Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini berisi rekomendasi dan sumber daya untuk mengonfigurasi komputasi untuk Pekerjaan Lakeflow.
Penting
Batasan untuk komputasi tanpa server untuk pekerjaan meliputi yang berikut ini:
- Tidak ada dukungan untuk Penjadwalan berkelanjutan .
- Tidak ada dukungan untuk pemicu interval default atau berbasis waktu di Streaming Terstruktur.
Untuk batasan lainnya, lihat Batasan komputasi tanpa server.
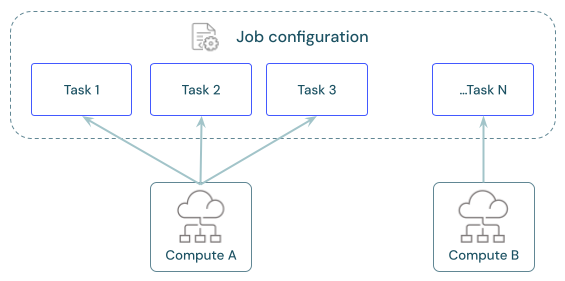
Setiap pekerjaan dapat memiliki satu atau beberapa tugas. Anda menentukan sumber daya komputasi untuk setiap tugas. Beberapa tugas yang ditentukan untuk pekerjaan yang sama dapat menggunakan sumber daya komputasi yang sama.
Apa komputasi yang direkomendasikan untuk setiap tugas?
Tabel berikut menunjukkan jenis komputasi yang direkomendasikan dan didukung untuk setiap jenis tugas.
Catatan
Komputasi tanpa server untuk pekerjaan memiliki batasan dan tidak mendukung semua beban kerja. Lihat Batasan komputasi tanpa server.
| Tugas | Komputasi yang direkomendasikan | Komputasi yang didukung |
|---|---|---|
| Notebooks | Pekerjaan tanpa server | Tugas tanpa server, tugas klasik, klasik serbaguna |
| Skrip Python | Pekerjaan tanpa server | Pekerjaan tanpa server, pekerjaan klasik, semua tujuan klasik |
| Roda Python | Pekerjaan tanpa server | Pekerjaan tanpa server, pekerjaan klasik, semua tujuan klasik |
| SQL | Gudang SQL tanpa server | Gudang SQL tanpa server, gudang pro SQL |
| Alur Deklaratif Lakeflow Spark | Alur tanpa server | Alur tanpa server, alur klasik |
| dbt | Gudang SQL tanpa server | Gudang SQL tanpa server, gudang pro SQL |
| perintah dbt CLI | Pekerjaan tanpa server | Pekerjaan tanpa server, pekerjaan klasik, semua tujuan klasik |
| JAR | Pekerjaan klasik | Pekerjaan klasik, semua tujuan klasik |
| Spark Kirim | Pekerjaan klasik | Pekerjaan klasik |
Harga untuk Pekerjaan Lakeflow terkait dengan komputasi yang digunakan untuk menjalankan tugas. Untuk detail selengkapnya, lihat Harga Databricks.
Bagaimana cara mengonfigurasi komputasi untuk Pekerjaan?
Komputasi pekerjaan klasik dikonfigurasi langsung dari UI Pekerjaan Lakeflow, dan konfigurasi ini adalah bagian dari definisi pekerjaan. Semua jenis komputasi lain yang tersedia menyimpan konfigurasinya dengan aset ruang kerja lainnya. Tabel berikut ini memiliki detail selengkapnya:
| Jenis komputasi | Detail-detail |
|---|---|
| Komputasi pekerjaan klasik | Anda mengonfigurasi komputasi untuk pekerjaan klasik menggunakan UI dan pengaturan yang sama yang tersedia untuk komputasi serbaguna. Lihat Referensi konfigurasi komputasi. |
| Komputasi tanpa server untuk pekerjaan | Komputasi tanpa server untuk pekerjaan adalah default untuk semua tugas yang mendukungnya. Databricks mengelola pengaturan komputasi untuk komputasi tanpa server. Lihat Menjalankan Pekerjaan Lakeflow Anda dengan komputasi tanpa server untuk alur kerja. |
| Gudang SQL | Gudang SQL tanpa server dan pro dikonfigurasi oleh admin ruang kerja atau pengguna dengan hak istimewa pembuatan kluster yang tidak dibatasi. Anda mengonfigurasi tugas untuk dijalankan terhadap gudang SQL yang ada. Lihat Menyambungkan ke gudang SQL. |
| Pemrosesan Pipa Deklaratif Lakeflow Spark | Anda mengonfigurasi pengaturan komputasi untuk Alur Deklaratif Lakeflow Spark selama konfigurasi alur. Lihat Mengonfigurasi komputasi klasik untuk alur. Azure Databricks mengelola sumber daya komputasi untuk Alur Deklaratif Lakeflow Spark tanpa server. Lihat Mengonfigurasi alur tanpa server. |
| Komputasi serbaguna | Anda dapat secara opsional mengonfigurasi tugas menggunakan komputasi klasik semua tujuan. Databricks tidak merekomendasikan konfigurasi ini untuk pekerjaan produksi. Lihat Referensi konfigurasi komputasi dan Haruskah komputasi serba guna pernah digunakan untuk pekerjaan?. |
Berbagi komputasi di seluruh tugas
Konfigurasikan tugas untuk menggunakan sumber daya komputasi pekerjaan yang sama untuk mengoptimalkan penggunaan sumber daya dengan pekerjaan yang mengatur beberapa tugas. Berbagi komputasi di seluruh tugas dapat mengurangi latensi yang terkait dengan waktu mulai.
