Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan visualisasi Azure Databricks yang lama. Lihat Visualisasi di buku catatan Databricks dan editor SQL untuk dukungan visualisasi saat ini saat membuat visualisasi di editor SQL atau buku catatan. Untuk informasi tentang bekerja dengan visualisasi di dasbor AI/BI, lihat Jenis visualisasi dasbor AI/BI.
Azure Databricks juga secara bawaan mendukung pustaka visualisasi dalam Python dan R dan memungkinkan Anda menginstal dan menggunakan pustaka pihak ketiga.
Membuat visualisasi warisan
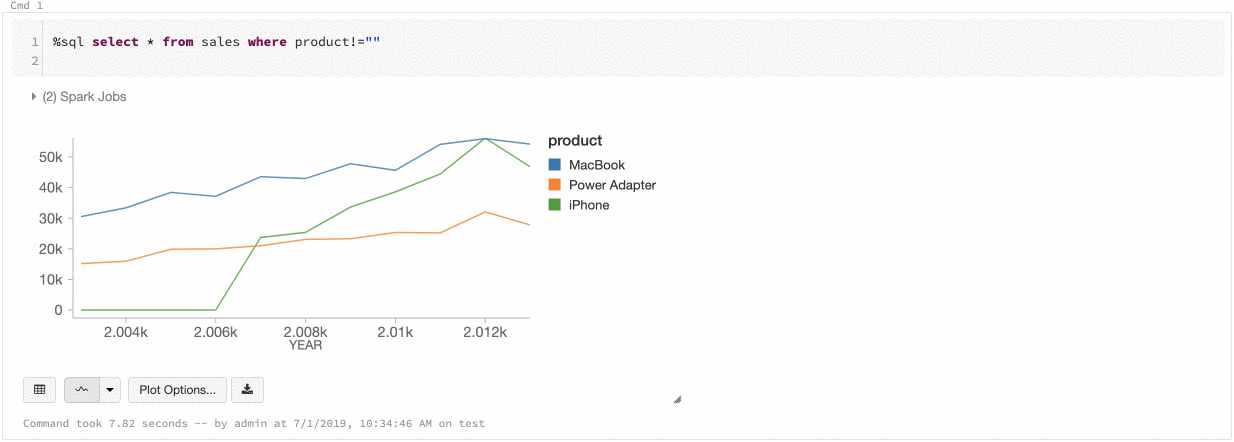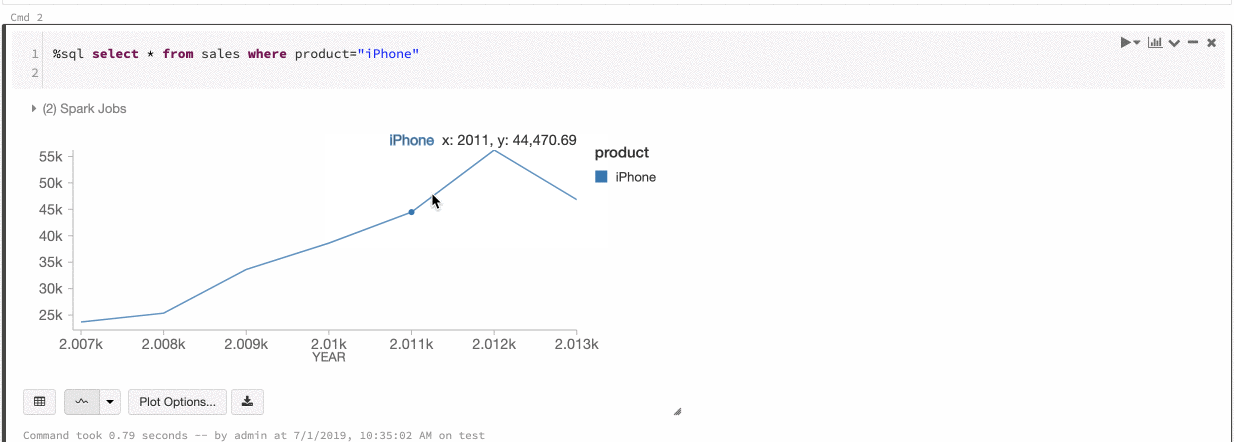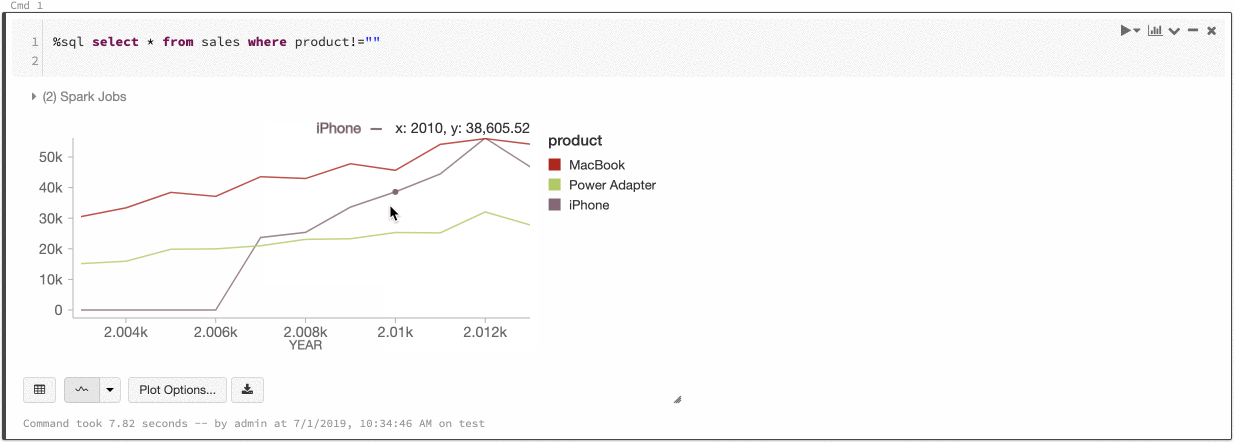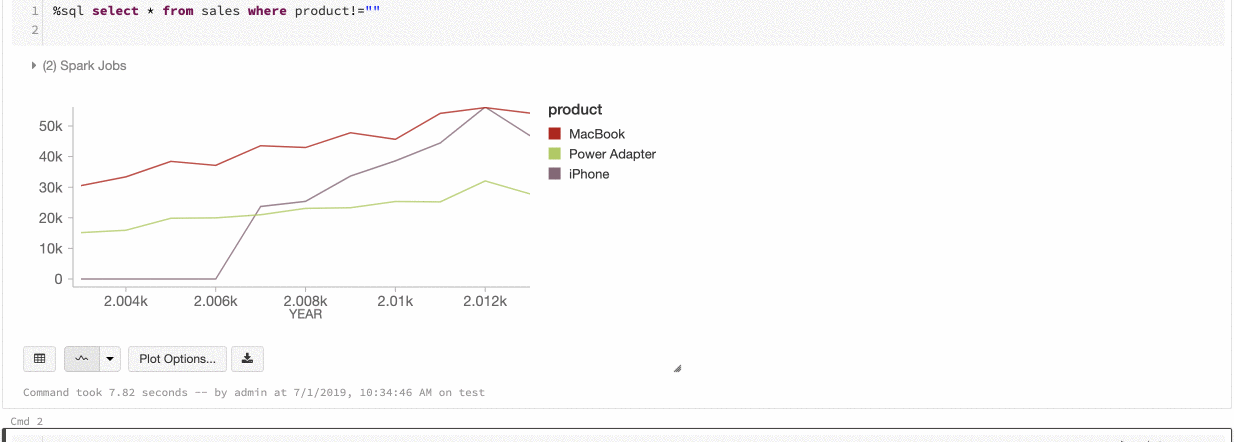
