Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pengujian beban menemukan kueri maksimum per detik (QPS) yang dapat dipertahankan agen Aplikasi Databricks Anda sebelum penurunan performa. Halaman ini memperlihatkan kepada Anda cara melakukan hal berikut:
- Sebarkan versi tiruan agen Anda untuk mengisolasi throughput infrastruktur dari latensi LLM.
- Jalankan uji beban ramp-to-saturation dengan Locust.
- Menganalisis hasil dengan dasbor interaktif.
Anda dapat mengikuti jalur yang dibantu AI menggunakan keterampilan Claude Code, atau menyiapkan setiap langkah secara manual.
Persyaratan
- Ruang kerja Azure Databricks dengan aplikasi Databricks diaktifkan.
- Aplikasi agen yang disebarkan (atau siap disebarkan) di Databricks Apps menggunakan OpenAI Agents SDK, LangGraph, atau kerangka kerja kustom. Lihat Menulis agen AI dan menyebarkannya di Aplikasi Databricks.
- Databricks CLI diinstal dan diautentikasi. Lihat Menginstal atau memperbarui Databricks CLI.
- Python 3.10+ dengan manajer paket
uv. - (Untuk jalur yang dibantu AI) Claude Code terinstal.
- (Untuk pengujian beban lebih lama dari ~1 jam) Prinsipal layanan dengan kredensial M2M OAuth (
client_iddanclient_secret). Lihat Otorisasi akses prinsipal layanan ke Azure Databricks dengan OAuth.- Untuk pengujian muatan singkat (kurang dari ~1 jam), kredensial OAuth pengguna (U2M) yang ada dari
databricks auth loginberfungsi dengan baik. Untuk pengujian yang lebih lama, gunakan M2M OAuth dengan prinsipal layanan — token M2M kedaluwarsa selama jalannya tes yang panjang dan menyebabkan kegagalan selama tes. Membuat perwakilan layanan memerlukan akses admin ruang kerja.
- Untuk pengujian muatan singkat (kurang dari ~1 jam), kredensial OAuth pengguna (U2M) yang ada dari
Disarankan penyiapan yang dibantu AI
Jika Anda menggunakan Claude Code, keterampilan /load-testing mengotomatiskan alur kerja. Ini membaca kode agen Anda, menghasilkan mockup, membuat skrip uji beban, dan memandu Anda melalui proses penyebaran.
Petunjuk / Saran
Minta Claude Code untuk melakukannya untuk Anda:
Clone https://github.com/databricks/app-templates and run the /load-testing skill against the {your-template} template.
Atau ikuti langkah-langkah di bawah ini.
Langkah 1: Mengkloning templat agen
Keterampilan /load-testing ini disertakan dalam repositori databricks/app-templates, baik sebagai keterampilan utama agent-load-testing maupun disinkronkan sebelumnya ke dalam setiap templat agen individu. Jika Anda sudah memiliki proyek dari app-templates, Anda sudah memiliki keterampilan.
Kloning repositori dan ubah ke direktori templat untuk agen yang ingin Anda muat pengujiannya:
git clone https://github.com/databricks/app-templates.git
cd app-templates/{your-template}
Langkah 2: Jalankan keterampilan pengujian beban
Jalankan perintah berikut di Claude Code.
/load-testing
Keterampilan ini secara interaktif memandu Anda melalui langkah-langkah berikut. Anda dapat melewati tiruan untuk menguji agen asli Anda, atau melewati penyebaran jika aplikasi Anda sudah berjalan.
- Mengumpulkan parameter: menanyakan tentang status penyebaran, ukuran komputasi, konfigurasi pekerja, dan kredensial OAuth Anda.
-
Membuat skrip pengujian beban: menghasilkan
locustfile.py,run_load_test.py, dandashboard_template.pydisesuaikan dengan proyek Anda. - Meniru LLM Anda: membuat klien tiruan khusus untuk SDK Anda (OpenAI Agents SDK, LangGraph, atau kustom) yang menggantikan panggilan LLM nyata dengan penundaan streaming yang dapat dikonfigurasi.
- Menyebarkan aplikasi pengujian: memandu Anda menyebarkan beberapa konfigurasi aplikasi dengan ukuran komputasi dan jumlah pekerja yang berbeda.
- Menjalankan pengujian: menjalankan uji beban dengan autentikasi M2M OAuth dan ramp-to-saturation.
