Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Jalur pemrosesan dapat berisi banyak kumpulan data dengan banyak aliran untuk tetap memperbaruinya. Pipeline secara otomatis mengelola pembaruan dan kluster guna memperbarui secara efisien. Namun, ada beberapa overhead dalam mengelola sejumlah besar arus data, dan kadang-kadang, hal ini dapat mengakibatkan overhead yang lebih besar dari yang diharapkan saat inisialisasi atau bahkan selama pengelolaan dalam proses.
Jika Anda mengalami penundaan menunggu alur yang dipicu untuk diinisialisasi, seperti waktu inisialisasi selama lima menit, pertimbangkan untuk memisahkan pemrosesan menjadi beberapa alur, bahkan ketika himpunan data menggunakan data sumber yang sama.
Nota
Alur yang dipicu melakukan langkah-langkah inisialisasi setiap kali dipicu. Alur berkelanjutan hanya melakukan langkah-langkah inisialisasi saat dihentikan dan dimulai ulang. Bagian ini paling berguna untuk mengoptimalkan inisialisasi alur yang dipicu.
Kapan harus mempertimbangkan untuk memisahkan alur
Ada beberapa kasus di mana memisahkan alur dapat menguntungkan karena alasan performa.
- Fase
INITIALIZINGdanSETTING_UP_TABLESmembutuhkan waktu lebih lama dari yang Anda inginkan, memengaruhi waktu alur Anda secara keseluruhan. Jika durasinya lebih dari 5 menit, ini sering kali dapat ditingkatkan dengan memisahkan jalur pemrosesan Anda. - Driver yang mengelola kluster dapat menjadi hambatan saat menjalankan banyak tabel streaming (lebih dari 30-40) dalam satu alur. Jika driver Anda tidak responsif, durasi kueri streaming Anda akan meningkat, yang akan berdampak pada total waktu pembaruan.
- Alur yang dipicu yang memiliki beberapa alur tabel streaming mungkin tidak dapat melakukan semua pembaruan aliran yang dapat diparalelkan secara paralel.
Detail tentang masalah performa
Bagian ini menjelaskan beberapa masalah kinerja yang dapat muncul dari memiliki banyak tabel dan alur dalam satu jalur.
Hambatan dalam fase INISIALISASI dan MENYIAPKAN_TABEL
Fase awal eksekusi dapat menjadi hambatan performa, tergantung pada kompleksitas alur.
Fase INISIALISASI
Selama fase ini, rencana logis dibuat, termasuk rencana untuk membangun grafik dependensi dan menentukan urutan pembaruan tabel.
fase SETTING_UP_TABLES
Selama fase ini, proses berikut dilakukan, berdasarkan rencana yang dibuat pada fase sebelumnya:
- Validasi dan resolusi skema untuk semua tabel yang ditentukan dalam jalur pemrosesan.
- Buat grafik dependensi, dan tentukan urutan eksekusi tabel.
- Periksa apakah setiap himpunan data aktif di alur atau baru sejak pembaruan sebelumnya.
- Buat tabel streaming di pembaruan pertama, dan, untuk tampilan materialisasi, buat tampilan sementara atau tabel cadangan yang diperlukan selama setiap pembaruan alur.
Mengapa INISIALISASI dan MENYIAPKAN_TABEL dapat memakan waktu lebih lama
Pipa besar dengan banyak aliran untuk banyak himpunan data dapat memakan waktu lebih lama karena beberapa alasan tertentu.
- Untuk pipeline dengan banyak aliran dan dependensi yang kompleks, fase-fase ini dapat memakan waktu lebih lama karena banyaknya pekerjaan yang harus diselesaikan.
- Transformasi kompleks, termasuk
Auto CDCtransformasi, dapat menyebabkan hambatan performa, karena operasi yang diperlukan untuk mewujudkan tabel berdasarkan transformasi yang ditentukan. - Ada juga skenario di mana sejumlah besar alur dapat menyebabkan perlambatan, bahkan jika alur tersebut bukan bagian dari pembaruan. Sebagai contoh, pertimbangkan alur yang memiliki lebih dari 700 alur, yang kurang dari 50 diperbarui untuk setiap pemicu, berdasarkan konfigurasi. Dalam contoh ini, setiap eksekusi harus melalui beberapa langkah untuk semua 700 tabel, mendapatkan kerangka data, lalu memilih yang akan dijalankan.
Penyempitan di sopir
Pengendali mengatur pembaruan dalam pengoperasian. Ini harus menjalankan beberapa logika untuk setiap tabel, untuk memutuskan instans mana dalam kluster yang harus menangani setiap alur. Saat menjalankan beberapa tabel streaming (lebih dari 30-40) dalam satu alur, driver dapat menjadi hambatan untuk sumber daya CPU karena menangani pekerjaan di seluruh kluster.
