Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Terjemahan non-bahasa Inggris disediakan hanya untuk kenyamanan. Silakan lihat EN-US versi dokumen ini untuk versi pengikatan.
Apa itu Catatan Transparansi?
Sistem AI tidak hanya menangani teknologi, tetapi juga orang-orang yang akan menggunakannya, orang-orang yang akan terpengaruh olehnya, dan lingkungan tempat AI disebarkan. Menciptakan sistem yang sesuai dengan tujuan yang dimaksudkan membutuhkan pemahaman tentang cara kerja teknologi, kemampuan dan batasannya, dan cara mencapai performa terbaik. Catatan Transparansi Microsoft dimaksudkan untuk membantu Anda memahami cara kerja teknologi AI kami, pilihan yang dapat dibuat pemilik sistem yang memengaruhi performa dan perilaku sistem, dan pentingnya memikirkan seluruh sistem, termasuk teknologi, orang-orang, dan lingkungan. Anda dapat menggunakan Catatan Transparansi saat mengembangkan atau menyebarkan sistem Anda sendiri atau membagikannya dengan orang-orang yang akan menggunakan atau terpengaruh oleh sistem Anda.
Catatan Transparansi Microsoft adalah bagian dari upaya yang lebih luas di Microsoft untuk mempraktikkan Prinsip AI kami. Untuk mengetahui selengkapnya, lihat prinsip Microsoft AI.
Dasar-dasar Pemahaman Konten Azure AI
Pendahuluan
Pemahaman Konten Azure AI menyerap konten yang tidak terstruktur dalam modalitas apa pun seperti dokumen, gambar, video, dan audio untuk menghasilkan output terstruktur dari skema bawaan atau yang ditentukan pengguna untuk paling mewakili skenario spesifik tugas dari konten. Output ini kemudian dapat dikonsumsi oleh aplikasi hilir, seperti menyimpannya dalam database, mengirim output ke sistem yang dikembangkan pelanggan untuk penalaran dengan LLM (yaitu, Pengambilan Augmented Generation atau RAG), membangun model AI/ML tertentu pada data, atau digunakan dalam alur kerja untuk mengotomatiskan proses bisnis. Pemahaman Konten akan memperluas cakupan Kecerdasan Dokumen Azure AI dan memanfaatkan kemampuan dari Azure Open AI Service, Azure AI Speech, dan Azure AI Vision untuk mendukung skenario modal tunggal dan multimodal.
Istilah kunci
| Istilah | Definisi |
|---|---|
| Klasifikasikan | Ini adalah jenis tipe bidang. Bidang akan mengklasifikasikan nilai dari data input menggunakan nama bidang. Contohnya adalah mengklasifikasikan apakah gambar memiliki cacat, atau wajah memiliki kacamata atau tidak. |
| Nilai Kepercayaan | Semua output Content Understanding mengembalikan nilai keyakinan dalam rentang antara 0 dan 1 untuk semua kata yang diekstrak dan pemetaan nilai kunci. Nilai ini menunjukkan persentase perkiraan berapa kali nilai tersebut mengekstrak kata dengan benar dari 100 atau memetakan pasangan kunci-nilai dengan benar. Misalnya, kata yang diperkirakan diekstraksi dengan benar 82% waktu menghasilkan nilai keyakinan 0,82. |
| Diarisasi | Diarisasi membedakan antara pembicara individual di setiap rekaman audio dengan menetapkan label anonim sementara ke setiap pembicara (misalnya, GUEST1, GUEST2, GUEST3, dll.) untuk menunjukkan pembicara mana yang berbicara dalam file audio. Semua CONTENT Understanding API yang mendukung transkripsi juga mendukung diarisasi. |
| Ekstrak | Ini adalah sejenis kategori bidang. Bidang akan langsung mengekstrak nilai dari data input. Contohnya adalah mengekstrak tanggal dari faktur atau tanda tangan dari dokumen. |
| Pendeteksi wajah | Menemukan wajah manusia dalam gambar dan mengembalikan kotak pembatas yang menunjukkan lokasi wajah. Model deteksi wajah sendiri tidak menemukan fitur yang mengidentifikasi secara individual, hanya kotak pembatas yang menandai seluruh wajah. Untuk semua wajah yang terdeteksi, FACE ID ditetapkan berdasarkan penyematan. Silakan merujuk ke dokumentasi konsep Deteksi wajah untuk informasi lebih lanjut. |
| Pengelompokan wajah | Setelah wajah terdeteksi, wajah yang diidentifikasi difilter ke dalam grup lokal. Jika seseorang terdeteksi lebih dari sekali, lebih banyak instance wajah diamati dibuat untuk orang ini. Silakan lihat [Dokumentasi pengelompokan wajah](/azure/ai-services/computer-vision/overview-identity" \l "group-faces) untuk informasi selengkapnya. |
| Menghasilkan | Ini adalah jenis kategori bidang. Bidang akan menghasilkan nilai dari konten bidang induk. Contohnya adalah menghasilkan deskripsi adegan dari video atau meringkas dari audio panggilan. |
| Skema | Skema adalah istilah yang kami gunakan untuk nama bidang dan deskripsi yang perlu disediakan pelanggan bagi kami untuk mengekstrak nilai dari input. Pemahaman Konten menyediakan sekumpulan skema bawaan agar sesuai dengan skenario Anda. Bergantung pada skenarionya, Pemahaman Konten memiliki daftar bidang yang telah ditentukan sebelumnya yang akan diisi berdasarkan input. Anda dapat menggunakan skema bawaan ini untuk memulai proyek Anda lebih cepat tanpa harus menentukan bidang sendiri. |
| Transkripsi | Fitur output ucapan ke teks otomatis Content Understanding, terkadang disebut transkripsi mesin atau pengenalan ucapan otomatis (ASR). Transkripsi menggunakan Azure AI Speech dan sepenuhnya otomatis. Semua CONTENT Understanding API yang mendukung transkripsi juga mendukung diarisasi. |
Kemampuan
Perilaku sistem
Azure AI Content Understanding adalah layanan Azure AI berbasis cloud yang menggunakan berbagai model AI/ML (seperti yang tersedia melalui Azure OpenAI Service, Azure Face Service, dan Azure Speech) untuk mengekstrak, mengklasifikasikan, dan menghasilkan bidang dari file input pelanggan. Pemahaman Konten tidak mendukung integrasi model apa pun yang dibawa pelanggan.