- Menghasilkan hasil: menghasilkan dasbor HTML interaktif dengan metrik QPS, latensi, dan kegagalan.
Penyiapan manual
Ikuti langkah-langkah ini untuk menyiapkan dan menjalankan pengujian beban tanpa bantuan AI.
Langkah 1: Simulasikan panggilan LLM agen Anda (opsional)
Lewati langkah ini jika Anda ingin hasil secara keseluruhan yang menyertakan latensi LLM nyata. Untuk mengukur throughput dari infrastruktur Databricks Apps secara terpisah, simulasikan LLM sehingga latensi pada setiap permintaannya (biasanya antara 1-30 detik) tidak menjadi hambatan.
Proses simulasi mengembalikan respons yang sudah dipersiapkan dengan penyesuaian waktu tunda streaming, mempertahankan alur permintaan/respons penuh (streaming SSE, pengiriman alat, pelari SDK) dan hanya menukar model bahasa besar (LLM). Ini menunjukkan QPS maksimum yang dapat diterima oleh platform Databricks Apps dan menghindari biaya token Foundation Model API selama uji beban.
Waktu tiruan dikontrol oleh dua variabel lingkungan:
| Variabel | Default | Description |
|---|---|---|
MOCK_CHUNK_DELAY_MS |
10 |
Penundaan dalam milidetik antara potongan teks yang dialirkan |
MOCK_CHUNK_COUNT |
80 |
Jumlah potongan teks per respons |
Dengan default, setiap balasan simulasi membutuhkan sekitar 800 ms (10 ms x 80 potongan), secara signifikan lebih cepat daripada balasan LLM nyata (3-15 detik). Angka throughput kemudian mencerminkan platform, bukan model.
Buat klien tiruan yang menggantikan klien LLM nyata. Sisa kode agen Anda tetap tidak berubah, dan pendekatan tergantung pada SDK Anda. Untuk OpenAI, lihat mock_openai_client.py implementasi referensi di databricks/app-templates. Pola yang sama beradaptasi dengan SDK lain.
OpenAI Agents SDK
Buat agent_server/mock_openai_client.py — kelas MockAsyncOpenAI yang mengimplementasikan chat.completions.create() dengan streaming. Ini secara instan mengembalikan potongan panggilan alat (mensimulasikan LLM yang memutuskan untuk memanggil alat) dan potongan respons teks dengan penundaan yang dapat dikonfigurasi dari variabel lingkungan MOCK_CHUNK_DELAY_MS dan MOCK_CHUNK_COUNT.
Tukarkan ke agen Anda:
from agent_server.mock_openai_client import MockAsyncOpenAI
from agents import set_default_openai_client, set_default_openai_api
set_default_openai_client(MockAsyncOpenAI())
set_default_openai_api("chat_completions")
Sisa kode agen Anda (handler, alat, logika streaming) tetap tidak berubah.
LangGraph
ChatDatabricks Ganti model dengan tiruan yang mengembalikan objek bawaanAIMessage:
# Before:
# model = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
# After:
from agent_server.mock_llm import MockChatModel
model = MockChatModel()
Tiruan harus mengembalikan AIMessage objek dengan panggilan alat pada pemanggilan pertama dan konten teks pada pemanggilan berikutnya, dengan penundaan streaming yang dapat dikonfigurasi.
Agen kustom
Bungkus panggilan API eksternal apa pun yang dilakukan agen Anda (LLM, pencarian vektor, API alat) dengan implementasi tiruan yang mengembalikan bentuk respons realistis dengan penundaan yang dapat dikonfigurasi.
Langkah 2: Menyiapkan skrip pengujian beban
Buat load-test-scripts/ direktori di proyek Anda. Kerangka kerja pengujian beban terdiri dari tiga skrip yang tidak bergantung pada kerangka kerja tertentu dan bekerja dengan agen aplikasi Databricks apa pun.
