Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini mencakup dua contoh model rekomendasi berbasis pembelajaran mendalam di Azure Databricks. Dibandingkan dengan model rekomendasi tradisional, model pembelajaran mendalam dapat mencapai hasil kualitas yang lebih tinggi dan menskalakan ke jumlah data yang lebih besar. Ketika model-model ini terus berkembang, Databricks menyediakan kerangka kerja untuk melatih model rekomendasi skala besar secara efektif yang mampu menangani ratusan juta pengguna.
Sistem rekomendasi umum dapat dilihat sebagai corong dengan tahapan yang ditunjukkan dalam diagram.
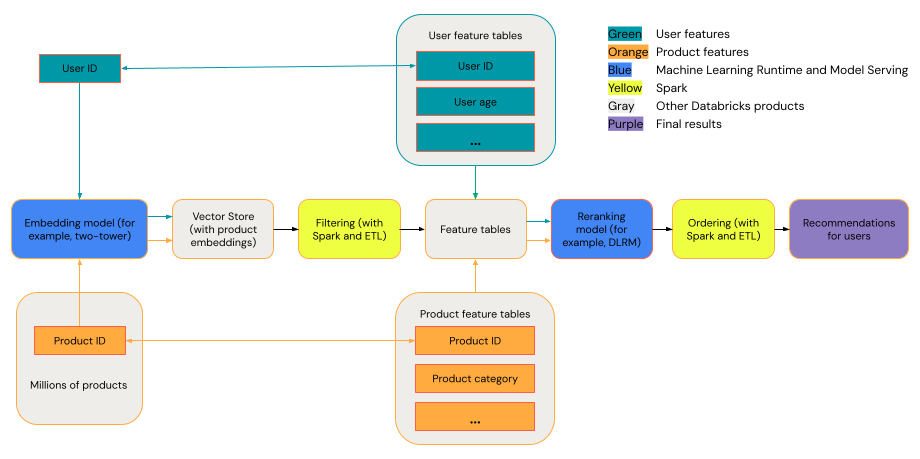
Beberapa model, seperti model dua menara, berkinerja lebih baik sebagai model pencarian. Model-model ini lebih kecil dan dapat beroperasi secara efektif pada jutaan titik data. Model lain, seperti DLRM atau DeepFM, berkinerja lebih baik sebagai model reranking. Model-model ini dapat menerima lebih banyak data, memiliki kapasitas lebih besar, dan dapat memberikan rekomendasi yang terperinci.
Persyaratan
Databricks Runtime 14.3 LTS ML
Alat
Contoh dalam artikel ini mengilustrasikan alat berikut:
- TorchDistributor: TorchDistributor adalah kerangka kerja yang memungkinkan Anda menjalankan pelatihan model PyTorch skala besar pada Databricks. Ini menggunakan Spark untuk orkestrasi dan dapat menskalakan ke GPU sebanyak yang tersedia di kluster Anda.
- Mosaic StreamingDataset: StreamingDataset meningkatkan performa dan skalabilitas pelatihan pada himpunan data besar pada Databricks menggunakan fitur seperti prefetching dan interleaving.
- MLflow: MLflow memungkinkan Anda melacak parameter, metrik, dan titik pemeriksaan model.
- TorchRec: Sistem rekomendasi modern menggunakan tabel pencarian embedding untuk menangani jutaan pengguna dan produk guna menghasilkan rekomendasi berkualitas tinggi. Ukuran penyematan yang lebih besar meningkatkan performa model tetapi memerlukan memori GPU yang substansial dan penyiapan multi-GPU. TorchRec menyediakan kerangka kerja untuk menskalakan model rekomendasi dan tabel pencarian di beberapa GPU, membuatnya ideal untuk penyematan besar.
Contoh: Rekomendasi film menggunakan arsitektur model dua menara
Model dua menara dirancang untuk menangani tugas personalisasi skala besar dengan memproses data pengguna dan item secara terpisah sebelum menggabungkannya. Ini mampu menghasilkan ratusan atau ribuan rekomendasi kualitas yang layak secara efisien. Model umumnya mengharapkan tiga input: Fitur user_id, fitur product_id, dan label biner yang menentukan apakah <pengguna, interaksi produk> positif (pengguna membeli produk) atau negatif (pengguna memberi produk peringkat bintang satu). Output model adalah penyematan untuk pengguna dan item, yang kemudian umumnya digabungkan (sering menggunakan produk titik atau kesamaan kosinus) untuk memprediksi interaksi item pengguna.