Pemahaman Konten terlebih dahulu mengekstrak konten ke dalam output terstruktur. Kemudian menggunakan model bahasa berkapasitas besar (LLM) untuk menghasilkan bidang dan menetapkan skor kepercayaan pada bidang yang relevan.
Saat ini, Pemahaman Konten dapat menyerap data dari jenis berikut: dokumen, gambar, teks, video, dan audio. Bergantung pada jenis data yang diunggah pengguna, Pemahaman Konten akan secara otomatis menyarankan pengguna skema bawaan umum yang dapat memulai. Pengguna juga memiliki pilihan untuk menyesuaikan skema itu sendiri, memungkinkan kemampuan penyerapan data yang lebih lengkap. Dalam kasus di mana pengguna mengunggah konten berbahaya, Pemahaman Konten akan mengeluarkan peringatan dalam output untuk memberi tahu pengguna bahwa file input berisi konten berbahaya, tetapi masih akan menghasilkan bidang.
Tujuan layanan ini adalah untuk memberikan representasi spesifik tugas yang dinormalisasi dari data input untuk mengaktifkan skenario ekstraktif dan generatif bagi pelanggan sambil memberikan pengalaman yang konsisten di seluruh modalitas. Perhatikan bahwa Pemahaman Konten tidak dimaksudkan untuk mendukung inferensi yang tidak berdasar, dan hanya akan menghasilkan output berdasarkan informasi dan konteks yang diberikan pengguna.
Nota
Pengeblurkan wajah
Untuk input ke GPT-4 Turbo dengan Visi dan GPT-4o yang berisi gambar atau video orang, sistem akan terlebih dahulu mengaburkan wajah sebelum diproses untuk mengembalikan hasil yang diminta. Blurring membantu melindungi privasi individu dan grup yang terlibat. Pengaburan seharusnya tidak memengaruhi kualitas penyelesaian Anda, tetapi Anda mungkin melihat sistem mengacu pada pengaburan wajah dalam beberapa kasus.
Penting
Setiap identifikasi individu bukan hasil pengenalan wajah atau pembuatan dan perbandingan templat wajah. Identifikasi adalah hasil dari pelatihan model untuk mengaitkan gambar individu dengan nama yang sama melalui pemberian tag gambar, di mana model mengembalikan nama dengan input gambar berikutnya dari individu tersebut. Model ini juga dapat mengambil petunjuk kontekstual selain wajah, sehingga model masih dapat mengaitkan gambar dengan individu meskipun wajahnya kabur. Misalnya, jika gambar berisi foto atlet populer yang mengenakan jersey tim mereka dan nomor spesifiknya, model masih dapat mendeteksi individu berdasarkan istiadat kontekstual.
Pemfilteran konten
Layanan Azure Content Understanding menyertakan sistem pemfilteran konten yang mendeteksi dan memblokir kategori tertentu dari konten yang berpotensi berbahaya dalam perintah input dan penyelesaian output. Variasi dalam konfigurasi API dan desain aplikasi dapat memengaruhi penyelesaian dan dengan demikian memfilter perilaku. Pelanggan yang disetujui dapat menyesuaikan sistem pemfilteran default dari Content Understanding untuk memberikan catatan alih-alih memblokir output yang bisa jadi berbahaya.
Nota
Menonaktifkan filter konten dapat mencegah layanan memblokir konten berbahaya secara efektif, termasuk, tetapi tidak terbatas pada, kategori kebencian dan keadilan, seksual, kekerasan, dan bahaya diri. Untuk informasi selengkapnya, lihatPemfilteran konten.
Menonaktifkan Indirect Attack Prompt Shield berpotensi mengekspos sistem terhadap kerentanan, di mana pihak ketiga dapat menyematkan instruksi berbahaya dalam dokumen yang dapat diakses dan diproses oleh sistem AI Generatif. Kerentanan analog dapat muncul dari upaya jailbreak yang secara langsung berusaha menghindari dan mengesampingkan perlindungan bawaan melalui perintah khusus.
Akses Terbatas ke Pemahaman Konten Azure AI
Fitur pengelompokan Wajah di Pemahaman Konten adalah layanan Akses Terbatas dan pendaftaran diperlukan untuk akses ke layanan tersebut. Untuk informasi selengkapnya, lihat Kebijakan Akses Terbatas Microsoft dan akses pendaftaran Face API. Fitur tertentu hanya tersedia untuk pelanggan terkelola Microsoft dan mitra yang disetujui, dan hanya untuk kasus penggunaan tertentu yang dipilih pada saat pendaftaran. Perhatikan bahwa deteksi wajah, atribut wajah, dan kasus penggunaan redaksi wajah tidak memerlukan pendaftaran.
Nota
Pada 11 Juni 2020, Microsoft mengumumkan bahwa mereka tidak akan menjual teknologi pengenalan wajah ke departemen kepolisian di Amerika Serikat sampai peraturan yang kuat, yang didasarkan pada hak asasi manusia, telah diberlakukan. Dengan demikian, pelanggan tidak boleh menggunakan fitur pengenalan wajah atau fungsionalitas yang disertakan dalam Layanan Azure, seperti Wajah, Pengindeks Video, atau Pemahaman Konten, jika pelanggan tersebut adalah departemen kepolisian di Amerika Serikat atau mengizinkan penggunaannya oleh atau untuk departemen tersebut.
Kasus penggunaan
Penggunaan yang dimaksudkan
Berikut adalah beberapa contoh kapan Anda mungkin menggunakan Pemahaman Konten.