<project-root>/
agent_server/ # Your existing agent code
load-test-scripts/ # Load testing scripts (create this)
run_load_test.py # CLI orchestrator
locustfile.py # Locust test with SSE streaming + TTFT tracking
dashboard_template.py # Interactive HTML dashboard generator
load-test-runs/ # Results (auto-created per run)
<run-name>/
dashboard.html # Interactive dashboard
test_config.json # Test parameters for reproducibility
<label>/ # Per-config Locust CSV output
Kerangka kerja mencakup file berikut:
-
locustfile.py: Tes beban Locust yang mengirimkanPOST /invocationspermintaan denganstream: true, menguraikan aliran SSE, melacak waktu ke token pertama (TTFT) sebagai metrik kustom, menggunakan pertukaran token M2M OAuth dengan refresh otomatis, dan mengimplementasikanStepRampShapeyang meningkatkan pengguna daristep_sizekemax_userssambil menahan setiap tingkat pengguna selamastep_durationdetik. -
run_load_test.py: Orkestrator CLI yang menguji setiap URL aplikasi secara berurutan dengan metrik terisolasi per konfigurasi. Ini menangani refresh token OAuth, menjalankan pemeriksaan kesehatan dan pemanasan sebelum setiap pengujian, dan menyimpan hasilnya keload-test-runs/<run-name>/<label>/. -
dashboard_template.py: Menghasilkan dasbor HTML mandiri menggunakan Chart.js dengan kartu KPI, bagan batang (QPS, latensi, TTFT menurut konfigurasi), bagan garis progresi ramp QPS, dan tabel hasil lengkap. Dapat dijalankan mandiri:uv run dashboard_template.py ../load-test-runs/<run-name>/.
Pasang dependensi
Skrip pengujian beban menggunakan elemen pyproject.toml mereka sendiri di dalam load-test-scripts/ untuk menghindari mencemari dependensi produksi agen Anda. Buat load-test-scripts/pyproject.toml:
[project]
name = "load-test-scripts"
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"locust>=2.32,<2.40",
"urllib3<2.3",
"requests",
]
Note
Sematkan locust ke <2.40. Versi yang lebih baru (>=2.43) memiliki bug yang diketahui RecursionError dan dapat mengganggu pengujian beban panjang.
Instal dari dalam load-test-scripts/ direktori:
cd load-test-scripts/
uv sync
Langkah 3: Menyebarkan aplikasi pengujian dengan berbagai konfigurasi
Sebarkan beberapa Aplikasi Databricks dengan ukuran komputasi dan jumlah pekerja yang berbeda untuk menemukan konfigurasi optimal untuk beban kerja Anda.
Matriks pengujian yang direkomendasikan
Konfigurasi di bawah ini berfokus pada sweet spot yang diidentifikasi dari pengujian sebelumnya. Jika Anda menginginkan cakupan yang lebih luas, tambahkan satu konfigurasi di kedua sisi (misalnya, medium-w1 atau large-w12), tetapi enam di bawah ini biasanya cukup.
| Hitung ukuran | Pekerja | Nama aplikasi yang disarankan |
|---|---|---|
| Medium | 2 | <your-app>-medium-w2 |
| Medium | 3 | <your-app>-medium-w3 |
| Medium | 4 | <your-app>-medium-w4 |
| Besar | 6 | <your-app>-large-w6 |
| Besar | 8 | <your-app>-large-w8 |
| Besar | 10 | <your-app>-large-w10 |
Mengonfigurasi ukuran komputasi
Gunakan Databricks CLI untuk mengatur ukuran komputasi saat membuat atau memperbarui aplikasi:
# Create a new app with Medium compute
databricks apps create <app-name> --compute-size MEDIUM
# Update an existing app to Large compute
databricks apps update <app-name> --compute-size LARGE
Mengonfigurasi jumlah pekerja dengan Bundel Otomatisasi Deklaratif
start-server (melalui AgentServer.run()) menerima flag --workers langsung. Sampaikan jumlah pekerja dalam command array menggunakan variabel DAB.
variables:
app_name:
default: 'my-agent-medium-w2'
workers:
default: '2'
resources:
apps:
load_test_app:
name: ${var.app_name}
source_code_path: .
config:
command: ['uv', 'run', 'start-server', '--workers', '${var.workers}']
env:
- name: MOCK_CHUNK_DELAY_MS
value: '10'
- name: MOCK_CHUNK_COUNT
value: '80'
targets:
medium-w2:
default: true
variables:
app_name: 'my-agent-medium-w2'
workers: '2'
large-w8:
variables:
app_name: 'my-agent-large-w8'
workers: '8'
Mengimplementasikan dan memeriksa
Sebarkan setiap target dengan Databricks CLI:
databricks bundle deploy --target medium-w2
databricks bundle run load_test_app --target medium-w2
Verifikasi bahwa aplikasi aktif sebelum menjalankan pengujian beban:
databricks apps get <app-name> --output json | jq '{app_status, compute_status, url}'
Note
Tunggu hingga semua aplikasi mencapai ACTIVE status sebelum melanjutkan. Aplikasi yang masih mulai menghasilkan hasil yang menyesatkan.
