Model faktur Kecerdasan Dokumen
Penting
- Rilis pratinjau publik Kecerdasan Dokumen menyediakan akses awal ke fitur yang sedang dalam pengembangan aktif. Fitur, pendekatan, dan proses dapat berubah, sebelum Ketersediaan Umum (GA), berdasarkan umpan balik pengguna.
- Versi pratinjau publik pustaka klien Kecerdasan Dokumen default ke REST API versi 2024-07-31-preview.
- Pratinjau publik versi 2024-07-31-preview saat ini hanya tersedia di wilayah Azure berikut. Perhatikan bahwa model generatif kustom (ekstraksi bidang dokumen) di AI Studio hanya tersedia di wilayah US Tengah Utara:
- US Timur
- US Barat2
- Eropa Barat
- US Tengah Utara
Konten ini berlaku untuk: ![]() v4.0 (pratinjau) | Versi sebelumnya:
v4.0 (pratinjau) | Versi sebelumnya: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Konten ini berlaku untuk: ![]() v3.1 (GA) | Versi terbaru:
v3.1 (GA) | Versi terbaru:![]() v4.0 (pratinjau) | Versi sebelumnya:
v4.0 (pratinjau) | Versi sebelumnya: ![]() v3.0
v3.0![]() v2.1
v2.1
Konten ini berlaku untuk: ![]() v3.0 (GA) | Versi terbaru:
v3.0 (GA) | Versi terbaru: ![]() v4.0 (pratinjau)
v4.0 (pratinjau) ![]() v3.1 | Versi sebelumnya:
v3.1 | Versi sebelumnya: ![]() v2.1
v2.1
Konten ini berlaku untuk: ![]() v2.1 | Versi terbaru:
v2.1 | Versi terbaru: ![]() v4.0 (pratinjau)
v4.0 (pratinjau)
Model faktur Kecerdasan Dokumen menggunakan kemampuan Pengenalan Karakter Optik (OCR) yang kuat untuk menganalisis dan mengekstrak bidang kunci dan item baris dari faktur penjualan, tagihan utilitas, dan pesanan pembelian. Dokumen dapat memiliki berbagai format dan kualitas, termasuk gambar yang diambil dengan ponsel, dokumen yang dipindai, dan PDF digital. API menganalisis teks faktur; mengekstrak informasi penting seperti nama pelanggan, alamat penagihan, tanggal jatuh tempo, dan jumlah yang jatuh tempo; dan menghasilkan representasi data JSON terstruktur. Model saat ini mendukung faktur dalam 27 bahasa.
Jenis dokumen yang didukung:
- Faktur
- Tagihan utilitas
- Pesanan penjualan
- Pesanan pembelian
Pemrosesan faktur otomatis
Pemrosesan faktur otomatis adalah proses mengekstrak bidang kunci accounts payable dari dokumen akun penagihan. Data yang diekstrak mencakup item baris dari faktur yang terintegrasi dengan alur kerja utang akun (AP) Anda untuk ulasan dan pembayaran. Secara historis, proses utang akun dilakukan secara manual dan, karenanya, sangat memakan waktu. Ekstraksi data kunci yang akurat dari faktur biasanya merupakan langkah pertama dan salah satu langkah paling penting dalam proses otomatisasi faktur.
Contoh faktur yang diproses dengan Document Intelligence Studio:

Contoh faktur yang diproses dengan alat Pelabelan Sampel Kecerdasan Dokumen:
Opsi pengembangan
Kecerdasan Dokumen v4.0 (pratinjau 2024-07-31) mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Model faktur | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
Faktur Bawaan |
Kecerdasan Dokumen v3.1 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Model faktur | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
Faktur Bawaan |
Kecerdasan Dokumen v3.0 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Model faktur | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
Faktur Bawaan |
Kecerdasan Dokumen v2.1 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber |
|---|---|
| Model faktur | • Alat pelabelan Kecerdasan Dokumen• REST API • SDK pustaka klien• Kontainer Docker Kecerdasan Dokumen |
Persyaratan input
Format file yang didukung:
Model PDF Gambar: JPEG/JPG, ,BMPPNG,TIFF, ,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLRead ✔ ✔ ✔ Tata letak ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Dokumen Umum ✔ ✔ Bawaan ✔ ✔ Ekstraksi kustom ✔ ✔ Klasifikasi kustom ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Untuk hasil terbaik, berikan satu foto yang jelas atau pemindaian berkualitas tinggi per dokumen.