Untuk membuat visualisasi warisan dari sel hasil, klik + dan pilih Visualisasi Warisan.
Visualisasi lama mendukung beragam jenis plot:
Jenis bagan
Memilih dan mengonfigurasi jenis bagan warisan
Untuk memilih bagan batang, klik ikon  bagan batang :
bagan batang :
Untuk memilih jenis plot lain, klik ![]() di sebelah kanan bagan batang dan pilih jenis plot.
di sebelah kanan bagan batang dan pilih jenis plot.
Bilah Alat Bagan Lama
Bagan garis dan batang memiliki toolbar bawaan yang mendukung serangkaian interaksi pengguna yang kaya.
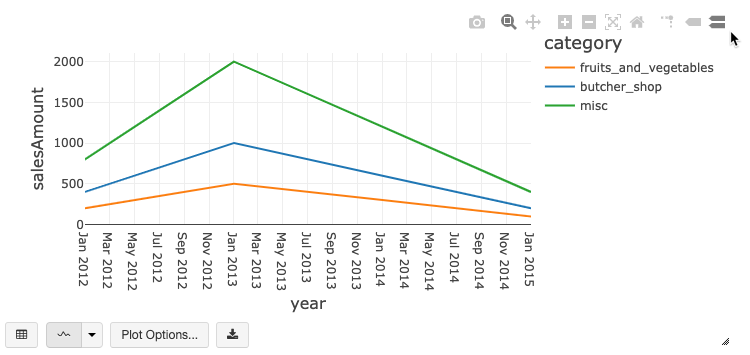
Untuk mengonfigurasi bagan, klik Opsi Plot....
