Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Model tata letak Kecerdasan Dokumen adalah API analisis dokumen berbasis pembelajaran mesin tingkat lanjut yang tersedia di cloud Kecerdasan Dokumen. Ini memungkinkan Anda untuk mengambil dokumen dalam berbagai format dan mengembalikan representasi data terstruktur dari dokumen. API menggabungkan versi yang disempurnakan dari kemampuan Pengenalan Karakter Optik (OCR) kami yang canggih dengan model pembelajaran mendalam untuk mengekstrak teks, tabel, tanda pilihan, dan struktur dokumen.
Analisis tata letak struktur dokumen
Analisis tata letak struktur dokumen adalah proses menganalisis dokumen untuk mengekstrak wilayah yang diminati dan hubungan antar-hubungannya. Tujuannya adalah untuk mengekstrak teks dan elemen struktural dari halaman untuk membangun model pemahaman semantik yang lebih baik. Ada dua jenis peran dalam tata letak dokumen:
- Peran geometris: Teks, tabel, gambar, dan tanda pilihan adalah contoh peran geometris.
- Peran logis: Judul, judul, dan footer adalah contoh peran logis teks.
Ilustrasi berikut menunjukkan komponen umum dalam gambar halaman sampel.

Opsi pengembangan
Kecerdasan Dokumen v4.0: 2024-11-30 (GA) mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Model tata letak | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
tata letak bawaan |
Bahasa yang didukung
Lihat Dukungan Bahasa—model analisis dokumen untuk daftar lengkap bahasa yang didukung.
Jenis file yang didukung
Model tata letak Kecerdasan Dokumen v4.0: 2024-11-30 (GA) mendukung format file berikut:
| Modél | Gambar: JPEG/JPG, , PNGBMP, TIFF, ,HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Tata letak | ✔ | ✔ | ✔ |
Persyaratan input
Untuk hasil terbaik, berikan satu foto yang jelas atau pemindaian berkualitas tinggi per dokumen.
Untuk PDF dan TIFF, hingga 2.000 halaman dapat diproses (dengan langganan tingkat gratis, hanya dua halaman pertama yang diproses).
Jika PDF Anda dikunci dengan kata sandi, Anda harus menghapus kunci sebelum pengiriman.
Ukuran file untuk menganalisis dokumen adalah 500 MB untuk tingkat berbayar (S0) dan
4MB secara gratis (F0).Dimensi gambar harus antara 50 piksel x 50 piksel dan 10.000 piksel x 10.000 piksel.
Tinggi minimum teks yang akan diekstrak adalah 12 piksel untuk gambar piksel 1024 x 768. Dimensi ini sesuai dengan
8teks dengan ukuran sekitar 150 titik per inci (DPI).Untuk pelatihan model kustom, jumlah maksimum halaman untuk data pelatihan adalah 500 untuk model template kustom dan 50.000 untuk model neural kustom.
Untuk pelatihan model ekstraksi kustom, ukuran total data pelatihan adalah 50 MB untuk model templat dan
1GB untuk model neural.Untuk pelatihan model klasifikasi kustom, ukuran total data pelatihan adalah
1GB dengan maksimum 10.000 halaman. Untuk2024-11-30(GA), ukuran total data pelatihan adalah2GB dengan maksimum 10.000 halaman.
Untuk informasi selengkapnya tentang penggunaan model, kuota, dan batas layanan, lihatbatas layanan.
Mulai menggunakan model Tata Letak
Lihat bagaimana data, termasuk teks, tabel, header tabel, tanda pilihan, dan informasi struktur diekstrak dari dokumen menggunakan Kecerdasan Dokumen. Anda membutuhkan sumber daya berikut:
Langganan Azure—Anda dapat membuatnya secara gratis.
Instans Kecerdasan Dokumen di portal Azure. Anda dapat menggunakan tingkat harga gratis (
F0) untuk mencoba layanan. Setelah sumber daya Anda disebarkan, pilih Buka sumber daya untuk mendapatkan kunci dan titik akhir Anda.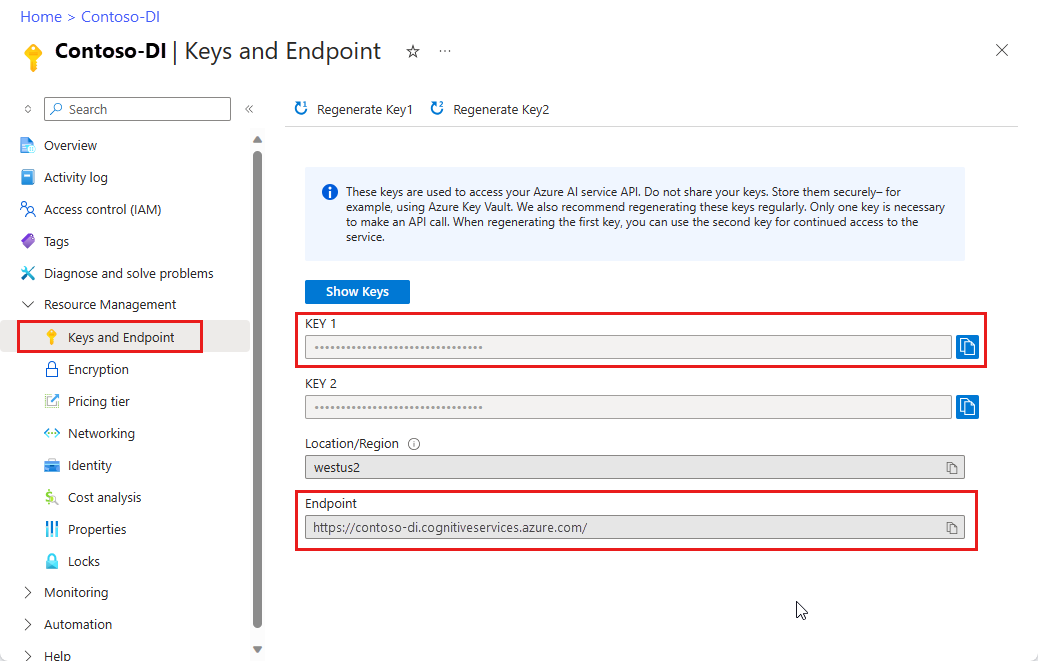
Setelah Anda mengambil kunci dan titik akhir, gunakan opsi pengembangan berikut untuk membangun dan menyebarkan aplikasi Kecerdasan Dokumen Anda:
Ekstraksi data
Model tata letak mengekstrak elemen struktural dari dokumen Anda. Untuk mengikuti adalah deskripsi elemen struktural ini dengan panduan tentang cara mengekstraknya dari input dokumen Anda:
- Halaman
- Paragraf
- Teks, baris, dan kata
- Tanda pilihan
- Tabel
- Hasil keluaran untuk markdown
- Angka
- Bagian
Jalankan analisis dokumen tata letak sampel dalam Document Intelligence Studio, lalu navigasikan ke tab hasil dan akses output JSON lengkap.
