Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Lakebase Autoscaling adalah versi terbaru Lakebase, dengan komputasi penskalaan otomatis, skala-ke-nol, percabangan, dan pemulihan instan. Untuk wilayah yang didukung, lihat Ketersediaan wilayah. Jika Anda adalah pengguna Lakebase Provisioned, lihat Lakebase Provisioned.
Lakebase Postgres Autoscaling adalah database Postgres yang dikelola sepenuhnya yang dibangun untuk aplikasi apa pun yang memerlukan pemrosesan transaksi online (OLTP) dan penyajian data latensi rendah. Ini diintegrasikan ke dalam platform Databricks, memungkinkan Anda untuk membangun aplikasi transaksional real time bersama beban kerja analitik Anda.
Autoscaling Lakebase Postgres menggabungkan keandalan dan keakraban Postgres dengan kemampuan database modern termasuk penskalaan otomatis, skala-ke-nol, pembuatan cabang, dan pemulihan cepat. Fitur-fitur ini memungkinkan alur kerja pengembangan yang fleksibel, operasi hemat biaya, dan iterasi yang cepat.
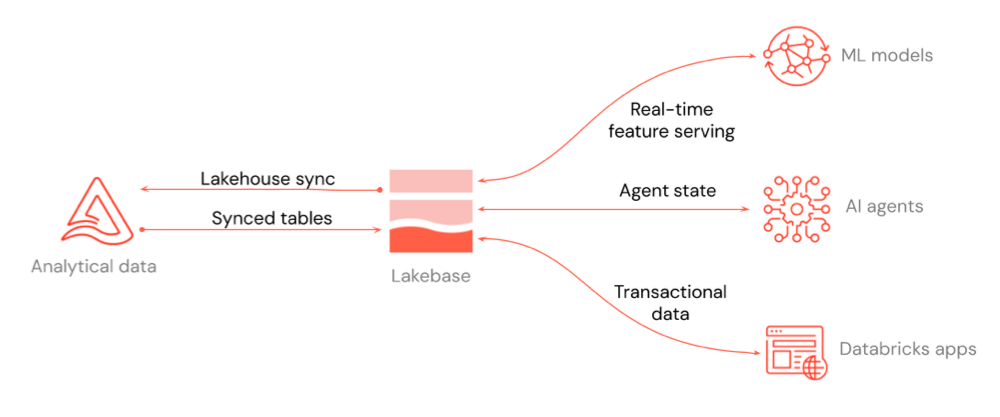
Diagram menunjukkan bagaimana Lakebase terintegrasi dengan platform lainnya: fitur real-time yang berfungsi untuk model ML dan Penyimpanan Fitur, status agen untuk agen AI, dan data transaksional untuk Aplikasi Databricks atau aplikasi apa pun yang Anda sambungkan ke dalamnya.
Anda dapat memindahkan data ke salah satu arah antara lakehouse dan Lakebase Anda. Tabel yang disinkronkan memindahkan data dari lakehouse ke Lakebase sehingga aplikasi Anda dapat mengkuerinya dengan latensi rendah.
Contoh kasus penggunaan dan jenis beban kerja
Berikut ini hanya beberapa contoh dari banyak cara Anda dapat menggunakan database OLTP Postgres seperti Lakebase di seluruh industri: rekomendasi yang dipersonalisasi dan menawarkan penargetan dalam e-niaga dan ritel, data uji klinis dan sistem rekomendasi dalam layanan kesehatan, analitik perdagangan dan streaming otomatis dalam layanan keuangan, dan telemetri mesin dan alur kerja pemeliharaan dalam manufaktur.
Jenis beban kerja umum untuk database OLTP dapat mencakup hal berikut:
- Penyajian data: Sajikan wawasan dari tabel emas ke aplikasi dengan latensi rendah dan QPS tinggi.
- Simpan status aplikasi: Mengelola alur kerja dan status agen di penyimpanan data transaksional.
- Penyajian fitur: Menyajikan data dengan latensi rendah ke model ML.
Integrasi Databricks
Diagram di atas menyoroti tiga kasus penggunaan integrasi utama:
- Penyajian fitur real-time: Gunakan proyek Lakebase sebagai toko online untuk model ML dan Penyimpanan Fitur, sehingga Anda dapat menyajikan data yang difeaturisasi dengan latensi rendah. Lihat Toko Fitur Online (Lakebase) dan Penyajian Fitur.
- Status agen untuk agen AI: Simpan dan kelola status untuk agen AI dalam database transaksional, sehingga percakapan dan konteks alur kerja tetap ada di seluruh permintaan.