Karena model dua menara menyediakan penyematan untuk pengguna dan produk, Anda dapat menempatkan penyematan ini dalam indeks vektor, seperti Mosaic AI Vector Search, dan melakukan operasi seperti pencarian kesamaan pada pengguna dan item. Misalnya, Anda dapat menempatkan semua item di penyimpanan vektor, dan untuk setiap pengguna, melakukan kueri pada penyimpanan vektor untuk menemukan seratus item teratas yang embedding-nya mirip dengan pengguna.
Contoh notebook berikut mengimplementasikan pelatihan model dua menara menggunakan himpunan data "Belajar dari Set Item" untuk memprediksi kemungkinan pengguna akan menilai film tertentu dengan sangat tinggi. Ini menggunakan Mosaic StreamingDataset untuk pemuatan data terdistribusi, TorchDistributor untuk pelatihan model terdistribusi, dan MLflow untuk pelacakan dan pengelogan model.
Notebook model pemberi rekomendasi dua menara
Ambil buku catatan
Notebook ini juga tersedia di Databricks Marketplace: Notebook model dua menara
Catatan
- Input untuk model dua menara paling sering merupakan fitur kategoris user_id dan product_id. Model dapat dimodifikasi untuk mendukung beberapa vektor fitur untuk pengguna dan produk.
- Output untuk model dua menara biasanya merupakan nilai biner yang menunjukkan apakah pengguna akan memiliki interaksi positif atau negatif dengan produk. Model ini dapat dimodifikasi untuk aplikasi lain seperti regresi, klasifikasi multi-kelas, dan probabilitas untuk beberapa tindakan pengguna (misalnya, mengabaikan atau membeli). Output kompleks harus diimplementasikan dengan hati-hati, karena objektif yang saling bersaing dapat menurunkan kualitas embedding yang dihasilkan oleh model.
Contoh: Melatih arsitektur DLRM menggunakan himpunan data sintetis
DLRM adalah arsitektur jaringan neural canggih yang dirancang khusus untuk sistem personalisasi dan rekomendasi. Ini menggabungkan input kategoris dan numerik untuk memodelkan interaksi item pengguna secara efektif dan memprediksi preferensi pengguna. DLRM umumnya mengharapkan input yang mencakup fitur jarang (seperti ID pengguna, ID item, lokasi geografis, atau kategori produk) dan fitur padat (seperti usia pengguna atau harga item). Output dari DLRM biasanya merupakan prediksi keterlibatan pengguna, seperti rasio klik-tayang atau kemungkinan pembelian.
DLRM menawarkan kerangka kerja yang sangat dapat disesuaikan yang dapat menangani data skala besar, sehingga cocok untuk tugas rekomendasi yang kompleks di berbagai domain. Karena merupakan model yang lebih besar daripada arsitektur dua menara, model ini sering digunakan dalam tahap reranking.
Contoh notebook berikut membangun model DLRM untuk memprediksi label biner menggunakan fitur padat (numerik) dan fitur jarang (kategoris). Ini menggunakan himpunan data sintetis untuk melatih model, Mosaic StreamingDataset untuk pemuatan data terdistribusi, TorchDistributor untuk pelatihan model terdistribusi, dan MLflow untuk pelacakan dan pengelogan model.
Buku catatan DLRM
Ambil buku catatan
Notebook ini juga tersedia di Databricks Marketplace: notebook DLRM.
Perbandingan model dua menara dan DLRM
Tabel memperlihatkan beberapa panduan untuk memilih model pemberi rekomendasi mana yang akan digunakan.
| Jenis model | Ukuran himpunan data yang diperlukan untuk pelatihan | Ukuran Model | Jenis input yang didukung | Tipe output yang didukung | Kasus penggunaan |
|---|---|---|---|---|---|
| Dua menara | Lebih kecil | Lebih kecil | Biasanya dua fitur (user_id, product_id) | Terutama klasifikasi biner dan generasi embedding | Menghasilkan ratusan atau ribuan rekomendasi yang mungkin |
| DLRM | Lebih besar | Lebih besar | Berbagai fitur kategoris dan padat (user_id, jenis kelamin, geographic_location, product_id, product_category, ...) | Klasifikasi multi-kelas, regresi, lainnya | Pengambilan sangat rinci (merekomendasikan puluhan item yang sangat relevan) |
Singkatnya, model dua menara paling baik digunakan untuk menghasilkan ribuan rekomendasi kualitas yang baik dengan sangat efisien. Contohnya mungkin rekomendasi film dari penyedia kabel. Model DLRM paling baik digunakan untuk menghasilkan rekomendasi yang sangat spesifik berdasarkan lebih banyak data. Contohnya mungkin peritel yang ingin menyajikan kepada pelanggan jumlah item yang lebih kecil yang kemungkinan besar mereka beli.