Langkah 4: Jalankan pengujian beban
Mengonfigurasikan autentikasi
Pilih autentikasi Anda berdasarkan berapa lama Anda berencana untuk menjalankan:
-
Tes singkat (kurang dari ~1 jam): gunakan kredensial pengguna yang ada dari
databricks auth login. Tidak diperlukan penyiapan tambahan. - Tes panjang (lebih dari ~1 jam, seperti pengujian semalaman): gunakan M2M OAuth dengan prinsipal layanan. Pengujian Anda dapat dihentikan di tengah jalan karena token U2M kedaluwarsa. Membuat prinsipal layanan memerlukan akses admin ruang kerja.
Untuk M2M OAuth, ekspor kredensial utama layanan sebelum menjalankan pengujian:
export DATABRICKS_HOST=https://your-workspace.cloud.databricks.com
export DATABRICKS_CLIENT_ID=<your-client-id>
export DATABRICKS_CLIENT_SECRET=<your-client-secret>
Referensi parameter
| Parameter | Required | Default | Description |
|---|---|---|---|
--app-url |
Yes | — | URL Aplikasi untuk diuji (dapat diulang) |
--client-id |
Untuk tes panjang |
DATABRICKS_CLIENT_ID env |
ID klien perwakilan layanan (M2M OAuth) |
--client-secret |
Untuk tes panjang |
DATABRICKS_CLIENT_SECRET env |
Rahasia klien perwakilan layanan (M2M OAuth) |
--label |
No | Turunan otomatis dari URL | Label yang dapat dibaca manusia per aplikasi (dapat diulang) |
--compute-size |
No | Terdeteksi otomatis atau medium |
Tag ukuran komputasi per aplikasi: medium, large (dapat diulang) |
--max-users |
No | 300 |
Pengguna yang disimulasikan secara bersamaan maksimum |
--step-size |
No | 20 |
Pengguna ditambahkan per langkah peningkatan |
--step-duration |
No | 30 |
Detik per langkah tanjakan |
--spawn-rate |
No | 20 |
Tingkat spawn pengguna (pengguna/detik) |
--run-name |
No | <timestamp> |
Nama untuk eksekusi ini — hasil disimpan ke load-test-runs/<run-name>/ |
--dashboard |
No | Nonaktif | Hasilkan dasbor HTML interaktif setelah pengujian selesai |
Contoh perintah
Pengujian aplikasi tunggal cepat (jangka pendek — menggunakan sesi Anda databricks auth login ):
cd load-test-scripts/
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--dashboard --run-name quick-test
Matriks penuh pada 6 konfigurasi yang direkomendasikan (jangka panjang — lewatkan kredensial M2M). Berikan --compute-size flag dalam urutan yang sama seperti --app-url:
uv run run_load_test.py \
--app-url https://my-app-medium-w2.aws.databricksapps.com \
--app-url https://my-app-medium-w3.aws.databricksapps.com \
--app-url https://my-app-medium-w4.aws.databricksapps.com \
--app-url https://my-app-large-w6.aws.databricksapps.com \
--app-url https://my-app-large-w8.aws.databricksapps.com \
--app-url https://my-app-large-w10.aws.databricksapps.com \
--compute-size medium --compute-size medium --compute-size medium \
--compute-size large --compute-size large --compute-size large \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--dashboard --run-name overnight-sweep
Beberapa pengulangan untuk konsistensi statistik:
for RUN in r1 r2 r3 r4 r5; do
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--max-users 1000 --step-size 20 --step-duration 10 \
--run-name my_test_${RUN} --dashboard || break
done
Apa yang terjadi selama proses berjalan
-
Healthcheck: memverifikasi aliran aplikasi dengan benar (menerima
[DONE]). - Pemanasan: mengirim permintaan berurutan untuk menghangatkan aplikasi.
