Pengambilan-Augmented Generation dengan Kecerdasan Dokumen Azure AI
Konten ini berlaku untuk:![]() v4.0 (pratinjau)
v4.0 (pratinjau)
Pendahuluan
Retrieval-Augmented Generation (RAG) adalah pola desain yang menggabungkan Model Bahasa Besar (LLM) yang telah dilatih sebelumnya seperti ChatGPT dengan sistem pengambilan data eksternal untuk menghasilkan respons yang ditingkatkan yang menggabungkan data baru di luar data pelatihan asli. Menambahkan sistem pengambilan informasi ke aplikasi Anda memungkinkan Anda untuk mengobrol dengan dokumen Anda, menghasilkan konten yang menawan, dan mengakses kekuatan model Azure OpenAI untuk data Anda. Anda juga memiliki kontrol lebih besar atas data yang digunakan oleh LLM saat merumuskan respons.
Model Tata Letak Kecerdasan Dokumen adalah API analisis dokumen berbasis pembelajaran mesin tingkat lanjut. Model Tata Letak menawarkan solusi komprehensif untuk ekstraksi konten tingkat lanjut dan kemampuan analisis struktur dokumen. Dengan model Tata Letak, Anda dapat dengan mudah mengekstrak teks dan elemen struktural untuk membagi isi teks besar menjadi potongan yang lebih kecil dan bermakna berdasarkan konten semantik daripada pemisahan semena-mena. Informasi yang diekstrak dapat dengan mudah dihasilkan ke format Markdown, memungkinkan Anda untuk menentukan strategi penggugusan semantik Anda berdasarkan blok penyusun yang disediakan.
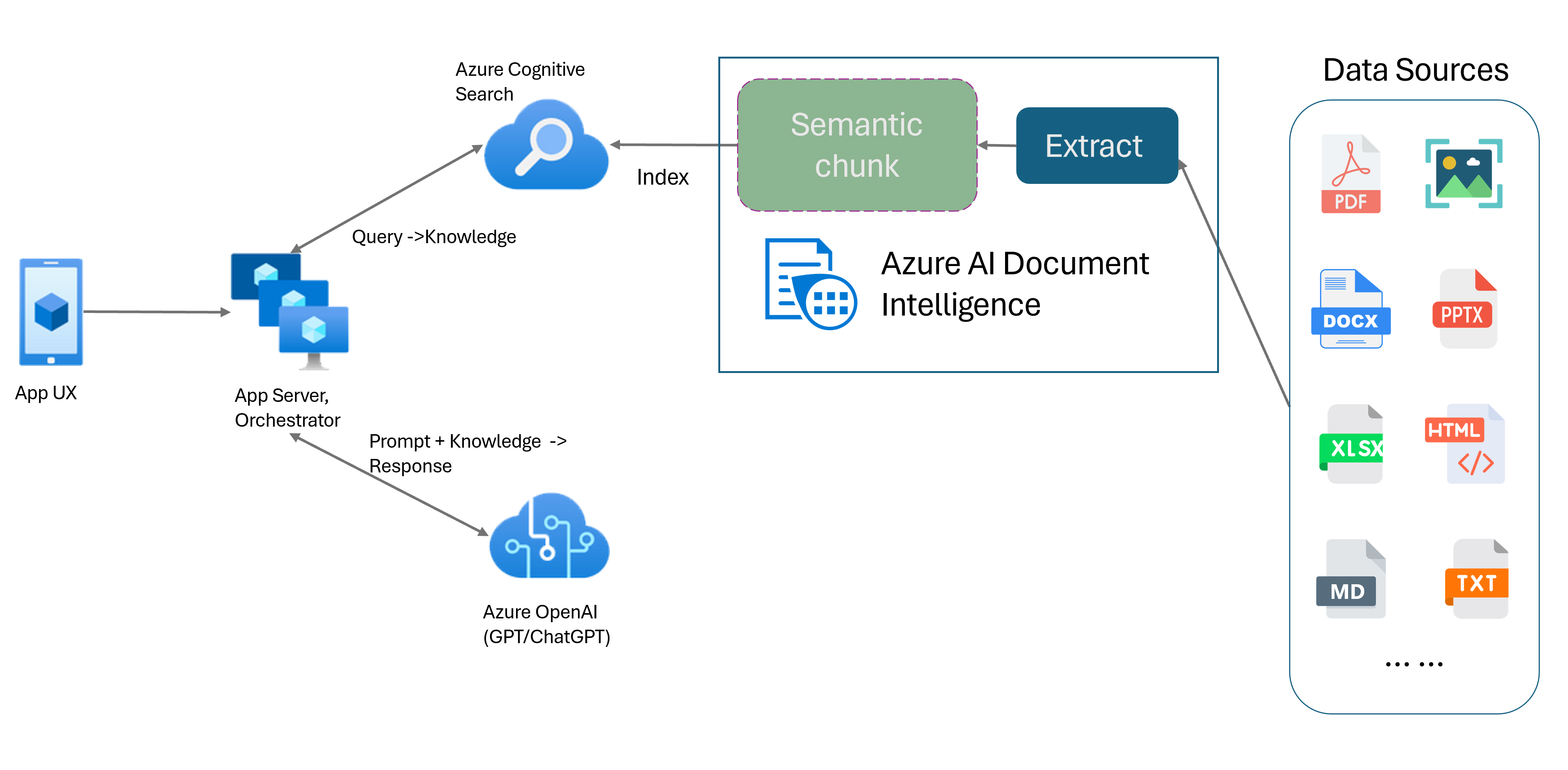
Potongan semantik
Kalimat panjang menantang untuk aplikasi pemrosesan bahasa alami (NLP). Terutama ketika terdiri dari beberapa klausa, kata benda kompleks atau frasa kata kerja, klausa relatif, dan pengelompokan kurung. Sama seperti manusia, sistem NLP juga perlu berhasil melacak semua dependensi yang disajikan. Tujuan dari potongan semantik adalah untuk menemukan fragmen semantik koheren dari representasi kalimat. Fragmen ini kemudian dapat diproses secara independen dan dikombinasikan ulang sebagai representasi semantik tanpa kehilangan informasi, interpretasi, atau relevansi semantik. Arti teks yang melekat digunakan sebagai panduan untuk proses penggugusan.