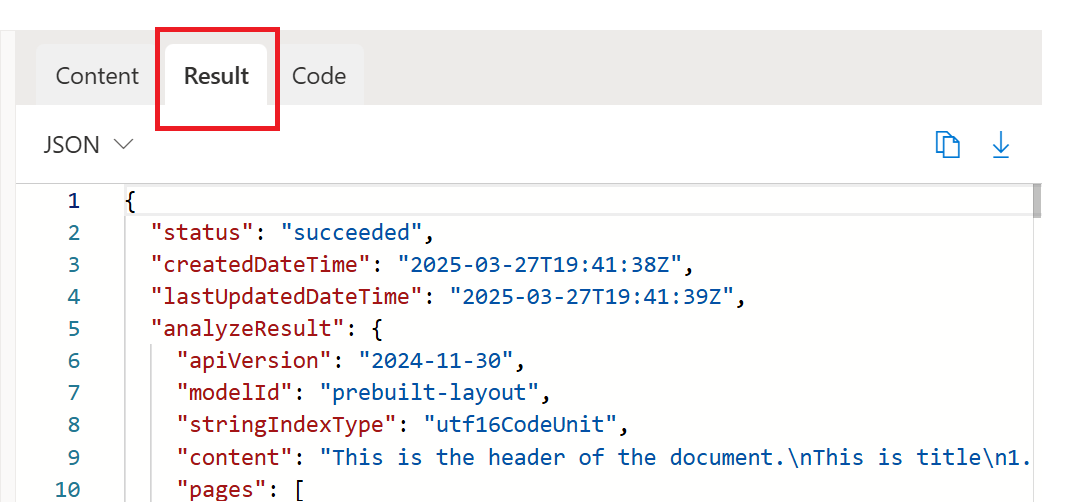
Halaman
Kumpulan halaman adalah daftar halaman dalam dokumen. Setiap halaman diwakili secara berurutan dalam dokumen dan menyertakan sudut orientasi yang menunjukkan apakah halaman diputar dan lebar dan tinggi (dimensi dalam piksel). Unit halaman dalam output model dihitung seperti yang ditunjukkan:
| Format file | Unit halaman terkomputasi | Total halaman |
|---|---|---|
| Gambar (JPEG/JPG, PNG, BMP, HEIF) | Setiap gambar = 1 unit halaman | Total gambar |
| Setiap halaman dalam PDF = 1 unit halaman | Total halaman dalam PDF | |
| TIFF | Setiap gambar dalam TIFF = 1 unit halaman | Jumlah gambar di TIFF |
| Word (DOCX) | Hingga 3.000 karakter = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Jumlah total halaman, masing-masing hingga 3.000 karakter |
| Excel (XLSX) | Setiap lembar kerja = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Total jumlah lembar kerja |
| PowerPoint (PPTX) | Setiap slide = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Total slide |
| HTML | Hingga 3.000 karakter = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Jumlah total halaman, masing-masing hingga 3.000 karakter |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Mengekstrak halaman yang dipilih
Untuk dokumen yang terdiri dari beberapa halaman besar, gunakan parameter kueri pages untuk menunjukkan nomor halaman atau rentang halaman tertentu untuk ekstraksi teks.
Paragraf
Model Tata Letak mengekstrak semua blok teks yang diidentifikasi dalam koleksi paragraphs sebagai objek tingkat atas di bawah analyzeResults. Setiap entri dalam koleksi ini mewakili blok teks dan mencakup teks yang diekstrak sebagai content serta koordinat pembatas polygon. Informasi spanmenunjuk ke fragmen teks dalam properti content tingkat atas yang berisi teks lengkap dari dokumen.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Fungsi paragraf
Deteksi objek halaman berbasis pembelajaran mesin baru mengekstrak peran logis seperti judul, judul bagian, header halaman, footer halaman, dan banyak lagi. Model Tata Letak Kecerdasan Dokumen menetapkan blok teks tertentu dalam paragraphs koleksi dengan peran atau jenis khusus yang diprediksi oleh model. Yang terbaik adalah menggunakan peran paragraf dengan dokumen yang tidak terstruktur untuk membantu memahami tata letak konten yang diekstrak untuk analisis semantik yang lebih kaya. Peran paragraf berikut didukung:
| Peran yang diprediksi | Deskripsi | Jenis file yang didukung |
|---|---|---|
title |
Judul utama di halaman | pdf, gambar, docx, pptx, xlsx, html |
sectionHeading |
Satu atau beberapa subjudul di halaman | pdf, image, docx, xlsx, html |
footnote |
Teks di dekat bagian bawah halaman | pdf, gambar |
pageHeader |
Teks di dekat tepi atas halaman | pdf, image, docx |
pageFooter |
Teks di dekat tepi bawah halaman | pdf, gambar, docx, pptx, html |
pageNumber |
Nomor halaman | pdf, gambar |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Teks, baris, dan kata
Model tata letak dokumen dalam Kecerdasan Dokumen mengekstrak teks gaya cetak dan tulisan tangan sebagai lines dan words. Koleksi styles mencakup gaya tulisan tangan apa pun untuk garis jika terdeteksi bersama dengan rentang yang menunjuk ke teks terkait. Fitur ini berlaku untuk bahasa tulisan tangan yang didukung.
Untuk Model Tata Letak Microsoft Word, Excel, PowerPoint, dan HTML, Kecerdasan Dokumen v4.0 2024-11-30 (GA) mengekstrak semua teks yang disematkan apa adanya. Teks diekstrak sebagai kata dan paragraf. Gambar yang disematkan tidak didukung.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Gaya tulisan tangan untuk baris teks
Respons mencakup pengklasifikasian apakah setiap baris teks bergaya tulisan tangan atau tidak, bersama dengan tingkat keyakinan. Untuk informasi selengkapnya. Lihat Dukungan bahasa tulisan tangan. Contoh berikut menunjukkan contoh cuplikan JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Jika Anda mengaktifkan kemampuan tambahan font/gaya
Tanda pilihan
Model Tata Letak juga mengekstrak tanda pilihan dari dokumen. Tanda pilihan yang diekstrak muncul di dalam koleksi pages untuk setiap halaman. Mereka termasuk pembatas polygon, confidence, dan pilihan state (selected/unselected). Representasi teks (yaitu, :selected: dan :unselected) juga disertakan sebagai indeks awal (offset) dan length yang mereferensikan properti tingkat content atas yang berisi teks lengkap dari dokumen.
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
Tabel
Mengekstrak tabel adalah persyaratan utama untuk memproses dokumen yang berisi data dalam volume besar yang biasanya diformat sebagai tabel. Model Tata Letak mengekstrak tabel di bagian pageResults output JSON. Informasi tabel yang diekstrak .. /menyertakan jumlah kolom dan baris, rentang baris, dan rentang kolom. Setiap sel dengan poligon pembatasnya dihasilkan bersama dengan informasi apakah area tersebut dikenali sebagai columnHeader atau tidak. Model ini mendukung ekstraksi tabel yang diputar. Setiap sel tabel berisi indeks baris dan kolom dan koordinat poligon pembatas. Untuk teks sel, model menghasilkan informasi span yang berisi indeks awal (offset). Model ini juga mengeluarkan length dalam konten tingkat atas yang berisi teks lengkap dari dokumen.
Berikut adalah beberapa faktor yang perlu dipertimbangkan saat menggunakan kemampuan ekstraksi dari Kecerdasan Dokumen:
Apakah data yang ingin Anda ekstrak disajikan sebagai tabel, dan apakah struktur tabel bermakna?
Apakah data dapat dimuat dalam kisi dua dimensi jika data tidak dalam format tabel?
Apakah tabel Anda mencakup beberapa halaman? Jika demikian, untuk menghindari harus melabeli semua halaman, pisahkan PDF menjadi beberapa halaman sebelum mengirimkannya ke Pemrosesan Dokumen. Setelah analisis, proses ulang halaman menjadi satu tabel.
Tabular fields lihat jika Anda membuat model kustom. Tabel dinamis memiliki jumlah variabel baris untuk setiap kolom. Tabel tetap memiliki jumlah baris konstan untuk setiap kolom.
Catatan
- Analisis tabel tidak didukung jika file input adalah XLSX.
- Untuk
2024-11-30(GA), wilayah pembatas untuk gambar dan tabel hanya mencakup konten inti dan mengecualikan keterangan dan catatan kaki terkait.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
Respons output ke format markdown
API Tata Letak dapat menghasilkan teks yang diekstrak dalam format markdown.
outputContentFormat=markdown Gunakan untuk menentukan format output dalam markdown. Konten markdown dihasilkan sebagai bagian dari content.
