Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Halaman ini memberikan gambaran umum tentang alat dan pendekatan untuk mengekspor data dan konfigurasi dari ruang kerja Azure Databricks Anda. Anda dapat mengekspor aset ruang kerja untuk persyaratan kepatuhan, portabilitas data, tujuan pencadangan, atau migrasi ruang kerja.
Gambaran Umum
Ruang kerja Azure Databricks berisi berbagai aset termasuk konfigurasi ruang kerja, tabel terkelola, objek AI dan ML, dan data yang disimpan di penyimpanan cloud. Saat Anda perlu mengekspor data ruang kerja, Anda dapat menggunakan kombinasi alat dan API bawaan untuk mengekstrak aset ini secara sistematis.
Alasan umum untuk mengekspor data ruang kerja meliputi:
- Persyaratan kepatuhan: Memenuhi kewajiban portabilitas data berdasarkan peraturan seperti GDPR dan CCPA.
- Pencadangan dan pemulihan bencana: Membuat salinan aset ruang kerja penting untuk kelangsungan bisnis.
- Migrasi ruang kerja: Memindahkan aset antara ruang kerja atau penyedia cloud.
- Audit dan pengarsipan: Mempertahankan catatan historis konfigurasi dan data ruang kerja.
Rencanakan ekspor Anda
Sebelum Anda mulai mengekspor data ruang kerja, buat inventaris aset yang perlu Anda ekspor dan pahami dependensi di antaranya.
Memahami aset ruang kerja
Ruang kerja Azure Databricks Anda berisi beberapa kategori aset yang dapat Anda ekspor:
- Konfigurasi ruang kerja: Notebook, folder, repos, rahasia, pengguna, grup, daftar kontrol akses (ACL), konfigurasi kluster, dan definisi pekerjaan.
- Aset data: Tabel terkelola, database, file Databricks File System, dan data yang disimpan di penyimpanan cloud.
- Sumber daya komputasi: Konfigurasi kluster, kebijakan, dan definisi kumpulan instans.
- Aset AI dan ML: Eksperimen MLflow, pelaksanaan, model, tabel Feature Store, indeks Pencarian Vektor, dan model Unity Catalog.
- Objek Unity Catalog: Konfigurasi metastore, katalog, skema, tabel, volume, dan hak akses.
Cakupan ekspor Anda
Buat daftar periksa aset untuk diekspor berdasarkan kebutuhan Anda. Pertimbangkan pertanyaan berikut:
- Apakah Anda perlu mengekspor semua aset atau hanya kategori tertentu?
- Apakah ada persyaratan kepatuhan atau keamanan yang menentukan aset mana yang harus Anda ekspor?
- Apakah Anda perlu mempertahankan hubungan antara aset (misalnya, pekerjaan yang mereferensikan notebook)?
- Apakah Anda perlu membuat ulang konfigurasi ruang kerja di lingkungan lain?
Merencanakan cakupan ekspor membantu Anda memilih alat yang tepat dan menghindari dependensi kritis yang hilang.
Mengekspor konfigurasi ruang kerja
Pengekspor Terraform adalah alat utama untuk mengekspor konfigurasi ruang kerja. Ini menghasilkan file konfigurasi Terraform yang mewakili aset ruang kerja Anda sebagai kode.
Menggunakan pengekspor Terraform
Pengekspor Terraform dibangun ke dalam penyedia Terraform Azure Databricks dan menghasilkan file konfigurasi Terraform untuk sumber daya ruang kerja termasuk notebook, pekerjaan, kluster, pengguna, grup, rahasia, dan daftar kontrol akses. Pengekspor harus dijalankan secara terpisah untuk setiap ruang kerja. Lihat Penyedia Databricks Terraform.
Prasyarat:
- Terraform terinstal pada komputer Anda
- Autentikasi Azure Databricks telah dikonfigurasi.
- Hak istimewa admin pada ruang kerja yang ingin Anda ekspor
Untuk mengekspor sumber daya ruang kerja:
Tinjau video penggunaan contoh untuk pengenalan pengekspor.
