Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Model MLflow adalah format standar untuk mengemas model pembelajaran mesin yang dapat digunakan dalam berbagai alat hilir—misalnya, inferensi batch pada Apache Spark atau penyajian real time melalui REST API. Format ini mendefinisikan konvensi yang memungkinkan Anda menyimpan model dalam berbagai rasa (fungsi python, pytorch, sklearn, dan sebagainya), yang dapat dipahami oleh berbagai platform penyajian model dan inferensi.
Untuk mempelajari cara mencatat dan menilai model streaming, lihat Cara menyimpan dan memuat model streaming.
MLflow 3 memperkenalkan peningkatan signifikan pada model MLflow dengan memperkenalkan objek khusus baru LoggedModel dengan metadatanya sendiri seperti metrik dan parameter. Untuk detail selengkapnya, lihat Melacak dan membandingkan model menggunakan MLflow Logged Models.
Log dan muat model
Saat Anda mencatat model, MLflow secara otomatis mencatat requirements.txt dan conda.yaml file. Anda dapat menggunakan file-file ini untuk membuat ulang lingkungan pengembangan model dan menginstal ulang dependensi menggunakan virtualenv (disarankan) atau conda.
Penting
Anaconda Inc. memperbarui ketentuan layanan mereka untuk saluran anaconda.org. Berdasarkan ketentuan layanan baru, Anda mungkin memerlukan lisensi komersial jika Anda mengandalkan pengemasan dan distribusi Anaconda. Lihat Tanya Jawab Umum Edisi Komersial Anaconda untuk informasi selengkapnya. Penggunaan Anda atas setiap saluran Anaconda diatur oleh persyaratan layanan mereka.
Model MLflow yang dicatat sebelum v1.18 (Databricks Runtime 8.3 ML atau yang lebih lama) secara default dicatat dengan saluran conda defaults (https://repo.anaconda.com/pkgs/) sebagai dependensi. Karena perubahan lisensi ini, Databricks telah menghentikan penggunaan saluran defaults untuk model yang dicatat menggunakan MLflow v1.18 dan di atasnya. Saluran default yang dicatat sekarang adalah conda-forge, yang menunjuk pada komunitas yang dikelola https://conda-forge.org/.
Jika Anda mencatat model sebelum MLflow v1.18 tanpa mengecualikan saluran defaults dari lingkungan conda untuk model tersebut, model tersebut mungkin memiliki dependensi pada saluran defaults yang mungkin tidak Anda maksudkan.
Untuk mengonfirmasi secara manual apakah model memiliki dependensi ini, Anda dapat memeriksa nilai channel dalam file conda.yaml yang dikemas dengan model yang dicatat. Misalnya, model conda.yaml dengan saluran yang memiliki ketergantungan defaults mungkin terlihat seperti ini:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Karena Databricks tidak dapat menentukan apakah penggunaan Anda atas repositori Anaconda untuk berinteraksi dengan model Anda diizinkan berdasarkan hubungan Anda dengan Anaconda, Databricks tidak memaksa pelanggannya untuk membuat perubahan apa pun. Jika penggunaan Anda atas repositori Anaconda.com melalui penggunaan Databricks diizinkan berdasarkan persyaratan Anaconda, Anda tidak perlu mengambil tindakan apa pun.
Jika Anda ingin mengubah saluran yang digunakan di lingkungan model, Anda dapat mendaftarkan ulang model ke registri model dengan baru conda.yaml. Anda dapat melakukannya dengan menentukan saluran di parameter conda_env dari log_model().
Untuk informasi selengkapnya tentang log_model() API, lihat dokumentasi MLflow untuk ragam model yang sedang Anda kerjakan, misalnya, log_model untuk scikit-learn.
Untuk informasi selengkapnya tentang conda.yaml file, lihat dokumentasi MLflow.
Perintah API
Untuk mencatat model ke server pelacakan MLflow, gunakan mlflow.<model-type>.log_model(model, ...).