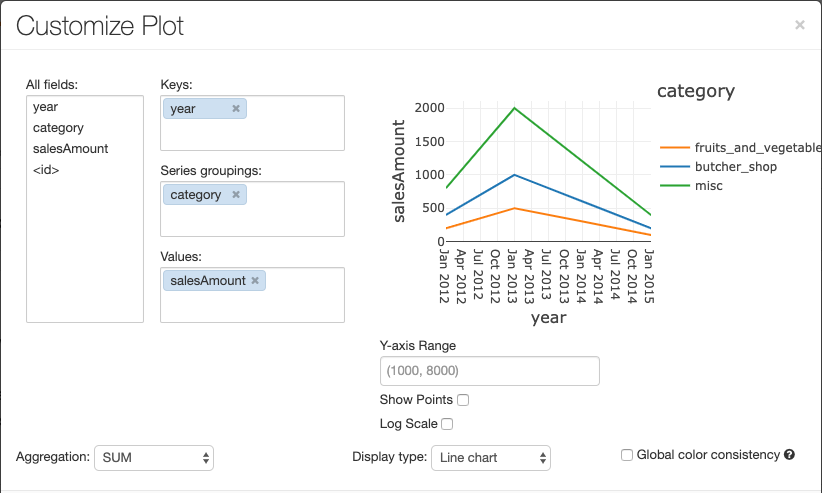
Diagram garis memiliki beberapa opsi bagan kustom: pengaturan rentang sumbu Y, penampilan dan penyembunyian titik, dan penampilan sumbu Y dengan skala log.
Untuk informasi tentang jenis bagan warisan, lihat:
Konsistensi warna di seluruh bagan
Azure Databricks mendukung dua jenis konsistensi warna di seluruh bagan warisan: set seri dan global.
Series set konsistensi warna menetapkan warna yang sama ke nilai yang sama jika Anda memiliki seri dengan nilai yang sama tetapi dalam urutan yang berbeda (misalnya, A = ["Apple", "Orange", "Banana"] dan B = ["Orange", "Banana", "Apple"]). Nilai diurutkan sebelum diplot, sehingga kedua legenda diurutkan dengan cara yang sama (["Apple", "Banana", "Orange"]), dan nilai yang sama diberi warna yang sama. Namun, jika Anda memiliki seri C = ["Orange", "Banana"], warnanya tidak akan konsisten dengan set A karena set tidak sama. Algoritma pengurutan akan menetapkan warna pertama ke "Pisang" di set C tetapi warna kedua ke "Pisang" di set A. Jika Anda ingin seri ini konsisten dengan warna, Anda dapat menentukan bahwa bagan harus memiliki konsistensi warna global.
Dalam konsistensi warna global, setiap nilai selalu dipetakan ke warna yang sama tidak peduli nilai apa yang dimiliki seri. Untuk mengaktifkan ini untuk setiap bagan, pilih kotak centang konsistensi warna global .
Catatan
Untuk mencapai konsistensi ini, Azure Databricks melakukan hashing secara langsung dari nilai menjadi warna. Untuk menghindari tabrakan (di mana dua nilai pergi ke warna yang sama persis), hash mengarah ke sekumpulan besar warna, yang memiliki efek samping di mana warna-warna yang enak dilihat atau mudah dibedakan tidak dapat dijamin; dengan banyak warna, akan ada beberapa yang terlihat sangat mirip.
Visualisasi pembelajaran mesin
Selain jenis bagan standar, visualisasi warisan mendukung parameter dan hasil pelatihan pembelajaran mesin berikut:
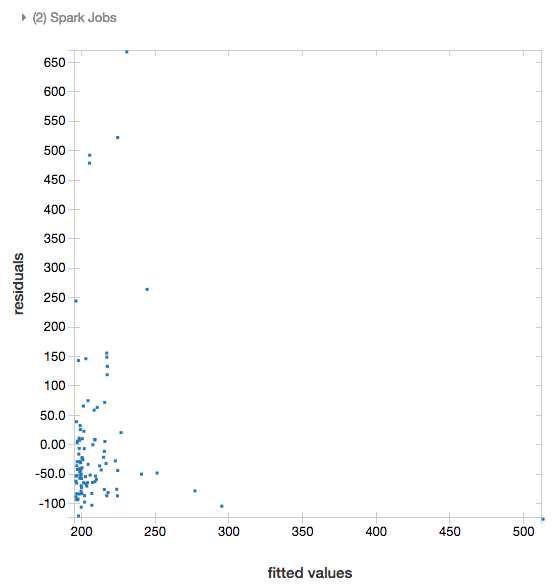
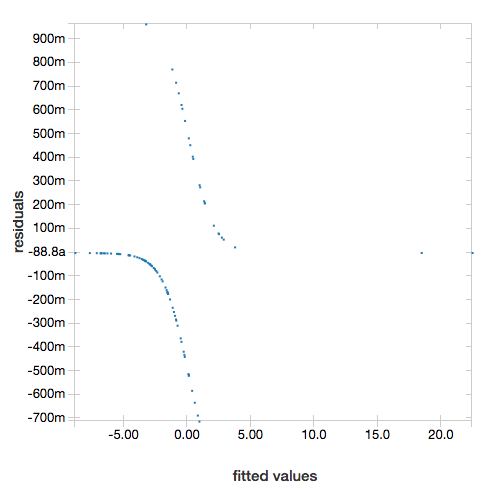
Residu
Untuk regresi linier dan logistik, Anda dapat menghasilkan plot model terpasang versus residu. Untuk mendapatkan plot ini, berikan model dan DataFrame.
Contoh berikut menjalankan regresi linier pada populasi kota terhadap data harga jual rumah dan kemudian menampilkan residu terhadap data yang dipasang.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
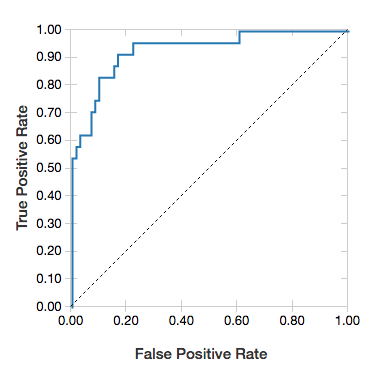
Kurva ROC
Untuk regresi logistik, Anda dapat merender kurva ROC . Untuk mendapatkan plot ini, berikan model, data yang disiapkan yang dimasukkan ke fit metode , dan parameter "ROC".
Contoh berikut mengembangkan pengklasifikasi yang memprediksi apakah individu menghasilkan <= 50K atau >50k setahun dari berbagai atribut individu tersebut. Himpunan data Dewasa berasal dari data sensus, dan berisi informasi tentang 48842 individu dan pendapatan tahunan mereka.
Kode contoh dalam bagian ini menggunakan one-hot encoding.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
Untuk menampilkan residu, hilangkan parameter "ROC":
display(lrModel, preppedDataDF)
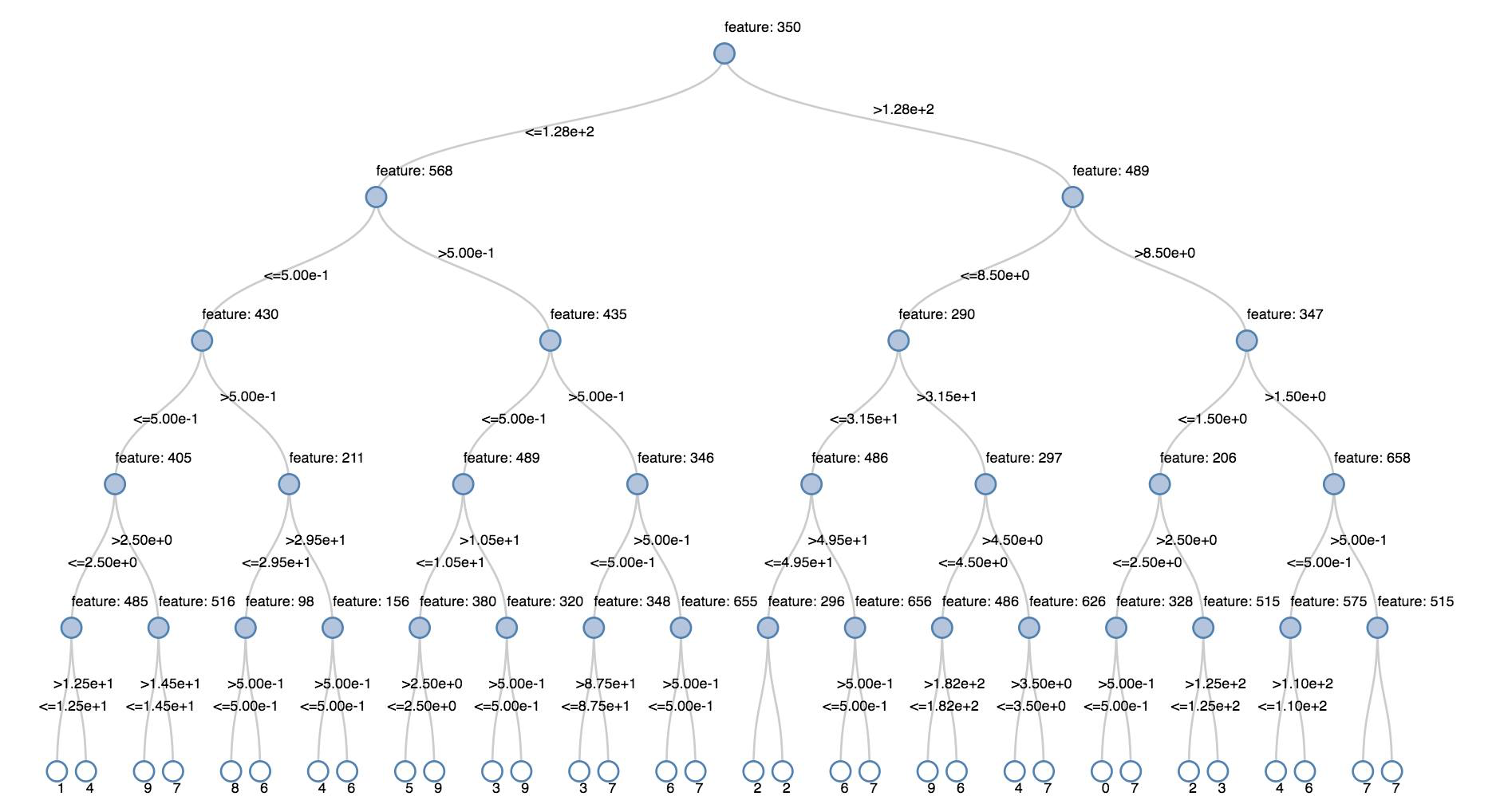
Pohon keputusan
Visualisasi warisan mendukung penyajian pohon keputusan.
Untuk mendapatkan visualisasi ini, berikan model pohon keputusan.
Contoh berikut melatih pohon untuk mengenali digit (0 - 9) dari himpunan data MNIST dari citra digit tulisan tangan dan kemudian menampilkan pohon.
Phyton
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
DataFrames Streaming Terstruktur
Untuk memvisualisasikan hasil kueri streaming secara waktu nyata, Anda dapat display DataFrame Streaming Terstruktur dalam Scala dan Python.
Phyton
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display mendukung parameter opsional berikut:
-
streamName: nama kueri streaming. -
trigger(Scala) danprocessingTime(Python): menentukan seberapa sering kueri streaming dijalankan. Jika tidak ditentukan, sistem memeriksa ketersediaan data baru segera setelah pemrosesan sebelumnya selesai. Untuk mengurangi biaya produksi, Databricks menyarankan agar Anda selalu menetapkan interval pemicu. Interval pemicu default adalah 500 ms. -
checkpointLocation: lokasi tempat sistem menulis semua informasi titik pemeriksaan. Jika tidak ditentukan, sistem secara otomatis menghasilkan lokasi titik pemeriksaan sementara pada DBFS. Agar aliran Anda dapat terus memproses data dari tempat aliran tersebut ditinggalkan, Anda harus menyediakan lokasi titik pemeriksaan. Databricks menyarankan agar dalam produksi Anda selalu menentukan opsicheckpointLocation.
Phyton
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Untuk informasi selengkapnya tentang parameter ini, lihat Memulai Kueri Streaming.
displayHTML fungsi
Notebook bahasa pemrograman Azure Databricks (Python, R, dan Scala) mendukung grafik HTML menggunakan fungsi displayHTML; Anda dapat meneruskan fungsi kode HTML, CSS, atau JavaScript apa pun. Fungsi ini mendukung grafik interaktif menggunakan pustaka JavaScript seperti D3.
Untuk contoh penggunaan displayHTML, lihat:
Catatan
iframe displayHTML disajikan dari domain databricksusercontent.com, dan kotak pasir iframe mencakup atribut allow-same-origin.
databricksusercontent.com harus dapat diakses dari browser Anda. Jika saat ini diblokir oleh jaringan perusahaan Anda, harus ditambahkan ke dalam daftar pengecualian.
Gambar
Kolom yang berisi jenis data gambar dirender sebagai HTML yang lengkap. Azure Databricks mencoba merender gambar mini untuk kolom DataFrame yang cocok dengan Spark ImageSchema.
Perenderan gambar mini berfungsi untuk gambar apapun yang berhasil dibaca dalam fungsi spark.read.format('image'). Untuk nilai gambar yang dihasilkan melalui cara lain, Azure Databricks mendukung penyajian 1, 3, atau 4 gambar saluran (di mana setiap saluran terdiri dari satu byte), dengan batasan berikut:
-
Citra satu saluran: bidang
modeharus sama dengan 0. Bidangheight,width, dannChannelsharus secara akurat menggambarkan data citra biner dalam bidangdata. -
Citra tiga saluran: bidang
modeharus sama dengan 16. Bidangheight,width, dannChannelsharus secara akurat menggambarkan data citra biner dalam bidangdata. Bidangdataharus berisi data piksel dalam kelompok tiga byte, dengan urutan saluran(blue, green, red)untuk setiap piksel. -
Citra empat saluran: bidang
modeharus sama dengan 24. Bidangheight,width, dannChannelsharus secara akurat menggambarkan data citra biner dalam bidangdata. Bidangdataharus berisi data piksel dalam gugus empat byte, dengan urutan saluran(blue, green, red, alpha)untuk setiap piksel.
Contoh
Misalkan Anda memiliki folder yang berisi beberapa citra:

Jika Anda membaca gambar ke dalam DataFrame dan kemudian menampilkan DataFrame, Azure Databricks merender gambar mini dari gambar tersebut.
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Visualisasi dalam Python
Di bagian ini:
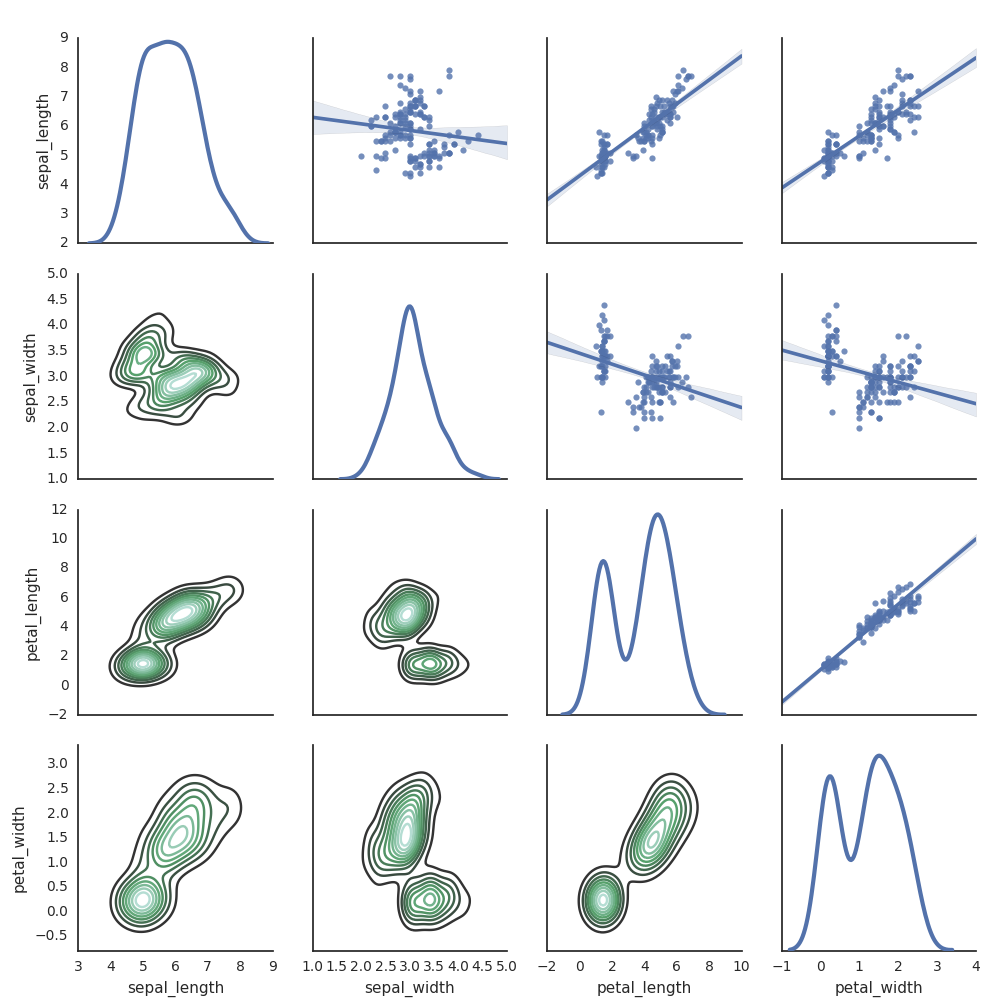
Seaborn
Anda juga dapat menggunakan pustaka Python lainnya untuk menghasilkan plot. Databricks Runtime mencakup pustaka visualisasi seaborn. Untuk membuat plot seaborn, impor pustaka, buat plot, dan teruskan plot ke fungsi display.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Pustaka Python lainnya
Visualisasi dalam R