Catatan
Untuk v4.0 2024-11-30 (GA), representasi tabel diubah ke tabel HTML untuk mengaktifkan penyajian sel gabungan, header multi-baris, dll. Perubahan terkait lainnya adalah menggunakan karakter ☒ kotak centang Unicode dan ☐ untuk tanda pilihan alih-alih :selected: dan :unselected:. Pembaruan ini berarti bahwa konten bidang tanda pilihan berisi :selected: meskipun rentangnya merujuk ke karakter Unicode dalam rentang tingkat atas. Lihat Format Output Markdown untuk definisi lengkap elemen Markdown.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Angka
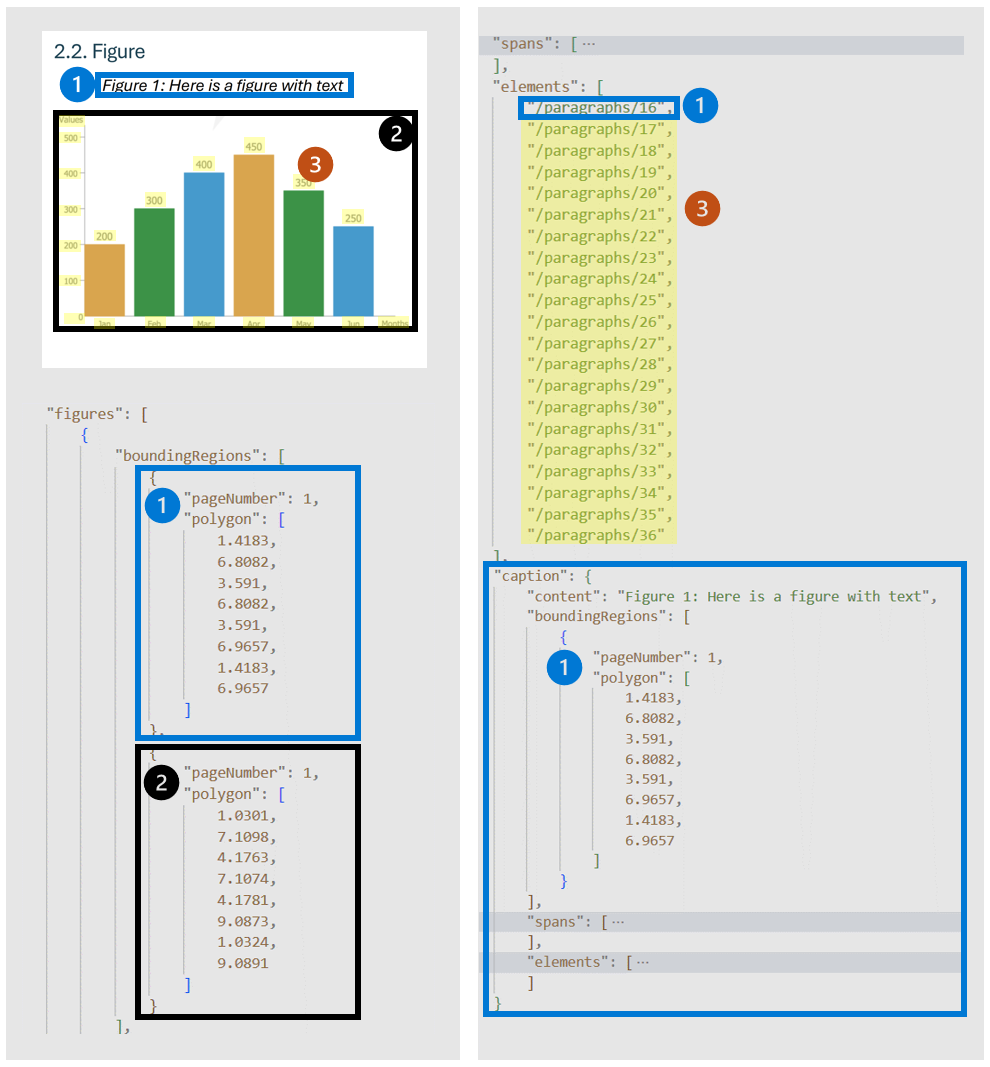
Gambar (bagan, gambar) dalam dokumen memainkan peran penting dalam melengkapi dan meningkatkan konten tekstual, memberikan representasi visual yang membantu pemahaman informasi yang kompleks. Objek gambar yang terdeteksi oleh model Tata Letak memiliki properti utama seperti boundingRegions (lokasi spasial gambar pada halaman dokumen, termasuk nomor halaman dan koordinat poligon yang menguraikan batas gambar), spans (merinci rentang teks yang terkait dengan gambar, menentukan offset dan panjangnya dalam teks dokumen. Koneksi ini membantu mengaitkan gambar dengan konteks tekstual yang relevan), elements (pengidentifikasi untuk elemen teks atau paragraf dalam dokumen yang terkait dengan atau menggambarkan gambar) dan caption jika ada.
Ketika output=figures ditentukan selama operasi analisis awal, layanan menghasilkan gambar yang dipotong untuk semua angka yang terdeteksi yang dapat diakses melalui /analyeResults/{resultId}/figures/{figureId}.
FigureId disertakan dalam setiap objek gambar, sesuai dengan konvensi yang tidak didokumentasikan di {pageNumber}.{figureIndex} di mana figureIndex direset menjadi satu per halaman.
Catatan
Untuk v4.0 2024-11-30 (GA), wilayah pembatas untuk gambar dan tabel hanya mencakup konten inti dan mengecualikan keterangan dan catatan kaki terkait.
