Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Fitur ini ada di Beta. Admin ruang kerja dapat mengontrol akses ke fitur ini dari halaman Pratinjau . Lihat Kelola pratinjau Azure Databricks.
Mosaic AI Vector Search menyediakan evaluasi kualitas pengambilan bawaan yang mengukur dan membandingkan relevansi strategi pencarian yang berbeda pada data Anda. Anda dapat secara otomatis menghasilkan kueri evaluasi dari dokumen Anda, menjalankan beberapa strategi pengambilan, dan membuat laporan terperinci.
Persyaratan
Indeks pencarian vektor Sinkronisasi Delta terkelola. Lihat Membuat titik akhir pencarian vektor dan indeks.
Permissions
Pekerjaan evaluasi dan dasbor hasil mewarisi izin Katalog Unity dari indeks pencarian vektor. Setiap pengguna dengan akses kueri ke indeks dapat memulai eksekusi evaluasi dan menampilkan dasbor hasil. Pengguna yang memulai eksekusi evaluasi adalah pemilik pekerjaan, bukan pemilik indeks.
Cara kerja evaluasi kualitas pencarian vektor
Evaluasi menjalankan alur empat tahap pada data Anda:
- Hasilkan kueri: Sistem mengambil sampel dokumen dari tabel sumber Anda dan menggunakan LLM untuk menghasilkan kueri pencarian yang realistis. Ini menghasilkan campuran kueri bahasa alami dan kueri kata kunci.
- Pencarian pada berbagai strategi: Setiap kueri yang dihasilkan dijalankan terhadap indeks Anda menggunakan beberapa strategi pencarian, termasuk ANN, hibrid, dan teks lengkap. Setiap strategi juga dievaluasi dengan dan tanpa reranker. Pendekatan ini membandingkan strategi secara berdampingan pada kumpulan kueri yang sama. Untuk informasi selengkapnya tentang setiap strategi pengambilan, lihat Algoritma pengambilan.
- Relevansi skor: Hakim LLM mengevaluasi setiap kueri dan pasangan dokumen yang diambil pada skala relevansi 4 titik.
