Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Shiny merupakan paket R, tersedia di CRAN, yang digunakan untuk membangun aplikasi dan dasbor R interaktif. Anda dapat menggunakan Shiny di dalam RStudio Server yang dihosting di kluster Azure Databricks. Anda juga dapat mengembangkan, menghosting, dan berbagi aplikasi Shiny langsung dari notebook Azure Databricks.
Untuk memulai dengan Shiny, lihat tutorial Shiny. Anda dapat menjalankan tutorial ini di buku catatan Azure Databricks.
Artikel ini menjelaskan cara menjalankan aplikasi Shiny di Azure Databricks dan menggunakan Apache Spark di dalam aplikasi Shiny.
Mengkilap di dalam buku catatan R
Paket Shiny disertakan dengan Databricks Runtime. Anda dapat secara interaktif mengembangkan dan menguji aplikasi Shiny di dalam buku catatan Azure Databricks R yang mirip dengan RStudio yang dihosting.
Mulai menggunakan Shiny di dalam buku catatan R
Ikuti langkah-langkah berikut untuk memulai:
Buat buku catatan R.
Impor paket Shiny dan jalankan aplikasi
01_hellocontoh sebagai berikut:library(shiny) runExample("01_hello")Saat aplikasi siap, output menyertakan URL aplikasi Shiny sebagai tautan yang dapat diklik yang membuka tab baru. Untuk berbagi aplikasi ini dengan pengguna lain, lihat Bagikan URL aplikasi Shiny.
Contoh aplikasi Shiny
Catatan
- Pesan log muncul di hasil perintah, mirip dengan pesan log default (
Listening on http://0.0.0.0:5150) yang ditunjukkan dalam contoh. - Untuk menghentikan aplikasi Shiny, klik Batalkan.
- Aplikasi Shiny menggunakan proses buku catatan R. Jika Anda melepaskan notebook dari kluster, atau jika Anda membatalkan sel yang menjalankan aplikasi, aplikasi Shiny akan dihentikan. Anda tidak dapat menjalankan sel lain saat aplikasi Shiny berjalan.
Menjalankan aplikasi Shiny dari folder Databricks Git
Anda dapat menjalankan aplikasi Shiny yang dimasukkan ke dalam Databricks Git folders.
Mengkloning repositori Git jarak jauh.
Jalankan aplikasi lagi.
library(shiny) runApp("006-tabsets")
Menjalankan aplikasi Shiny dari file
Jika kode aplikasi Shiny Anda adalah bagian dari proyek yang dikelola oleh kontrol versi, Anda dapat menjalankannya di dalam buku catatan.
Catatan
Anda harus menggunakan jalur absolut atau mengatur direktori kerja dengan setwd().
Lihat kode dari repositori menggunakan kode yang mirip dengan:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Untuk menjalankan aplikasi, masukkan kode yang mirip dengan yang berikut ini di sel lain:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Bagikan URL aplikasi Shiny
URL aplikasi Shiny yang dihasilkan saat Anda memulai aplikasi dapat dibagikan dengan pengguna lain. Setiap pengguna Azure Databricks dengan izin CAN ATTACH TO pada kluster dapat melihat dan berinteraksi dengan aplikasi selama aplikasi dan kluster berjalan.
Jika kluster yang dijalankan aplikasi berakhir, aplikasi tidak lagi dapat diakses. Anda dapat menonaktifkan penghentian otomatis di pengaturan kluster.
Jika Anda melampirkan dan menjalankan notebook yang menjadi host aplikasi Shiny pada kluster yang berbeda, URL aplikasi Shiny berubah. Selain itu, jika Anda memulai ulang aplikasi pada kluster yang sama, Shiny mungkin memilih port acak yang berbeda. Untuk memastikan URL stabil, Anda dapat mengatur shiny.port opsi, atau, saat memulai ulang aplikasi pada kluster yang sama, Anda dapat menentukan port argumen.
Shiny pada Server RStudio yang dihosting
Penting
RStudio Server yang dihosting Databricks tidak digunakan lagi dan hanya tersedia di Databricks Runtime versi 15.4 ke bawah. Untuk opsi lain, lihat Alternatif untuk server RStudio yang dihosting.
Persyaratan
Penting
Dengan RStudio Server Pro, Anda harus menonaktifkan autentikasi proksi.
Pastikan auth-proxy=1 tidak muncul di dalam /etc/rstudio/rserver.conf.
Get started
Buka RStudio di Azure Databricks.
Di RStudio, impor paket Shiny dan jalankan aplikasi contoh
01_hellosebagai berikut:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Jendela baru akan muncul, menampilkan aplikasi Shiny.