Strategi potongan data teks memainkan peran kunci dalam mengoptimalkan respons dan performa RAG. Berukuran tetap dan semantik adalah dua metode penggugusan yang berbeda:
Potongan berukuran tetap. Sebagian besar strategi potongan yang digunakan dalam RAG saat ini didasarkan pada segmen teks berukuran tetap yang dikenal sebagai gugus. Potongan berukuran tetap cepat, mudah, dan efektif dengan teks yang tidak memiliki struktur semantik yang kuat seperti log dan data. Namun tidak disarankan untuk teks yang memerlukan pemahaman semantik dan konteks yang tepat. Sifat ukuran tetap jendela dapat mengakibatkan pemisahan kata, kalimat, atau paragraf yang menghambat pemahaman dan mengganggu alur informasi dan pemahaman.
Potongan semantik. Metode ini membagi teks menjadi potongan berdasarkan pemahaman semantik. Batas pembagian difokuskan pada subjek kalimat dan menggunakan sumber daya komputasi yang signifikan secara algoritma kompleks. Namun, ia memiliki keuntungan berbeda untuk mempertahankan konsistensi semantik dalam setiap gugus. Ini berguna untuk ringkasan teks, analisis sentimen, dan tugas klasifikasi dokumen.
Pemotongan semantik dengan model Tata Letak Kecerdasan Dokumen
Markdown adalah bahasa markup terstruktur dan diformat dan input populer untuk mengaktifkan penggugusan semantik di RAG (Retrieval-Augmented Generation). Anda dapat menggunakan konten Markdown dari model Tata Letak untuk memisahkan dokumen berdasarkan batas paragraf, membuat gugus tertentu untuk tabel, dan menyempurnakan strategi penggugusan Anda untuk meningkatkan kualitas respons yang dihasilkan.
Manfaat menggunakan model Tata Letak
Pemrosesan yang disederhanakan. Anda dapat mengurai berbagai jenis dokumen, seperti PDF digital dan dipindai, gambar, file office (docx, xlsx, pptx), dan HTML, hanya dengan satu panggilan API.
Skalabilitas dan kualitas AI. Model Tata Letak sangat dapat diskalakan dalam Optical Character Recognition (OCR), ekstraksi tabel, dan analisis struktur dokumen. Ini mendukung 309 bahasa cetak dan 12 bahasa tulisan tangan, lebih lanjut memastikan hasil berkualitas tinggi yang didorong oleh kemampuan AI.
Kompatibilitas model bahasa besar (LLM). Output berformat Markdown model Tata Letak ramah LLM dan memfasilitasi integrasi yang mulus ke dalam alur kerja Anda. Anda dapat mengubah tabel apa pun dalam dokumen menjadi format Markdown dan menghindari upaya ekstensif mengurai dokumen untuk pemahaman LLM yang lebih besar.
