Kontainer ucapan ke teks kustom dengan Docker
Kontainer ucapan ke teks kustom mentranskripsikan rekaman ucapan atau audio batch real time dengan hasil perantara. Anda dapat menggunakan model kustom yang Anda buat di portal ucapan kustom. Dalam artikel ini, Anda mempelajari cara mengunduh, menginstal, dan menjalankan kontainer ucapan ke teks kustom.
Untuk informasi selengkapnya tentang prasyarat, memvalidasi bahwa kontainer sedang berjalan, menjalankan beberapa kontainer pada host yang sama, dan menjalankan kontainer yang terputus, lihat Menginstal dan menjalankan kontainer Ucapan dengan Docker.
Gambar kontainer
Gambar kontainer ucapan ke teks kustom untuk semua versi dan lokal yang didukung dapat ditemukan pada sindikat Microsoft Container Registry (MCR ). Itu berada di dalam repositori azure-cognitive-services/speechservices/ dan dinamai custom-speech-to-text.

Nama gambar kontainer yang sepenuhnya memenuhi syarat adalah, mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text. Tambahkan versi tertentu atau tambahkan :latest untuk mendapatkan versi terbaru.
| Versi | Jalur |
|---|---|
| terbaru | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.10.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.10.0-amd64 |
Semua tag, kecuali latest, berada dalam format berikut dan peka huruf besar/kecil:
<major>.<minor>.<patch>-<platform>-<prerelease>
Catatan
locale dan voice untuk kontainer ucapan ke teks kustom ditentukan oleh model kustom yang diserap oleh kontainer.
Tag juga tersedia dalam format JSON untuk kenyamanan Anda. Isinya mencakup jalur kontainer dan daftar tag. Tag tidak diurutkan menurut versi, tetapi "latest" selalu disertakan di akhir daftar seperti yang ditunjukkan dalam cuplikan ini:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
<--redacted for brevity-->
"4.4.0-amd64",
"4.5.0-amd64",
"4.6.0-amd64",
"4.7.0-amd64",
"4.8.0-amd64",
"4.9.0-amd64",
"4.10.0-amd64",
"latest"
]
}
Dapatkan gambar kontainer dengan penarikan docker
Anda memerlukan prasyarat termasuk perangkat keras yang diperlukan. Lihat juga alokasi sumber daya yang direkomendasikan untuk setiap kontainer Ucapan.
Gunakan perintah penarikan docker untuk mengunduh citra kontainer dari Microsoft Container Registry:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Catatan
locale dan voice untuk kontainer Ucapan kustom ditentukan oleh model kustom yang diserap oleh kontainer.
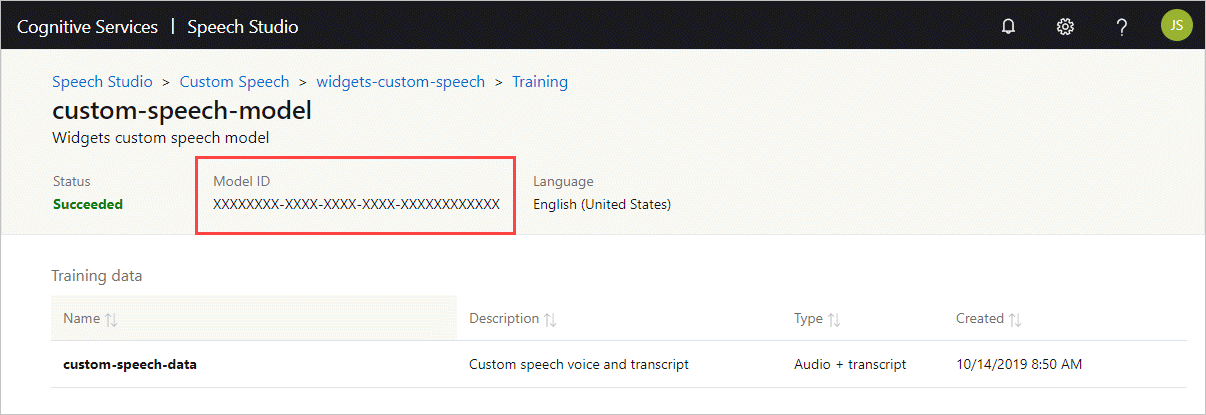
Mendapatkan ID model
Sebelum dapat menjalankan kontainer, Anda perlu mengetahui ID model model kustom Anda atau ID model dasar. Saat menjalankan kontainer, Anda menentukan salah satu ID model untuk diunduh dan digunakan.
Model kustom harus dilatih dengan menggunakan Speech Studio. Untuk informasi tentang cara mendapatkan ID model, lihat siklus hidup model ucapan kustom.
Dapatkan ID Model untuk digunakan sebagai argumen ModelId parameter perintah docker run.
Tampilkan unduhan model
Sebelum menjalankan kontainer, Anda dapat secara opsional mendapatkan informasi model tampilan yang tersedia dan memilih untuk mengunduh model tersebut ke dalam kontainer ucapan ke teks Anda untuk mendapatkan output tampilan akhir yang sangat ditingkatkan. Unduhan model tampilan tersedia dengan kontainer ucapan ke teks kustom versi 3.1.0 dan yang lebih baru.
Catatan
Meskipun Anda menggunakan docker run perintah , kontainer tidak dimulai untuk layanan.
Anda dapat mengkueri atau mengunduh salah satu atau semua jenis model tampilan ini: Penskoran Ulang (Rescore), Tanda Baca (Punct), Segmentasi Ulang (Resegment), dan wfstitn (Wfstitn). Atau, Anda dapat menggunakan opsi FullDisplay (dengan atau tanpa jenis lain) untuk mengkueri atau mengunduh semua jenis model tampilan.
Atur BaseModelLocale untuk mengkueri model tampilan terbaru yang tersedia pada lokal target. Jika Anda menyertakan beberapa jenis model tampilan, perintah mengembalikan model tampilan terbaru yang tersedia untuk setiap jenis. Contohnya:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Atur DisplayLocale untuk mengunduh model tampilan terbaru yang tersedia pada lokal target. Saat Anda mengatur DisplayLocale, Anda juga harus menentukan FullDisplay atau subset model tampilan yang dipisahkan spasi. Perintah mengunduh model tampilan terbaru yang tersedia untuk setiap jenis yang ditentukan. Contohnya:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Atur satu parameter ID model untuk mengunduh model tampilan tertentu: Penskoran Ulang (RescoreId), Tanda Baca (PunctId), segmentasi ulang (ResegmentId), atau wfstitn (WfstitnId). Ini mirip dengan cara Anda akan mengunduh model dasar melalui parameter ModelId. Misalnya, untuk mengunduh model tampilan penskoran ulang, Anda dapat menggunakan perintah berikut dengan parameter RescoreId:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Catatan
Jika Anda mengatur lebih dari satu parameter kueri atau unduhan, perintah akan memprioritaskan dalam urutan ini: BaseModelLocale, ID model, lalu DisplayLocale (hanya berlaku untuk model tampilan).
Jalankan kontainer dengan docker run
Gunakan perintah jalankan docker untuk menjalankan kontainer untuk layanan.
Tabel berikut ini menunjukkan berbagai parameter docker run dan deskripsi terkait:
| Parameter | Deskripsi |
|---|---|
{VOLUME_MOUNT} |
Dudukan volume komputer host, yang digunakan docker untuk mempertahankan model kustom. Contohnya adalah c:\CustomSpeech tempat c:\ drive berada di komputer host. |
{MODEL_ID} |
ID model ucapan atau dasar kustom. Untuk informasi selengkapnya, lihat Mendapatkan ID model. |
{ENDPOINT_URI} |
Titik akhir diperlukan untuk pengukuran dan penagihan. Untuk informasi selengkapnya, lihat argumen penagihan. |
{API_KEY} |
Kunci API diperlukan. Untuk informasi selengkapnya, lihat argumen penagihan. |
Saat Anda menjalankan kontainer ucapan ke teks kustom, konfigurasikan port, memori, dan CPU sesuai dengan persyaratan dan rekomendasi kontainer ucapan ke teks kustom.
Berikut adalah contoh docker run perintah dengan nilai tempat penampung. Anda harus menentukan VOLUME_MOUNTnilai , MODEL_ID, ENDPOINT_URI, dan API_KEY :
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Perintah ini:
- Menjalankan kontainer ucapan ke teks kustom dari gambar kontainer.
- Mengalokasikan 4 core CPU dan memori 8 GB.
- Memuat model ucapan ke teks kustom dari pemasangan input volume, misalnya, C:\CustomSpeech.
- Mengekspos port TCP 5000 dan mengalokasikan pseudo-TTY untuk kontainer.
- Mengunduh model yang diberikan
ModelId(jika tidak ditemukan pada dudukan volume). - Jika model kustom sebelumnya diunduh,
ModelIddiabaikan. - Menghapus kontainer secara otomatis setelah kontainer keluar. Gambar kontainer masih tersedia di komputer host.
Untuk informasi selengkapnya tentang docker run kontainer Ucapan, lihat Menginstal dan menjalankan kontainer Ucapan dengan Docker.
Gunakan kontainer
Kontainer ucapan menyediakan API titik akhir kueri berbasis websocket yang diakses melalui Speech SDK dan Speech CLI. Secara default, Speech SDK dan Speech CLI menggunakan layanan Ucapan publik. Untuk menggunakan kontainer, Anda perlu mengubah metode inisialisasi.
Penting
Saat Anda menggunakan layanan Ucapan dengan kontainer, pastikan untuk menggunakan autentikasi host. Jika Anda mengonfigurasi kunci dan wilayah, permintaan akan masuk ke layanan Ucapan publik. Hasil dari layanan Ucapan mungkin bukan yang Anda harapkan. Permintaan dari kontainer yang terputus akan gagal.
Alih-alih menggunakan konfigurasi inisialisasi Azure-cloud ini:
var config = SpeechConfig.FromSubscription(...);
Gunakan konfigurasi ini dengan host kontainer:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
Alih-alih menggunakan konfigurasi inisialisasi Azure-cloud ini:
auto speechConfig = SpeechConfig::FromSubscription(...);
Gunakan konfigurasi ini dengan host kontainer:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
Alih-alih menggunakan konfigurasi inisialisasi Azure-cloud ini:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Gunakan konfigurasi ini dengan host kontainer:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
Alih-alih menggunakan konfigurasi inisialisasi Azure-cloud ini:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Gunakan konfigurasi ini dengan host kontainer:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
Alih-alih menggunakan konfigurasi inisialisasi Azure-cloud ini:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Gunakan konfigurasi ini dengan host kontainer:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
Alih-alih menggunakan konfigurasi inisialisasi Azure-cloud ini:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Gunakan konfigurasi ini dengan host kontainer:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
Alih-alih menggunakan konfigurasi inisialisasi Azure-cloud ini:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Gunakan konfigurasi ini dengan host kontainer:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
Alih-alih menggunakan konfigurasi inisialisasi Azure-cloud ini:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Gunakan konfigurasi ini dengan titik akhir kontainer:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
Saat Anda menggunakan Speech CLI dalam kontainer, sertakan --host ws://localhost:5000/ opsi . Anda juga harus menentukan --key none untuk memastikan bahwa CLI tidak mencoba menggunakan kunci Ucapan untuk autentikasi. Untuk informasi tentang cara mengonfigurasi Speech CLI, lihat Mulai menggunakan Azure AI Speech CLI.
Coba mulai cepat ucapan ke teks menggunakan autentikasi host alih-alih kunci dan wilayah.
Langkah berikutnya
- Lihat gambaran umum kontainer Ucapan
- Tinjau Mengonfigurasikan kontainer untuk pengaturan konfigurasi
- Gunakan lebih banyak kontainer Azure AI