Untuk PDF dan TIFF, hingga 2.000 halaman dapat diproses (dengan langganan tingkat gratis, hanya dua halaman pertama yang diproses).
Ukuran file untuk menganalisis dokumen adalah 500 MB untuk tingkat berbayar (S0) dan
4MB secara gratis (F0).Dimensi gambar harus antara 50 piksel x 50 piksel dan 10.000 piksel x 10.000 piksel.
Jika PDF Anda dikunci dengan kata sandi, Anda harus menghapus kunci sebelum pengiriman.
Tinggi minimum teks yang akan diekstrak adalah 12 piksel untuk gambar piksel 1024 x 768. Dimensi ini sesuai dengan tentang
8teks titik pada 150 titik per inci (DPI).Untuk pelatihan model kustom, jumlah maksimum halaman untuk data pelatihan adalah 500 untuk model template kustom dan 50.000 untuk model neural kustom.
Untuk pelatihan model ekstraksi kustom, ukuran total data pelatihan adalah 50 MB untuk model templat dan
1GB untuk model neural.Untuk pelatihan model klasifikasi kustom, ukuran total data pelatihan adalah
1GB dengan maksimum 10.000 halaman. Untuk pratinjau 2024-07-31 dan yang lebih baru, ukuran total data pelatihan adalah2GB dengan maksimum 10.000 halaman.
- Format file yang didukung: JPEG, PNG, PDF, dan TIFF.
- PDF dan TIFF yang didukung, hingga 2.000 halaman diproses. Untuk pelanggan level gratis, hanya dua halaman pertama yang diproses.
- Ukuran file yang didukung harus kurang dari 50 MB dan dimensi minimal 50 x 50 piksel dan paling banyak 10.000 x 10.000 piksel.
Ekstraksi data model faktur
Lihat bagaimana data, termasuk informasi pelanggan, detail vendor, dan item baris, diekstrak dari faktur. Anda membutuhkan sumber daya berikut:
Langganan Azure—Anda dapat membuatnya secara gratis.
Instans Kecerdasan Dokumen di portal Azure. Anda dapat menggunakan tingkat harga gratis (
F0) untuk mencoba layanan. Setelah sumber daya Anda disebarkan, pilih Buka sumber daya untuk mendapatkan kunci dan titik akhir Anda.

Alat Pelabelan Sampel Kecerdasan Dokumen
Navigasikan ke Alat Sampel Kecerdasan Dokumen.
Pada beranda alat sampel, pilih gunakan model bawaan untuk mendapatkan petak data .
Pilih Jenis Formulir untuk dianalisis dari menu dropdown.
Pilih URL untuk {i>file
Pada bidang Sumber, pilih URL dari menu drop down, tempel URL yang dipilih, dan pilih tombol Ambil.
Di bidang titik akhir layanan Inteligensi Dokumen, tempelkan titik akhir yang Anda peroleh dengan langganan Kecerdasan Dokumen Anda.
Di bidang kunci, tempelkan kunci yang Anda peroleh dari sumber daya Kecerdasan Dokumen Anda.
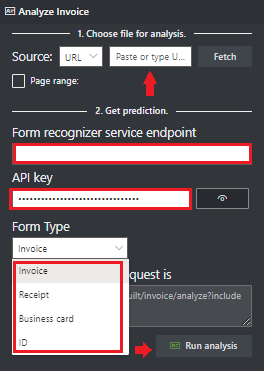
Pilih Jalankan analisis. Alat Pelabelan Sampel Kecerdasan Dokumen memanggil API Analisis Bawaan dan menganalisis dokumen.
Lihat hasilnya - lihat pasangan kunci-nilai yang diekstrak, item baris, teks yang disorot diekstrak, dan tabel terdeteksi.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Catatan
Alat pelabelan sampel tidak mendukung format file BMP. Ini adalah batasan alat bukan Document Intelligence Service.