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
Bagian
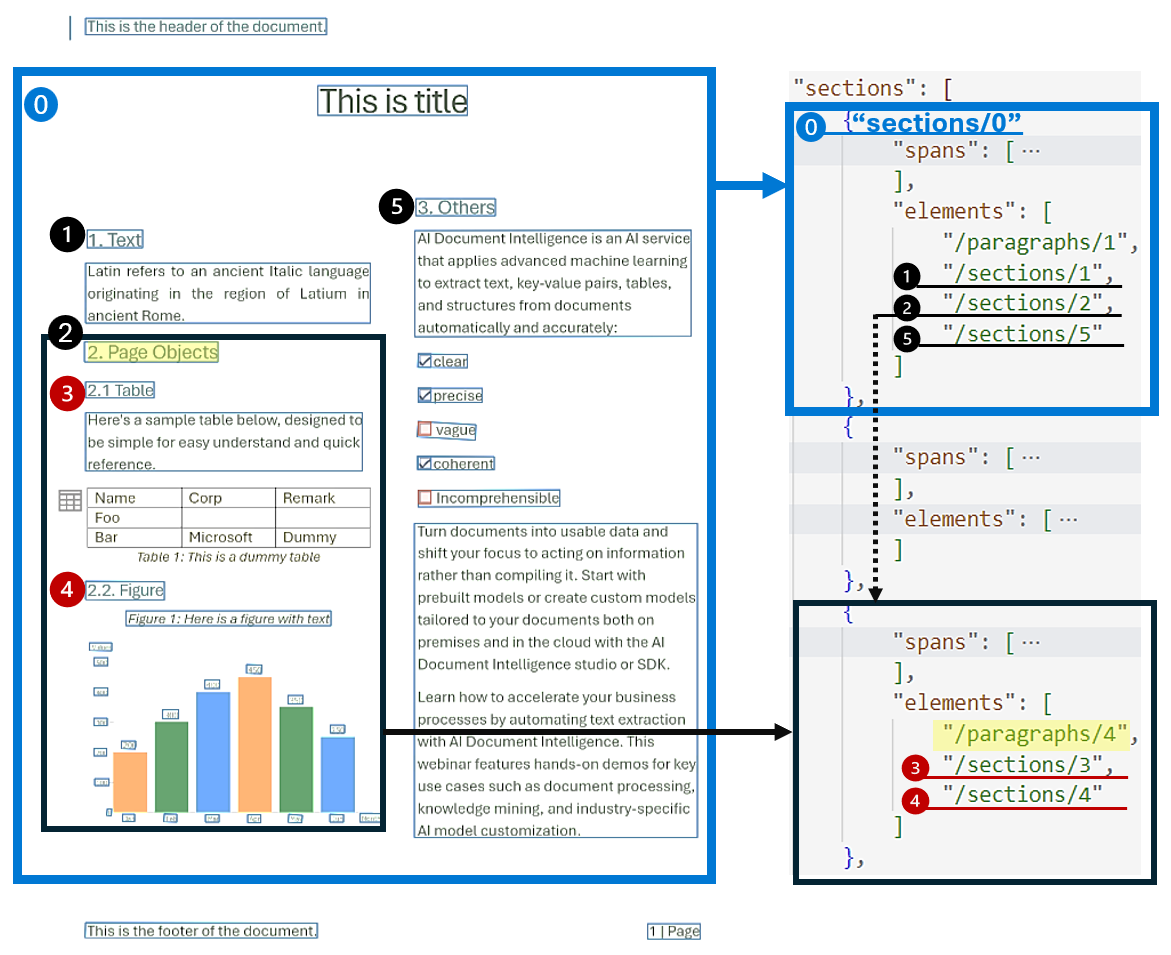
Analisis struktur dokumen hierarkis sangat penting dalam mengatur, memahami, dan memproses dokumen yang luas. Pendekatan ini sangat penting untuk mensegmentasi dokumen panjang secara semantik untuk meningkatkan pemahaman, memfasilitasi navigasi, dan meningkatkan pengambilan informasi. Munculnya retrieval-augmented generation (RAG) dalam AI generatif dokumen menggarisbawahi pentingnya analisis struktur dokumen hierarkis. Model Tata Letak mendukung bagian dan subbagian dalam output, yang mengidentifikasi hubungan bagian dan objek dalam setiap bagian. Struktur hierarki pada setiap bagian dipertahankan di elements. Anda dapat menggunakan format respons output ke markdown untuk dengan mudah mendapatkan bagian dan subbagian pada markdown.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Konten ini berlaku untuk:![]() tanda centangv3.0 (GA) | Versi terbaru:tanda centang ungu
tanda centangv3.0 (GA) | Versi terbaru:tanda centang ungu![]() purple-checkmark v4.0 (GA) Versi sebelumnya:tanda centang biruv2.1
purple-checkmark v4.0 (GA) Versi sebelumnya:tanda centang biruv2.1
Konten ini berlaku untuk:![]() Versi terbaru: |
Versi terbaru: | ![]() v4.0 (GA)
v4.0 (GA)
Model tata letak Kecerdasan Dokumen adalah API analisis dokumen berbasis pembelajaran mesin tingkat lanjut yang tersedia di cloud Kecerdasan Dokumen. Ini memungkinkan Anda untuk mengambil dokumen dalam berbagai format dan mengembalikan representasi data terstruktur dari dokumen. API menggabungkan versi yang disempurnakan dari kemampuan Pengenalan Karakter Optik (OCR) kami yang canggih dengan model pembelajaran mendalam untuk mengekstrak teks, tabel, tanda pilihan, dan struktur dokumen.
Analisis tata letak dokumen
Analisis tata letak struktur dokumen adalah proses menganalisis dokumen untuk mengekstrak wilayah yang diminati dan hubungan antar-hubungannya. Tujuannya adalah untuk mengekstrak teks dan elemen struktural dari halaman untuk membangun model pemahaman semantik yang lebih baik. Ada dua jenis peran dalam tata letak dokumen:
- Peran geometris: Teks, tabel, gambar, dan tanda pilihan adalah contoh peran geometris.
- Peran logis: Judul, judul, dan footer adalah contoh peran logis teks.
Ilustrasi berikut menunjukkan komponen umum dalam gambar halaman sampel.
Bahasa dan lokal yang didukung
Lihat halaman Dukungan Bahasa—model analisis dokumen untuk daftar lengkap bahasa yang didukung.
Kecerdasan Dokumen v2.1 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber |
|---|---|
| Model tata letak | • pelabelan Kecerdasan Dokumen • • • Kontainer Docker Kecerdasan Dokumen |
Panduan input
Format file yang didukung:
| Modél | Gambar: JPEG/JPG, , PNGBMP, TIFF, ,HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Baca | ✔ | ✔ | ✔ |
| Tata letak | ✔ | ✔ | |
| Dokumen Umum | ✔ | ✔ | |
| Bawaan | ✔ | ✔ | |
| Ekstraksi khusus | ✔ | ✔ | |
| Klasifikasi kustom | ✔ | ✔ | ✔ |
Untuk hasil terbaik, berikan satu foto yang jelas atau pemindaian berkualitas tinggi per dokumen.
Untuk PDF dan TIFF, hingga 2.000 halaman dapat diproses (dengan langganan tingkat gratis, hanya dua halaman pertama yang diproses).
Ukuran file untuk menganalisis dokumen adalah 500 MB untuk tingkat berbayar (S0) dan
4MB secara gratis (F0).Dimensi gambar harus antara 50 piksel x 50 piksel dan 10.000 piksel x 10.000 piksel.
Jika PDF Anda dikunci dengan kata sandi, Anda harus menghapus kunci sebelum pengiriman.
Tinggi minimum teks yang akan diekstrak adalah 12 piksel untuk gambar piksel 1024 x 768. Dimensi ini sesuai dengan
8teks dengan ukuran sekitar 150 titik per inci (DPI).Untuk pelatihan model kustom, jumlah maksimum halaman untuk data pelatihan adalah 500 untuk model template kustom dan 50.000 untuk model neural kustom.
Untuk pelatihan model ekstraksi kustom, ukuran total data pelatihan adalah 50 MB untuk model templat dan
1GB untuk model neural.Untuk pelatihan model klasifikasi kustom, ukuran total data pelatihan adalah
1GB dengan maksimum 10.000 halaman. Untuk2024-11-30(GA), ukuran total data pelatihan adalah2GB dengan maksimum 10.000 halaman.
Panduan Input
- Format file yang didukung: JPEG, PNG, PDF, dan TIFF.
- Jumlah halaman yang didukung: Untuk PDF dan TIFF, hingga 2.000 halaman diproses. Untuk pelanggan level gratis, hanya dua halaman pertama yang diproses.
- Ukuran file yang didukung: ukuran file harus kurang dari 50 MB dan dimensi minimal 50 x 50 piksel dan paling banyak 10.000 x 10.000 piksel.
Mulai sekarang
Lihat bagaimana data, termasuk teks, tabel, header tabel, tanda pilihan, dan informasi struktur diekstrak dari dokumen menggunakan Kecerdasan Dokumen. Anda membutuhkan sumber daya berikut:
Langganan Azure—Anda dapat membuatnya secara gratis.
Instans Kecerdasan Dokumen di portal Azure. Anda dapat menggunakan tingkat harga gratis (
F0) untuk mencoba layanan. Setelah sumber daya Anda disebarkan, pilih Buka sumber daya untuk mendapatkan kunci dan titik akhir Anda.
Setelah mengambil kunci dan titik akhir, Anda dapat menggunakan opsi pengembangan berikut untuk membangun dan menyebarkan aplikasi Kecerdasan Dokumen Anda:
Catatan
Document Intelligence Studio tersedia dengan API v3.0 dan versi yang lebih baru.
REST API
Alat Pelabelan Sampel untuk Kecerdasan Dokumen
Navigasikan ke alat contoh Kecerdasan Dokumen.
Pada beranda alat sampel, pilih Gunakan Tata Letak untuk mendapatkan teks, tabel, dan tanda pilihan.