- Komputasi metrik dan analisis: Sistem menghitung metrik kualitas pengambilan dengan interval keyakinan. Hasil dipertahankan sehingga Anda dapat melihatnya nanti atau membandingkannya di seluruh eksekusi evaluasi.
Memulai pelaksanaan evaluasi kualitas pengambilan data
Untuk memulai proses, klik Evaluasi kualitas pencarian di halaman indeks pencarian vektor. Tidak diperlukan konfigurasi, karena nilai default telah diisi sebelumnya berdasarkan metadata indeks Anda.
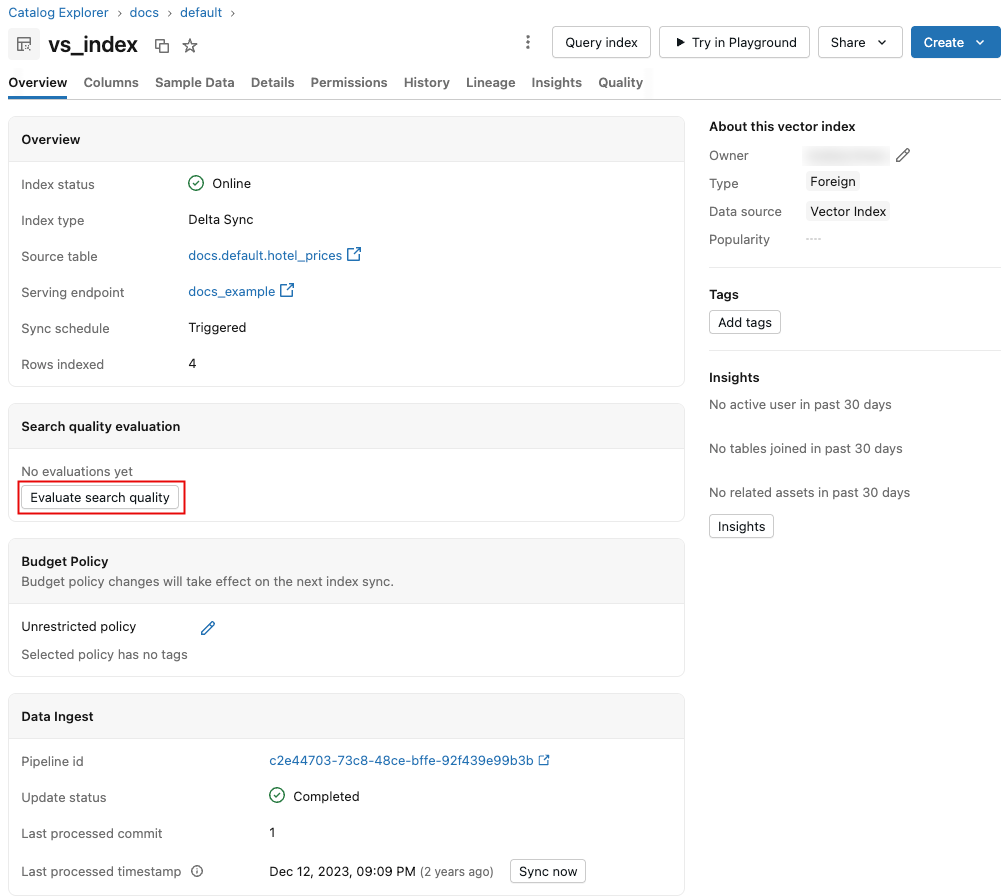
Saat eksekusi selesai, klik Tampilkan hasil untuk menampilkan dasbor hasil. Untuk gambaran umum dasbor, lihat Dasbor hasil.
Untuk memulai evaluasi baru kapan saja, klik Mulai evaluasi baru.
Dasbor hasil
Dasbor menyajikan hasil evaluasi yang dijalankan. Gunakan menu drop-down Pilih Jalankan untuk memilih eksekusi yang akan ditampilkan.
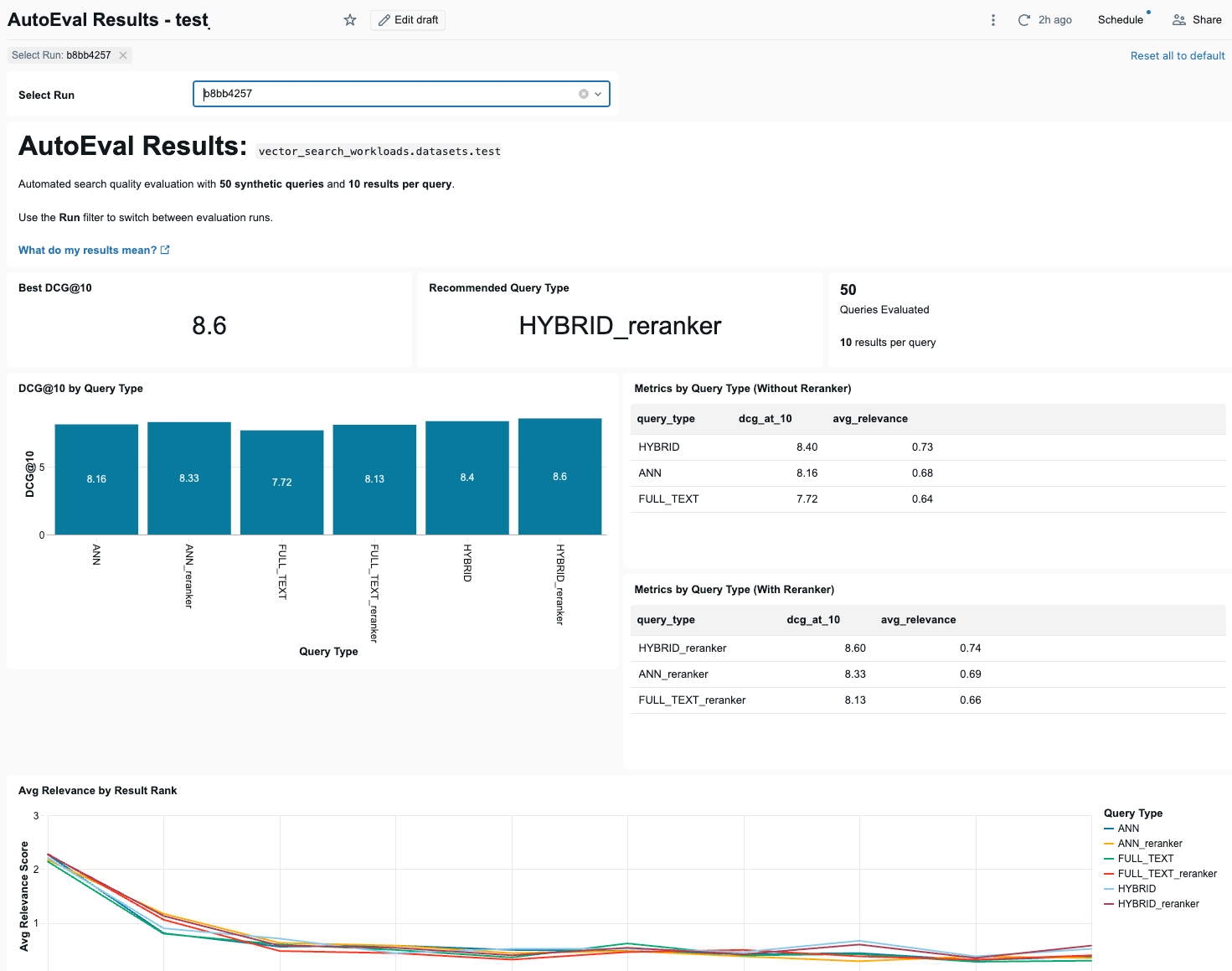
Di bagian atas dasbor ada 3 indikator ringkasan: skor DCG@10 terbaik di semua jenis kueri, jenis kueri yang direkomendasikan yang mencapainya, dan jumlah kueri yang dievaluasi.
Lihat Mengapa Databricks merekomendasikan DCG@10.
Di bawah indikator ringkasan, dasbor memperlihatkan bagan batang yang membandingkan skor DCG@10 untuk setiap jenis kueri, dengan dan tanpa menggunakan reranker. Di samping bagan batang ada dua tabel yang memperlihatkan DCG@10 dan relevansi rata-rata untuk setiap jenis kueri, dengan dan tanpa reranker.
Berikut ini adalah bagan garis yang memperlihatkan bagaimana relevansi rata-rata berubah di seluruh posisi hasil untuk setiap jenis kueri.