- Data transaksi untuk aplikasi: Menyimpan data untuk Aplikasi Databricks atau aplikasi apa pun yang Anda sambungkan ke Lakebase. Untuk Aplikasi Databricks, tambahkan proyek Lakebase sebagai sumber daya aplikasi. Lihat Menambahkan sumber daya Lakebase ke aplikasi Databricks.
Lakebase Diprovisikan
Lakebase Provisioned adalah penawaran Lakebase asli yang menggunakan komputasi yang disediakan yang Anda skalakan secara manual. Instans yang disediakan akan terus didukung. Pengembangan New Lakebase berfokus pada Autoscaling. Jika Anda memiliki instans yang Disediakan atau sedang mengevaluasi kedua opsi, lihat Apa itu Lakebase Provisioned? dan Autoscaling secara default.
Apa itu proyek?
Sumber daya autoscaling Lakebase diatur ke dalam struktur proyek. Proyek adalah kontainer tingkat atas untuk sumber daya database Anda. Saat Anda membuat database Lakebase Autoscaling, Anda membuat proyek. Proyek ini menyimpan cabang Anda, lingkungan database, komputasi, peran, dan basis data. Anggap proyek sebagai unit organisasi untuk satu aplikasi atau beban kerja. Anda dapat memiliki beberapa proyek di ruang kerja, masing-masing dengan cabang dan datanya sendiri.
Bagaimana proyek diatur
Memahami hierarki objek dalam proyek membantu Anda mengatur dan mengelola sumber daya Anda:
Databricks Workspace
└── Project(s)
└── Branch(es)
├── Compute (primary R/W)
├── Read replica(s) (optional)
├── Role(s)
└── Database(s)
└── Schema(s)
Setiap tingkat dalam hierarki melayani tujuan tertentu:
| Objek | Description |
|---|---|
| Project | Kontainer tingkat atas untuk sumber daya database Anda. Proyek berisi cabang, database, peran, dan sumber daya komputasi. Lihat Mengelola proyek. |
| Cabang | Lingkungan database terisolasi yang berbagi penyimpanan dengan cabang induknya. Setiap proyek dapat berisi beberapa cabang. Lihat mengelola cabang. |
| Menghitung | Server Postgres yang mendukung cabang. Setiap cabang memiliki komputasinya sendiri yang menyediakan daya pemrosesan dan memori untuk operasi database. Lihat Mengelola komputasi. |
| Database | Database Postgres standar dalam cabang. Setiap cabang dapat berisi beberapa database dengan tabel, skema, dan data mereka sendiri. Lihat Mengelola database. |
Memahami cabang
Salah satu fitur Lakebase Postgres yang paling kuat adalah pencabangan. Seperti cabang Git untuk kode Anda, cabang memungkinkan Anda membuat lingkungan database terisolasi untuk pengembangan dan pengujian—tanpa memengaruhi produksi.
Mengapa hal ini penting: Alur kerja database tradisional memerlukan server dev dan staging terpisah, refresh data manual, dan koordinasi yang cermat. Dengan cabang, Anda dapat:
- Membuat lingkungan pengembangan secara instan dengan data produksi
- Menguji perubahan skema dengan aman sebelum menerapkannya ke produksi
- Pulihkan dari kesalahan dengan membuat cabang dari titik waktu mana pun
- Bayar hanya untuk data yang Anda ubah, bukan database duplikat penuh
| Topik | Description |
|---|---|
| Cabang | Pelajari cara kerja cabang, alur kerja umum, dan praktik terbaik untuk tim Anda. |
| Mengelola cabang | Membuat, mengatur ulang, dan menghapus cabang untuk pengembangan dan pengujian. |
| Cabang yang dilindungi | Lindungi cabang produksi dari perubahan dan penghapusan yang tidak disengaja. |
Konsep inti
Lakebase dibangun di atas beberapa inovasi utama yang membedakannya dari sistem database tradisional:
- Komputasi dan penyimpanan yang dipisahkan: Menskalakan sumber daya komputasi secara independen dari penyimpanan untuk efisiensi dan fleksibilitas biaya.
- Autoscaling: Komputasi secara otomatis menyesuaikan berdasarkan permintaan beban kerja, dengan dukungan untuk skala ke nol selama periode diam.
- Penyimpanan berbasis salin saat tulis: Memungkinkan percabangan instan di mana Anda hanya membayar perubahan data, bukan duplikat penuh.
- Operasi point-in-time instan: Buat cabang atau kembalikan ke titik waktu mana saja dalam jangka waktu pemulihan yang telah dikonfigurasi (2-30 hari)
Konsep-konsep ini bekerja sama untuk memungkinkan alur kerja pengembangan yang fleksibel, operasi hemat biaya, dan pemulihan yang cepat dari kesalahan.
Untuk penjelasan terperinci tentang setiap konsep inti, lihat Konsep inti.