Untuk memuat model yang dicatat sebelumnya untuk inferensi atau pengembangan lebih lanjut, gunakan mlflow.<model-type>.load_model(modelpath), di mana modelpath adalah salah satu hal berikut:
- jalur model (seperti
models:/{model_id}) (hanya MLflow 3 ) - jalur relatif run (seperti
runs:/{run_id}/{model-path}) - jalur volume pada Unity Catalog (seperti
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - jalur penyimpanan artefak yang dikelola MLflow dimulai dengan
dbfs:/databricks/mlflow-tracking/ - jalur model terdaftar (seperti
models:/{model_name}/{model_stage}).
Untuk daftar lengkap opsi untuk memuat model MLflow, lihat Mereferensikan Artefak dalam dokumentasi MLflow.
Untuk model Python MLflow, opsi tambahan adalah menggunakan mlflow.pyfunc.load_model() untuk memuat model sebagai fungsi Python generik.
Anda dapat menggunakan cuplikan kode berikut untuk memuatkan model dan menilai poin data.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
Sebagai alternatif, Anda dapat mengekspor model sebagai Apache Spark UDF untuk digunakan untuk penilaian pada kluster Spark, baik sebagai pekerjaan batch atau sebagai pekerjaan Spark Streaming real time.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Dependensi model logaritma
Untuk memuat model secara akurat, Anda sebaiknya memastikan dependensi model dimuat dengan versi yang benar ke lingkungan notebook. Dalam Databricks Runtime 10.5 ML ke atas, MLflow memperingatkan Anda jika ketidakcocokan terdeteksi antara lingkungan saat ini dan dependensi model.
Fungsionalitas tambahan untuk menyederhanakan pemulihan dependensi model disertakan dalam Databricks Runtime 11.0 ML dan yang lebih baru. Dalam Databricks Runtime 11.0 ML dan yang lebih baru, untuk model flavor pyfunc, Anda dapat memanggil mlflow.pyfunc.get_model_dependencies untuk mengambil dan mengunduh dependensi model. Fungsi ini mengembalikan jalur ke file dependensi yang kemudian dapat Anda pasang dengan menggunakan %pip install <file-path>. Saat Anda memuat model sebagai UDF PySpark, tentukan env_manager="virtualenv" dalam panggilan mlflow.pyfunc.spark_udf. Ini akan memulihkan dependensi model dalam konteks UDF PySpark dan tidak memengaruhi lingkungan luar.
Anda juga dapat menggunakan fungsionalitas ini di Databricks Runtime 10.5 atau di bawahnya dengan menginstal MLflow versi 1.25.0 atau lebih tinggi secara manual:
%pip install "mlflow>=1.25.0"
Untuk informasi tambahan tentang cara mencatat dependensi model (Python dan non-Python) dan artefak, lihat Dependensi model log.
Pelajari cara mencatat dependensi model dan artefak kustom untuk penyajian model:
- Menyebarkan model dengan dependensi
- Menggunakan pustaka Python kustom dengan Model Serving
- Mengemas artefak kustom untuk Model Serving
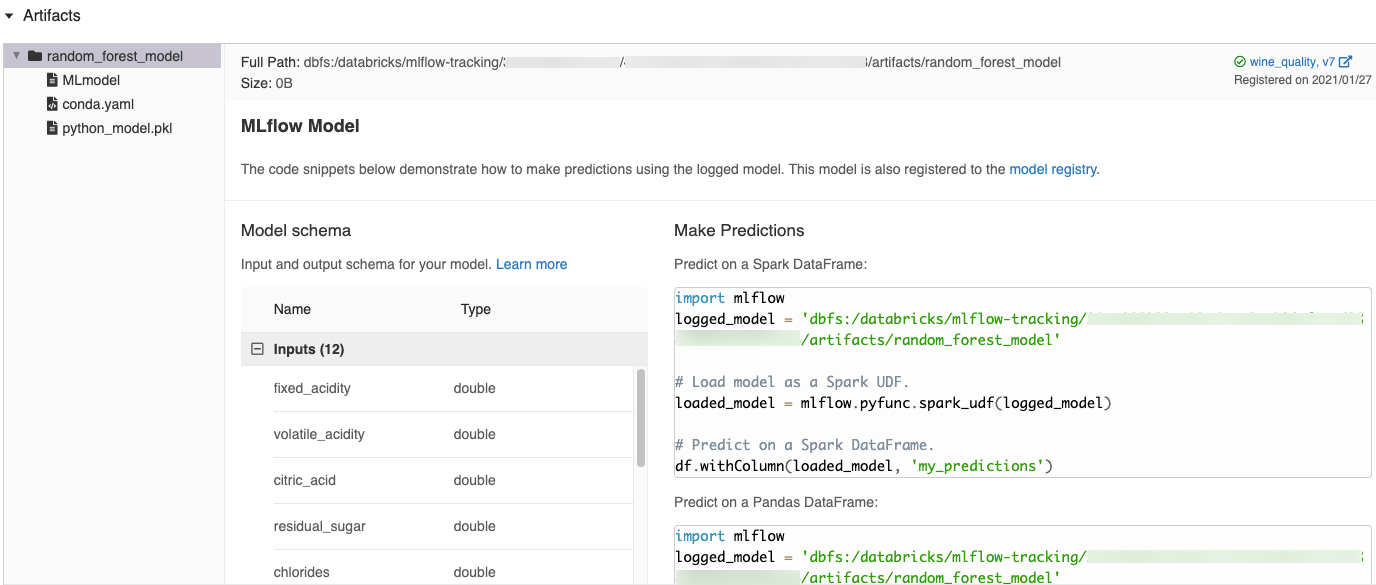
Cuplikan kode yang dihasilkan secara otomatis di UI MLflow