Unduh dan instal penyedia Terraform dengan alat pengekspor:
wget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|') unzip -d terraform-provider-databricks terraform-provider-databricks.zipSiapkan variabel lingkungan autentikasi untuk ruang kerja Anda:
export DATABRICKS_HOST=https://your-workspace-url export DATABRICKS_TOKEN=your-tokenJalankan pengekspor untuk menghasilkan file konfigurasi Terraform:
terraform-provider-databricks exporter \ -directory ./exported-workspace \ -listing notebooks,jobs,clusters,users,groups,secretsOpsi pengekspor umum:
-
-listing: Tentukan jenis sumber daya yang akan diekspor (dipisahkan koma) -
-services: Alternatif daftar untuk memfilter sumber daya -
-directory: Direktori output untuk file yang dihasilkan.tf -
-incremental: Jalankan dalam mode inkremental untuk migrasi bertahap
-
Tinjau file yang dihasilkan
.tfdi direktori output. Pengekspor membuat satu file untuk setiap jenis sumber daya.
Nota
Pengekspor Terraform berfokus pada konfigurasi ruang kerja dan metadata. Ini tidak mengekspor data aktual yang disimpan dalam tabel atau Databricks File System. Anda harus mengekspor data secara terpisah menggunakan pendekatan yang dijelaskan di bagian berikut.
Mengekspor jenis aset tertentu
Untuk aset yang tidak sepenuhnya dicakup oleh pengekspor Terraform, gunakan pendekatan berikut:
- Buku Catatan: Unduh buku catatan satu per satu dari UI ruang kerja atau gunakan API Ruang Kerja untuk mengekspor buku catatan secara terprogram. Lihat Mengelola objek ruang kerja.
- Rahasia: Rahasia tidak dapat diekspor secara langsung karena alasan keamanan. Anda harus membuat ulang rahasia secara manual di lingkungan target. Mendokumentasikan nama-nama dan ruang lingkup rahasia untuk referensi.
- Objek MLflow: Gunakan alat mlflow-export-import untuk mengekspor eksperimen, eksekusi, dan model. Lihat bagian Aset ML di bawah ini.
Mengekspor data
Data pelanggan biasanya berada di penyimpanan akun cloud Anda, bukan di Azure Databricks. Anda tidak perlu mengekspor data yang sudah ada di penyimpanan cloud Anda. Namun, Anda perlu mengekspor data yang disimpan di lokasi yang dikelola Azure Databricks.
Mengekspor tabel terkelola
Meskipun tabel terkelola berada dalam penyimpanan cloud Anda, tabel tersebut disimpan dalam hierarki berbasis UUID yang mungkin sulit diurai. Anda dapat menggunakan DEEP CLONE perintah untuk menulis ulang tabel terkelola sebagai tabel eksternal di lokasi tertentu, membuatnya lebih mudah dikerjakan.
Contoh DEEP CLONE perintah:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
Untuk skrip lengkap untuk mengkloning semua tabel dalam daftar katalog, lihat contoh skrip di bawah ini.
Mengekspor penyimpanan default Databricks
Untuk ruang kerja tanpa server, Azure Databricks menawarkan penyimpanan default, yang merupakan solusi penyimpanan yang dikelola sepenuhnya dalam akun Azure Databricks. Data dalam penyimpanan default harus diekspor ke kontainer penyimpanan milik pelanggan sebelum penghapusan atau penonaktifan ruang kerja. Untuk informasi selengkapnya tentang ruang kerja tanpa server, lihat Membuat ruang kerja tanpa server.
Untuk tabel dalam penyimpanan default, gunakan DEEP CLONE untuk menulis data ke dalam kontainer penyimpanan milik pelanggan. Untuk volume dan file arbitrer, ikuti pola yang sama seperti yang dijelaskan di bagian ekspor akar DBFS di bawah ini.
Mengekspor direktori akar Sistem File Databricks
Akar Databricks File System adalah lokasi penyimpanan warisan di akun penyimpanan ruang kerja Anda yang mungkin berisi aset milik pelanggan, unggahan pengguna, skrip init, pustaka, dan tabel. Meskipun akar Databricks File System adalah pola penyimpanan yang tidak digunakan lagi, ruang kerja warisan mungkin masih memiliki data yang disimpan di lokasi ini yang perlu diekspor. Untuk informasi selengkapnya tentang arsitektur penyimpanan ruang kerja, lihat Penyimpanan ruang kerja.
Mengekspor Dasar Sistem File Databricks:
Karena wadah akar di Azure bersifat privat, Anda tidak dapat menggunakan alat asli Azure seperti azcopy memindahkan data antar akun penyimpanan. Sebagai gantinya, gunakan dbutils fs cp dan Delta DEEP CLONE dalam Azure Databricks. Ini mungkin memakan waktu lama untuk dijalankan, tergantung pada volume data.
# Copy DBFS files to a local path
dbutils.fs.cp("dbfs:/path/to/remote/folder", "/path/to/local/folder", recurse=True)
Untuk tabel pada penyimpanan root di Databricks File System, gunakan DEEP CLONE:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/external/storage/`
DEEP CLONE delta.`dbfs:/path/to/dbfs/location`
Penting
Mengekspor data dalam volume besar dari penyimpanan cloud dapat dikenakan biaya transfer data dan penyimpanan yang signifikan. Tinjau harga penyedia cloud Anda sebelum memulai ekspor besar.
Tantangan ekspor umum
Rahasia:
Rahasia tidak dapat diekspor secara langsung karena alasan keamanan. Saat menggunakan pengekspor Terraform dengan opsi -export-secrets, pengekspor menghasilkan variabel di vars.tf dengan nama yang sama seperti rahasia. Anda harus memperbarui file ini secara manual dengan nilai rahasia aktual atau menjalankan pengekspor Terraform dengan -export-secrets opsi (hanya untuk rahasia yang dikelola Azure Databricks).
Azure Databricks merekomendasikan penggunaan penyimpanan rahasia yang didukung Azure Key Vault.
Mengekspor aset AI dan ML
Beberapa aset AI dan ML memerlukan alat dan pendekatan yang berbeda untuk ekspor. Model-model Unity Catalog diekspor sebagai bagian dari ekspor Terraform.
Objek MLflow
MLflow tidak tercakup oleh pengekspor Terraform karena kesenjangan dalam API dan kesulitan dengan serialisasi. Untuk mengekspor eksperimen, eksekusi, model, dan artefak MLflow, gunakan alat mlflow-export-import . Alat sumber terbuka ini menyediakan cakupan semi lengkap migrasi MLflow.
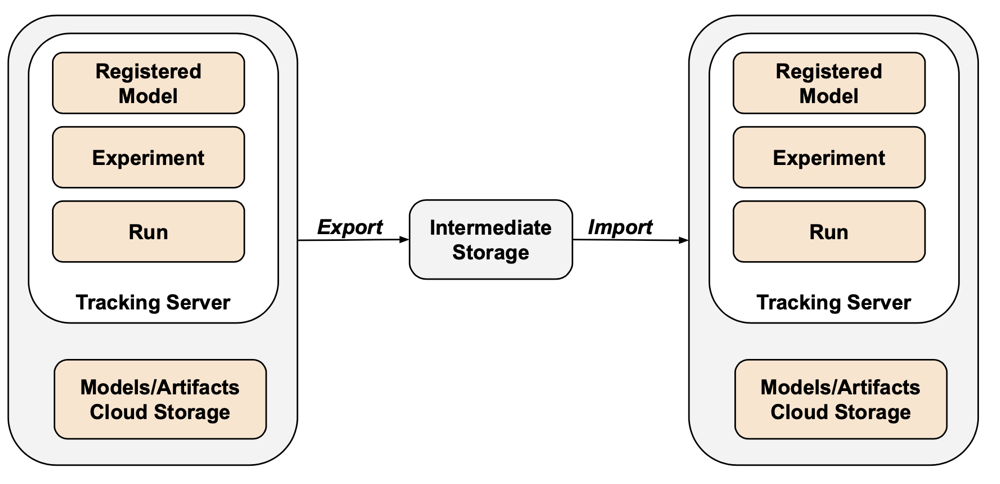
Untuk skenario khusus ekspor, Anda dapat menyimpan semua aset MLflow dalam wadah milik pelanggan tanpa perlu melakukan langkah impor. Untuk informasi selengkapnya tentang manajemen MLflow, lihat Mengelola siklus hidup model di Unity Catalog.
Penyimpanan Fitur dan Pencarian Vektor
Indeks Pencarian Vektor: Indeks Pencarian Vektor tidak berada dalam cakupan prosedur ekspor data Uni Eropa. Jika Anda masih ingin mengekspornya, mereka harus ditulis ke tabel standar lalu diekspor menggunakan DEEP CLONE.
Tabel Penyimpanan Fitur: Penyimpanan Fitur harus diperlakukan mirip dengan indeks Pencarian Vektor. Menggunakan SQL, pilih data yang relevan dan tulis ke tabel standar, lalu ekspor menggunakan DEEP CLONE.
Memvalidasi data yang diekspor
Setelah mengekspor data ruang kerja, validasi bahwa pekerjaan, pengguna, notebook, dan sumber daya lainnya diekspor dengan benar sebelum menonaktifkan lingkungan lama. Gunakan daftar periksa yang Anda buat selama fase cakupan dan perencanaan untuk memverifikasi bahwa semua yang Anda harapkan untuk diekspor berhasil diekspor.
Daftar periksa verifikasi
Gunakan daftar periksa ini untuk memverifikasi ekspor Anda:
- File konfigurasi yang dihasilkan: File konfigurasi Terraform dibuat untuk semua sumber daya ruang kerja yang diperlukan.
- Notebook yang diekspor: Semua notebook diekspor dengan konten dan metadatanya secara utuh.
- Tabel dikloning: Tabel terkelola berhasil dikloning ke lokasi ekspor.
- File data yang disalin: Data penyimpanan cloud disalin sepenuhnya tanpa kesalahan.
- Objek MLflow yang diekspor: Eksperimen, eksekusi, dan model diekspor dengan artefaknya.
- Izin yang didokumenkan: Daftar kontrol akses dan izin dicatat dalam konfigurasi Terraform.
- Dependensi yang diidentifikasi: Hubungan antar aset (misalnya, pekerjaan yang merujuk notebook) dipertahankan dalam ekspor.
Praktik terbaik pasca-ekspor
Pengujian validasi dan penerimaan sebagian besar didorong oleh kebutuhan Anda dan dapat sangat bervariasi. Namun, praktik terbaik umum ini berlaku:
- Tentukan testbed: Buat pengujian pekerjaan atau notebook yang memvalidasi bahwa rahasia, data, pemasangan, konektor, dan dependensi lainnya berfungsi dengan benar di lingkungan yang diekspor.
- Mulailah dengan lingkungan dev: Jika bergerak secara bertahap, mulailah dengan lingkungan dev dan bekerja hingga produksi. Ini memunculkan masalah utama lebih awal dan menghindari dampak produksi.
- Manfaatkan folder Git: Jika memungkinkan, gunakan folder Git karena mereka tinggal di repositori Git eksternal. Ini menghindari ekspor manual dan memastikan kode identik di seluruh lingkungan.
- Dokumentasikan proses ekspor: Rekam alat yang digunakan, perintah yang dijalankan, dan masalah apa pun yang dihadapi.
- Data yang diekspor dengan aman: Pastikan data yang diekspor disimpan dengan aman dengan kontrol akses yang sesuai, terutama jika berisi informasi sensitif atau dapat diidentifikasi secara pribadi.
- Pertahankan kepatuhan: Jika mengekspor untuk tujuan kepatuhan, verifikasi bahwa ekspor memenuhi persyaratan peraturan dan kebijakan penyimpanan.
Contoh skrip dan otomatisasi
Anda dapat mengotomatiskan ekspor ruang kerja menggunakan skrip dan pekerjaan terjadwal.
Skrip Klon Mendalam Ekspor
Skrip berikut mengekspor tabel terkelola Katalog Unity menggunakan DEEP CLONE. Kode ini harus dijalankan di ruang kerja sumber untuk mengekspor katalog tertentu ke wadah perantara. Perbarui variabel catalogs_to_copy dan dest_bucket.
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
Pertimbangan otomatisasi
Saat mengotomatiskan ekspor:
- Gunakan pekerjaan terjadwal: Buat pekerjaan Azure Databricks yang menjalankan skrip ekspor pada jadwal reguler.
- Memantau pekerjaan ekspor: Konfigurasikan pemberitahuan untuk memberi tahu Anda jika ekspor gagal atau memakan waktu lebih lama dari yang diharapkan.
- Mengelola kredensial: Menyimpan kredensial penyimpanan cloud dan token API dengan aman menggunakan rahasia Azure Databricks. Lihat Manajemen Rahasia.
- Ekspor versi: Gunakan tanda waktu atau nomor versi di jalur ekspor untuk mempertahankan ekspor historis.
- Membersihkan ekspor lama: Terapkan kebijakan retensi untuk menghapus ekspor lama dan mengelola biaya penyimpanan.
- Ekspor bertambah bertahap: Untuk ruang kerja besar, pertimbangkan untuk menerapkan ekspor bertambah bertahap yang hanya mengekspor data yang diubah sejak ekspor terakhir.