Bahasa dan lokal yang didukung
Untuk daftar lengkap bahasa yang didukung, lihat halaman dukungan bahasa model bawaan kami.
Ekstraksi lapangan
Untuk bidang ekstraksi dokumen yang didukung, lihat halaman skema model faktur di repositori sampel GitHub kami.
Pasangan kunci-nilai faktur dan item baris yang diekstrak berada di bagian
documentResultsoutput JSON.
Pasangan kunci-nilai
Faktur bawaan 2022-06-30 dan rilis yang lebih baru mendukung pengembalian opsional pasangan kunci-nilai. Secara default, pengembalian pasangan kunci-nilai dinonaktifkan. Pasangan kunci nilai adalah rentang tertentu dalam dokumen yang mengidentifikasi label atau kunci dan respons atau nilai terkaitnya. Dalam faktur, pasangan ini bisa menjadi label dan nilai yang dimasukkan pengguna untuk bidang atau nomor telepon tersebut. Model AI dilatih untuk mengekstrak kunci dan nilai yang dapat diidentifikasi berdasarkan berbagai jenis, format, dan struktur dokumen.
Kunci juga dapat ada dalam isolasi ketika model mendeteksi bahwa ada kunci, tanpa nilai terkait atau saat memproses bidang opsional. Misalnya, bidang nama tengah dapat dibiarkan kosong pada formulir dalam beberapa instans. Pasangan kunci-nilai selalu mencakup teks yang terkandung dalam dokumen. Untuk dokumen di mana nilai yang sama dijelaskan dengan cara yang berbeda, misalnya, pelanggan/pengguna, kunci terkait adalah pelanggan atau pengguna (berdasarkan konteks).
Bidang diekstrak
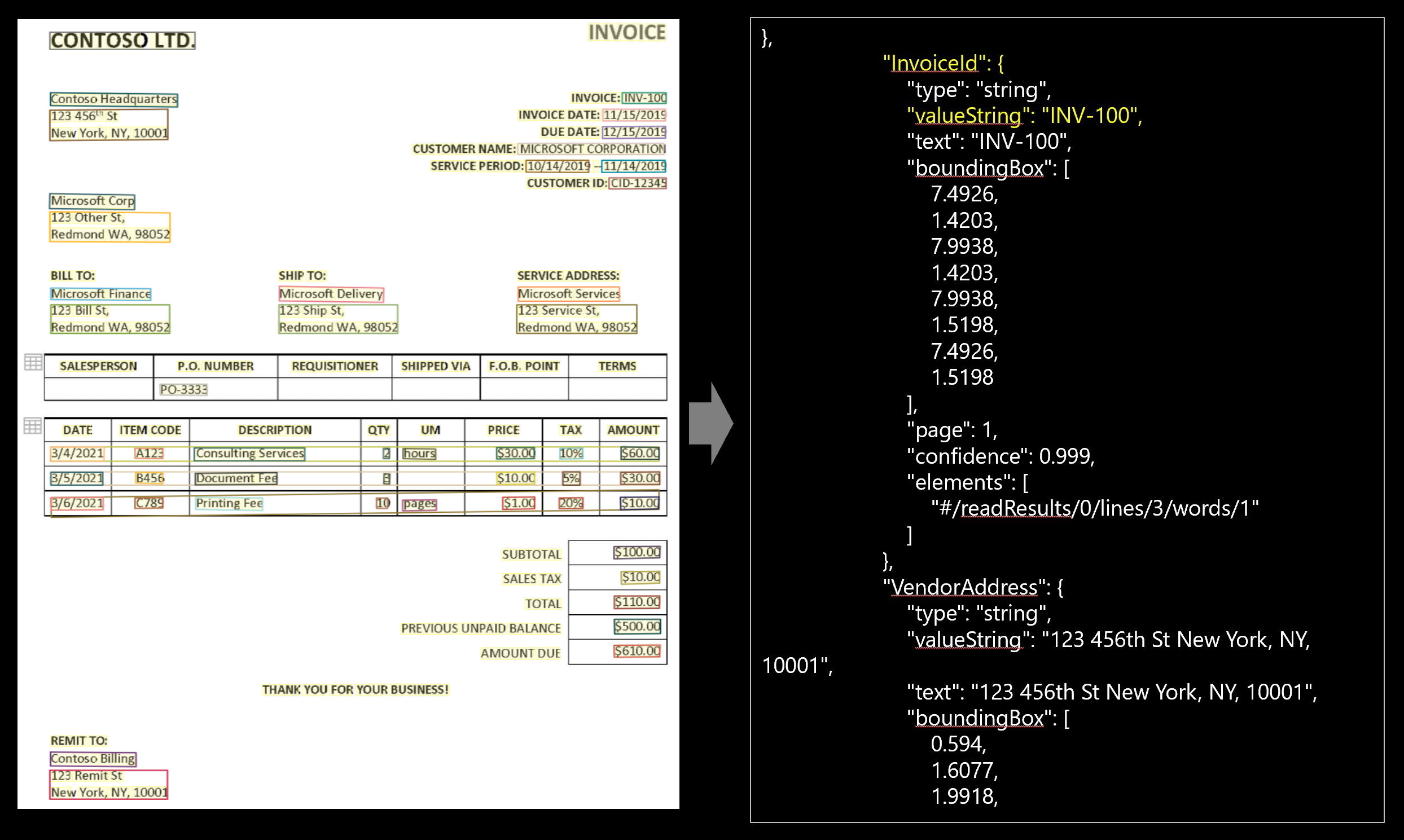
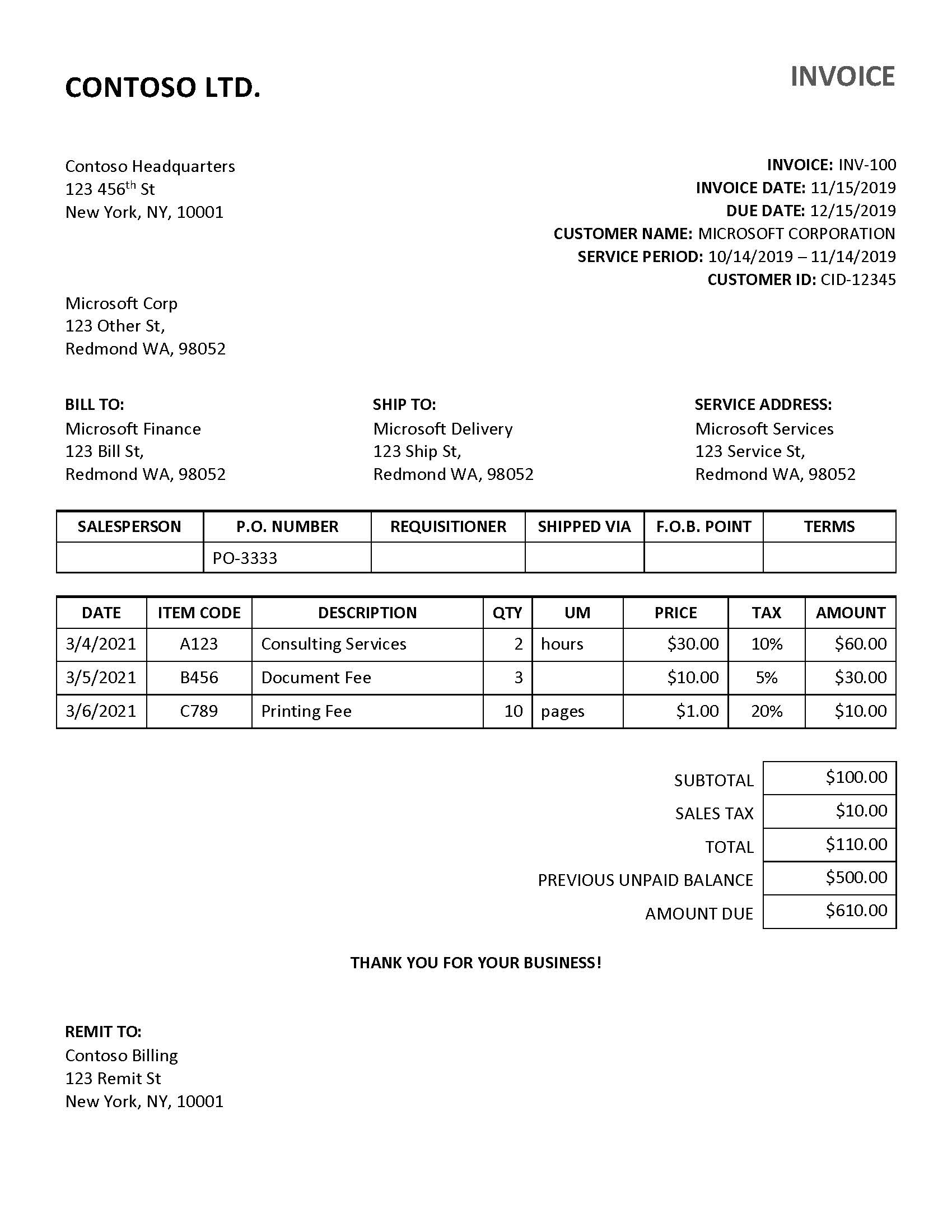
Layanan Faktur mengekstrak teks, tabel, dan 26 bidang faktur. Berikut ini adalah bidang yang diekstrak dari faktur dalam respons output JSON (output berikut menggunakan faktur sampel ini).
{kind=link}
| Nama | Tipe | Deskripsi | SMS | Nilai (output standar) |
|---|---|---|---|---|