- Otomatisasi proses pajak: Anda dapat menggunakan fitur ekstraksi dokumen Content Understanding untuk mengekstrak bidang dari formulir pajak. Terlepas dari templat yang berbeda, Anda akan dapat mengekstrak data kunci dari formulir pajak untuk menghasilkan tampilan informasi terpadu yang menghasilkan otomatisasi proses pajak.
- Analitik setelah panggilan pusat layanan: Dari rekaman panggilan, bisnis dapat menghasilkan wawasan. Input audio akan diubah menjadi output transkripsi teks, yang dapat digunakan untuk mengekstrak wawasan berharga yang mengarah pada peningkatan efisiensi pusat panggilan dan pengalaman pelanggan.
- Marketing Automation and DAM (Manajemen Aset Digital): Untuk membangun solusi manajemen aset media, Anda dapat menggunakan Content Understanding untuk mengekstrak bidang yang ditentukan dalam skema dari gambar dan video untuk mengekstrak wawasan untuk meningkatkan relevansi iklan yang ditargetkan.
- Pencarian dan penemuan konten dengan RAG (Retrieval Augmented Generation): Pelanggan yang perlu mencari dan menemukan konten modalitas apa pun (seperti teks, gambar, audio, video, atau media campuran,) berdasarkan konten, metadata, atau fitur mereka dapat menggunakan output terstruktur dari Content Understanding untuk mengaktifkan skenario RAG hilir.
- Ringkasan konten atau media: Misalnya, perusahaan media dapat menggunakan Pemahaman Konten untuk menghasilkan ringkasan dan sorotan acara olahraga.
- Pemahaman bagan dan grafik: Bentuk keuangan atau jurnal akademik yang berisi bagan dan grafik biasanya sulit dipahami ketika hanya teks yang sedang diekstraksi. Pemahaman Konten memecahkan masalah dengan menginterpretasikan bagan dan grafik dalam konteks dokumen atau gambar tertentu itu sendiri, dan pengguna dapat dengan mudah mengekstrak informasi yang mereka inginkan seperti jenis bagan atau grafik, ringkasan, dan makna keseluruhan.
Pertimbangan saat memilih kasus penggunaan lainnya
Pertimbangkan faktor-faktor berikut saat Anda memilih kasus penggunaan:
-
Hindari skenario saat penggunaan atau penyalahgunaan dapat mengakibatkan kerusakan fisik atau psikologis. Misalnya, menggunakan Pemahaman Konten untuk mendiagnosis pasien atau meresepkan obat dapat menyebabkan kerusakan yang signifikan.
Perhatian
Pemahaman Konten tidak dirancang, dimaksudkan, atau disediakan sebagai perangkat medis, dan tidak dirancang atau dimaksudkan untuk menjadi pengganti saran medis profesional, diagnosis, pengobatan, atau penilaian, dan tidak boleh digunakan untuk mengganti atau mengganti nasihat medis profesional, diagnosis, pengobatan, atau penilaian.
-
Tidak cocok untuk identifikasi atau verifikasi biometrik. Misalnya, Pemahaman Konten tidak dirancang atau ditujukan untuk identifikasi atau verifikasi unik individu berdasarkan geometri wajah, pola suara, atau karakteristik fisik, fisiologis, atau perilaku lainnya.
Penting
Jika Anda menggunakan produk atau layanan Microsoft untuk memproses Data Biometrik, Anda bertanggung jawab untuk: (i) memberikan pemberitahuan kepada subjek data, termasuk sehubungan dengan periode retensi dan penghancuran; (ii) mendapatkan persetujuan dari subjek data; dan (iii) menghapus Data Biometrik, semuanya sesuai dan diperlukan berdasarkan Persyaratan Perlindungan Data yang berlaku. "Data Biometrik" akan memiliki arti yang diatur dalam Pasal 4 GDPR dan, jika berlaku, istilah yang setara dalam persyaratan perlindungan data lainnya. Untuk informasi terkait, lihat Data dan Privasi untuk Pengenalan Wajah.
- Hindari penggunaan untuk melacak orang dalam konteks dunia nyata. Contohnya termasuk menggunakan Pemahaman Konten untuk pengawasan individu dalam konteks dunia nyata atau menggunakan Pemahaman Konten untuk memverifikasi bahwa individu yang digambarkan di lokasi terpisah adalah orang yang sama. Rekomendasi ini tidak berlaku untuk menggunakan Pemahaman Konteks untuk tujuan kreatif, seperti menemukan adegan pemindahan yang berbeda dengan aktor yang sama.
- Hindari skenario saat penggunaan atau penyalahgunaan sistem dapat berdampak konsekuensial pada peluang hidup atau status hukum. Contohnya termasuk skenario di mana penggunaan Pemahaman Konten dapat memengaruhi status hukum individu, hak hukum, atau akses mereka ke kredit, pendidikan, pekerjaan, layanan kesehatan, perumahan, asuransi, manfaat kesejahteraan sosial, layanan, peluang, atau persyaratan tempat mereka disediakan. Pertimbangkan untuk menggabungkan tinjauan dan pengawasan manusia yang bermakna untuk membantu mengurangi risiko hasil berbahaya.
- Pertimbangkan kasus penggunaan dengan hati-hati di domain atau industri berisiko tinggi. Contohnya termasuk tetapi tidak terbatas pada layanan kesehatan, kedokteran, keuangan, atau hukum.
- Hindari penggunaan untuk sistem pemantauan tugas yang dapat mengganggu privasi. Model AI dasar Pemahaman Konten tidak dirancang untuk memantau pola individu untuk menyimpulkan informasi pribadi yang intim, seperti orientasi seksual atau politik individu.
- Hindari skenario di mana penggunaan, atau penyalahgunaan sistem dapat menyebarkan narasi palsu tentang topik atau orang sensitif. Contohnya termasuk pembuatan dan distribusi informasi yang salah tentang peristiwa yang sangat sensitif atau pembuatan informasi tentang orang nyata dalam keadaan yang mencerminkan narasi palsu.