Anda dapat menggunakan satu sumber daya komputasi pekerjaan untuk menjalankan semua tugas yang merupakan bagian dari pekerjaan atau beberapa sumber daya pekerjaan yang dioptimalkan untuk beban kerja tertentu. Komputasi pekerjaan apa pun yang dikonfigurasi sebagai bagian dari pekerjaan tersedia untuk semua tugas lain dalam pekerjaan.
Tabel berikut menyoroti perbedaan antara komputasi pekerjaan yang dikonfigurasi untuk satu tugas dan komputasi pekerjaan yang dibagikan antar tugas:
| Tugas tunggal | Dibagikan di seluruh tugas | |
|---|---|---|
| Mulai | Ketika tugas berjalan dimulai. | Ketika tugas pertama yang dikonfigurasi untuk menggunakan sumber daya komputasi mulai dijalankan. |
| Mengakhiri | Setelah tugas selesai. | Setelah tugas akhir yang dikonfigurasi untuk menggunakan sumber daya komputasi dijalankan. |
| Komputasi tidak aktif | Tidak berlaku. | Komputer tetap menyala dan siaga ketika tugas tidak menggunakan sumber daya komputasi. |
Kluster berbagi tugas dibatasi untuk satu pelaksanaan pekerjaan dan tidak dapat digunakan oleh pekerjaan lain atau pelaksanaan instansi yang sama.
Pustaka tidak dapat dideklarasikan dalam konfigurasi kluster pekerjaan bersama. Anda harus menambahkan pustaka dependen dalam pengaturan tugas.
Status driver bersama di seluruh tugas
Saat beberapa tugas berbagi sumber daya komputasi pekerjaan, tugas berjalan pada driver JVM yang sama. Status kelas dan singleton bertahan di seluruh tugas selama durasi pekerjaan berjalan. Untuk sebagian besar beban kerja, ini transparan, tetapi ketahui implikasi berikut:
- Scala singleton dan objek pendamping (companion objects) dibagikan di seluruh tugas. Status yang dapat diubah dalam objek pendamping Scala bertahan di antara tugas yang berjalan pada kluster bersama yang sama. Jika tugas paralel membaca dari atau menulis ke variabel objek pendamping yang sama, nilai dari satu tugas dapat menimpa nilai tugas yang lain. Untuk contoh kerja, lihat artikel Pangkalan Pengetahuan Alur kerja multi-tugas menggunakan nilai parameter yang salah.
- Pustaka yang dimuat oleh satu tugas tertentu tetap tersedia untuk tugas berikutnya selama durasi pekerjaan itu berjalan.
Jika kode Anda memerlukan isolasi tingkat tugas, gunakan salah satu pendekatan berikut:
- Konfigurasikan setiap tugas untuk menggunakan sumber daya komputasi pekerjaan terpisah.
- Tambahkan dependensi tugas eksplisit sehingga tugas berjalan secara berurutan daripada secara paralel.
- Refaktor kode untuk menghindari mengandalkan status singleton atau shared mutable. Misalnya, berikan parameter secara eksplisit ke setiap fungsi alih-alih membacanya dari objek pendamping.
Meninjau, mengonfigurasi, dan menukar pekerjaan komputasi
Bagian Komputasi di panel Detail pekerjaan mencantumkan semua komputasi yang dikonfigurasi untuk tugas dalam pekerjaan saat ini.
Tugas yang dikonfigurasi untuk menggunakan sumber daya komputasi disorot dalam grafik tugas saat Anda mengarahkan mouse ke atas spesifikasi komputasi.
Gunakan tombol Tukar untuk mengubah komputasi untuk semua tugas yang terkait dengan sumber daya komputasi.
Sumber daya komputasi tugas klasik memiliki opsi Konfigurasi. Sumber daya komputasi lainnya memberi Anda opsi untuk melihat dan memodifikasi detail konfigurasi komputasi.
Informasi selengkapnya
Untuk detail tambahan tentang mengonfigurasi pekerjaan klasik Azure Databricks, lihat Praktik terbaik untuk mengonfigurasi Pekerjaan Lakeflow klasik.