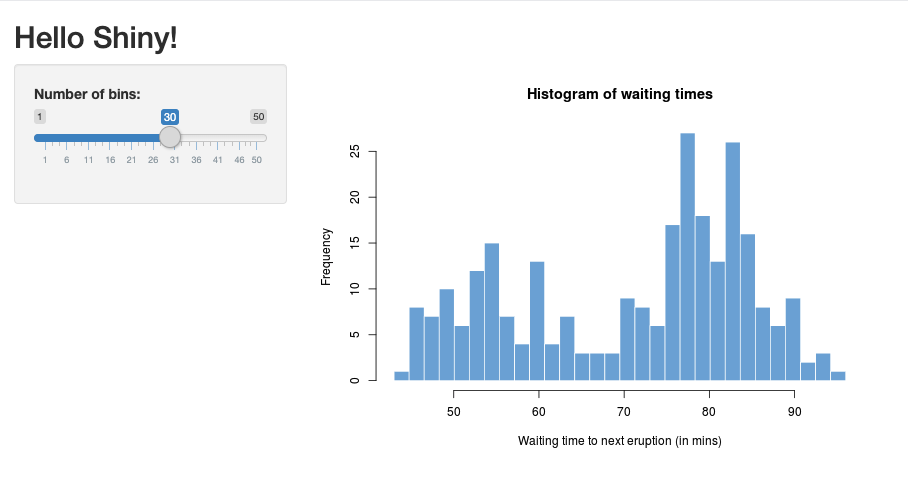
Menjalankan aplikasi Shiny dari skrip R
Untuk menjalankan aplikasi Shiny dari skrip R, buka skrip R di editor RStudio dan klik tombol Jalankan Aplikasi di kanan atas.
Gunakan Apache Spark di dalam aplikasi Shiny
Anda dapat menggunakan Apache Spark di dalam aplikasi Shiny dengan SparkR atau sparklyr.
Gunakan SparkR dengan Shiny di buku catatan
Penting
SparkR di Databricks ditinggalkan mulai dari Databricks Runtime 16.0 ke atas.
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Gunakan sparklyr dengan Shiny di notebook
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
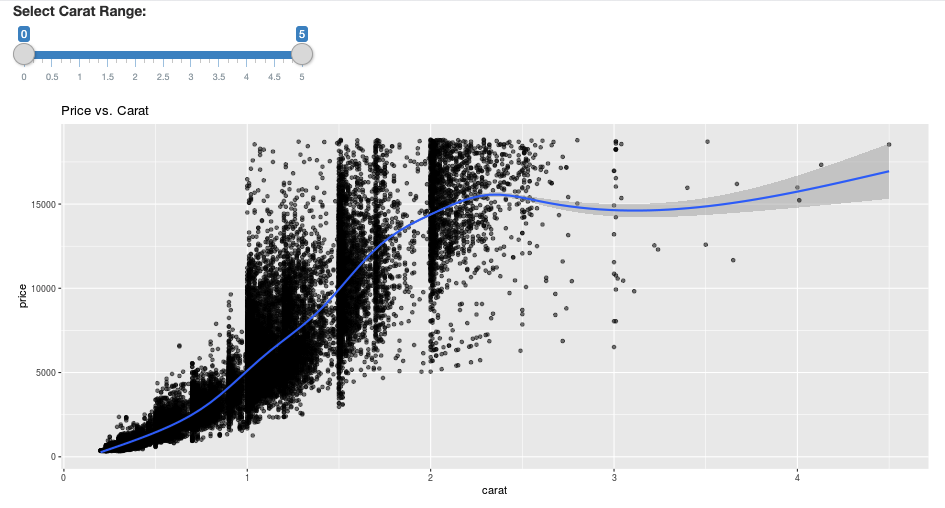
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Pertanyaan Umum (FAQ)
- Mengapa aplikasi Shiny saya berwarna abu-abu setelah beberapa waktu?
- Mengapa jendela penampil Shiny saya menghilang setelah beberapa saat?
- Mengapa pekerjaan Spark yang lama tidak pernah kembali?
- Bagaimana saya bisa menghindari batas waktu?
- Aplikasi saya terhenti setelah diluncurkan, tetapi kodenya tampaknya benar. Apa yang terjadi?
- Berapa banyak koneksi yang dapat diterima untuk satu tautan aplikasi Shiny selama pengembangan?
- Bisakah saya menggunakan versi paket Shiny yang berbeda dari yang diinstal di Databricks Runtime?
- Bagaimana cara mengembangkan aplikasi Shiny yang dapat dipublikasikan ke server Shiny dan dapat mengakses data di Azure Databricks?
- Bisakah saya mengembangkan aplikasi Shiny di dalam notebook Azure Databricks?
- Bagaimana cara menyimpan aplikasi Shiny yang saya kembangkan di Server RStudio yang dihosting?
Mengapa aplikasi Shiny saya berwarna abu-abu setelah beberapa waktu?
Jika tidak ada interaksi dengan aplikasi Shiny, koneksi ke aplikasi akan ditutup setelah sekitar 4 menit.
Untuk menyambungkan kembali, refresh halaman aplikasi Shiny. Status dasbor diatur ulang.
Mengapa jendela penampil Shiny saya menghilang setelah beberapa saat?
Jika jendela penampil Shiny menghilang setelah tidak digunakan selama beberapa menit, itu karena memiliki batas waktu yang sama dengan skenario menghilang dari tampilan.
Mengapa pekerjaan Spark yang berlangsung lama tidak pernah menghasilkan hasil?
Hal ini juga disebabkan oleh batas waktu idle. Setiap pekerjaan Spark yang berjalan lebih lama dari batas waktu yang disebutkan sebelumnya tidak akan dapat menampilkan hasilnya karena koneksi ditutup sebelum pekerjaan kembali.
Bagaimana saya bisa menghindari timeout?
Ada solusi yang disarankan dalam Permintaan Fitur: Minta klien mengirim pesan tetap aktif untuk mencegah batas waktu TCP pada beberapa penyeimbang beban di Github. Solusinya mengirimkan heartbeat untuk menjaga koneksi WebSocket tetap hidup saat aplikasi diam. Namun, solusi ini tidak berfungsi jika aplikasi diblokir oleh komputasi yang sudah berjalan lama.
Shiny tidak mendukung tugas jangka panjang. Postingan blog Shiny merekomendasikan penggunaan promises and futures untuk menjalankan tugas panjang secara asinkron dan untuk menjaga aplikasi tidak diblokir. Berikut adalah contoh yang menggunakan detak jantung otomatis untuk menjaga aplikasi Shiny tetap hidup, dan menjalankan pekerjaan Spark yang cukup lama dalam konstruksi
future.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages('future') install.packages('promises') library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)Ada batas keras 12 jam sejak pemuatan halaman awal setelah itu koneksi apa pun, bahkan jika aktif, akan dihentikan. Anda harus memuat ulang aplikasi Shiny untuk menyambungkan kembali dalam kasus ini. Namun, koneksi WebSocket yang mendasar dapat ditutup kapan saja oleh berbagai faktor termasuk ketidakstabilan jaringan atau mode tidur komputer. Databricks merekomendasikan penulisan ulang aplikasi Shiny sehingga mereka tidak memerlukan koneksi berumur panjang dan tidak terlalu mengandalkan status sesi.
Aplikasi saya terhenti setelah diluncurkan, tetapi kodenya tampaknya benar. Apa yang terjadi?
Ada batas 50 MB pada jumlah total data yang dapat ditampilkan dalam aplikasi Shiny di Azure Databricks. Jika ukuran total data aplikasi melebihi batas ini, aplikasi akan langsung crash setelah diluncurkan. Untuk menghindari hal ini, Databricks merekomendasikan untuk mengurangi ukuran data, misalnya dengan menurunkan data yang ditampilkan atau mengurangi resolusi gambar.
Berapa banyak koneksi yang dapat diterima untuk satu tautan aplikasi Shiny selama pengembangan?
Databricks menyarankan hingga 20.
Bisakah saya menggunakan versi paket Shiny yang berbeda dari yang diinstal di Databricks Runtime?
Ya. Lihat Memperbaiki Versi Paket R.
Bagaimana cara mengembangkan aplikasi Shiny yang dapat dipublikasikan ke server Shiny dan dapat mengakses data di Azure Databricks?
Meskipun Anda dapat mengakses data secara alami menggunakan SparkR atau sparklyr selama pengembangan dan pengujian di Azure Databricks, namun setelah aplikasi Shiny dipublikasikan ke layanan hosting yang berdiri sendiri, aplikasi tersebut tidak dapat langsung mengakses data dan tabel di Azure Databricks.
Untuk mengaktifkan aplikasi Anda agar berfungsi di luar Azure Databricks, Anda harus menulis ulang cara Anda mengakses data. Berikut adalah beberapa opsinya:
- Gunakan JDBC/ODBC untuk mengirimkan kueri ke kluster Azure Databricks.
- Gunakan Databricks Connect.
- Akses langsung data pada penyimpanan objek.
Databricks merekomendasikan agar Anda bekerja dengan tim solusi Azure Databricks Anda untuk menemukan pendekatan terbaik untuk arsitektur data dan analitik yang ada.
Bisakah saya mengembangkan aplikasi Shiny di dalam notebook Azure Databricks?
Ya, Anda dapat mengembangkan aplikasi Shiny di dalam notebook Azure Databricks.
Bagaimana cara menyimpan aplikasi Shiny yang saya kembangkan di Server RStudio yang dihosting?
Anda dapat menyimpan kode aplikasi di DBFS atau memeriksa kode Anda ke dalam kontrol versi.