** Pada kolom titik akhir layanan Kecerdasan Dokumen, tempelkan titik akhir yang Anda peroleh dengan langganan Kecerdasan Dokumen Anda.
Di bidang kunci, tempelkan kunci yang Anda peroleh dari sumber daya Kecerdasan Dokumen Anda.
Di bidang Sumber, pilih URL dari menu dropdown Anda dapat menggunakan dokumen sampel kami:
Pilih tombol Ambil .
Pilih jalankan tata letak. Alat Pelabelan Sampel Kecerdasan Dokumen memanggil
Analyze LayoutAPI untuk menganalisis dokumen.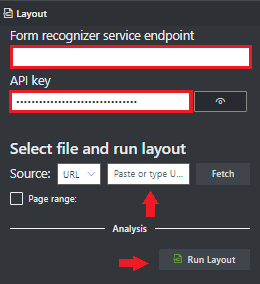
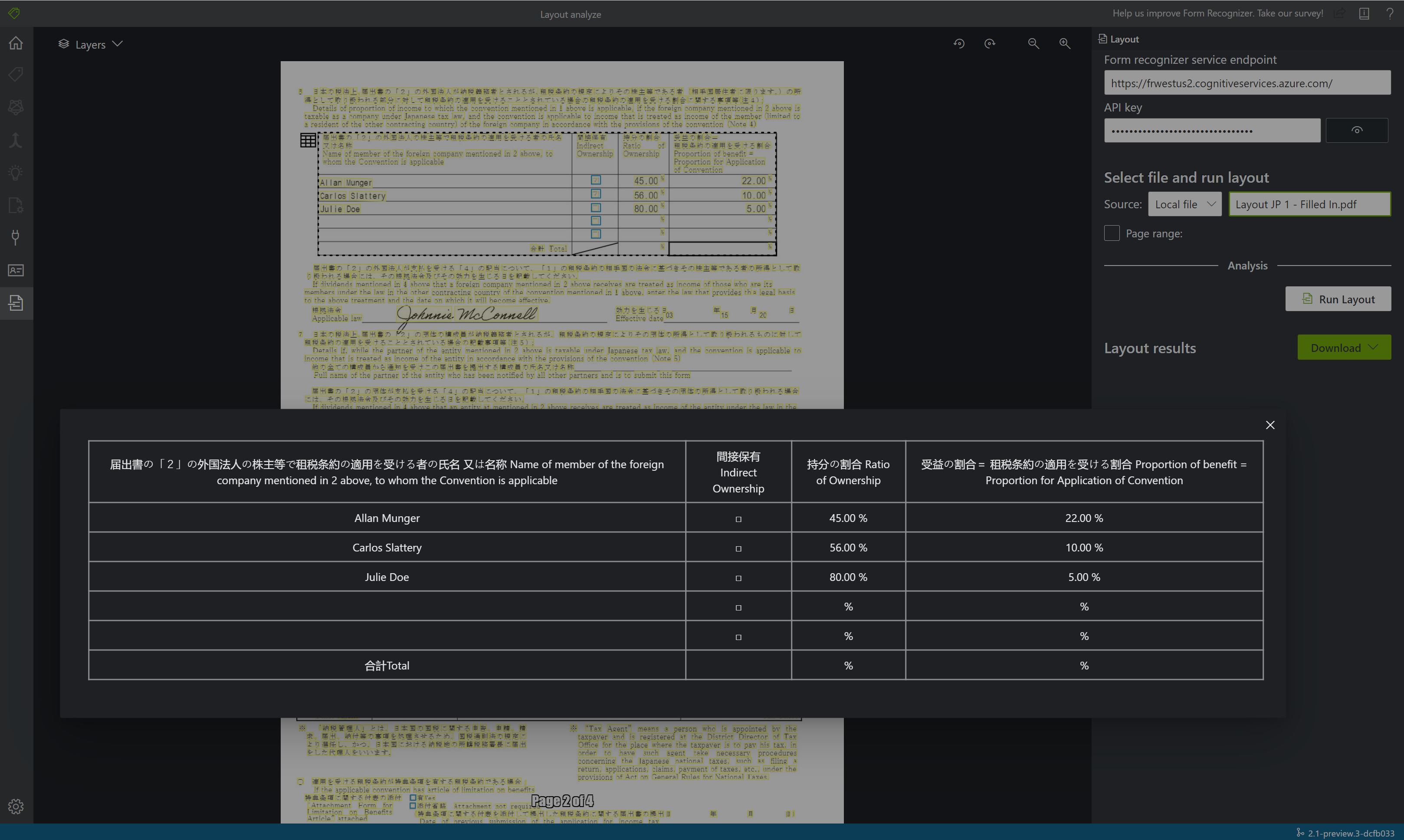
Lihat hasilnya - lihat teks yang diekstrak yang disorot, tanda pilihan yang terdeteksi, dan tabel yang terdeteksi.
{kind=link}
Kecerdasan Dokumen v2.1 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber |
|---|---|
| API Tata Letak | • pelabelan Kecerdasan Dokumen • • • Kontainer Docker Kecerdasan Dokumen |
Ekstrak data
Model tata letak mengekstrak elemen struktural dari dokumen Anda. Untuk mengikuti adalah deskripsi elemen struktural ini dengan panduan tentang cara mengekstraknya dari input dokumen Anda:
Ekstrak data
Model tata letak mengekstrak elemen struktural dari dokumen Anda. Untuk mengikuti adalah deskripsi elemen struktural ini dengan panduan tentang cara mengekstraknya dari input dokumen Anda:
Halaman
Kumpulan halaman adalah daftar halaman dalam dokumen. Setiap halaman diwakili secara berurutan dalam dokumen dan .. /termasuk sudut orientasi yang menunjukkan apakah halaman diputar dan lebar dan tinggi (dimensi dalam piksel). Unit halaman dalam output model dihitung seperti yang ditunjukkan:
| Format file | Unit halaman terkomputasi | Total halaman |
|---|---|---|
| Gambar (JPEG/JPG, PNG, BMP, HEIF) | Setiap gambar = 1 unit halaman | Total gambar |
| Setiap halaman dalam PDF = 1 unit halaman | Total halaman dalam PDF | |
| TIFF | Setiap gambar dalam TIFF = 1 unit halaman | Jumlah gambar di TIFF |
| Word (DOCX) | Hingga 3.000 karakter = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Jumlah total halaman, masing-masing hingga 3.000 karakter |
| Excel (XLSX) | Setiap lembar kerja = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Total jumlah lembar kerja |
| PowerPoint (PPTX) | Setiap slide = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Total slide |
| HTML | Hingga 3.000 karakter = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Jumlah total halaman, masing-masing hingga 3.000 karakter |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Mengekstrak halaman yang dipilih dari dokumen
Untuk dokumen yang terdiri dari beberapa halaman besar, gunakan parameter kueri pages untuk menunjukkan nomor halaman atau rentang halaman tertentu untuk ekstraksi teks.
