Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Saat kueri pengguna dicocokkan dengan pangkalan pengetahuan, QnA Maker menampilkan jawaban yang relevan, bersama dengan skor keyakinan. Skor ini menunjukkan keyakinan bahwa jawabannya adalah kecocokan yang tepat untuk kueri pengguna yang diberikan.
Skor keyakinan adalah angka antara 0 dan 100. Skor 100 kemungkinan adalah kecocokan yang tepat, sementara skor 0 berarti, bahwa tidak ada jawaban yang cocok ditemukan. Semakin tinggi skor - semakin besar kepercayaan pada jawabannya. Untuk kueri tertentu, mungkin ada beberapa jawaban yang ditampilkan. Dalam hal ini, jawabannya ditampilkan dalam urutan menurun skor keyakinan.
Dalam contoh di bawah, Anda dapat melihat satu entitas tanya jawab, dengan 2 pertanyaan.

Untuk contoh di atas- Anda dapat mengharapkan skor seperti rentang skor sampel di bawah- untuk berbagai jenis kueri pengguna:
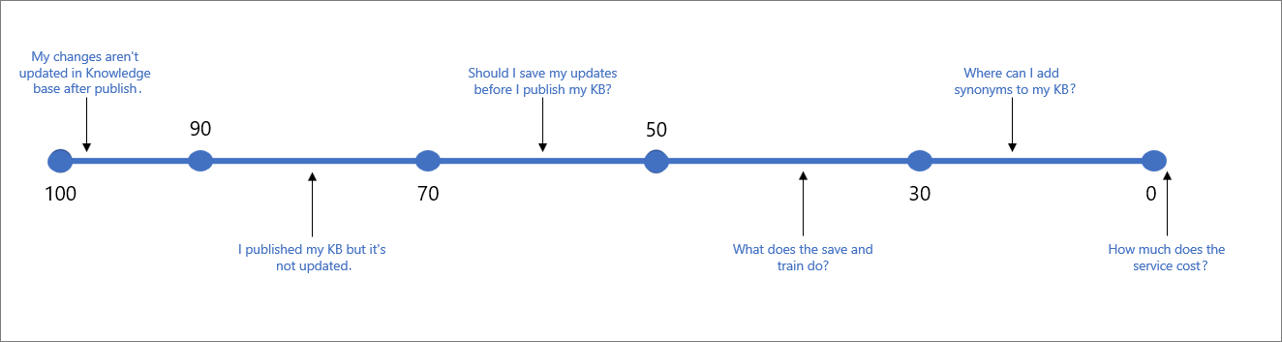
Tabel berikut menunjukkan keyakinan umum yang terkait dengan skor tertentu.
| Nilai Skor | Arti Skor | Kueri Contoh |
|---|---|---|
| 90 - 100 | Kecocokan yang hampir tepat dari kueri pengguna dan pertanyaan KB | "Perubahan saya tidak diperbarui dalam KB setelah diterbitkan" |
| > 70 | Keyakinan tinggi - biasanya jawaban yang baik yang sepenuhnya menjawab kueri pengguna | "Saya menerbitkan KB saya tetapi tidak diperbarui" |
| 50 - 70 | Keyakinan sedang - biasanya jawaban yang cukup baik yang akan menjawab niat utama kueri pengguna | "Apakah saya harus menyimpan pembaruan saya sebelum menerbitkan KB?" |
| 30 - 50 | Keyakinan rendah - biasanya jawaban terkait, yang sebagian menjawab niat pengguna | " Apa fungsi menyimpan dan melatih?" |
| < 30 | Keyakinan yang sangat rendah - biasanya tidak menjawab kueri pengguna, tetapi memiliki beberapa kata atau frasa yang cocok | " Di mana saya dapat menambahkan sinonim ke KB saya" |
| 0 | Tidak ada kecocokan, jadi jawabannya tidak ditampilkan. | "Berapa biaya layanan" |
Memilih ambang skor
Tabel di atas menunjukkan skor yang diharapkan pada sebagian besar KB. Namun, karena setiap KB berbeda, dan memiliki berbagai jenis kata, niat, dan tujuan - kami sarankan Anda menguji dan memilih ambang yang paling cocok untuk Anda. Secara default ambang diatur ke 0, sehingga semua jawaban yang mungkin ditampilkan. Ambang yang direkomendasikan yang akan berfungsi untuk sebagian besar KB, adalah 50.
Saat memilih ambang Anda, ingatlah keseimbangan antara Akurasi dan Cakupan, dan sesuaikan ambang Anda berdasarkan kebutuhan Anda.
Jika Akurasi (atau presisi) lebih penting untuk skenario Anda, tingkatkan ambang Anda. Dengan cara ini, setiap kali Anda mengembalikan jawaban, ini akan menjadi situasi yang jauh lebih PERCAYA DIRI, dan jauh lebih mungkin menjadi jawaban yang diinginkan pengguna. Dalam hal ini, Anda mungkin akhirnya membiarkan lebih banyak pertanyaan tidak terjawab. Misalnya: jika Anda menetapkan ambang batas 70, Anda mungkin melewatkan beberapa contoh ambigu seperti "what is save and train?".
Jika Cakupan (atau recall) lebih penting, dan Anda ingin menjawab sebanyak mungkin pertanyaan, meskipun hanya ada hubungan parsial dengan pertanyaan pengguna, maka TURUNKAN ambang batas. Ini berarti mungkin ada lebih banyak kasus saat jawabannya tidak menjawab kueri pengguna yang sebenarnya, tetapi memberikan beberapa jawaban lain yang agak terkait. Misalnya: jika Anda membuat ambang 30, Anda mungkin memberikan jawaban untuk kueri seperti "Di mana saya dapat mengedit KB saya?"
Catatan
Versi QnA Maker yang lebih baru mencakup peningkatan logika penilaian, dan dapat memengaruhi ambang Anda. Setiap kali Anda memperbarui layanan, pastikan untuk menguji dan mengubah ambang jika perlu. Anda dapat memeriksa versi Layanan QnA di sini, dan melihat cara mendapatkan pembaruan terbaru di sini.
Tetapkan ambang batas
Atur skor ambang sebagai properti dari JSON body GenerateAnswer API. Ini berarti Anda mengaturnya untuk setiap panggilan ke GenerateAnswer.
Dari kerangka bot, atur skor sebagai bagian dari objek opsi dengan C# atau Node.js.
Meningkatkan skor keyakinan
Untuk meningkatkan skor keyakinan respons tertentu terhadap kueri pengguna, Anda dapat menambahkan kueri pengguna ke pangkalan pengetahuan sebagai pertanyaan alternatif tentang respons tersebut. Anda juga dapat menggunakan perubahan kata yang tidak peka huruf besar/kecil untuk menambahkan sinonim ke kata kunci di KB Anda.
Skor kepercayaan yang serupa
Saat beberapa respons memiliki skor keyakinan yang sama, kemungkinan kueri terlalu umum dan karenanya cocok dengan kemungkinan yang sama dengan beberapa jawaban. Cobalah untuk menyusun tanya jawab Anda dengan lebih baik sehingga setiap entitas tanya jawab memiliki niat yang berbeda.
Perbedaan skor keyakinan antara pengujian dan produksi
Skor keyakinan dari jawaban dapat berubah sedikit antara versi pengujian dan diterbitkan dari pangkalan pengetahuan meskipun kontennya sama. Ini karena konten pengujian dan basis pengetahuan yang diterbitkan terletak di indeks Azure AI Search yang berbeda.
Indeks tes menyimpan semua pasangan QnA dari basis pengetahuan Anda. Saat mengkueri indeks pengujian, kueri berlaku untuk seluruh indeks, lalu hasil dibatasi untuk partisi untuk pangkalan pengetahuan tertentu tersebut. Jika hasil kueri pengujian berdampak negatif pada kemampuan Anda memvalidasi pangkalan pengetahuan, Anda dapat:
- atur basis pengetahuan Anda menggunakan salah satu hal berikut:
- 1 sumber daya dibatasi hingga 1 KB: batasi satu sumber daya QnA Anda (dan indeks pengujian Azure AI Search yang dihasilkan) ke satu basis pengetahuan.
- 2 sumber daya - 1 untuk pengujian, 1 untuk produksi: memiliki dua sumber daya QnA Maker, menggunakan satu untuk pengujian (dengan indeks pengujian dan produksi sendiri) dan satu untuk produk (juga memiliki indeks pengujian dan produksi sendiri)
- dan, selalu gunakan parameter yang sama, seperti atas saat mengkueri pangkalan pengetahuan pengujian dan produksi Anda
Saat Anda menerbitkan pangkalan pengetahuan, konten pertanyaan dan jawaban dari pangkalan pengetahuan Anda berpindah dari indeks pengujian ke indeks produksi di pencarian Azure. Lihat cara kerja operasi penerbitan.
Jika Anda memiliki basis pengetahuan di wilayah yang berbeda, setiap wilayah menggunakan indeks Azure AI Search sendiri. Karena indeks yang berbeda digunakan, skornya tidak akan sama persis.
Tidak ditemukan kecocokan
Saat tidak ada kecocokan yang baik ditemukan oleh pembuat peringkat, skor keyakinan 0,0 atau "Tidak Ada" ditampilkan dan respons default adalah "Tidak ada kecocokan yang baik ditemukan di KB". Anda dapat mengganti respons default ini di bot atau kode aplikasi yang memanggil titik akhir. Sebagai alternatif, Anda juga dapat mengatur respons penggantian di Azure, dan ini mengubah default untuk semua basis pengetahuan yang diimplementasikan dalam layanan QnA Maker tertentu.