| CustomerName | string | Pelanggan sedang ditagih | Microsoft Corp | |
| ID Pelanggan | string | ID Referensi untuk pelanggan | CID-12345 | |
| PurchaseOrder | string | Nomor referensi pesanan pembelian | PO-3333 | |
| InvoiceId | string | ID faktur khusus ini (sering kali "Nomor Faktur") | INV-100 | |
| InvoiceDate | date | Tanggal faktur dikeluarkan | 11/15/2019 | 2019-11-15 |
| DueDate | date | Tanggal jatuh tempo pembayaran untuk faktur ini | 12/15/2019 | 2019-12-15 |
| VendorName | string | Vendor yang membuat faktur | CONTOSO | |
| VendorAddress | string | Alamat surat untuk Vendor | 123 456th St New York, NY, 10001 | |
| VendorAddressRecipient | string | Nama yang terkait dengan VendorAddress | Kantor Pusat Contoso | |
| CustomerAddress | string | Alamat surat untuk Pelanggan | 123 Other Street, Redmond, Washington, 98052 | |
| CustomerAddressRecipient | string | Nama yang terkait dengan CustomerAddress | Microsoft Corp | |
| BillingAddress | string | Alamat penagihan eksplisit untuk pelanggan | 123 Bill Street, Redmond, Washington, 98052 | |
| BillingAddressRecipient | string | Nama yang terkait dengan BillingAddress | Layanan Microsoft | |
| ShippingAddress | string | Alamat pengiriman eksplisit untuk pelanggan | 123 Ship Street, Redmond, Washington, 98052 | |
| ShippingAddressRecipient | string | Nama yang terkait dengan ShippingAddress | Microsoft Delivery | |
| SubTotal | number | Bidang subtotal yang diidentifikasi pada faktur ini | $100.00 | 100 |
| TotalTax | number | Bidang total pajak yang diidentifikasi pada faktur ini | $10.00 | 10 |
| InvoiceTotal | number | Total biaya baru yang terkait dengan faktur ini | $110.00 | 110 |
| AmountDue | number | Total Jumlah Jatuh Tempo untuk vendor | $610.00 | 610 |
| ServiceAddress | string | Alamat layanan eksplisit atau alamat properti untuk pelanggan | 123 Service Street, Redmond, Washington, 98052 | |