Paragraf
Model Tata Letak mengekstrak semua blok teks yang diidentifikasi dalam koleksi paragraphs sebagai objek tingkat atas di bawah analyzeResults. Setiap entri dalam koleksi ini mewakili blok teks dan mencakup teks yang diekstrak sebagai content serta koordinat pembatas polygon. Informasi spanmenunjuk ke fragmen teks dalam properti content tingkat atas yang berisi teks lengkap dari dokumen.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Fungsi paragraf
Deteksi objek halaman berbasis pembelajaran mesin baru mengekstrak peran logis seperti judul, judul bagian, header halaman, footer halaman, dan banyak lagi. Model Tata Letak Kecerdasan Dokumen menetapkan blok teks tertentu dalam paragraphs koleksi dengan peran atau jenis khusus yang diprediksi oleh model. Yang terbaik adalah menggunakan peran paragraf dengan dokumen yang tidak terstruktur untuk membantu memahami tata letak konten yang diekstrak untuk analisis semantik yang lebih kaya. Peran paragraf berikut didukung:
| Peran yang diprediksi | Deskripsi | Jenis file yang didukung |
|---|---|---|
title |
Judul utama di halaman | pdf, gambar, docx, pptx, xlsx, html |
sectionHeading |
Satu atau beberapa subjudul di halaman | pdf, image, docx, xlsx, html |
footnote |
Teks di dekat bagian bawah halaman | pdf, gambar |
pageHeader |
Teks di dekat tepi atas halaman | pdf, image, docx |
pageFooter |
Teks di dekat tepi bawah halaman | pdf, gambar, docx, pptx, html |
pageNumber |
Nomor halaman | pdf, gambar |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Teks, garis, dan kata
Model tata letak dokumen dalam Kecerdasan Dokumen mengekstrak teks gaya cetak dan tulisan tangan sebagai lines dan words. Koleksi styles .. /menyertakan gaya tulisan tangan untuk baris jika terdeteksi bersama dengan rentang yang menunjuk ke teks terkait. Fitur ini berlaku untuk bahasa tulisan tangan yang didukung.
Untuk Model Tata Letak Microsoft Word, Excel, PowerPoint, dan HTML, Kecerdasan Dokumen v4.0 2024-11-30 (GA) mengekstrak semua teks yang disematkan apa adanya. Teks diekstrak sebagai kata dan paragraf. Gambar yang disematkan tidak didukung.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Gaya tulisan tangan
Respons mencakup pengklasifikasian apakah setiap baris teks bergaya tulisan tangan atau tidak, bersama dengan tingkat keyakinan. Untuk informasi selengkapnya. Lihat Dukungan bahasa tulisan tangan. Contoh berikut menunjukkan contoh cuplikan JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Jika Anda mengaktifkan kemampuan tambahan font/gaya
Tanda pilihan
Model Tata Letak juga mengekstrak tanda pilihan dari dokumen. Tanda pilihan yang diekstrak muncul di dalam koleksi pages untuk setiap halaman. Mereka termasuk pembatas polygon, confidence, dan pilihan state (selected/unselected). Representasi teks (yaitu, :selected: dan :unselected) juga disertakan sebagai indeks awal (offset) dan length yang mereferensikan properti tingkat content atas yang berisi teks lengkap dari dokumen.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Tabel
Mengekstrak tabel adalah persyaratan utama untuk memproses dokumen yang berisi data dalam volume besar yang biasanya diformat sebagai tabel. Model Tata Letak mengekstrak tabel di bagian pageResults output JSON. Informasi tabel yang diekstrak .. /menyertakan jumlah kolom dan baris, rentang baris, dan rentang kolom. Setiap sel dengan poligon pembatasnya dihasilkan bersama dengan informasi apakah area tersebut dikenali sebagai columnHeader atau tidak. Model ini mendukung ekstraksi tabel yang diputar. Setiap sel tabel berisi indeks baris dan kolom dan koordinat poligon pembatas. Untuk teks sel, model menghasilkan informasi span yang berisi indeks awal (offset). Model ini juga mengeluarkan length dalam konten tingkat atas yang berisi teks lengkap dari dokumen.
Berikut adalah beberapa faktor yang perlu dipertimbangkan saat menggunakan kemampuan ekstraksi dari Kecerdasan Dokumen:
Apakah data yang ingin Anda ekstrak disajikan sebagai tabel, dan apakah struktur tabel bermakna?
Apakah data dapat dimuat dalam kisi dua dimensi jika data tidak dalam format tabel?
Apakah tabel Anda mencakup beberapa halaman? Jika demikian, untuk menghindari harus melabeli semua halaman, pisahkan PDF menjadi beberapa halaman sebelum mengirimkannya ke Pemrosesan Dokumen. Setelah analisis, proses ulang halaman menjadi satu tabel.
Tabular fields lihat jika Anda membuat model kustom. Tabel dinamis memiliki jumlah variabel baris untuk setiap kolom. Tabel tetap memiliki jumlah baris konstan untuk setiap kolom.
Catatan
- Analisis tabel tidak didukung jika file input adalah XLSX.
- Kecerdasan Dokumen v4.0
2024-11-30(GA) mendukung wilayah pembatas untuk gambar dan tabel yang hanya mencakup konten inti dan mengecualikan keterangan dan catatan kaki terkait.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Anotasi
Model Tata Letak mengekstrak anotasi dalam dokumen, seperti centang dan silang. Respons.. termasuk skor kepercayaan, jenis anotasi, dan poligon pembatas.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Urutan pembacaan alami (hanya Latin)
Anda dapat menentukan urutan output baris teks dengan parameter kueri readingOrder. Gunakan natural untuk output urutan membaca yang lebih dapat dipahami manusia seperti yang ditunjukkan pada contoh berikut. Fitur ini hanya didukung untuk bahasa Latin.

Pilih nomor halaman atau rentang untuk ekstraksi teks
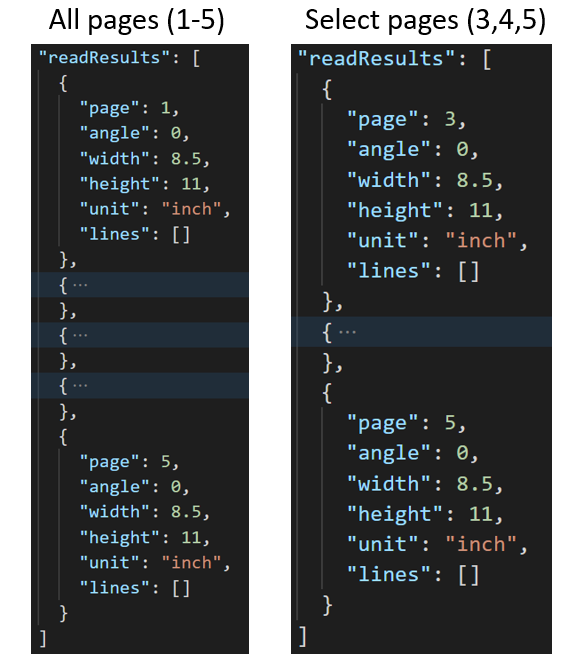
Untuk dokumen yang terdiri dari beberapa halaman besar, gunakan parameter kueri pages untuk menunjukkan nomor halaman atau rentang halaman tertentu untuk ekstraksi teks. Contoh berikut memperlihatkan dokumen dengan 10 halaman, dengan teks yang diekstrak untuk kedua kasus - semua halaman (1-10) dan halaman yang dipilih (3-6).
Operasi Pengambilan Hasil Analisis Tata Letak
Langkah kedua adalah memanggil operasi Dapatkan Hasil Analisis Tata Letak. Operasi ini menggunakan ID Hasil yang dibuat oleh operasi Analyze Layout sebagai masukan. Operasi menghasilkan respons JSON yang berisi bidang status dengan kemungkinan nilai berikut.
| Bidang | Jenis | Nilai yang dapat dipakai |
|---|---|---|
| kedudukan | benang |
notStarted: Operasi analisis tidak dimulai.running: Operasi analisis sedang berlangsung.failed: Operasi analisis gagal.succeeded: Operasi analisis berhasil. |
Panggil operasi ini secara berulang hingga menghasilkan nilai succeeded. Untuk menghindari melebihi tarif permintaan per detik (RPS), gunakan interval 3 hingga 5 detik.
Ketika bidang status memiliki nilai succeeded, respons JSON mencakup tata letak, teks, tabel, dan tanda pilihan yang diekstrak. Data yang diekstrak mencakup baris dan kata teks yang diekstraksi, kotak pembatas, tampilan teks dengan indikasi tulisan tangan, tabel, dan tanda pilihan dengan penunjukan terpilih/tidak terpilih.
Klasifikasi tulisan tangan untuk baris teks (hanya dalam bahasa Latin)
Respons mencakup pengklasifikasian apakah setiap baris teks bergaya tulisan tangan atau tidak, bersama dengan tingkat keyakinan. Fitur ini hanya didukung untuk bahasa Latin. Contoh berikut menunjukkan klasifikasi tulisan tangan untuk teks dalam gambar.

Sampel output JSON
Respons terhadap operasi Dapatkan Hasil Analisis Tata Letak adalah representasi terstruktur dari dokumen dengan semua informasi yang diekstrak. Silakan lihat di sini untuk file dokumen sampel dan output terstruktur output tata letak sampel.
Output JSON memiliki dua bagian:
-
readResultsnode berisi semua teks yang dikenali dan tanda pilihan. Hierarki presentasi teks adalah halaman, lalu baris, lalu kata individual. -
pageResultsnode berisi informasi tentang tabel dan sel yang diekstrak dengan kotak pembatas, tingkat kepercayaan, serta rujukan ke baris dan kata di bidang "readResults".
Contoh Keluaran
Teks
API tata letak mengekstrak teks dari dokumen dan gambar dengan berbagai sudut dan warna teks. API menerima foto dokumen, faks, teks cetak dan/atau tulisan tangan (hanya dalam bahasa Inggris), dan mode campuran. Teks diekstrak dengan informasi yang diberikan pada kata, garis, kotak pembatas, tingkat kepercayaan, dan gaya (tulisan tangan atau lainnya). Semua informasi teks disertakan dalam bagian readResults dari output JSON.
Tabel dengan header
API Tata Letak mengekstrak tabel di bagian pageResults dari output JSON. Dokumen dapat dipindai, difoto, atau di buat digital. Tabel dapat menjadi rumit dengan sel atau kolom yang digabungkan, dengan atau tanpa batas, dan dengan sudut ganjil. Informasi tabel yang diekstrak .. /menyertakan jumlah kolom dan baris, rentang baris, dan rentang kolom. Setiap sel dengan kotak pembatasnya dihasilkan bersama dengan apakah area dikenali sebagai bagian dari header atau tidak. Model memprediksi sel header dapat mencakup beberapa baris dan belum tentu merupakan baris pertama dalam tabel. Mereka juga bekerja dengan tabel yang diputar. Setiap sel tabel juga menyertakan teks lengkap dengan referensi ke kata-kata individual di bagian readResults.
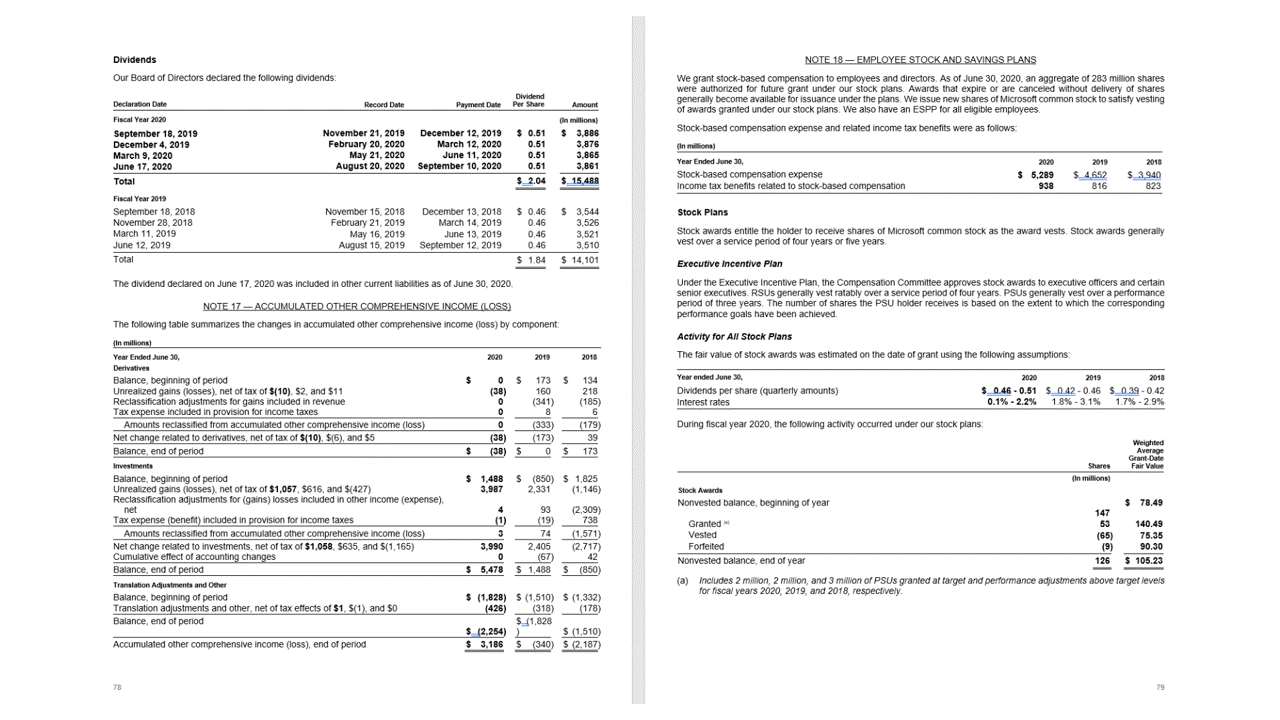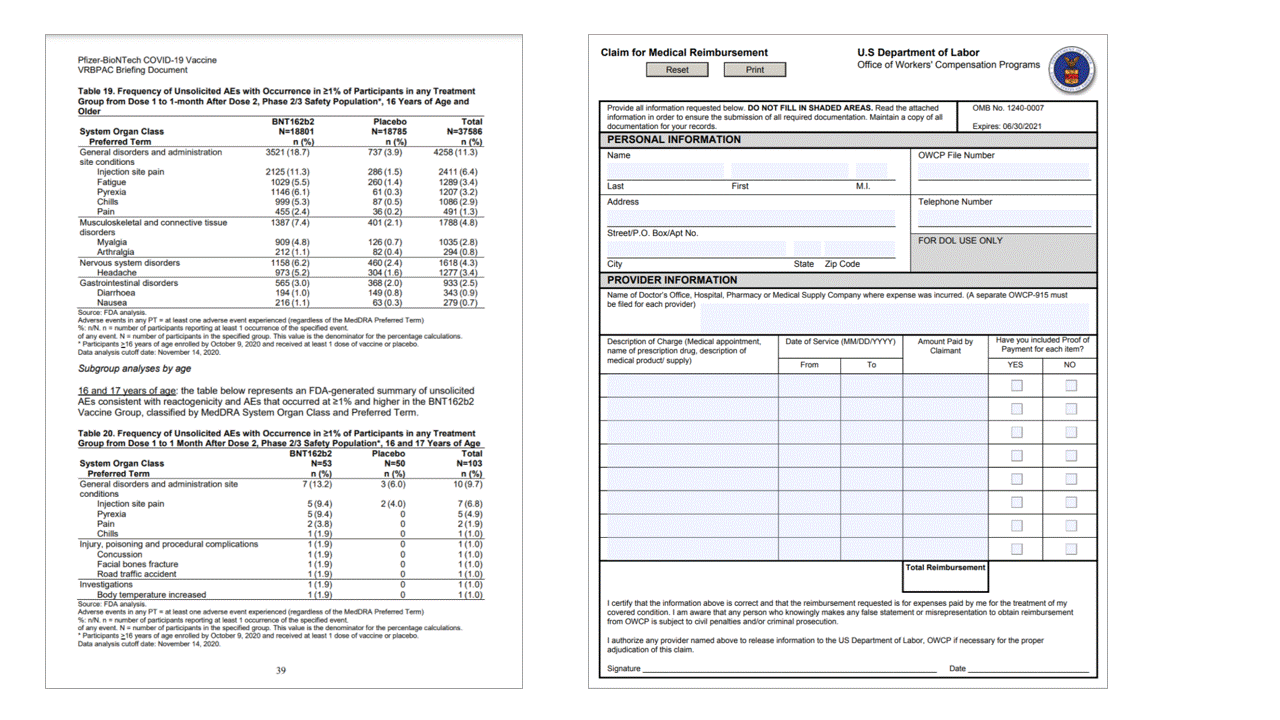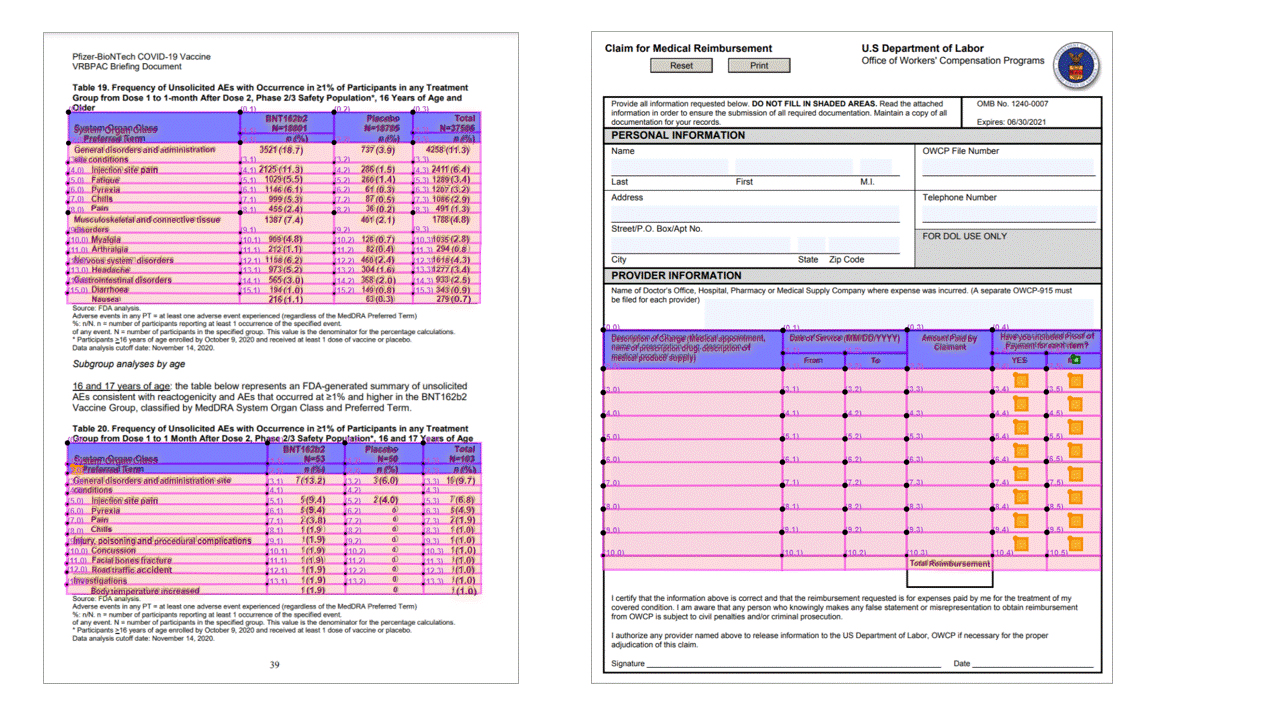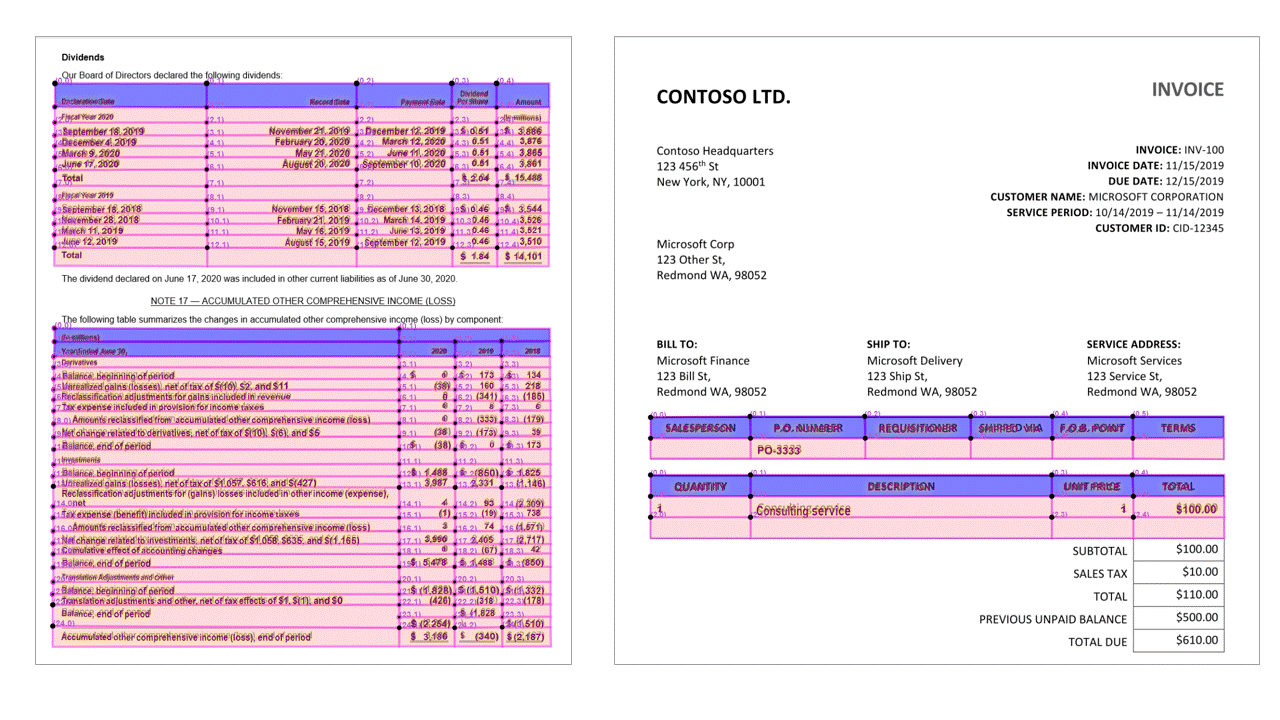
Tanda pilihan (dokumen)
API tata letak juga mengekstrak tanda pilihan dari dokumen. Tanda pilihan yang diekstrak termasuk kotak pembatas, tingkat keyakinan, dan status (dipilih/tidak dipilih). Informasi tanda pilihan diekstrak di bagian readResults dari output JSON.
Panduan migrasi
- Ikuti panduan migrasi Kecerdasan Dokumen v3.1 kami untuk mempelajari cara menggunakan versi v3.1 di aplikasi dan alur kerja Anda.
Langkah berikutnya
Pelajari cara memproses formulir dan dokumen Anda sendiri dengan Studio Kecerdasan Dokumen.
Selesaikan panduan cepat Kecerdasan Dokumen dan mulai buat aplikasi pemrosesan dokumen dalam bahasa pengembangan pilihan Anda.
Pelajari cara memproses formulir dan dokumen Anda sendiri dengan alat Pelabelan Sampel Kecerdasan Dokumen.
Selesaikan panduan cepat Kecerdasan Dokumen dan mulai buat aplikasi pemrosesan dokumen dalam bahasa pengembangan pilihan Anda.