to_query,safety, danguideline_adherence.
Untuk detail selengkapnya, lihat:
- Menjalankan subset penilai bawaan
- Hakim AI kustom
- Bagaimana kualitas, biaya, dan latensi dinilai oleh Evaluasi Agen (MLflow 2)
Untuk informasi kepercayaan dan keselamatan hakim LLM, lihat Informasi tentang model yang mendukung hakim LLM.
Contoh: Cara meneruskan aplikasi ke Evaluasi Agen
Untuk meneruskan aplikasi ke mlflow_evaluate(), gunakan model argumen . Ada 5 opsi untuk meneruskan aplikasi dalam model argumen.
- Model yang terdaftar di Unity Catalog.
- Model tercatat di MLflow dalam eksperimen MLflow saat ini.
- Model PyFunc yang dimuat di notebook.
- Fungsi lokal di buku catatan.
- Titik akhir agen terpasang.
Lihat bagian berikut untuk contoh kode yang mengilustrasikan setiap opsi.
Opsi 1. Model terdaftar di Unity Catalog
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Opsi 2. Model yang telah dicatat oleh MLflow dalam eksperimen MLflow saat ini
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Opsi 3. Model PyFunc yang dimuat di buku catatan
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Opsi 4. Fungsi lokal di buku catatan
Fungsi menerima input yang diformat sebagai berikut:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
Fungsi harus mengembalikan nilai dalam string biasa atau kamus yang dapat diserialisasikan (misalnya, Dict[str, Any]). Untuk hasil terbaik dengan juri bawaan, Databricks merekomendasikan penggunaan format obrolan seperti ChatCompletionResponse. Contohnya:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models.",
},
...
}
],
...,
}
Contoh berikut menggunakan fungsi lokal untuk membungkus titik akhir model fondasi dan mengevaluasinya:
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Opsi 5. Titik akhir yang telah disebarkan untuk agen
Opsi ini hanya berfungsi saat Anda menggunakan titik akhir agen yang telah disebarkan menggunakan databricks.agents.deploy dan dengan databricks-agents atau versi SDK 0.8.0 ke atas. Untuk model fondasi atau versi SDK yang lebih lama, gunakan Opsi 4 untuk membungkus model dalam fungsi lokal.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
Cara melewati set evaluasi ketika aplikasi disertakan dalam panggilan mlflow_evaluate()
Dalam kode berikut, data adalah pandas DataFrame yang berisi kumpulan data evaluasi Anda. Ini adalah contoh sederhana. Lihat skema input untuk detailnya.
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Contoh: Cara meneruskan output yang dihasilkan sebelumnya ke Evaluasi Agen
Bagian ini menjelaskan cara meneruskan output yang dihasilkan sebelumnya ke dalam panggilan mlflow_evaluate(). Untuk skema set evaluasi yang diperlukan, lihat Skema input Evaluasi Agen (MLflow 2).
Dalam kode berikut, data adalah pandas DataFrame dengan kumpulan data evaluasi dan keluaran yang dihasilkan oleh aplikasi. Ini adalah contoh sederhana. Lihat skema input untuk detailnya.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Contoh: Menggunakan fungsi kustom untuk memproses respons dari LangGraph
Agen LangGraph, terutama yang memiliki fungsionalitas obrolan, dapat mengembalikan beberapa pesan untuk satu panggilan inferensi. Pengguna bertanggung jawab untuk mengonversi respons agen ke format yang didukung oleh Evaluasi Agen.
Salah satu pendekatannya adalah menggunakan fungsi kustom untuk memproses respons. Contoh berikut menunjukkan fungsi kustom yang mengekstrak pesan obrolan terakhir dari model LangGraph. Fungsi ini kemudian digunakan dalam mlflow.evaluate() untuk mengembalikan respons string tunggal, yang dapat dibandingkan dengan kolom ground_truth.
Contoh kode membuat asumsi berikut:
- Model menerima input dalam format {"pesan": [{"role": "user", "content": "hello"}]}.
- Model mengembalikan daftar string dalam format ["respons 1", "respons 2"].
Kode berikut mengirimkan respons yang digabungkan ke hakim dalam format ini: "respons 1nresponse2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models. MLflow enables teams of all sizes to debug, evaluate, monitor, and optimize their AI applications while controlling costs and managing access to models and data. With over 30 million monthly downloads, thousands of organizations rely on MLflow each day to ship AI to production with confidence.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Buat dasbor dengan metrik
Ketika Anda melakukan iterasi pada kualitas agen Anda, Anda mungkin ingin berbagi dasbor dengan pemangku kepentingan Anda yang menunjukkan bagaimana kualitas telah meningkat dari waktu ke waktu. Anda dapat mengekstrak metrik dari eksekusi evaluasi MLflow, menyimpan nilai ke dalam tabel Delta, dan membuat dasbor.
Contoh berikut menunjukkan cara mengekstrak dan menyimpan nilai metrik dari evaluasi terbaru yang dijalankan di buku catatan Anda:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Contoh berikut menunjukkan cara mengekstrak dan menyimpan nilai metrik untuk eksekusi sebelumnya yang telah Anda simpan dalam eksperimen MLflow Anda.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Anda sekarang dapat membuat dasbor menggunakan data ini.
Kode berikut menentukan fungsi append_metrics_to_table yang digunakan dalam contoh sebelumnya.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Informasi tentang model yang mendukung penilai LLM
- Hakim LLM dapat menggunakan layanan pihak ketiga untuk mengevaluasi aplikasi GenAI Anda, termasuk Azure OpenAI yang dioperasikan oleh Microsoft.
- Untuk Azure OpenAI, Databricks telah memilih keluar dari Pemantauan Penyalahgunaan sehingga tidak ada perintah atau respons yang disimpan dengan Azure OpenAI.
- Untuk ruang kerja Uni Eropa (UE), penilai LLM menggunakan model yang dioperasikan di UE. Semua wilayah lain menggunakan model yang dihosting di AS.
- Menonaktifkan fitur AI yang didukung Mitra mencegah hakim LLM memanggil model yang didukung mitra. Anda masih dapat menggunakan juri LLM dengan menyediakan model Anda sendiri.
- Hakim LLM dimaksudkan untuk membantu pelanggan mengevaluasi agen/aplikasi GenAI mereka, dan output hakim LLM tidak boleh digunakan untuk melatih, meningkatkan, atau menyempurnakan LLM.