-
Ramp-to-saturation: meningkatkan pengguna secara bersamaan setiap
step_durationdetik. - Deteksi saturasi: ketika QPS tidak meningkat meskipun menambah lebih banyak pengguna, Anda telah mencapai batas throughput.
Estimasi durasi
Setiap aplikasi yang sedang diuji melalui tahapannya sendiri, sehingga waktu total pelaksanaan disesuaikan dengan jumlah konfigurasi dalam matriks. Gunakan rumus di bawah ini untuk merencanakan jendela waktu Anda.
Durasi per aplikasi: (max_users / step_size) * step_duration detik.
Dengan default (--max-users 300 --step-size 20 --step-duration 30):
- 15 langkah x 30 detik = sekitar 7,5 menit per aplikasi
- Untuk matriks konfigurasi 6 yang direkomendasikan: sekitar 45 menit per eksekusi
Langkah 5: Menampilkan dan menginterpretasikan hasil
Buka dasbor:
open load-test-runs/<run-name>/dashboard.html(Opsional) Regenerasi dasbor dari data yang ada, misalnya setelah memperbarui templat:
cd load-test-scripts/ uv run dashboard_template.py ../load-test-runs/<run-name>/
Bagian dasbor
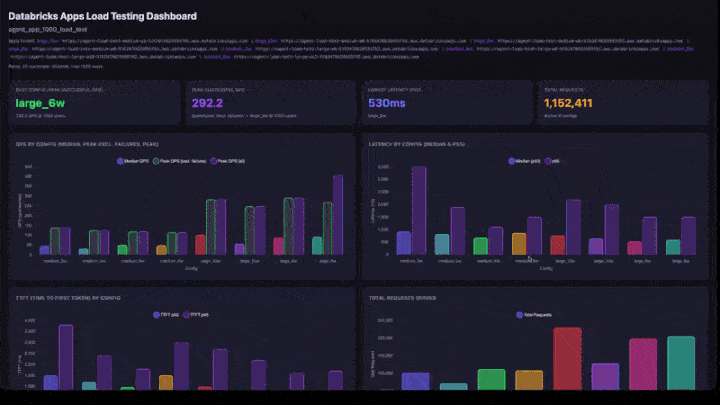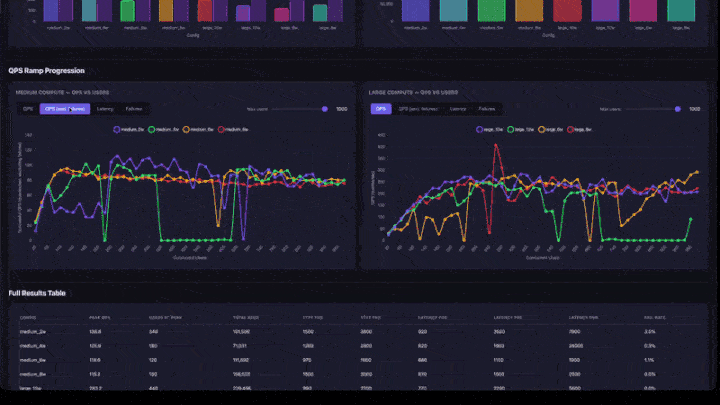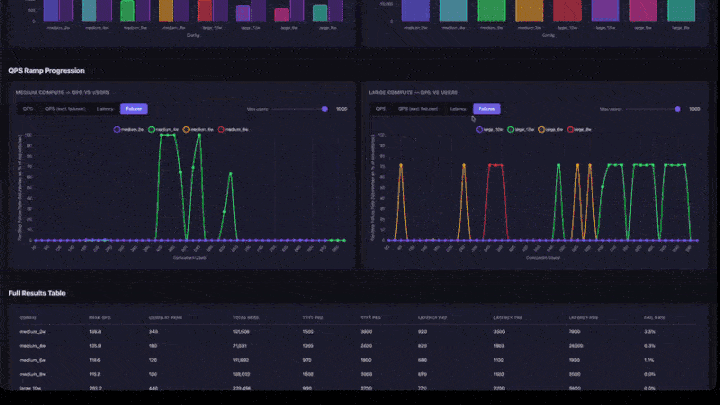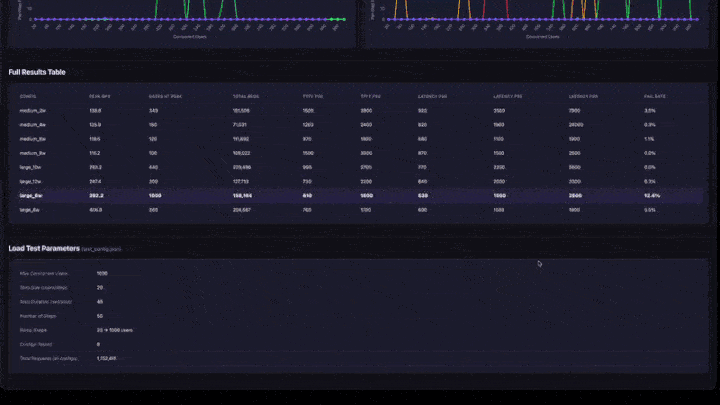
Dasbor interaktif meliputi:
- Kartu KPI: konfigurasi terbaik (berdasarkan QPS puncak yang berhasil), QPS puncak keseluruhan, latensi terendah, dan total permintaan yang dilayani.