Driver juga dapat mengalami masalah memori. Ini dapat terjadi lebih sering ketika jumlah aliran paralel adalah 30 atau lebih. Tidak ada sejumlah alur atau himpunan data tertentu yang dapat menyebabkan masalah memori driver tetapi tergantung pada kompleksitas tugas yang berjalan secara paralel.
Aliran streaming dapat berjalan secara paralel, tetapi ini mengharuskan driver untuk menggunakan memori dan CPU untuk semua aliran secara bersamaan. Dalam alur yang dipicu, driver mungkin memproses subset aliran secara paralel pada satu waktu, untuk menghindari batasan memori dan CPU.
Dalam semua kasus ini, memisahkan alur sehingga ada serangkaian alur yang optimal di masing-masing dapat mempercepat inisialisasi dan waktu pemrosesan.
Pertimbangan dalam pemisahan pipeline
Ketika semua alur data Anda berada dalam pipa data yang sama, Lakeflow Spark Declarative Pipelines mengelola dependensi untuk Anda. Ketika ada beberapa alur, Anda harus mengelola dependensi antar alur.
Dependensi Anda mungkin memiliki alur hilir yang bergantung pada beberapa alur upstream (bukan satu). Misalnya, jika Anda memiliki tiga alur,
pipeline_A,pipeline_B, danpipeline_C, danpipeline_Cbergantung pada baikpipeline_Adanpipeline_B, Anda inginpipeline_Cmemperbarui hanya setelahpipeline_Adanpipeline_Btelah menyelesaikan pembaruan masing-masing. Salah satu cara untuk mengatasinya adalah dengan mengatur dependensi dengan membuat setiap alur menjadi tugas dalam pekerjaan dengan dependensi yang dimodelkan dengan benar, jadipipeline_Chanya pembaruan setelah keduanyapipeline_Adanpipeline_Bselesai.Concurrency Anda mungkin memiliki alur yang berbeda dalam pipeline yang membutuhkan waktu sangat berbeda untuk diselesaikan, misalnya, jika
flow_Amemperbarui dalam 15 detik danflow_Bmembutuhkan waktu beberapa menit. Dapat berguna untuk melihat waktu kueri sebelum memisahkan alur kerja Anda, dan mengelompokkan kueri-kueri pendek.
Rencanakan untuk memisahkan jalur pemrosesan Anda
Anda dapat memvisualisasikan pemisahan alur sebelum memulai. Berikut adalah grafik alur sumber yang memproses 25 tabel. Sumber data akar tunggal dibagi menjadi 8 segmen, yang masing-masing memiliki 2 tampilan.
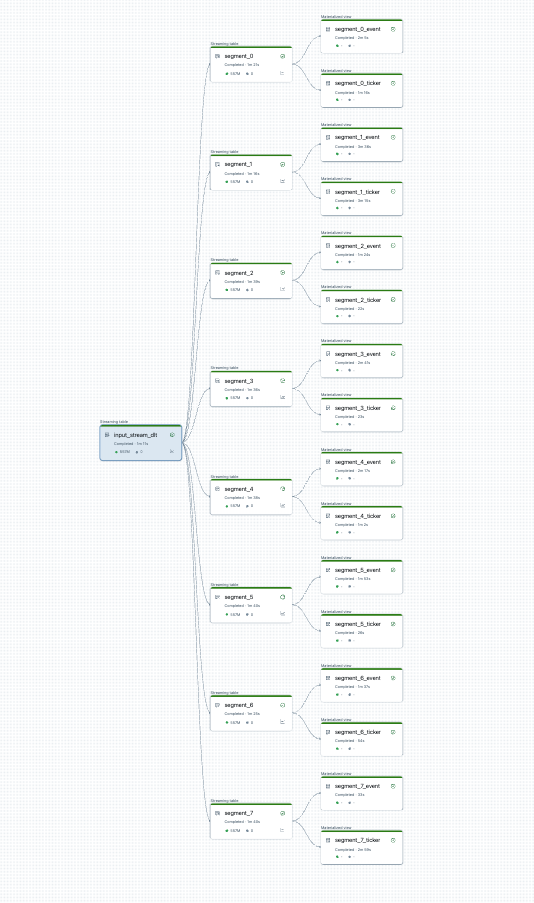
Setelah membagi jalur pemrosesan, ada dua jalur pemrosesan. Satu memproses sumber data akar tunggal, dan 4 segmen dan tampilan terkait. Alur kedua memproses 4 segmen lainnya dan tampilan terkaitnya. Alur kedua bergantung pada yang pertama untuk memperbarui sumber data akar.
