Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tabel Streaming adalah tabel Delta dengan dukungan tambahan untuk pemrosesan data streaming atau inkremental. Tabel Streaming dapat ditargetkan oleh satu atau beberapa alur data dalam sebuah pipeline.
Tabel streaming adalah pilihan yang baik untuk penyerapan data karena alasan berikut:
- Setiap baris input hanya diolah sekali, yang sesuai dengan sebagian besar beban kerja pemasukan data (yaitu, dengan menambahkan atau memperbarui baris ke dalam tabel).
- Mereka dapat menangani data yang hanya bisa ditambahkan dalam volume besar.
Tabel streaming juga merupakan pilihan yang baik untuk transformasi streaming latensi rendah karena dapat beralasan melalui baris dan jendela waktu, menangani volume data yang tinggi, dan menyediakan pemrosesan latensi rendah.
Diagram berikut menunjukkan bagaimana alur dibaca dari sumber streaming dan menulis secara bertahap ke tabel Streaming dalam alur.
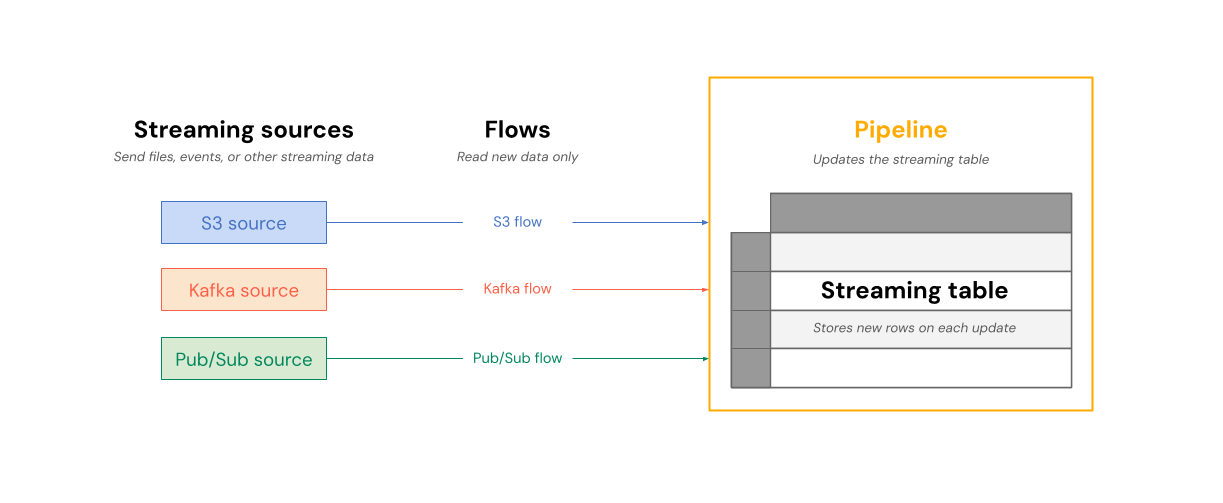
Pada setiap pembaruan, alur yang terkait dengan tabel Streaming membaca informasi yang diubah di sumber streaming, dan menambahkan informasi baru ke tabel tersebut.
Tabel streaming dimiliki dan diperbarui oleh satu alur. Anda secara eksplisit menentukan tabel streaming dalam kode sumber alur. Tabel yang ditentukan oleh alur tidak dapat diubah atau diperbarui oleh alur lain. Anda dapat menentukan beberapa alur untuk ditambahkan ke satu tabel streaming.
Azure Databricks membuat tabel internal untuk mendukung pemrosesan tabel Streaming. Tabel ini muncul di system.information_schema.tables tetapi tidak terlihat di Catalog Explorer atau halaman UI ruang kerja lainnya.
Nota
Saat Anda membuat tabel streaming di luar alur menggunakan Databricks SQL, Azure Databricks membuat alur yang digunakan untuk memperbarui tabel. Anda dapat melihat alur dengan memilih Pekerjaan & Alur dari navigasi kiri di ruang kerja Anda. Anda dapat menambahkan kolom Jenis alur ke tampilan Anda. Tabel streaming yang didefinisikan dalam pipeline memiliki jenis ETL. Tabel streaming yang dibuat di Databricks SQL memiliki jenis MV/ST.