Untuk mengeplot data dalam R, gunakan fungsi display sebagai berikut:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
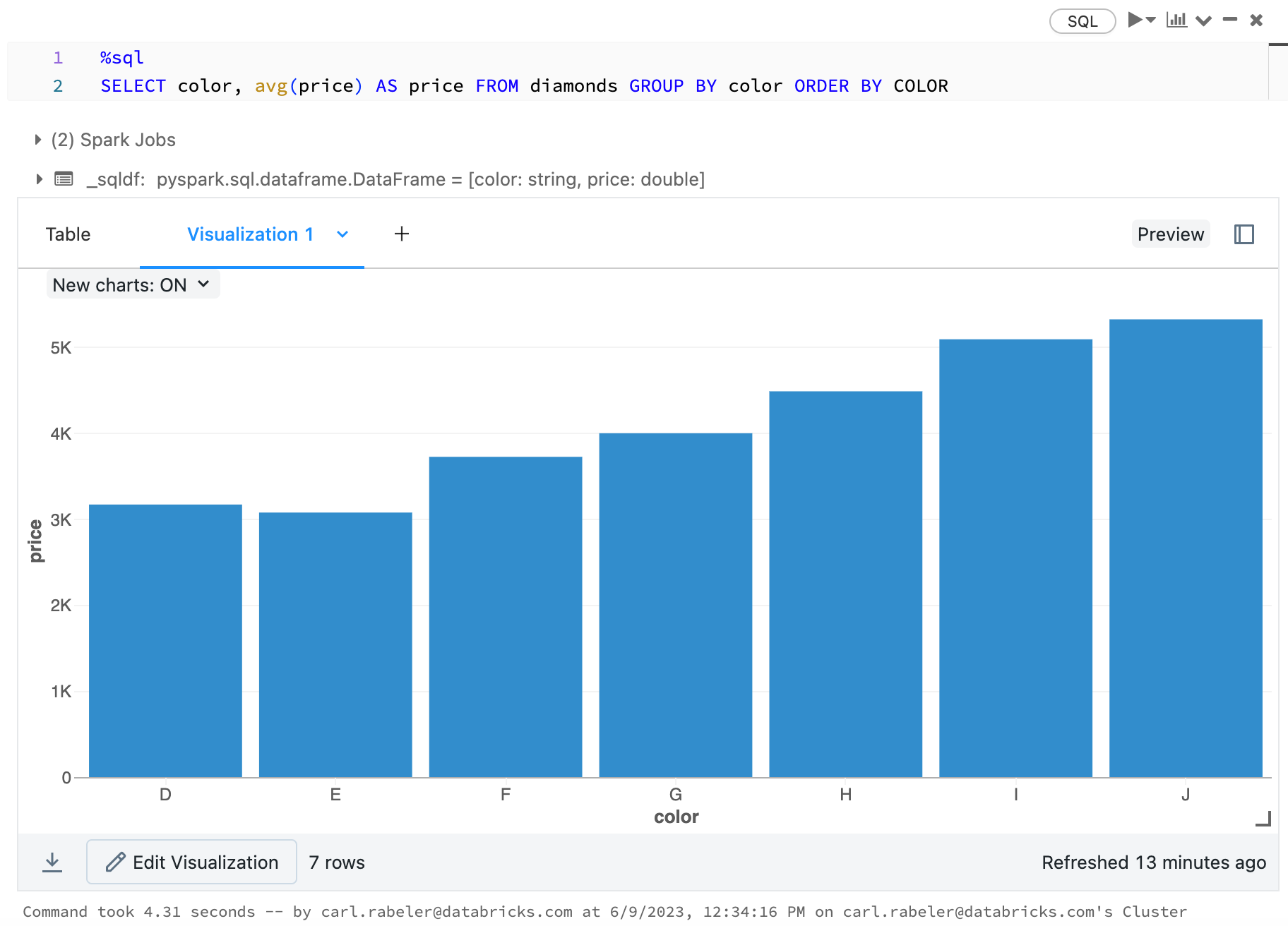
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Anda dapat menggunakan fungsi plot R default.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
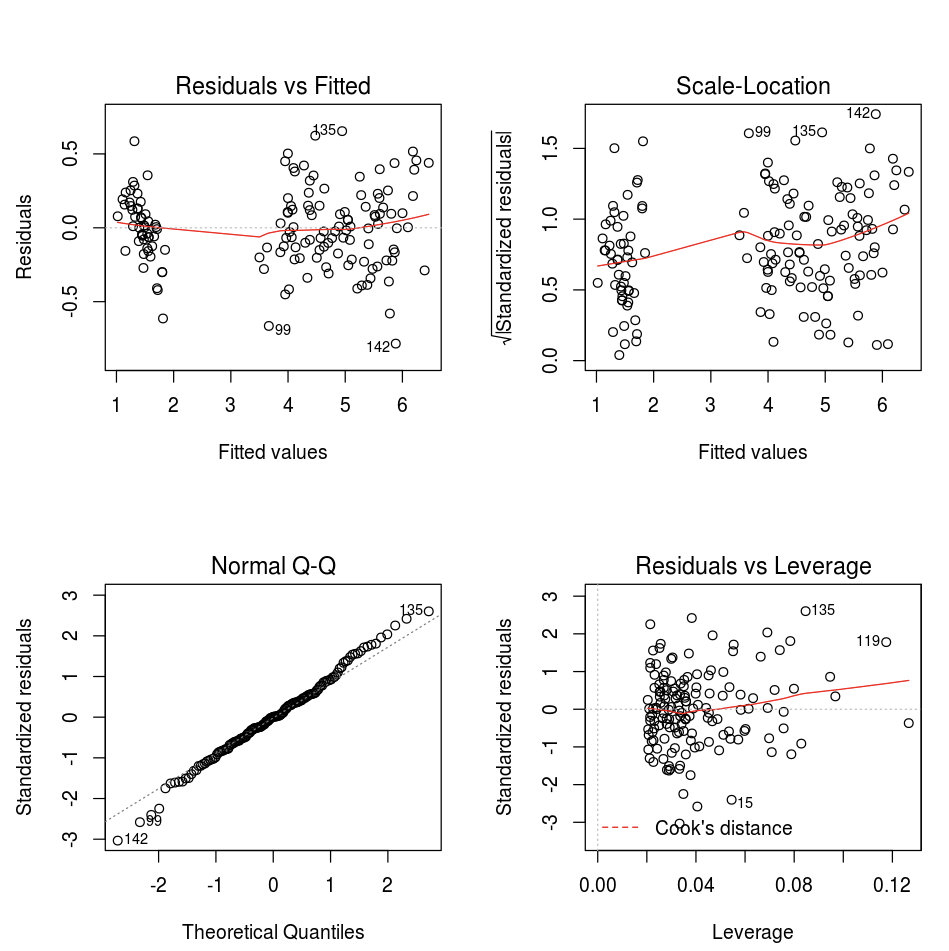
Anda juga dapat menggunakan paket visualisasi R apa pun. Notebook R menangkap plot yang dihasilkan sebagai .png dan menampilkannya secara sebaris.