Dasbor juga menyajikan kueri berkinerja tertinggi dan terendah berdasarkan skor relevansi rata-rata, tabel yang membandingkan performa dasar dan reranker untuk setiap jenis kueri, tabel kueri yang gagal (kueri di mana hasil 1 teratas diberi skor 0 (tidak relevan)), dan bagan garis yang menunjukkan metrik yang dipilih di seluruh evaluasi berjalan dari waktu ke waktu, dengan metrik kueri.
Penilaian relevansi
Evaluasi kualitas pengambilan menggunakan LLM sebagai penilai untuk menilai setiap pasangan kueri dan dokumen yang diambil pada skala relevansi dengan penilaian 4 poin.
| Skor | Label | Deskripsi | Example |
|---|---|---|---|
| 3 | Sangat Relevan | Dokumen langsung menjawab kueri atau menyediakan informasi yang dicari dengan tepat | Kueri: "bagaimana cara menghitung area persegi panjang?" Dokumen menjelaskan rumus panjang × lebar |
| 2 | Relevan | Dokumen terkait dan menyediakan informasi yang berguna, tetapi mungkin tidak sepenuhnya menjawab kueri | Kueri: "di mana nomor routing pada cek?" Dokumen berbunyi "dicetak di bagian bawah cek" (belum lengkap) |
| 1 | Sebagian Relevan | Dokumen menyebutkan topik tetapi tidak menyediakan informasi yang berguna untuk kueri | Kueri: "bagaimana cara menghitung area persegi panjang?" Dokumen membahas luas persegi panjang hanya dalam istilah umum |
| 0 | Tidak Relevan | Dokumen tidak terkait dengan kueri, atau bahasa dokumen tidak cocok dengan bahasa kueri | Kueri dalam bahasa Inggris Jawaban didokumentasikan dengan benar tetapi dalam bahasa Prancis |
Dibandingkan dengan skala biner yang relevan/tidak relevan, skala bertingkat menangkap perbedaan penting. Misalnya, dokumen yang langsung menjawab pertanyaan (skor 3) sangat berbeda dari yang hanya menyentuh topik (skor 1). Granularitas ini melekat pada metrik, terutama DCG, yang memberikan bobot lebih besar pada hasil berkualitas tinggi.