Untuk informasi selengkapnya tentang alur, lihat Memuat dan memproses data secara bertahap dengan alur Alur Deklaratif Lakeflow Spark.
Tabel streaming untuk penyerapan
Tabel streaming dirancang untuk sumber data yang hanya ditambahkan dan memproses input sekali saja. Ini membuatnya sangat cocok untuk beban kerja penyerapan di mana data tiba terus menerus dan harus ditangkap dengan andal tanpa memproses ulang rekaman yang ada. Azure Databricks mendukung penyerapan data dari penyimpanan cloud dan bus pesan streaming.
Menyerap file dari penyimpanan cloud
Anda dapat menggunakan tabel Streaming untuk menyerap file baru dari penyimpanan cloud. Contoh-contoh ini menggunakan Auto Loader untuk memproses file baru secara bertahap saat tiba.
Phyton
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
Untuk membuat tabel Streaming, definisi himpunan data harus merupakan jenis aliran. Saat Anda menggunakan spark.readStream fungsi dalam definisi himpunan data, fungsi mengembalikan himpunan data streaming.
SQL
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
Tabel streaming memerlukan kumpulan data streaming. Kata STREAM kunci sebelum read_files memberi tahu kueri untuk memperlakukan himpunan data sebagai aliran.
Menyerap pesan streaming
Anda juga dapat menggunakan tabel streaming untuk menyerap data dari bus pesan. Contoh berikut menunjukkan cara membuat tabel streaming yang membaca dari topik *Pub/Sub*.
Phyton
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
SQL
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
Databricks merekomendasikan penggunaan rahasia saat memberikan opsi otorisasi. Lihat Mengonfigurasi akses ke Pub/Sub untuk semua opsi autentikasi.
Untuk detail selengkapnya tentang memuat data ke dalam tabel streaming, lihat Memuat data dalam alur.
Diagram berikut mengilustrasikan cara kerja tabel streaming khusus tambahan.
Diagram 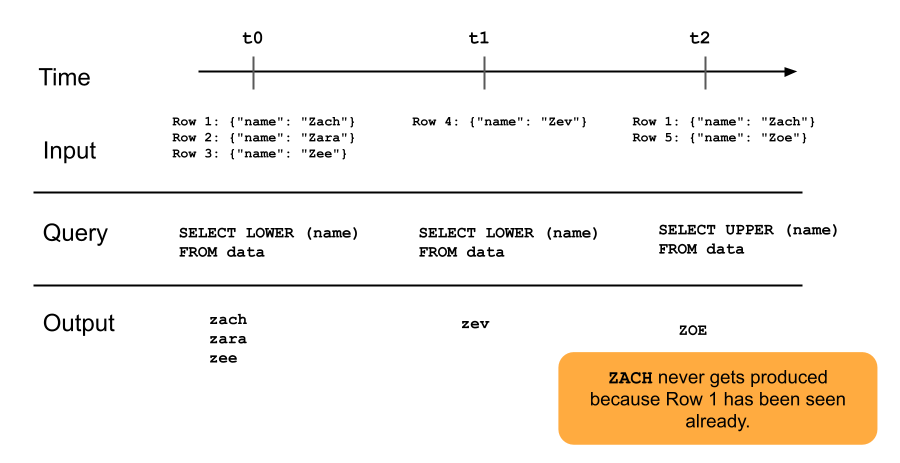
Baris yang telah ditambahkan ke tabel streaming tidak akan dikueri lagi dengan pembaruan alur selanjutnya. Jika Anda mengubah kueri (misalnya, dari SELECT LOWER (name) ke SELECT UPPER (name)), baris yang ada tidak akan diperbarui menjadi huruf besar, tetapi baris baru akan menjadi huruf besar. Anda dapat memicu refresh penuh untuk mengkueri ulang semua data sebelumnya dari tabel sumber untuk memperbarui semua baris dalam tabel Streaming.