- QPS menurut Konfigurasi: bagan batang yang dikelompokkan memperlihatkan QPS median, QPS puncak tidak termasuk kegagalan, dan puncak QPS berdampingan untuk setiap konfigurasi.
- Latensi menurut Konfigurasi: bilah yang dikelompokkan memperlihatkan latensi p50 dan p95.
- TTFT by Config: waktu untuk token pertama (p50 dan p95).
- Total Permintaan Dilayani: jumlah permintaan per konfigurasi.
- Perkembangan Ramp QPS: bagan garis dengan tab untuk QPS, QPS (tidak termasuk kegagalan), Latensi, dan Kegagalan. Menyertakan penggeser jumlah pengguna maksimum untuk memfokuskan pada rentang konkurensi yang lebih rendah. Bagan dikelompokkan menurut ukuran komputasi (sedang dan besar berdampingan).
- Tabel Hasil Lengkap: semua konfigurasi dengan QPS puncak, pengguna pada puncak, persentil latensi, dan tingkat kegagalan.
- Parameter Pengujian: ringkasan konfigurasi untuk reproduksi.
Cara menginterpretasikan hasil
- QPS puncak: QPS maksimum yang dicapai pada tahap peningkatan apa pun. Ini adalah batas maksimum throughput untuk konfigurasi tersebut.
- Pengguna di Puncak: jumlah pengguna bersamaan saat QPS puncak tercapai. Menambahkan lebih banyak pengguna di luar titik ini tidak meningkatkan throughput.
- Tingkat Kegagalan: harus 0% atau sangat rendah. Tingkat kegagalan yang tinggi berarti aplikasi kelebihan beban pada tingkat konkurensi tersebut.
- Bagan Kenaikan QPS: temukan bagian di mana garis menjadi datar. Itulah titik saturasi: menambahkan lebih banyak pengguna tidak akan meningkatkan throughput.
Troubleshooting
| Issue | Solusi |
|---|---|
| Token autentikasi kedaluwarsa pertengahan pengujian | Untuk pengujian yang lebih lama dari ~1 jam, beralih dari U2M ke M2M OAuth dengan melewati --client-id dan --client-secret |
| Pemeriksaan kesehatan gagal | Verifikasi bahwa aplikasi aktif: databricks apps get <name> --output json |
| 0 QPS atau tidak ada hasil | Periksa load-test-runs/<run-name>/<label>/locust_output.log untuk kesalahan |
| QPS rendah meskipun jumlah pengguna tinggi | Aplikasi ini penuh. Coba lebih banyak pekerja atau komputasi yang lebih besar. |
| Tingkat kegagalan tinggi | Aplikasi kelebihan beban. Kurangi --max-users pekerja atau tingkatkan komputasi. |
| Dasbor tidak menunjukkan data ramp | Verifikasi results_stats_history.csv ada di setiap subdirektori hasil |
Langkah berikutnya
- Uji dengan panggilan LLM nyata: lewati langkah tiruan dan sebarkan agen aktual Anda untuk mengukur latensi end-to-end termasuk waktu respons LLM.
- Menyetel jumlah pekerja: gunakan hasil matriks pengujian untuk menemukan jumlah pekerja yang optimal untuk ukuran komputasi Anda.
- Tutorial: Mengevaluasi dan meningkatkan aplikasi GenAI untuk mengukur akurasi, relevansi, dan keamanan serta keluaran.