- Pertimbangkan dengan cermat lokal dan bahasa yang didukung: Model Pemahaman Konten memiliki lokal dan bahasa yang didukung yang berbeda. Misalnya, dalam bahasa Inggris itu sendiri, ada berbagai lokal seperti AS, Inggris dan Australia, yang memiliki perbedaan dalam bagaimana waktu diformat, serta ejaan untuk beberapa kata. Pastikan untuk memeriksa dengan cermat lokal dan bahasa yang didukung secara resmi untuk setiap modalitas.
- Hindari penggunaan di mana manusia dalam loop atau metode verifikasi sekunder tidak tersedia. Mekanisme fail-safe (misalnya, metode sekunder yang tersedia untuk pengguna akhir jika teknologi gagal) membantu mencegah penolakan layanan penting atau bahaya lainnya karena kesalahan dalam output.
- Tidak cocok untuk skenario di mana up-to-date, informasi yang akurat secara faktual sangat penting kecuali Anda memiliki peninjau manusia atau menggunakan model untuk mencari dokumen Anda sendiri dan memiliki kesesuaian terverifikasi untuk skenario Anda. Pemahaman Konten tidak memiliki informasi tentang peristiwa yang terjadi setelah tanggal pelatihannya, kemungkinan telah kehilangan pengetahuan tentang beberapa topik, dan mungkin tidak selalu menghasilkan informasi yang akurat secara faktual.
- Transkripsi percakapan dengan pengenalan pembicara: Pemahaman Konten tidak dirancang untuk memberikan diarisasi dengan pengenalan pembicara, dan tidak dapat digunakan untuk mengidentifikasi individu. Dengan kata lain, pembicara akan disajikan sebagai Guest1, Guest2, Guest3, dan sebagainya, dalam transkripsi. Ini akan ditetapkan secara acak dan mungkin tidak digunakan untuk mengidentifikasi pembicara individu dalam percakapan. Untuk setiap transkripsi percakapan, penugasan Guest1, Guest2, Guest3, dan sebagainya, akan acak.
- Pertimbangan hukum dan peraturan. Organisasi perlu mengevaluasi potensi kewajiban hukum dan peraturan tertentu saat menggunakan Pemahaman Konten. Pemahaman Konten tidak sesuai untuk digunakan di setiap industri atau skenario. Selalu gunakan Pemahaman Konten sesuai dengan ketentuan layanan yang berlaku dan kode etik yang relevan, termasuk Kode Etik AI Generatif.
- Pertimbangan hukum dan peraturan: Organisasi perlu mengevaluasi potensi kewajiban hukum dan peraturan tertentu saat menggunakan layanan dan solusi AI apa pun, yang mungkin tidak sesuai untuk digunakan di setiap industri atau skenario. Selain itu, layanan atau solusi AI tidak dirancang untuk dan tidak dapat digunakan dengan cara yang dilarang dalam ketentuan layanan yang berlaku dan kode etik yang relevan.
Keterbatasan
Batasan teknis, faktor operasional, dan rentang
Seperti semua sistem AI, ada beberapa batasan untuk Pemahaman Konten yang harus diperhatikan pelanggan.
Jika file input yang sangat mengganggu diunggah ke Pemahaman Konten, file tersebut dapat mengembalikan konten berbahaya dan menyinggung sebagai bagian dari hasilnya. Untuk mengurangi hasil yang tidak diinginkan ini, kami sarankan Anda mengontrol akses ke sistem dan mendidik orang-orang yang akan menggunakannya tentang penggunaan yang sesuai.
Pengelompokan wajah
Wajah kabur sebelum gambar atau video dikirim ke model untuk analisis sehingga inferensi pada wajah, seperti emosi, tidak akan berfungsi dalam gambar atau video. Hanya modalitas video yang mendukung pengelompokan wajah yang hanya menyediakan grup wajah serupa tanpa analisis tambahan.
Penting
Fitur pengelompokan wajah dalam Pemahaman Konten dibatasi berdasarkan kriteria kelayakan dan penggunaan. untuk mendukung prinsip-prinsip AI yang Bertanggung Jawab. Layanan Face hanya tersedia untuk pelanggan dan mitra terkelola Microsoft. Gunakan formulir pendaftaran Pengenalan Wajah untuk mengajukan akses. Untuk informasi selengkapnya, lihat halaman Akses Terbatas Wajah.
Dokumen
Kemampuan ekstraksi dokumen sangat bergantung pada cara Anda menamai bidang dan deskripsi bidang. Selain itu, produk memaksa proses dasar, yaitu menempatkan output dalam teks dokumen masukan, dan tidak akan mengembalikan jawaban jika tidak dapat ditempatkan dengan benar. Oleh karena itu, dalam beberapa kasus, nilai bidang mungkin hilang. Karena metode ekstraksi bersifat dasar, sistem akan mengambil konten dari dokumen meskipun dokumen tersebut salah atau kontennya tidak terlihat oleh mata manusia. Dokumen juga harus memiliki resolusi yang wajar, di mana teks tidak terlalu buram agar model Tata Letak dikenali.
Rekaman video
Pemahaman Konten tidak dimaksudkan untuk menggantikan pengalaman menonton penuh video, terutama untuk konten di mana detail dan nuansa sangat penting. Ini juga tidak dirancang untuk meringkas video yang sangat sensitif atau rahasia di mana konteks dan privasi sangat penting.
- Kualitas video: Selalu unggah konten video dan audio berkualitas tinggi. Ukuran bingkai maksimum yang disarankan adalah HD dan kecepatan bingkai adalah 30 FPS. Bingkai harus berisi tidak lebih dari 10 orang. Saat mengeluarkan bingkai dari video ke model AI, hanya kirim sekitar satu bingkai per detik. Memproses 10 bingkai atau lebih mungkin menunda hasil AI. Setidaknya diperlukan 1 menit percakapan spontan untuk melakukan analisis. Deteksi sinyal audio non-ucapan seperti efek suara dan musik vokal tidak didukung.
- Akurasi wawasan yang dihasilkan mungkin lebih rendah ketika wajah direkam oleh kamera yang dipasang tinggi, menghadap ke bawah, atau dengan bidang pandang yang luas (FOV) mungkin memiliki lebih sedikit piksel.