| ServiceAddressRecipient | string | Nama yang terkait dengan ServiceAddress | Layanan Microsoft | |
| RemittanceAddress | string | Pengiriman uang atau alamat pembayaran eksplisit untuk pelanggan | 123 Remit St New York, NY, 10001 | |
| ServiceAddressRecipient | string | Nama yang terkait dengan RemittanceAddress | Penagihan Contoso | |
| ServiceStartDate | date | Tanggal pertama periode layanan (misalnya, periode layanan tagihan utilitas) | 10/14/2019 | 2019-10-14 |
| ServiceEndDate | date | Tanggal akhir periode layanan (misalnya, periode layanan tagihan utilitas) | 11/14/2019 | 2019-11-14 |
| PreviousUnpaidBalance | number | Saldo eksplisit yang sebelumnya belum dibayar | $500.00 | 500 |
Berikut ini adalah item baris yang diekstrak dari faktur dalam respons output JSON dan menggunakan faktur sampel ini:
| Nama | Tipe | Deskripsi | Teks (item baris #1) | Nilai (output standar) |
|---|---|---|---|---|
| Item | string | Baris teks string lengkap dari item baris | 3/4/2021 A123 Layanan Konsultasi 2 jam $30.00 10% $60.00 | |
| Jumlah | number | Jumlah item baris | $60.00 | 100 |
| Deskripsi | string | Deskripsi teks untuk item baris faktur | Layanan konsultasi | Layanan konsultasi |
| Quantity | number | Kuantitas untuk item baris faktur ini | 2 | 2 |
| UnitPrice | number | Harga bersih atau kotor (tergantung pada pengaturan faktur kotor faktur) dari satu unit item ini | $30.00 | 30 |
| ProductCode | string | Kode produk, nomor produk, atau SKU yang terkait dengan item baris tertentu | A123 | |
| Unit | string | Unit item baris, misalnya, kg, lb, dll. | hours | |
| Date | date | Tanggal saat setiap item baris dikirim. Sering kali berupa tanggal item baris dikirim | 3/4/2021 | 2021-03-04 |
| Pajak | number | Pajak yang terkait dengan setiap item baris. Kemungkinan nilai termasuk jumlah pajak, % pajak, dan pajak Y/N | 10% |
Berikut ini adalah bidang kompleks yang diekstrak dari faktur dalam respons output JSON:
TaxDetails
Detail pajak menentukan pajak tertentu yang diterapkan pada total faktur.
| Nama | Tipe | Deskripsi | Teks (item baris #1) | Nilai (output standar) |
|---|---|---|---|---|
| Item | string | Baris teks string penuh dari item pajak | V.A.T. 15% $60,00 | |
| Jumlah | number | Jumlah pajak item pajak | 60,00 | 60 |
| Tarif | string | Tarif pajak item pajak | 15% |
PaymentDetails
Cantumkan semua opsi pembayaran yang terdeteksi terdeteksi di bidang .
| Nama | Tipe | Deskripsi | Teks (item baris #1) | Nilai (output standar) |
|---|---|---|---|---|
IBAN |
string | Nomor Rekening Bank Internal | GB33BUKB20201555555555 | |
SWIFT |
string | Kode SWIFT | BUKBGB22 | |
| BankAccountNumber | string | Nomor rekening bank, pengidentifikasi unik untuk rekening bank | 123456 | |
| BPayBillerCode | string | Kode Penagih B-Pay Australia | 12345 | |
| BPayReference | string | Kode Referensi B-Pay Australia | 98765432100 |
Output JSON
Output JSON memiliki tiga bagian:
"readResults"simpul berisi semua teks dan tanda pilihan yang dikenali. Teks diatur melalui halaman, lalu menurut baris, lalu dengan kata-kata individual."pageResults"node berisi tabel dan sel yang diekstrak dengan kotak pembatas, keyakinan, dan referensi ke baris dan kata di readResults.- Simpul
"documentResults"berisi nilai spesifik faktur dan item baris yang ditemukan oleh model. Di sinilah untuk menemukan semua bidang dari faktur seperti ID faktur, pengiriman ke, tagihan ke, pelanggan, total, item baris, dan banyak lagi.
Panduan migrasi
- Ikuti panduan migrasi Kecerdasan Dokumen v3.1 kami untuk mempelajari cara menggunakan versi v3.0 di aplikasi dan alur kerja Anda.