Semua metrik mencakup 95% interval keyakinan yang dihitung di seluruh nilai per kueri, sehingga Anda dapat menilai apakah perbedaan antara strategi bermakna secara statistik.
Metode evaluasi pengambilan data
Di bagian bawah dasbor, Anda dapat melihat metrik yang dipilih dari waktu ke waktu. Pilih metrik yang akan ditampilkan dari menu drop-down Pilih Metrik .
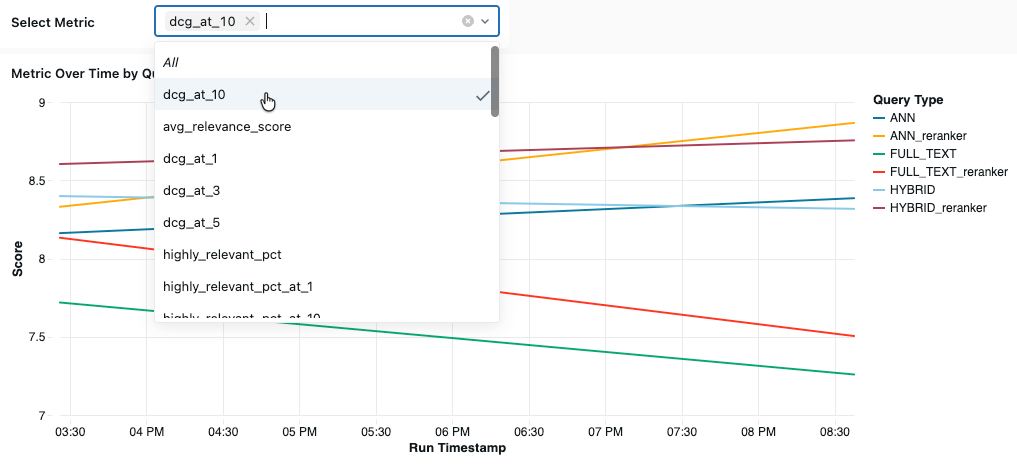
Bagian ini menjelaskan metrik yang tersedia.
DCG@k — Peningkatan Kumulatif dengan Diskon
DCG@10 menangkap seberapa relevan hasilnya dan di mana hasil tersebut muncul dalam peringkat, menggunakan skala relevansi 0–3 penuh. Databricks merekomendasikan penggunaan DCG@10 sebagai metrik utama untuk mengevaluasi kualitas pengambilan keseluruhan.
- Apa yang diukurnya: Total utilitas dari 10 hasil teratas, ditimbang berdasarkan posisi. Hasil berperingkat lebih tinggi berkontribusi lebih dari yang berperingkat lebih rendah.
- Cara kerjanya: Setiap skor relevansi hasil ditimbang oleh diskon logaritma berdasarkan posisinya. Hasil pertama berkontribusi relevansi penuh, sementara hasil berperingkat lebih rendah berkontribusi secara progresif lebih sedikit.
- Rentang: 0 hingga maksimum teoritis yang diperlihatkan dalam tabel berikut. Lebih tinggi lebih baik.
Nilai DCG maksimum teoritis, jika nilai setiap hasil adalah 3:
| k | DCG Maksimum Teoritis |
|---|---|
| 1 | 3,00 |
| 3 | 6.39 |
| 5 | 8.85 |
| 10 | 13.63 |
| 20 | 21.12 |
Untuk menempatkan angka-angka ini dalam perspektif: jika semua 10 hasil memiliki relevansi 2 (pada skala 0–3), DCG@10 adalah 13,6. Dalam skenario ini, perolehan DCG@10 1 poin adalah peningkatan yang sangat signifikan (+7% relatif). Anda dapat menganggapnya sebagai kira-kira satu hasil pada halaman yang menjadi lebih baik secara signifikan, dengan kecenderungan untuk muncul di bagian atas.