- Detektor dapat salah mengklasifikasikan objek dalam video yang berada dalam tampilan overhead saat dilatih dengan tampilan frontal objek.
- Bahasa non-bahasa Inggris: Pemahaman Konten terutama diuji dan dioptimalkan untuk bahasa Inggris. Ketika diterapkan ke bahasa non-bahasa Inggris, akurasi dan kualitas ringkasan dapat bervariasi. Untuk mengurangi batasan ini, pengguna yang menggunakan fitur untuk bahasa non-bahasa Inggris harus memverifikasi ringkasan yang dihasilkan untuk akurasi dan kelengkapan.
- Video dengan beberapa bahasa: Jika video menggabungkan ucapan dalam beberapa bahasa, Ringkasan Video Tekstual mungkin berjuang untuk mengenali semua bahasa yang ditampilkan dalam konten video secara akurat. Pengguna harus mengetahui potensi batasan ini saat menggunakan fitur Ringkasan Video Tekstual untuk video multibahasa.
- Video yang sangat khusus atau teknis: Model AI untuk Ringkasan Video dilatih menggunakan berbagai video, termasuk berita, film, dan konten umum lainnya. Jika video sangat khusus atau teknis, model mungkin tidak dapat mengekstrak ringkasan video secara akurat.
- Video dengan kualitas audio yang buruk atau OCR (pengenalan karakter optik): Model AI Ringkasan Video Tekstual mengandalkan audio dan wawasan lainnya untuk mengekstrak ringkasan dari video, atau OCR untuk mengekstrak teks yang muncul di layar. Jika kualitas audio buruk dan tidak ada teks yang diidentifikasi, model mungkin tidak dapat mengekstrak ringkasan dari video secara akurat.
- Video dengan pencahayaan rendah atau gerakan cepat: Video yang diambil dalam pencahayaan rendah atau memiliki gerakan cepat mungkin sulit bagi model untuk mengolah informasi, menghasilkan performa yang buruk.
- Video dengan aksen atau dialek yang tidak biasa: Model AI dilatih pada berbagai ucapan, termasuk aksen dan dialek yang berbeda. Namun, jika video berisi ucapan dengan aksen atau dialek yang tidak diwakili dengan baik dalam data pelatihan, model mungkin berjuang untuk mengekstrak transkrip secara akurat dari video.
Suara
Untuk file audio, Anda mungkin perlu menentukan lokal untuk setiap input audio. Lokal harus cocok dengan bahasa aktual yang diucapkan dalam suara input. Pemahaman Konten mendukung deteksi bahasa otomatis juga untuk beberapa kasus penggunaan. Untuk informasi selengkapnya, lihat daftar lokal yang didukung.
- Kualitas akustik: Aplikasi dan perangkat yang mendukung ucapan ke teks dapat menggunakan berbagai jenis dan spesifikasi mikrofon. Model ucapan terpadu telah dilatih pada berbagai skenario perangkat audio suara, seperti telepon, ponsel, dan perangkat speaker. Kualitas suara mungkin terdegradasi dengan cara pengguna berbicara ke mikrofon, bahkan jika mereka menggunakan mikrofon berkualitas tinggi. Misalnya, jika speaker terletak jauh dari mikrofon, kualitas input mungkin terlalu rendah. Speaker yang terlalu dekat dengan mikrofon juga dapat menyebabkan penurunan kualitas audio. Kasus-kasus ini, serta kasus apa pun yang menyebabkan kualitas file audio terdegradasi dapat berdampak buruk pada akurasi ucapan ke teks.
- Kebisingan bukan ujaran: Jika audio input berisi tingkat kebisingan tertentu, akurasi akan terpengaruh. Kebisingan yang berasal dari perangkat audio yang digunakan untuk membuat rekaman, atau input audio itu sendiri mungkin berisi kebisingan, seperti latar belakang atau kebisingan lingkungan.
- Ucapan yang tumpang tindih: Mungkin ada beberapa pembicara dalam rentang perangkat input audio, dan mungkin berbicara secara bersamaan. File audio yang memiliki suara speaker lain yang direkam di latar belakang saat pembicara utama merekam juga menghasilkan file ucapan yang tumpang tindih. Selain itu, meskipun tidak ada batasan pada jumlah pembicara dalam percakapan, sistem berkinerja lebih baik ketika jumlah pembicara di bawah 30.
- Kosakata: Jika kata yang tidak ada dalam model muncul di audio, hasilnya adalah kesalahan dalam transkripsi.
- Aksen: Bahkan dalam satu lokal, seperti dalam bahasa Inggris - Amerika Serikat (en-US), banyak orang memiliki aksen yang berbeda. Aksen yang sangat spesifik mungkin juga menyebabkan kesalahan dalam transkripsi.
- Bahasa atau lokal yang tidak cocok: Jika Anda menentukan bahasa Inggris - Amerika Serikat (en-US) untuk input audio, tetapi pembicara berbicara dalam bahasa Swedia, misalnya, akurasi akan berkurang.
- Kesalahan penyisipan: Terkadang, model dapat menghasilkan kesalahan penyisipan dengan adanya kebisingan atau ucapan latar belakang lunak.
Gambar
- Pengenalan Objek: Pengenalan produk ambigu tertentu mungkin tidak akurat jika tidak dapat dikenali oleh model. Konsep abstrak yang tidak sesuai dengan gambar, misalnya, jenis kelamin dan emosi, mungkin tidak dikenali juga.
Performa sistem
Metrik performa berbeda untuk setiap modalitas dalam Pemahaman Konten. Setiap modalitas akan memiliki standar industri yang berbeda untuk mengukur performa AI.
Salah satu metrik umum yang kami berikan dalam Pemahaman Konten di semua modalitas adalah skor keyakinan untuk bidang. Sampai sekarang, hanya jenis bidang "ekstrak" dan "hasilkan" yang akan memiliki tingkat kepercayaan.