Tabel streaming dan streaming latensi rendah
Tabel streaming dirancang untuk streaming dengan latensi rendah di atas keadaan terbatas. Tabel streaming menggunakan manajemen titik pemeriksaan, yang membuatnya sangat cocok untuk streaming latensi rendah. Namun, mereka mengharapkan aliran sungai yang secara alami dibatasi atau dibatasi dengan penanda air.
Aliran yang terikat secara alami diproduksi oleh sumber data streaming yang memiliki awal dan akhir yang terdefinisi dengan baik. Contoh aliran yang terikat secara alami adalah membaca data dari direktori file di mana tidak ada file baru yang ditambahkan setelah batch awal file ditempatkan. Aliran dianggap terikat karena jumlah file terbatas, dan aliran berakhir setelah semua file diproses.
Anda juga dapat menggunakan tanda air untuk membatasi aliran. Tanda air dalam Streaming Terstruktur adalah mekanisme yang membantu menangani data terlambat dengan menentukan berapa lama sistem harus menunggu peristiwa yang tertunda sebelum mempertimbangkan jendela waktu tersebut sebagai selesai. Aliran tidak terbatas yang tidak memiliki marka air dapat menyebabkan alur gagal karena tekanan memori.
Untuk informasi selengkapnya tentang pemrosesan aliran berbasis status, lihat Optimalkan pemrosesan berbasis status dengan penanda waktu.
Gabungan cuplikan aliran
Gabungan salinan bayangan aliran menghubungkan himpunan data streaming ke tabel dimensi yang direkam jepret saat streaming dimulai. Karena tabel dimensi diperlakukan sebagai tetap pada saat itu, setiap perubahan yang dilakukan padanya setelah aliran dimulai tidak tercermin dalam penggabungan. Ini dapat diterima ketika perbedaan kecil tidak masalah — misalnya, ketika jumlah transaksi beberapa kali lipat lebih besar dari jumlah pelanggan.
Sampel kode berikut menggabungkan tabel dimensi dengan dua baris yang disebut customers dengan himpunan data yang terus meningkat, transactions. Ini mewujudkan gabungan antara kedua himpunan data ini dalam tabel yang disebut sales_report. Jika proses luar memperbarui tabel pelanggan dengan menambahkan baris baru (customer_id=3, name=Zoya), baris baru ini tidak akan ada dalam join karena tabel dimensi statis diambil gambarnya saat streaming dimulai.
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
Batasan pada tabel streaming
Tabel streaming memiliki batasan berikut:
-
Evolusi terbatas: Anda dapat mengubah kueri tanpa mengkomputasi ulang seluruh himpunan data. Tanpa refresh penuh, tabel Streaming hanya melihat setiap baris sekali, sehingga kueri yang berbeda akan memproses baris yang berbeda. Misalnya, jika Anda menambahkan
UPPER()ke bidang dalam kueri, hanya baris yang diproses setelah perubahan akan berada dalam huruf besar. Ini berarti Anda harus mengetahui semua versi kueri sebelumnya yang berjalan pada himpunan data Anda. Untuk memproses ulang baris yang sudah ada yang diproses sebelum perubahan, diperlukan refresh penuh. - Pengelolaan status: Tabel streaming dengan latensi rendah memerlukan aliran yang secara alami terbatas atau dibatasi menggunakan penanda air. Untuk informasi selengkapnya, lihat Mengoptimalkan pemrosesan stateful dengan marka air.
- Gabungan tidak mengolah ulang: Gabungan dalam tabel streaming tidak komputasi ulang saat dimensi berubah. Karakteristik ini bisa baik untuk skenario "cepat-tapi-salah". Jika Anda ingin tampilan Anda selalu benar, Anda mungkin ingin menggunakan tampilan Materialisasi. Tampilan terwujud selalu benar karena secara otomatis menghitung ulang penggabungan ketika dimensi berubah. Untuk informasi selengkapnya, lihat tampilan terwujud .