NDCG@k — Keuntungan Kumulatif Diskon yang Dinormalisasi
- Apa yang diukurnya: Seberapa baik hasil diurutkan relatif terhadap urutan terbaik. NDCG menormalkan DCG dengan membaginya dengan DCG yang ideal (yaitu DCG jika hasil diurutkan dalam urutan menurun berdasarkan relevansi).
- Rentang: 0 hingga 1. Skor 1,0 berarti hasil dalam urutan sempurna.
- Kapan harus digunakan: Ketika Anda ingin tahu apakah sistem memberi peringkat hasil dengan benar, terlepas dari jumlah total dokumen yang relevan yang tersedia. Lihat Mengapa DCG@10 adalah metrik utama yang direkomendasikan untuk perbandingan terperinci.
Recall@k
- Apa yang diukur: Persentase dokumen relevan yang diketahui yang muncul di hasil teratas k.
- Rentang: 0 hingga 1. Skor 1.0 berarti semua dokumen relevan yang diketahui berhasil ditemukan.
- Kapan harus digunakan: Ketika kelengkapan penting, seperti dalam aplikasi RAG di mana kehilangan dokumen yang relevan berarti LLM menghasilkan jawaban yang tidak lengkap.
Precision@k
- Apa yang diukurnya: Pecahan dari hasil top-k yang relevan (skor relevansi = 2).
- Rentang: 0 hingga 1. Skor 1,0 berarti setiap hasil dalam k teratas relevan.
- Kapan digunakan: Ketika kualitas hasil lebih penting daripada kelengkapan, seperti di antarmuka pencarian di mana hasil yang tidak relevan mungkin berdampak negatif pada kepercayaan pengguna.
Nilai relevansi rata-rata
- Apa yang diukurnya: Skor relevansi rata-rata yang dinilai oleh LLM pada semua pasangan kueri dan hasil.
- Rentang: 0 hingga 3. Lebih tinggi lebih baik.
- Kapan harus digunakan: Sebagai rekam jepret berkualitas cepat.
Distribusi relevansi
-
Apa yang diukurnya: Persentase hasil dalam setiap kategori relevansi:
- Sangat Relevan %: Hasil penilaian 3 (jawaban langsung).
- Relevan+ %: Hasil penilaian 2 atau lebih tinggi (berguna).
- Tidak Relevan %: Penilaian hasil 0 atau 1 (tidak berguna).
- Kapan harus digunakan: Untuk memahami bentuk distribusi kualitas. Dua strategi dapat memiliki skor rata-rata yang sama tetapi distribusi yang sangat berbeda. Misalnya, distribusi bimodal (banyak 3 dan banyak 0) mungkin menunjukkan bahwa pola kueri tidak dijangkau dengan baik dan perlu dipertimbangkan.
MRR — Rata-rata Peringkat Timbal Balik
- Apa yang diukurnya: Seberapa cepat pengguna menemukan hasil pertama yang relevan. MRR adalah rata-rata 1/peringkat di seluruh kueri, di mana peringkat adalah posisi hasil pertama yang relevan (skor >= 2).
- Rentang: 0 hingga 1. Skor 1,0 berarti hasil pertama selalu relevan.
- Kapan harus digunakan: Ketika hasil teratas paling penting, seperti dalam sistem jawaban atas pertanyaan.
MAP@k — Presisi Rata-Rata
- Apa yang diukurnya: Kualitas peringkat di semua hasil yang relevan, bukan hanya yang pertama. MAP menghitung presisi pada setiap posisi hasil yang relevan, dan kemudian menghitung rata-ratanya.
- Rentang: 0 hingga 1. Nilai yang lebih tinggi menunjukkan dokumen yang relevan secara konsisten diberi peringkat di dekat bagian atas.