Fitur khas Pemahaman Konten adalah dukungannya untuk skor grounding dan skor keyakinan, saat ini hanya tersedia untuk modalitas dokumen tetapi direncanakan untuk pengembangan di masa depan. Penandaan dalam dokumen mencakup nomor halaman dan kotak pembatas untuk nilai yang diekstrak, meningkatkan pengalaman pengguna dengan menyoroti lokasi untuk tinjauan dan koreksi manusia. Skor keyakinan, mulai dari 0 hingga 1, memperkirakan akurasi nilai yang diekstrak berdasarkan dokumen yang dianalisis atau pelatihan, dengan skor yang lebih tinggi menunjukkan keyakinan yang lebih besar. Untuk panduan tentang menggunakan skor keyakinan, lihat bagian Evaluasi Pemahaman Konten.
Di bawah ini adalah metrik performa umum yang dapat Anda gunakan untuk setiap modalitas:
Dokumen
Akurasi
Teks terdiri dari baris dan kata-kata di tingkat dasar dan entitas seperti nama, harga, jumlah, nama perusahaan, dan produk di tingkat pemahaman dokumen.
Akurasi tingkat kata
Ukuran akurasi untuk OCR adalah tingkat kesalahan kata (WER), atau berapa banyak kata yang salah dihasilkan dalam hasil yang diekstraksi. Semakin rendah WER, semakin tinggi akurasinya.
WER didefinisikan sebagai:
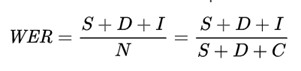
Lokasi:
| Istilah | Definisi | Contoh |
|---|---|---|
| S | Jumlah kata yang salah ("diganti") dalam output. | "Velvet" akan diekstraksi menjadi "Veivet" karena "l" terdeteksi secara salah sebagai "i." |
| D | Jumlah kata yang hilang ("dihapus") dalam output. | Untuk teks "Nama Perusahaan: Microsoft," Microsoft tidak diekstrak karena ditulis tangan atau sulit dibaca. |
| Saya | Jumlah kata yang tidak terdapat ("disisipkan") dalam output. | "Departemen" disegmentasikan secara salah menjadi tiga kata sebagai "Dep artm ent." Dalam hal ini, hasilnya adalah satu kata yang dihapus dan tiga kata yang dimasukkan. |
| C | Jumlah kata yang diekstrak dengan benar dalam output. | Semua kata yang telah diekstrak dengan benar. |
| N | Jumlah total kata dalam referensi (N=S+D+C) dengan mengesampingkan I karena kata-kata tersebut hilang dari referensi asli dan salah diprediksi ada. | Pertimbangkan gambar dengan kalimat, "Microsoft, yang bermarkas di Redmond, WA mengumumkan produk baru yang disebut Velvet untuk departemen keuangan." Asumsikan output OCR adalah " , yang bermarkas di Redmond, WA mengumumkan produk baru yang disebut Veivet untuk dep artm ents keuangan." Dalam hal ini, S (Velvet) = 1, D (Microsoft) = 1, I (dep artm ents) = 3, C (11), dan N = S + D + C = 13. Oleh karena itu, WER = (S + D + I) / N = 5 / 13 = 0,38 atau 38% (dari 100). |
Akurasi tingkat dokumen dan entitas Pada tingkat dokumen, misalnya, dalam kasus faktur atau tanda terima, kesalahan hanya satu karakter di seluruh dokumen mungkin dinilai tidak signifikan. jika kesalahan tersebut ada dalam teks yang mewakili jumlah berbayar, seluruh faktur atau tanda terima mungkin ditandai sebagai salah.
Metrik lain adalah tingkat kesalahan entitas (EER). Ini adalah persentase entitas yang salah diekstraksi, seperti nama, harga, jumlah, dan nomor telepon, dari jumlah total entitas yang sesuai dalam satu atau beberapa dokumen. Misalnya, untuk total 30 kata yang mewakili 10 nama, 2 kata yang salah dari 30 sama dengan 0,06 (6%) WER. Tetapi jika itu menghasilkan 2 nama dari 10 yang salah, tingkat kesalahan Nama (Nama EER) adalah 0,20 (20%), yang jauh lebih tinggi dari WER.
Mengukur WER dan EER adalah latihan yang berguna untuk mendapatkan perspektif penuh tentang akurasi pemahaman dokumen.
Rekaman video
Akurasi analisis video tergantung pada beberapa faktor termasuk penempatan kamera dan interpretasi output sistem. Akurasi harus dinilai oleh seberapa dekat hasil nilai bidang mode selaras dengan konten video yang sebenarnya. Misalnya, ketika pengguna mencari entitas dalam video, diharapkan untuk mengembalikan daftar lengkap entitas yang ditemukan dalam video. Untuk mengevaluasi akurasi, himpunan data pengujian tertentu, perwakilan dari berbagai skenario dan kondisi dunia nyata, digunakan. Himpunan data ini mencakup berbagai jenis konten video dan skenario interaksi pengguna.
| Istilah | Definisi |
|---|---|
| Benar Positif | Output yang dihasilkan sistem dengan benar sesuai dengan peristiwa nyata. |
| Negatif Benar | Sistem dengan benar tidak menghasilkan peristiwa ketika peristiwa nyata belum terjadi. |
| Positif Palsu | Sistem salah menghasilkan/mengekstrak/mengklasifikasikan output ketika tidak ada peristiwa nyata yang terjadi. |
| Negatif Palsu | Sistem gagal menghasilkan output saat peristiwa nyata telah terjadi. |
Suara
Performa sistem diukur oleh faktor-faktor utama ini:
- Tingkat kesalahan kata (WER)
- Tingkat kesalahan token (TER)
- Latensi runtime
Sebuah model dianggap lebih baik hanya ketika menunjukkan peningkatan yang signifikan (seperti peningkatan relatif WER sebesar 5%) dalam semua skenario (seperti transkripsi ucapan percakapan, transkripsi pusat panggilan, dikte, dan asisten suara) selama konsisten dengan penggunaan sumber daya dan sasaran latensi respons.