Gambar teks diproses dengan Document Intelligence Studio dan output ke MarkDown menggunakan model Tata Letak

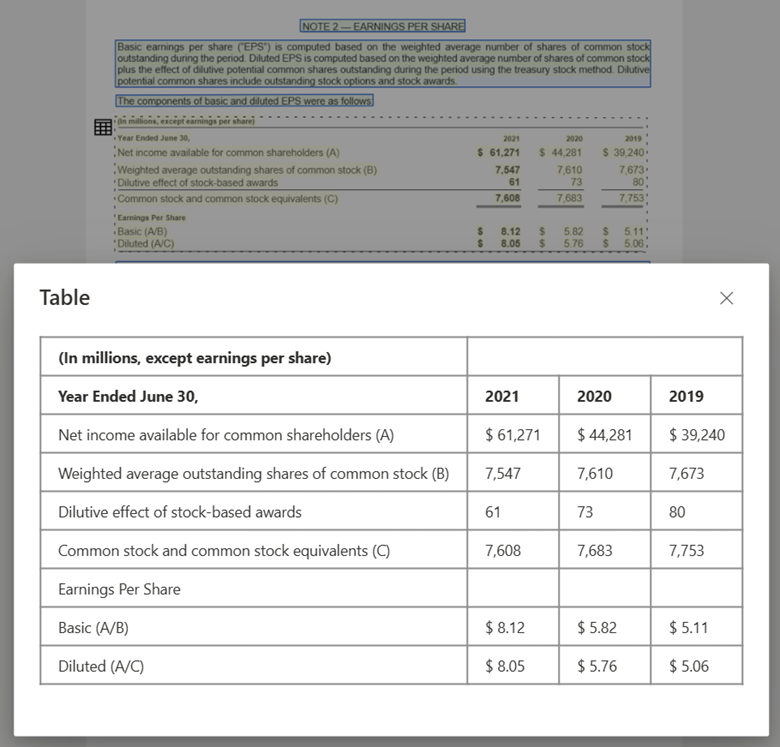
Gambar tabel diproses dengan Document Intelligence Studio menggunakan model Tata Letak
Memulai
Model Tata Letak Kecerdasan Dokumen 2024-02-29-preview dan 2023-10-31-preview mendukung opsi pengembangan berikut:
Studio Kecerdasan Dokumen.
.NET • Java • JavaScript • Pustaka klien bahasa pemrograman Python (SDK).
Siap untuk memulai?
Studio Kecerdasan Dokumen
Anda dapat mengikuti mulai cepat Document Intelligence Studio untuk memulai. Selanjutnya, Anda dapat mengintegrasikan fitur Kecerdasan Dokumen dengan aplikasi Anda sendiri menggunakan kode sampel yang disediakan.
Mulailah dengan model Tata Letak. Anda perlu memilih opsi Analisis berikut untuk menggunakan RAG di studio:
**Required**- Jalankan rentang analisis → Dokumen saat ini.
- Rentang halaman → Semua halaman.
- Gaya format output → Markdown.
**Optional**- Anda juga dapat memilih parameter deteksi opsional yang relevan.
Pilih Simpan.

Pilih tombol Jalankan analisis untuk melihat output.

SDK atau REST API
Anda dapat mengikuti mulai cepat Kecerdasan Dokumen untuk SDK bahasa pemrograman atau REST API pilihan Anda. Gunakan model Tata Letak untuk mengekstrak konten dan struktur dari dokumen Anda.
Anda juga dapat memeriksa repositori GitHub untuk sampel kode dan tips untuk menganalisis dokumen dalam format output markdown.
Membangun obrolan dokumen dengan potongan semantik
Azure OpenAI pada data Memungkinkan Anda menjalankan obrolan yang didukung di dokumen Anda. Azure OpenAI pada data Anda menerapkan model Tata Letak Kecerdasan Dokumen untuk mengekstrak dan mengurai data dokumen dengan memotong teks panjang berdasarkan tabel dan paragraf. Anda juga dapat menyesuaikan strategi penggugusan menggunakan skrip sampel Azure OpenAI yang terletak di repositori GitHub kami.
Azure AI Document Intelligence sekarang terintegrasi dengan LangChain sebagai salah satu pemuat dokumennya. Anda dapat menggunakannya untuk memuat data dan output dengan mudah ke format Markdown. Untuk informasi selengkapnya, lihat kode sampel kami yang memperlihatkan demo sederhana untuk pola RAG dengan Azure AI Document Intelligence sebagai pemuat dokumen dan Azure Search sebagai retriever di LangChain.
Sampel obrolan dengan kode akselerator solusi data Anda menunjukkan sampel pola RAG garis besar end-to-end. Ini menggunakan Azure AI Search sebagai retriever dan Azure AI Document Intelligence untuk pemuatan dokumen dan pemotongan semantik.
Gunakan huruf besar
Jika Anda mencari bagian tertentu dalam dokumen, Anda dapat menggunakan potongan semantik untuk membagi dokumen menjadi potongan yang lebih kecil berdasarkan header bagian yang membantu Anda menemukan bagian yang Anda cari dengan cepat dan mudah:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Langkah berikutnya
Pelajari selengkapnya tentang Kecerdasan Dokumen Azure AI.
Pelajari cara memproses formulir dan dokumen Anda sendiri dengan Studio Kecerdasan Dokumen.
Selesaikan mulai cepat Kecerdasan Dokumen dan mulai membuat aplikasi pemrosesan dokumen dalam bahasa pengembangan pilihan Anda.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk