Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Konten ini berlaku untuk:![]() v4.0 (GA) | Versi sebelumnya:
v4.0 (GA) | Versi sebelumnya:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
Konten ini berlaku untuk:![]() v2.1 | Versi terbaru:
v2.1 | Versi terbaru:![]() v4.0 (GA)
v4.0 (GA)
Model Dokumen Identitas Kecerdasan Dokumen (ID) menggabungkan Pengenalan Karakter Optik (OCR) dengan model pembelajaran mendalam untuk menganalisis dan mengekstrak informasi utama dari dokumen identitas. API menganalisis dokumen identitas (termasuk yang berikut) dan mengembalikan representasi data JSON terstruktur.
| Wilayah | Jenis dokumen |
|---|---|
| Di seluruh dunia | Buku Paspor, Kartu Paspor |
| Amerika Serikat | SIM, Kartu Identifikasi, Izin Tinggal (Kartu Hijau), Kartu Jaminan Sosial, KTP |
| Eropa | SIM, Kartu Identifikasi, Izin Tinggal |
| India | SIM, Kartu PAN, Kartu Aadhaar |
| Kanada | SIM, Kartu Identifikasi, Izin Tinggal (Kartu Maple) |
| Australia | SIM, Kartu Foto, ID Key-pass (termasuk versi digital) |
Kecerdasan Dokumen dapat menganalisis dan mengekstrak informasi dari dokumen identifikasi (ID) yang dikeluarkan pemerintah menggunakan model ID bawaannya. Ini menggabungkan kemampuan Optical Character Recognition (OCR) kami yang canggih dengan kemampuan pengenalan ID untuk mengekstrak informasi utama dari Paspor di Seluruh Dunia dan SIM AS (semua 50 negara bagian dan D.C.). ID API mengekstrak informasi utama dari dokumen identitas ini, seperti nama depan, nama keluarga, tanggal lahir, nomor dokumen, dan banyak lagi. API ini tersedia di Kecerdasan Dokumen v2.1 sebagai layanan cloud.
Pemrosesan dokumen identitas
Pemrosesan dokumen identitas melibatkan ekstraksi data dari dokumen identitas baik secara manual atau dengan menggunakan teknologi berbasis OCR. Pemrosesan dokumen ID adalah langkah penting dalam operasi bisnis apa pun yang memerlukan bukti identitas. Contohnya termasuk verifikasi pelanggan di bank dan lembaga keuangan lainnya, aplikasi hipotek, kunjungan medis, pemrosesan klaim, industri perhotelan, dan banyak lagi. Individu memberikan beberapa bukti identitas mereka melalui SIM, paspor, dan dokumen serupa lainnya sehingga bisnis dapat memverifikasinya secara efisien sebelum memberikan layanan dan manfaat.
Contoh SIM A.S. yang diproses dengan Document Intelligence Studio
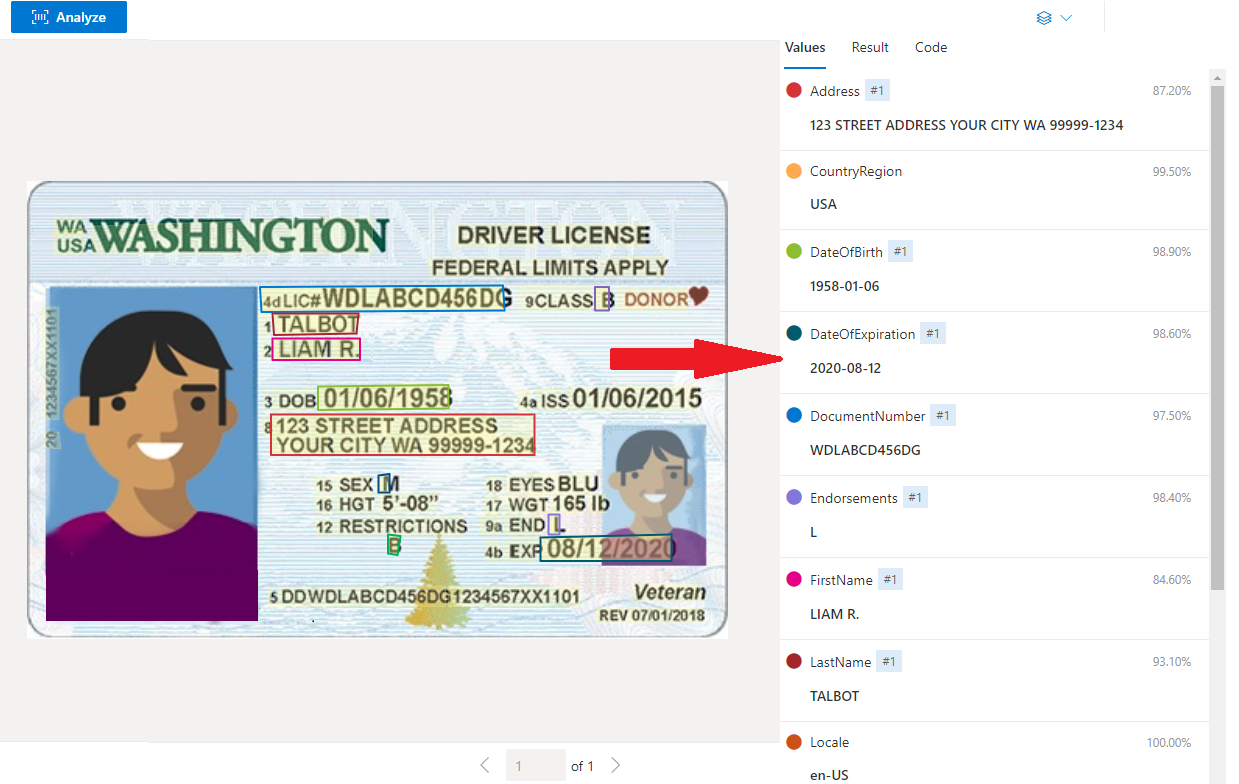
Ekstraksi data
Layanan ID bawaan mengekstrak nilai-nilai utama dari paspor di seluruh dunia dan SIM AS serta mengembalikannya dalam respons JSON terstruktur yang terkelola.
Contoh SIM
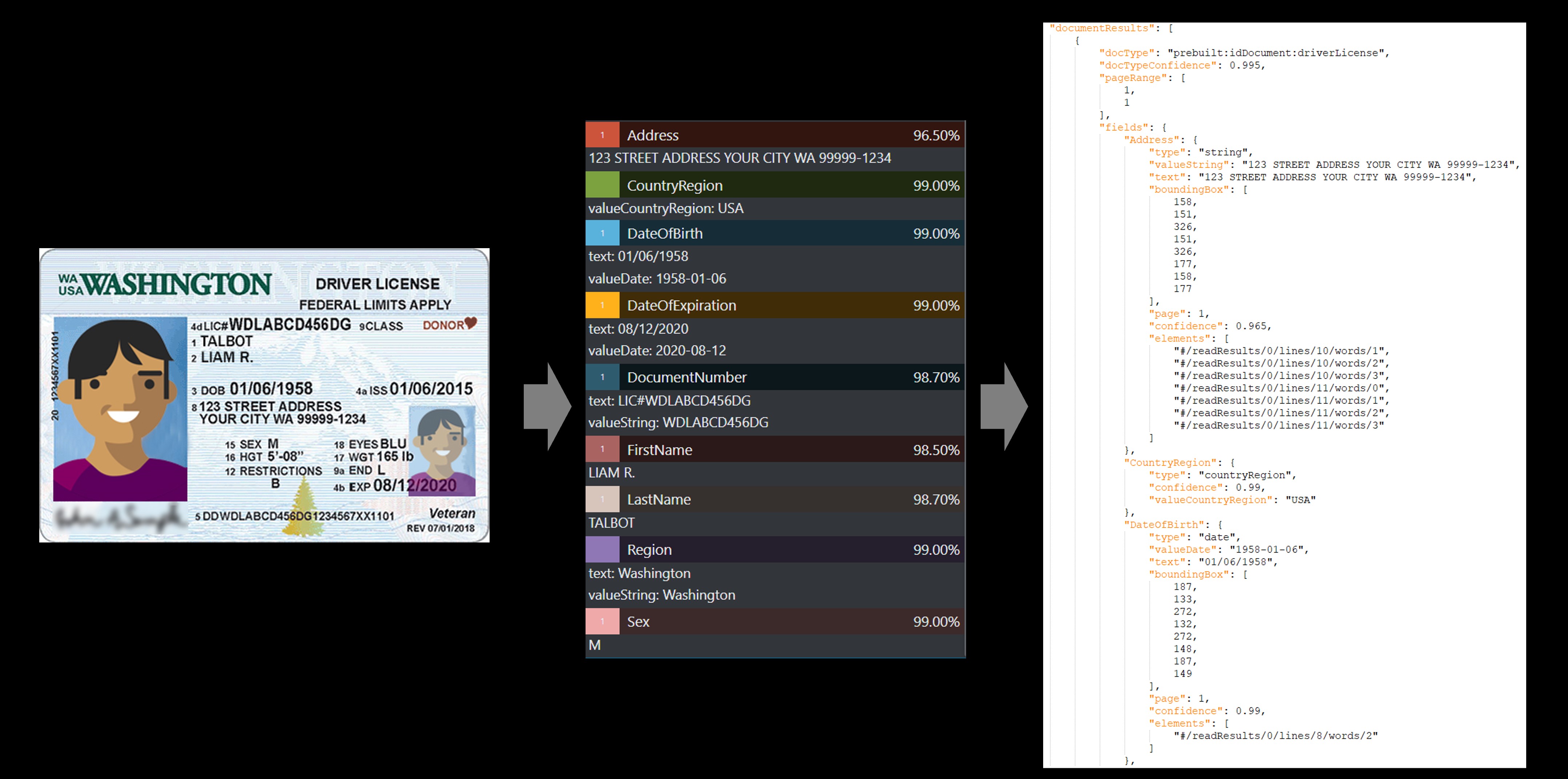
Contoh paspor
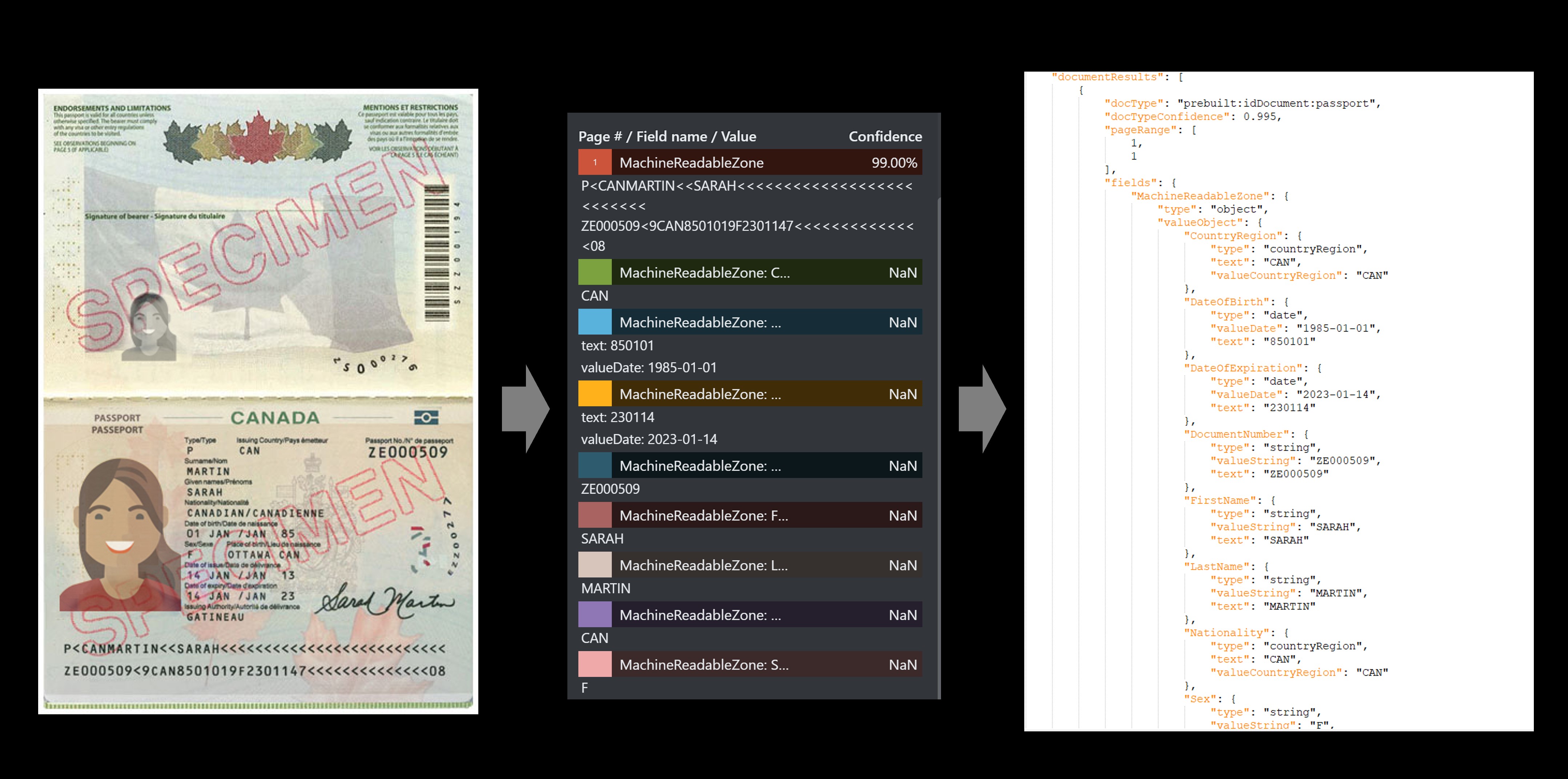
Opsi pengembangan
Kecerdasan Dokumen v4.0: 2024-11-30 (GA) mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Model dokumen ID | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Kecerdasan Dokumen v3.1 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Model dokumen ID | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Kecerdasan Dokumen v3.0 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Model dokumen ID | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Kecerdasan Dokumen v2.1 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber |
|---|---|
| Model dokumen ID | • Alat pelabelan Kecerdasan Dokumen• REST API • SDK pustaka klien• Kontainer Docker Kecerdasan Dokumen |
Persyaratan input
Format file yang didukung:
| Model | Gambar: JPEG/JPG, , BMPPNG, TIFF, ,HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Read | ✔ | ✔ | ✔ |
| Tata letak | ✔ | ✔ | ✔ |
| Dokumen Umum | ✔ | ✔ | |
| Bawaan | ✔ | ✔ | |
| Ekstraksi kustom | ✔ | ✔ | |
| Klasifikasi kustom | ✔ | ✔ | ✔ |
Untuk hasil terbaik, berikan satu foto yang jelas atau pemindaian berkualitas tinggi per dokumen.
Untuk PDF dan TIFF, hingga 2.000 halaman dapat diproses (dengan langganan tingkat gratis, hanya dua halaman pertama yang diproses).
Ukuran file untuk menganalisis dokumen adalah 500 MB untuk tingkat berbayar (S0) dan
4MB secara gratis (F0).Dimensi gambar harus antara 50 piksel x 50 piksel dan 10.000 piksel x 10.000 piksel.
Jika PDF Anda dikunci dengan kata sandi, Anda harus menghapus kunci sebelum pengiriman.
Tinggi minimum teks yang akan diekstrak adalah 12 piksel untuk gambar piksel 1024 x 768. Dimensi ini sesuai dengan tentang
8teks titik pada 150 titik per inci (DPI).Untuk pelatihan model kustom, jumlah maksimum halaman untuk data pelatihan adalah 500 untuk model template kustom dan 50.000 untuk model neural kustom.
Untuk pelatihan model ekstraksi kustom, ukuran total data pelatihan adalah 50 MB untuk model templat dan
1GB untuk model neural.Untuk pelatihan model klasifikasi kustom, ukuran total data pelatihan adalah
1GB dengan maksimum 10.000 halaman. Untuk 2024-11-30 (GA), ukuran total data pelatihan adalah2GB dengan maksimum 10.000 halaman.
Format file yang didukung: JPEG, PNG, PDF, dan TIFF.
Jumlah halaman yang didukung untuk file PDF dan TIFF: hingga 2.000 halaman atau hanya dua halaman pertama untuk pelanggan tingkat gratis.
Ukuran file yang didukung: kurang dari 50 MB TOTAL; piksel minimum: 50 x 50 px; piksel maksimum 10.000 x 10.000 px.
Ekstraksi data model dokumen ID
Ekstrak data, termasuk nama, tanggal lahir, dan tanggal kedaluwarsa, dari dokumen ID. Anda membutuhkan sumber daya berikut:
Langganan Azure—Anda dapat membuatnya secara gratis.
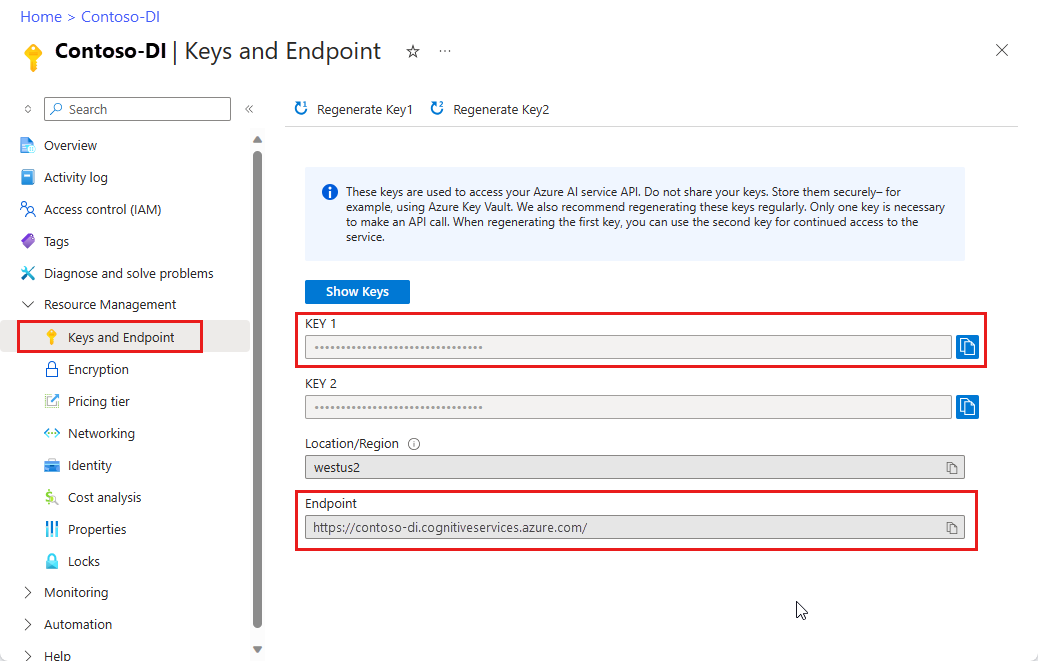
Instans Kecerdasan Dokumen di portal Azure. Anda dapat menggunakan tingkat harga gratis (
F0) untuk mencoba layanan. Setelah sumber daya Anda disebarkan, pilih Buka sumber daya untuk mendapatkan kunci dan titik akhir Anda.
Catatan
Document Intelligence Studio tersedia dengan API v3.1 dan v3.0 dan versi yang lebih baru.
Pada beranda Studio Kecerdasan Dokumen, pilih Dokumen identitas.
Anda dapat menganalisis faktur sampel atau mengunggah file Anda sendiri.
Pilih tombol Jalankan analisis dan, jika perlu, konfigurasikan opsi Analisis:

Coba Studio Kecerdasan Dokumen.
Alat Pelabelan Sampel Kecerdasan Dokumen
Navigasikan ke Alat Sampel Kecerdasan Dokumen.
Pada beranda alat sampel, pilih gunakan model bawaan untuk mendapatkan petak data .
Pilih Jenis Formulir untuk dianalisis dari menu dropdown.
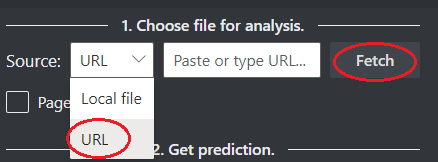
Pilih URL untuk {i>file
Pada bidang Sumber, pilih URL dari menu drop down, tempel URL yang dipilih, dan pilih tombol Ambil.
Di bidang titik akhir layanan Inteligensi Dokumen, tempelkan titik akhir yang Anda peroleh dengan langganan Kecerdasan Dokumen Anda.
Di bidang kunci, tempelkan kunci yang Anda peroleh dari sumber daya Kecerdasan Dokumen Anda.
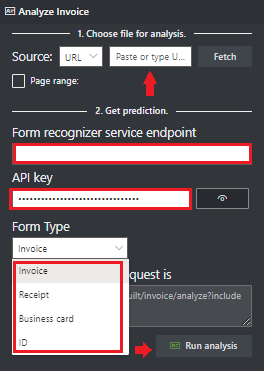
Pilih Jalankan analisis. Alat Pelabelan Sampel Kecerdasan Dokumen memanggil API Analisis Bawaan dan menganalisis dokumen.
Lihat hasilnya - lihat pasangan kunci-nilai yang diekstrak, item baris, teks yang disorot diekstrak, dan tabel terdeteksi.
Unduh {i>file output
- Simpul "readResults" berisi setiap baris teks dengan penempatan kotak pembatasnya masing-masing pada halaman.
- Simpul "selectionMarks" memperlihatkan setiap tanda pilihan (kotak centang, tanda radio) dan apakah statusnya dipilih atau tidak dipilih.
- Bagian "pageResults" mencakup tabel yang diekstrak. Untuk setiap tabel, Kecerdasan Dokumen mengekstrak indeks teks, baris, dan kolom, rentang baris dan kolom, kotak pembatas, dan lainnya.
- Bidang "documentResults" berisi informasi pasangan kunci/nilai dan informasi item baris untuk bagian dokumen yang paling relevan.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Catatan
Alat Pelabelan Sampel tidak mendukung format file BMP. Pembatasan ini adalah batasan alat bukan Document Intelligence Service.
Ekstraksi bidang
Untuk bidang ekstraksi dokumen yang didukung, lihathalaman skema model dokumen ID di repositori sampel GitHub kami.
Jenis dokumen yang didukung
Model dokumen ID saat ini mendukung SIM AS dan halaman biografis dari paspor internasional (tidak termasuk visa dan dokumen perjalanan lainnya).
Bidang diekstrak
| Nama | Tipe | Deskripsi | Nilai |
|---|---|---|---|
| Negara | negara | Kode negara yang sesuai dengan standar ISO 3166 | "AS" |
| DateOfBirth | date | Tanggal Lahir dalam format YYYY-MM-DD | "1980-01-01" |
| DateOfExpiration | date | Tanggal kedaluwarsa dalam format YYYY-MM-DD | "2019-05-05" |
| DocumentNumber | string | Nomor paspor yang relevan, nomor SIM, dll. | "340020013" |
| FirstName | string | Nama pemberian diekstrak dan inisial tengah jika berlaku | "JENNIFER" |
| LastName | string | Nama keluarga yang diekstrak | "BROOKS" |
| Kebangsaan | negara | Kode negara yang sesuai dengan standar ISO 3166 | "AS" |
| Jenis Kelamin | gender | Kemungkinan nilai yang diekstrak termasuk "M" "F" "X" | "F" |
| MachineReadableZone | object | Paspor MRZ yang diekstrak termasuk dua baris masing-masing 44 karakter |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | string | Jenis dokumen, misalnya, Paspor, SIM | "passport" |
| Alamat | string | Alamat yang diekstrak (hanya SIM) | "123 ALAMAT JALAN KOTA ANDA WA 99999-1234" |
| Wilayah | string | Wilayah yang diekstrak, negara bagian, provinsi, dll. (Hanya SIM) | "Washington" |
Panduan migrasi
- Ikuti panduan migrasi Kecerdasan Dokumen v3.1 kami untuk mempelajari cara menggunakan versi v3.0 di aplikasi dan alur kerja Anda.