Untuk diarisasi, kami mengukur kualitas dengan menggunakan tingkat kesalahan diarisasi kata (WDER). Semakin rendah WDER, semakin baik kualitas diarisasi.
Gambar
Akurasi analisis gambar adalah ukuran seberapa baik output sesuai dengan konten visual aktual yang ada dalam gambar. Untuk mengukur akurasi analisis gambar, Anda dapat mengevaluasi gambar dengan data kebenaran dasar Anda dan membandingkan output model AI. Dengan membandingkan kebenaran dasar dengan hasil yang dihasilkan AI, Anda dapat mengklasifikasikan peristiwa menjadi dua jenis hasil yang benar ("true") dan dua jenis hasil yang salah ("salah"):
| Istilah | Definisi |
|---|---|
| Benar Positif | Output yang dihasilkan sistem dengan benar sesuai dengan data kebenaran dasar. Misalnya, sistem menandai gambar anjing dengan benar sebagai anjing. |
| Negatif Benar | Sistem dengan benar tidak menghasilkan hasil yang tidak ada dalam data kebenaran dasar. Misalnya, sistem dengan benar tidak menandai gambar sebagai anjing ketika tidak ada anjing yang ada dalam gambar. |
| Positif Palsu | Sistem salah menghasilkan output yang tidak ada dalam data kebenaran dasar. Misalnya, sistem menandai gambar kucing sebagai anjing. |
| Negatif Palsu | Sistem gagal menghasilkan hasil yang ada dalam data kebenaran dasar. Misalnya, sistem gagal menandai gambar anjing yang ada dalam gambar. |
Kategori peristiwa ini digunakan untuk menghitung presisi dan pengenalan:
| Istilah | Definisi |
|---|---|
| Presisi | Ukuran kebenaran konten yang diekstrak. Dari gambar yang berisi beberapa objek, Anda mengetahui berapa banyak objek tersebut yang diekstrak dengan benar. |
| Penarikan | Ukuran konten keseluruhan yang diekstrak. Dari gambar yang berisi beberapa objek, Anda mengetahui berapa banyak objek yang terdeteksi secara keseluruhan, tanpa memperhatikan kebenarannya. |
Definisi presisi dan pengenalan menyiratkan bahwa, dalam kasus tertentu, mungkin sulit untuk dioptimalkan untuk presisi dan pengenalan pada saat yang sama. Bergantung pada skenario Anda, Anda mungkin perlu memprioritaskan satu di atas yang lain. Misalnya, jika Anda mengembangkan solusi untuk mendeteksi hanya tag atau label yang paling akurat dalam konten, seperti untuk menampilkan hasil pencarian gambar, Anda akan mengoptimalkan presisi yang lebih tinggi. Tetapi jika Anda mencoba menandai semua konten visual yang mungkin dalam gambar untuk pengindeksan atau katalog internal, Anda akan mengoptimalkan untuk pengenalan yang lebih tinggi.
Praktik terbaik untuk meningkatkan performa sistem
Dalam kebanyakan kasus, meningkatkan performa sistem sangat tergantung pada pengguna yang menyediakan data yang cukup dimengerti bagi Pemahaman Konten untuk mengekstrak nilai.
Pastikan bahwa bidang yang dihasilkan dari konten relevan dengan penggunaan hilir yang dimaksudkan. Misalnya, jika Anda ingin mencari "anjing yang bermain di halaman belakang", pastikan output bidang Anda menyertakan konsep ini dan memperbarui definisi skema seperti nama bidang dan deskripsi bidang untuk memperbaikinya jika tidak.
Untuk gambar, lihat dokumentasi berikut untuk persyaratan input tertentu. Gambar harus memiliki kualitas yang wajar, paparan cahaya, dan kontras.
Untuk audio, lokal yang tidak cocok mengurangi akurasi, jadi penting untuk mencocokkan lokal input dengan speaker dalam file. Gunakan file audio dengan kondisi akustik yang wajar dan hindari file dengan kebisingan latar belakang, ucapan samping, jarak ke mikrofon dan gaya berbicara yang dapat berdampak buruk pada akurasi.
Mempertimbangkan batasan setiap modalitas sehubungan dengan input, bahasa, dan lokal yang saat ini didukung, dan skenario juga akan membantu meningkatkan performa sistem.
Namun, untuk ekstraksi dokumen, ada cara untuk meningkatkan kualitas penganalisis, yaitu memperbarui atau memperbaiki hasil label bidang sesuai kebutuhan dengan setiap dokumen yang Anda tambahkan ke himpunan data. Fitur ekstraksi dokumen mendukung pembelajaran dalam konteks, sehingga lebih banyak himpunan data dan label bidang yang akurat akan menyebabkan performa sistem yang lebih baik secara umum. Untuk formulir yang diisi, disarankan juga untuk menggunakan contoh yang memiliki semua bidang yang diisi dan menggunakan nilai dunia nyata yang ingin Anda lihat untuk setiap bidang.
Evaluasi Pemahaman Konten
Metode evaluasi
Untuk membuat Pemahaman Konten, kami menyiapkan himpunan data yang menargetkan kasus penggunaan pelanggan umum. Ini disiapkan secara independen oleh Microsoft, dan kami tidak menggunakan data pelanggan yang dikirim ke layanan kami untuk tujuan pelatihan atau evaluasi apa pun.
Efektivitas Content Understanding akan bergantung pada aplikasi tertentu yang digunakannya. Pelanggan harus melakukan pengujian mereka sendiri untuk menjamin hasil terbaik.
Misalnya, dalam ekstraksi dokumen, layanan menetapkan nilai keyakinan dari 0 hingga 1 untuk setiap kata dan bidang. Menjalankan uji coba dapat membantu pelanggan menilai rentang nilai keyakinan dan kualitas ekstraksi. Mereka kemudian dapat mengatur ambang batas, seperti mengirim hasil dengan nilai keyakinan 0,80 atau lebih tinggi untuk pemrosesan langsung, dan yang di bawah ini untuk tinjauan manusia.
