Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pipa mungkin berisi beberapa alur kerja yang hampir identik, hanya berbeda dalam beberapa parameter. Menentukan alur ini secara eksplisit rentan terhadap kesalahan, redundan, dan sulit dipertahankan. Metaprogram dengan fungsi dalam Python menghasilkan alur berulang secara dinamis, dengan setiap pemanggilan menyediakan serangkaian parameter yang berbeda.
Ikhtisar
Metaprogram dalam Lakeflow Spark Declarative Pipelines menggunakan fungsi dalam Python. Karena fungsi-fungsi ini dievaluasi secara tunda oleh runtime pipeline, Anda dapat membungkus dekorator @dp.table di dalam fungsi pembuat dan memanggil fungsi tersebut beberapa kali dengan argumen yang berbeda. Setiap panggilan mendaftarkan alur baru tanpa menduplikasi kode.
Untuk detail tentang menggunakan for perulangan dengan Alur Deklaratif Lakeflow Spark, lihat Membuat tabel dalam perulanganfor.
Contoh: waktu respons pemadam kebakaran
Contoh berikut menggunakan himpunan data pemadam kebakaran bawaan untuk menemukan lingkungan dengan waktu respons darurat tercepat untuk setiap jenis panggilan. Tanpa metaprogram, Anda harus menulis definisi tabel yang hampir identik untuk setiap jenis panggilan (Alarm, Kebakaran Struktur, Insiden Medis). Dengan metaprogram, satu fungsi pabrik menghasilkan semuanya.
Langkah 1: Tentukan tabel penyerapan mentah
import functools
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name="raw_fire_department",
comment="raw table for fire department response"
)
@dp.expect_or_drop("valid_received", "received IS NOT NULL")
@dp.expect_or_drop("valid_response", "responded IS NOT NULL")
@dp.expect_or_drop("valid_neighborhood", "neighborhood != 'None'")
def get_raw_fire_department():
return (
spark.read.format('csv')
.option('header', 'true')
.option('multiline', 'true')
.load('/databricks-datasets/timeseries/Fires/Fire_Department_Calls_for_Service.csv')
.withColumnRenamed('Call Type', 'call_type')
.withColumnRenamed('Received DtTm', 'received')
.withColumnRenamed('Response DtTm', 'responded')
.withColumnRenamed('Neighborhooods - Analysis Boundaries', 'neighborhood')
.select('call_type', 'received', 'responded', 'neighborhood')
)
Langkah 2: Tentukan fungsi pabrik alur
Fungsi generate_tables pabrik mendaftarkan dua tabel untuk setiap jenis panggilan: tabel panggilan yang difilter dan tabel waktu respons berpangkat. Keduanya dibuat sebagai fungsi dalam yang dihiasi dengan @dp.table.
all_tables = []
def generate_tables(call_table, response_table, filter):
@dp.table(
name=call_table,
comment="top level tables by call type"
)
def create_call_table():
return spark.sql("""
SELECT
unix_timestamp(received,'M/d/yyyy h:m:s a') as ts_received,
unix_timestamp(responded,'M/d/yyyy h:m:s a') as ts_responded,
neighborhood
FROM raw_fire_department
WHERE call_type = '{filter}'
""".format(filter=filter))
@dp.table(
name=response_table,
comment="top 10 neighborhoods with fastest response time"
)
def create_response_table():
return spark.sql("""
SELECT
neighborhood,
AVG((ts_received - ts_responded)) as response_time
FROM {call_table}
GROUP BY 1
ORDER BY response_time
LIMIT 10
""".format(call_table=call_table))
all_tables.append(response_table)
Langkah 3: Panggil pabrik dan tentukan tabel ringkasan
Panggil pabrik sekali untuk setiap jenis panggilan, lalu tentukan tabel ringkasan yang menyabungkan hasil untuk menemukan lingkungan yang paling sering muncul di semua kategori.