- Kapan harus digunakan: Saat Anda memerlukan satu angka yang menangkap kualitas peringkat keseluruhan di semua dokumen yang relevan.
Mengapa DCG@10 adalah metrik utama yang direkomendasikan
DCG@10 memberikan gambaran paling lengkap tentang kualitas pengambilan untuk sebagian besar aplikasi:
- Relevansi yang dinilai menangkap nuansa: Metrik biner seperti akurasi memperlakukan semua dokumen yang relevan secara setara. Dokumen yang menjawab kueri dengan sempurna (skor 3) dihitung sama dengan dokumen yang samar-samar menyebutkan topik (skor 1). DCG menggunakan skala relevansi 0–3 penuh, sehingga hasil yang dinilai 3 berkontribusi secara signifikan lebih dari hasil yang dinilai 1.
- Masalah posisi: Pengguna melihat hasil teratas terlebih dahulu. DCG menerapkan diskon logaritma, sehingga hasil pada posisi 1 jauh lebih banyak daripada hasil pada posisi 10. Hasil pertama berkontribusi skor relevansi penuhnya, sedangkan kontribusi hasil ke-10 dibagi dengan log₂(11) ≈ 3,46.
- Utilitas absolut mengungkapkan kesalahan metrik yang dinormalisasi: Pertimbangkan contoh yang ditunjukkan dalam tabel berikut. Kedua set hasil mencapai NDCG sempurna sebesar 1,00 karena masing-masing memiliki hasil dalam urutan turun yang ideal. Namun, Result Set B memberikan hampir dua kali nilai total (DCG 8,02 vs 4,26) karena setiap hasil berguna. NDCG tidak dapat membedakan antara "peringkat sempurna dari 2 hasil yang baik di antara 3 hasil yang tidak relevan" dan "peringkat sempurna dari 5 hasil yang baik." DCG menjawab pertanyaan: "Berapa banyak informasi berguna yang benar-benar didapat pengguna?"
Untuk informasi selengkapnya tentang DCG dan NDCG, lihat Keuntungan kumulatif dengan diskon.
| Hasil | Posisi 1 | Posisi 2 | Posisi 3 | Posisi 4 | Posisi 5 | NDCG@5 | DCG@5 |
|---|---|---|---|---|---|---|---|
| Set hasil A | 3 | 2 | 0 | 0 | 0 | 1,00 | 4.26 |
| Tataan hasil B | 3 | 3 | 3 | 2 | 2 | 1,00 | 8.02 |
Tidak ada metrik tunggal yang menceritakan seluruh cerita. Gunakan rangkaian metrik lengkap untuk gambar lengkap dan pilih metrik yang paling sesuai dengan persyaratan kualitas aplikasi Anda.
Skenario umum
Tabel berikut menjelaskan pola hasil evaluasi umum, apa artinya, dan cara mengatasinya:
| Pola | Apa artinya | Tindakan yang disarankan |
|---|---|---|
| Hibrid secara signifikan lebih baik daripada ANN | Kueri mendapat manfaat dari pencocokan kata kunci. | Gunakan pencarian hibrid dalam produksi. |
| ANN kira-kira sama dengan hibrid | Kata kunci tidak menambahkan nilai untuk data Anda. | Salah satu strategi bekerja. ANN lebih sederhana. |
| Teks lengkap secara signifikan lebih baik daripada ANN | Embedding mungkin tidak menangkap bidang Anda dengan baik. | Pertimbangkan untuk menyempurnakan model penyematan Anda atau menggunakan pencarian teks lengkap. |
| Reranker meningkatkan metrik secara signifikan | Penyandi silang menyediakan lift kualitas yang bermakna. | Aktifkan reranker jika anggaran latensi memungkinkan. |
| Interval keyakinan yang lebar | Tidak cukup kueri untuk perbandingan yang dapat diandalkan. | Tingkatkan jumlah kueri evaluasi. |
| Semua strategi mendapatkan skor rendah | Masalah kualitas atau relevansi data. | Lihat Panduan kualitas pengambilan pencarian vektor untuk panduan langkah demi langkah untuk meningkatkan kualitas pengambilan. |