Hasil evaluasi
Untuk memastikan performa layanan, kami secara teratur melakukan evaluasi dan analisis kesalahan, menggunakan hasilnya untuk meningkatkan penawaran kami. Banyak dari evaluasi ini disesuaikan dengan skenario pelanggan dan membantu menentukan batasan seperti nomor bidang dan ukuran data pelatihan. Batasan ini didokumenkan untuk referensi pelanggan. Karena banyak kemungkinan skenario, kami tidak dapat menguji semuanya. Misalnya, kami sering menguji domain keuangan tetapi memiliki lebih sedikit cakupan di bidang medis.
Pertimbangan keadilan
Salah satu dimensi penting yang perlu dipertimbangkan saat menggunakan sistem AI, adalah seberapa baik performa sistem untuk berbagai kelompok orang. Penelitian telah menunjukkan bahwa tanpa upaya sadar yang berfokus pada peningkatan performa untuk semua kelompok, sistem AI dapat menunjukkan berbagai tingkat performa di berbagai faktor demografis seperti ras, etnis, jenis kelamin, dan usia.
Sebagai bagian dari evaluasi Pemahaman Konten Azure AI, kami telah melakukan analisis untuk menilai potensi kerugian keadilan. Kami telah memeriksa performa sistem di berbagai grup demografis, yang bertujuan untuk mengidentifikasi perbedaan atau perbedaan yang mungkin ada dan berpotensi berdampak pada kewajaran.
Dalam beberapa kasus, mungkin ada perbedaan kinerja yang masih ada. Penting untuk dicatat bahwa perbedaan ini mungkin melebihi target, dan kami secara aktif bekerja untuk mengatasi dan meminimalkan potensi bias atau kesenjangan performa dan mencari perspektif yang beragam dari berbagai latar belakang.
Mengenai bahaya representasional, seperti stereotip, merendahkan, atau menghapus output, kami mengakui risiko yang terkait dengan masalah ini. Meskipun proses evaluasi kami bertujuan untuk mengurangi risiko tersebut, kami mendorong pengguna untuk mempertimbangkan kasus penggunaan spesifik mereka dengan hati-hati dan menerapkan mitigasi tambahan sebagaimana mestinya. Kehadiran manusia dalam proses dapat memberikan lapisan pengawasan tambahan untuk mengatasi potensi bias atau konsekuensi yang tidak diinginkan.
Kami berkomitmen untuk terus meningkatkan evaluasi kewajaran kami untuk mendapatkan pemahaman yang lebih mendalam tentang kinerja sistem di berbagai kelompok demografis dan potensi masalah kewajaran. Proses evaluasi sedang berlangsung, dan kami secara aktif berupaya meningkatkan kewajaran dan inklusivitas serta mengurangi perbedaan yang diidentifikasi. Anda dapat menemukan lebih banyak pengujian kewajaran yang terkait dengan ucapan dalam dokumentasi ini.
Mengevaluasi dan mengintegrasikan Analisis Gambar untuk penggunaan Anda
Saat mengintegrasikan Pemahaman Konten untuk kasus penggunaan Anda, mengetahui bahwa Pemahaman Konten tunduk pada Kode Etik Layanan AI Microsoft Generative akan memastikan integrasi yang sukses.
Saat Anda bersiap-siap untuk mengintegrasikan Pemahaman Konten ke produk atau fitur Anda, aktivitas berikut membantu menyiapkan Anda untuk sukses:
- Pahami apa yang dapat dilakukannya: Sepenuhnya menilai potensi Pemahaman Konten untuk memahami kemampuan dan batasannya. Pahami bagaimana performanya dalam skenario dan konteks Anda. Misalnya, jika Anda menggunakan ekstraksi konten audio, uji dengan rekaman dunia nyata dari proses bisnis Anda untuk menganalisis dan membuat tolok ukur hasil terhadap metrik proses yang ada.
- Hormati hak privasi seseorang: Hanya kumpulkan data dan informasi dari individu yang telah Anda peroleh persetujuannya, dan untuk tujuan yang sah dan dapat dibenar.
- Pertimbangan hukum dan peraturan. Organisasi perlu mengevaluasi potensi kewajiban hukum dan peraturan tertentu saat menggunakan Pemahaman Konten. Pemahaman Konten tidak sesuai untuk digunakan di setiap industri atau skenario. Selalu gunakan Pemahaman Konten sesuai dengan ketentuan layanan yang berlaku dan Kode Etik Layanan Microsoft Generative AI.
- Human-in-the-loop: Libatkan manusia dalam proses, dan sertakan pengawasan manusia sebagai area pola konsisten untuk dijelajahi. Ini berarti memastikan pengawasan manusia yang konstan terhadap produk atau fitur yang didukung AI dan untuk mempertahankan peran manusia dalam pengambilan keputusan. Pastikan Anda memiliki kemampuan untuk intervensi manusia secara real-time untuk solusi guna mencegah bahaya. Keberadaan manusia dalam proses memungkinkan Anda mengelola situasi saat Pemahaman Konten tidak bekerja seperti yang diharapkan.
- Keamanan: Pastikan solusi Anda aman dan memiliki kontrol yang memadai untuk mempertahankan integritas konten Anda dan mencegah akses yang tidak sah.
Pelajari selengkapnya tentang AI yang bertanggung jawab
- Prinsip Microsoft AI
- Sumber daya AI yang bertanggung jawab Microsoft
- Kursus Microsoft Azure Learning tentang AI yang bertanggung jawab
Pelajari selengkapnya tentang Pemahaman Konten
- Gambaran umum Azure OpenAI
- Gambaran umum Kecerdasan Dokumen Azure AI
- Gambaran umum Azure AI Speech
- Gambaran umum Azure AI Vision
- Gambaran umum layanan Azure AI Face
- Gambaran umum Azure AI Video Indexer
Catatan transparansi tambahan untuk layanan yang mendasar
- Azure OpenAI
- Azure AI Document Intelligence
- Azure AI Speech
- Azure AI Vision
- Azure AI Face
- Pengindeks Video Azure AI