Saat Anda mencatat model di buku catatan Azure Databricks, Azure Databricks secara otomatis menghasilkan cuplikan kode yang dapat Anda salin dan gunakan untuk memuat dan menjalankan model. Untuk melihat cuplikan kode ini:
- Pergi ke layar Hasil untuk proses yang menghasilkan model. (Lihat View notebook experiment untuk cara menampilkan layar Run.)
- Gulir ke bagian Artefak .
- Klik nama model yang dicatat. Panel terbuka ke kanan menampilkan kode yang dapat Anda gunakan untuk memuat model yang dicatat dan membuat prediksi pada Spark atau pandas DataFrames.
Contoh
Untuk contoh model pengelogan, lihat contoh dalam Melacak contoh eksekusi pelatihan pembelajaran mesin.
Mendaftarkan model di Registri Model
Anda dapat mendaftarkan model di MLflow Model Registry, penyimpanan model terpusat yang menyediakan UI dan set API untuk mengelola siklus hidup penuh Model MLflow. Untuk petunjuk tentang cara menggunakan Registri Model untuk mengelola model di Databricks Unity Catalog, lihat Mengelola siklus hidup model di Unity Catalog. Untuk menggunakan Registri Model Ruang Kerja, lihat Mengelola siklus hidup model menggunakan Registri Model Ruang Kerja (warisan).
Saat model yang dibuat dengan MLflow 3 didaftarkan ke registri model Unity Catalog, Anda dapat melihat data seperti parameter dan metrik di satu lokasi pusat, di semua eksperimen dan ruang kerja. Untuk informasi, lihat Peningkatan Registri Model dengan MLflow 3.
Untuk mendaftarkan model menggunakan API, gunakan perintah berikut:
MLflow 3
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
MLflow 2.x
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
Menyimpan model ke volume Katalog Unity
Untuk menyimpan model secara lokal, gunakan mlflow.<model-type>.save_model(model, modelpath).
modelpath harus berupa jalur volume Katalog Unity . Misalnya, jika Anda menggunakan lokasi volume Unity Catalog dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models untuk menyimpan pekerjaan proyek, Anda harus menggunakan jalur model /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models:
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
Untuk model MLlib, gunakan Alur ML.
Unduh artefak model
Anda dapat mengunduh artefak model yang dicatat (seperti file model, plot, dan metrik) untuk model terdaftar dengan berbagai API.
Contoh API Python:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Contoh Java API:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
Contoh perintah CLI:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Menerapkan model untuk layanan online
Nota
Sebelum menyebarkan model Anda, sebaiknya memverifikasi bahwa model dapat dijalankan. Lihat dokumentasi MLflow tentang cara yang dapat Anda gunakan mlflow.models.predict untuk memvalidasi model sebelum penyebaran.
Gunakan Mosaic AI Model Serving untuk menghosting model pembelajaran mesin yang terdaftar di registri model Unity Catalog sebagai endpoint REST. Titik akhir ini diperbarui secara otomatis berdasarkan ketersediaan versi model.