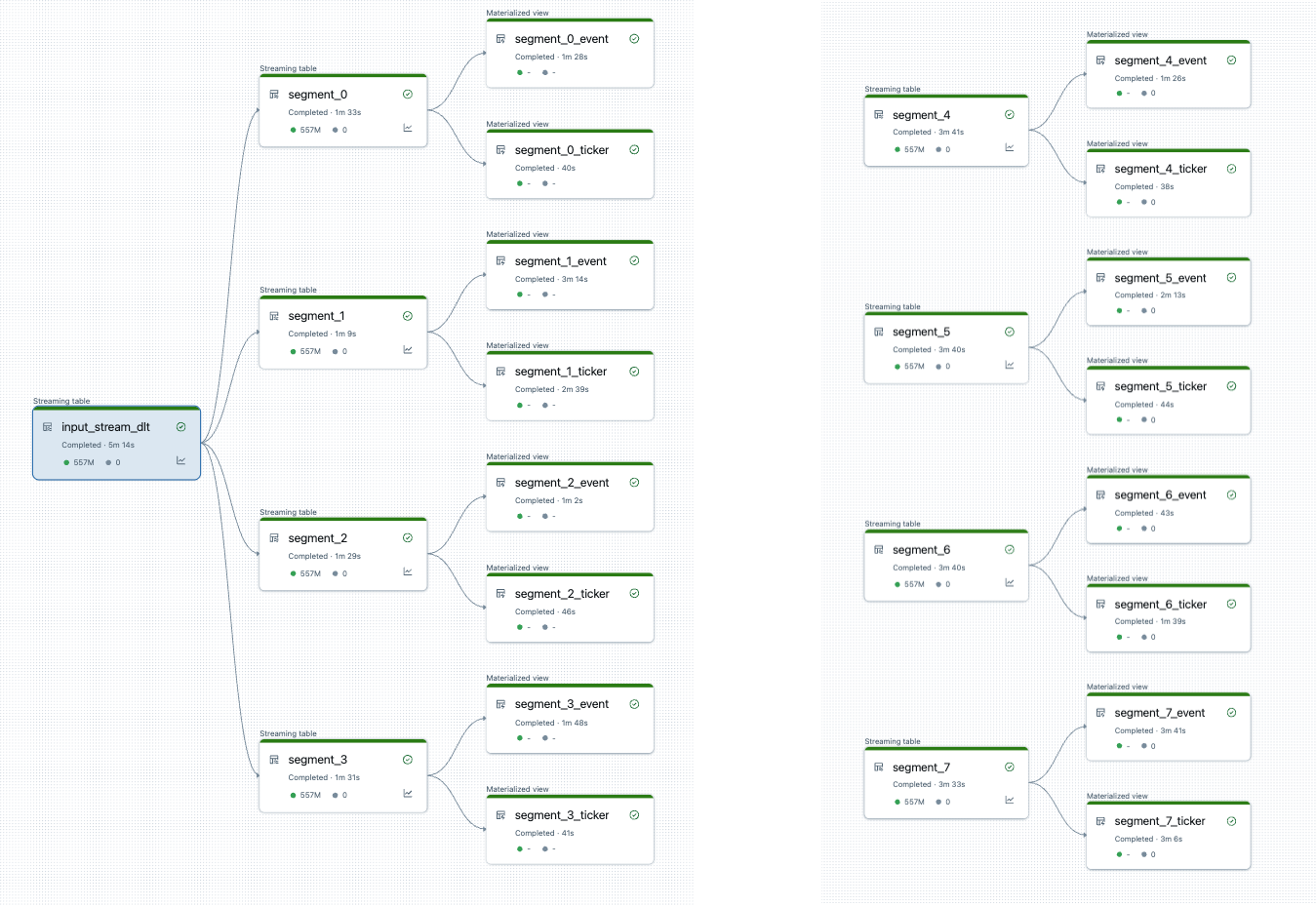
Memisahkan alur pemrosesan tanpa penyegaran penuh
Setelah Anda merencanakan pemisahan alur, buat alur baru yang diperlukan, dan pindahkan tabel antar alur untuk menyeimbangkan beban alur. Anda dapat memindahkan tabel tanpa menyebabkan refresh penuh.
Untuk detailnya, lihat Memindahkan tabel antar alur.
Ada beberapa batasan dengan pendekatan ini:
- Pipeline harus berada di Katalog Unity.
- Alur sumber dan tujuan harus berada dalam ruang kerja yang sama. Pemindahan antar ruang kerja tidak didukung.
- Alur tujuan harus dibuat dan dijalankan sekali (bahkan jika gagal) sebelum pemindahan.
- Anda tidak dapat memindahkan tabel dari alur yang menggunakan mode penerbitan default ke tabel yang menggunakan mode penerbitan lama. Untuk detail selengkapnya, lihat Skema Live (versi lama).