generate_tables("alarms_table", "alarms_response", "Alarms")
generate_tables("fire_table", "fire_response", "Structure Fire")
generate_tables("medical_table", "medical_response", "Medical Incident")
@dp.table(
name="best_neighborhoods",
comment="which neighbor appears in the best response time list the most"
)
def summary():
target_tables = [dp.read(t) for t in all_tables]
unioned = functools.reduce(lambda x, y: x.union(y), target_tables)
return (
unioned.groupBy(col("neighborhood"))
.agg(count("*").alias("score"))
.orderBy(desc("score"))
)
Setelah menjalankan alur ini, Anda akan membuat sekumpulan tabel serupa, seperti grafik ini:
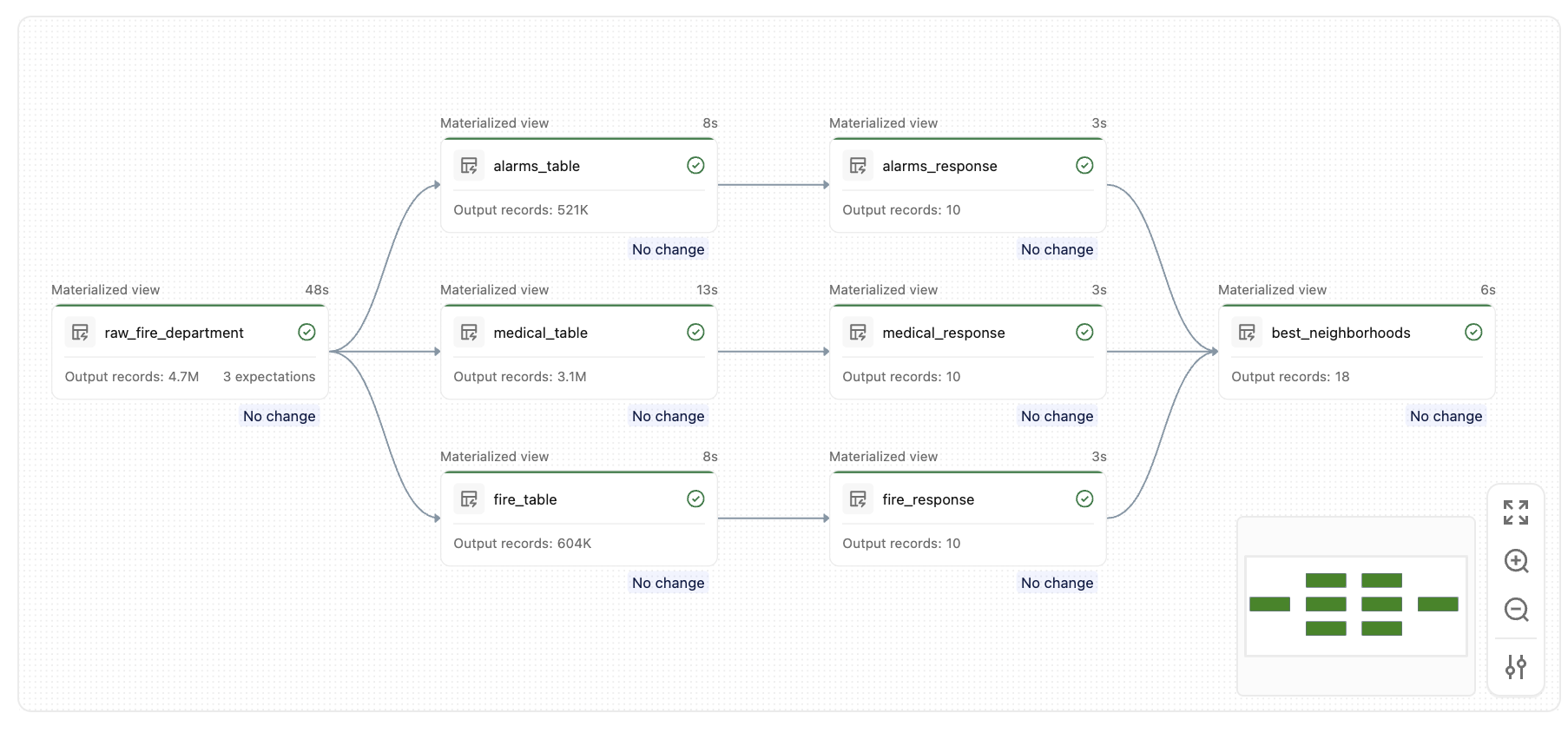
Konsep Utama
-
Fungsi dalam didaftarkan secara malas: Dekorator
@dp.tabletidak segera menjalankan fungsi. Ini mendaftarkan fungsi dengan waktu proses pipeline, yang memetakan graf aliran data lengkap sebelum eksekusi dimulai. -
Penutupan menangkap parameter: Setiap fungsi inner menangkap parameter yang diteruskan ke factory (
call_table,response_table,filter) sehingga setiap alur terdaftar menggunakan set nilai terisolasi sendiri. -
Daftar tabel dinamis: Menggunakan daftar seperti
all_tablesuntuk melacak nama tabel yang dihasilkan secara programatik memudahkan referensi di kemudian hari (misalnya, dalam union atau penggabungan).