Di bagian ini:
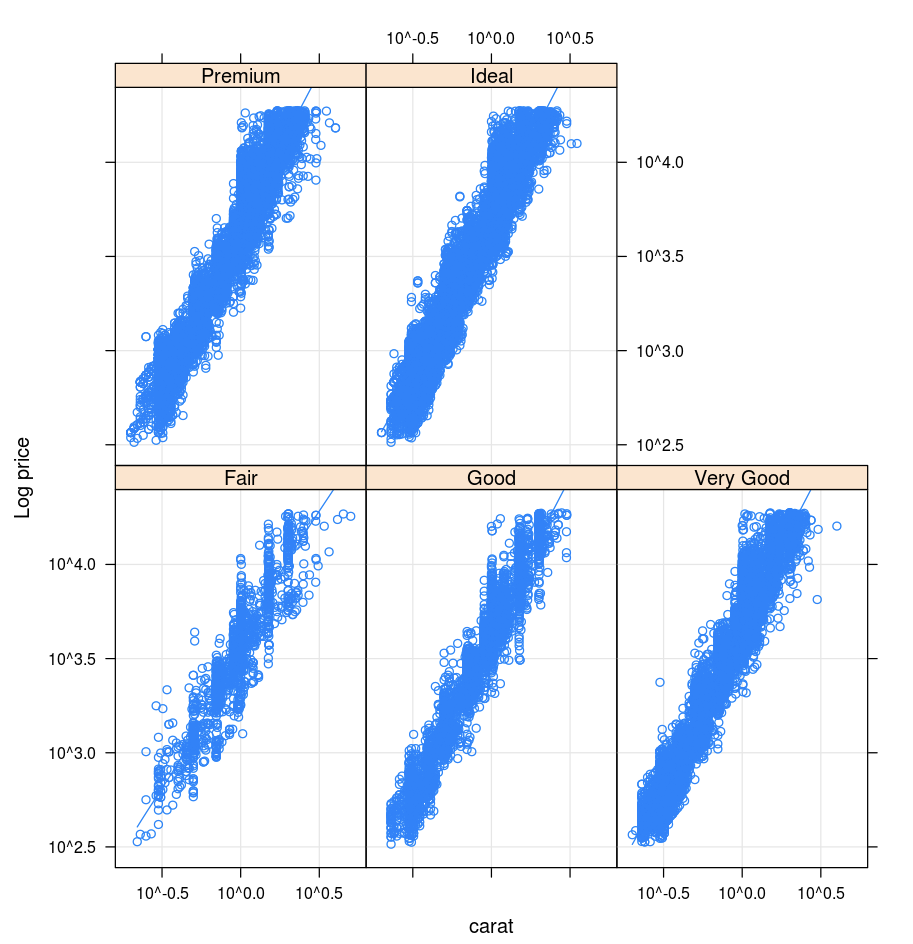
Kisi
Paket Lattice mendukung grafik trelis—grafik yang menampilkan variabel atau hubungan antar variabel, yang dikondisikan pada satu atau lebih variabel lainnya.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
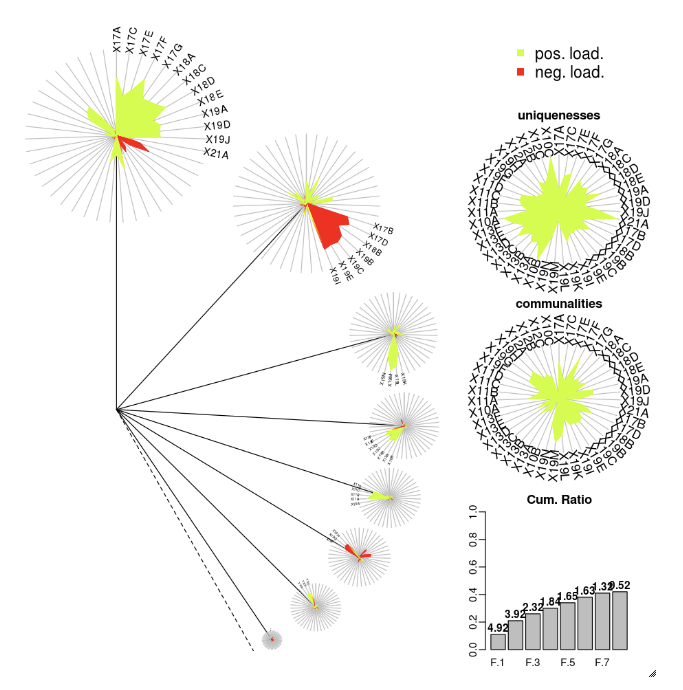
DandEFA
Paket DandEFA mendukung plot dandelion.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Secara plot
Paket R Plotly bergantung pada htmlwidgets untuk bahasa R. Untuk petunjuk penginstalan dan notebook, silakan lihat htmlwidgets.
Pustaka R lainnya
Visualisasi dalam Scala
Untuk mengeplot data dalam Scala, gunakan fungsi display sebagai berikut:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Pendalaman notebook untuk Python dan Scala
Untuk mendalami visualisasi Python, lihat buku catatan:
Untuk mendalami visualisasi Scala, lihat buku catatan: