Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Nota
Fitur ini saat ini dalam pratinjau publik. Pratinjau ini disediakan tanpa perjanjian tingkat layanan, dan tidak disarankan untuk beban kerja produksi. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk informasi lebih lanjut, lihat Supplemental Terms of Use for Microsoft Azure Previews.
Dalam artikel ini, Anda mempelajari cara menggunakan suara langsung dengan AI generatif dan Azure AI Speech di portal Azure AI Foundry.
Prasyarat
- Sebuah langganan Azure. Buat akun gratis.
- Python 3.8 atau versi yang lebih baru. Sebaiknya gunakan Python 3.10 atau yang lebih baru, tetapi diperlukan setidaknya Python 3.8. Jika Anda tidak memiliki versi Python yang sesuai yang terinstal, Anda dapat mengikuti instruksi dalam Tutorial Python Visual Studio Code untuk cara term mudah menginstal Python pada sistem operasi Anda.
- Sebuah sumber daya Azure AI Foundry yang dibuat di salah satu wilayah yang didukung. Untuk informasi selengkapnya tentang ketersediaan wilayah, lihat dokumentasi ringkasan Voice Live API.
Petunjuk / Saran
Untuk menggunakan Voice Live API, Anda tidak perlu menyebarkan model audio dengan sumber daya Azure AI Foundry Anda. Voice Live API dikelola sepenuhnya, dan model digunakan secara otomatis untuk Anda. Untuk informasi selengkapnya tentang ketersediaan model, lihat dokumentasi ringkasan Voice Live API.
Coba suara secara langsung di platform percobaan suara
Untuk mencoba demo langsung suara, ikuti langkah-langkah berikut:
Buka proyek Anda di Azure AI Foundry.
Pilih Playgrounds dari panel kiri.
Di petak taman bermain Ucapan, pilih Coba taman bermain Ucapan.
Pilih Kemampuan ucapan menurut skenario>Suara langsung.
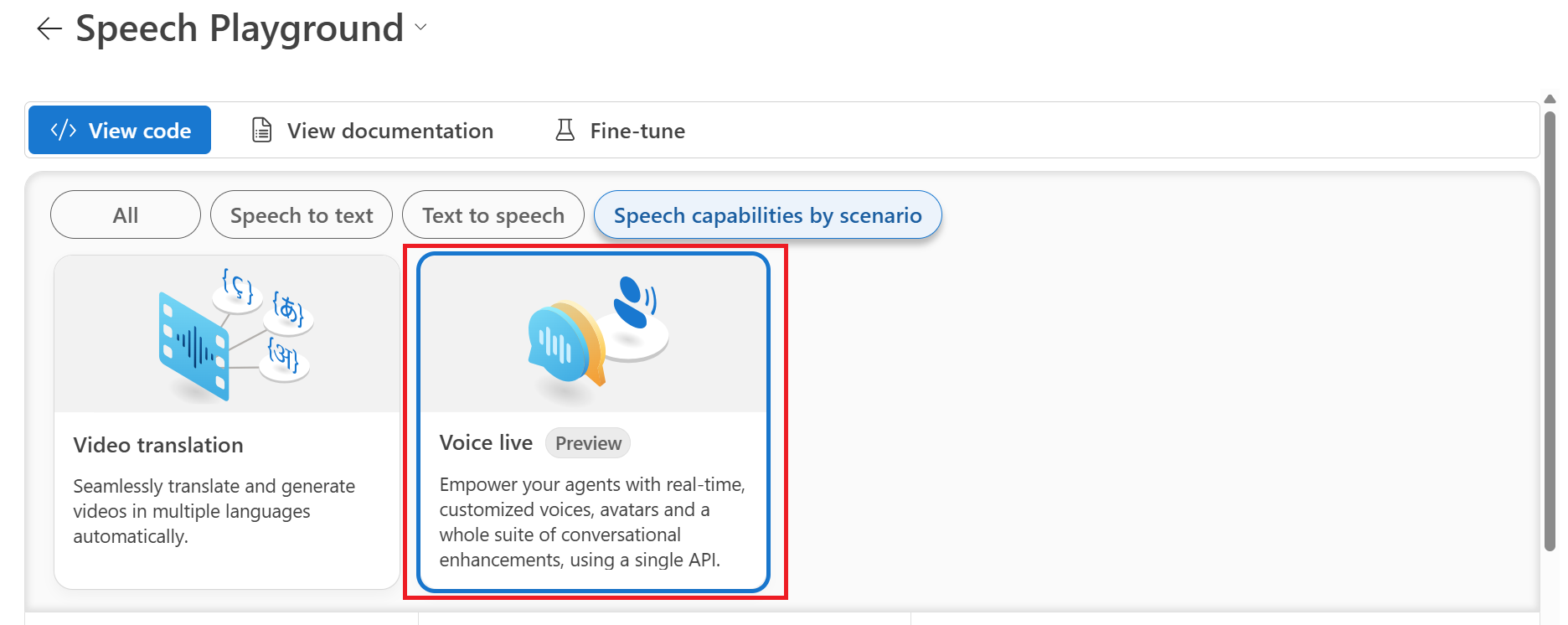
Pilih skenario sampel, seperti Obrolan santai.
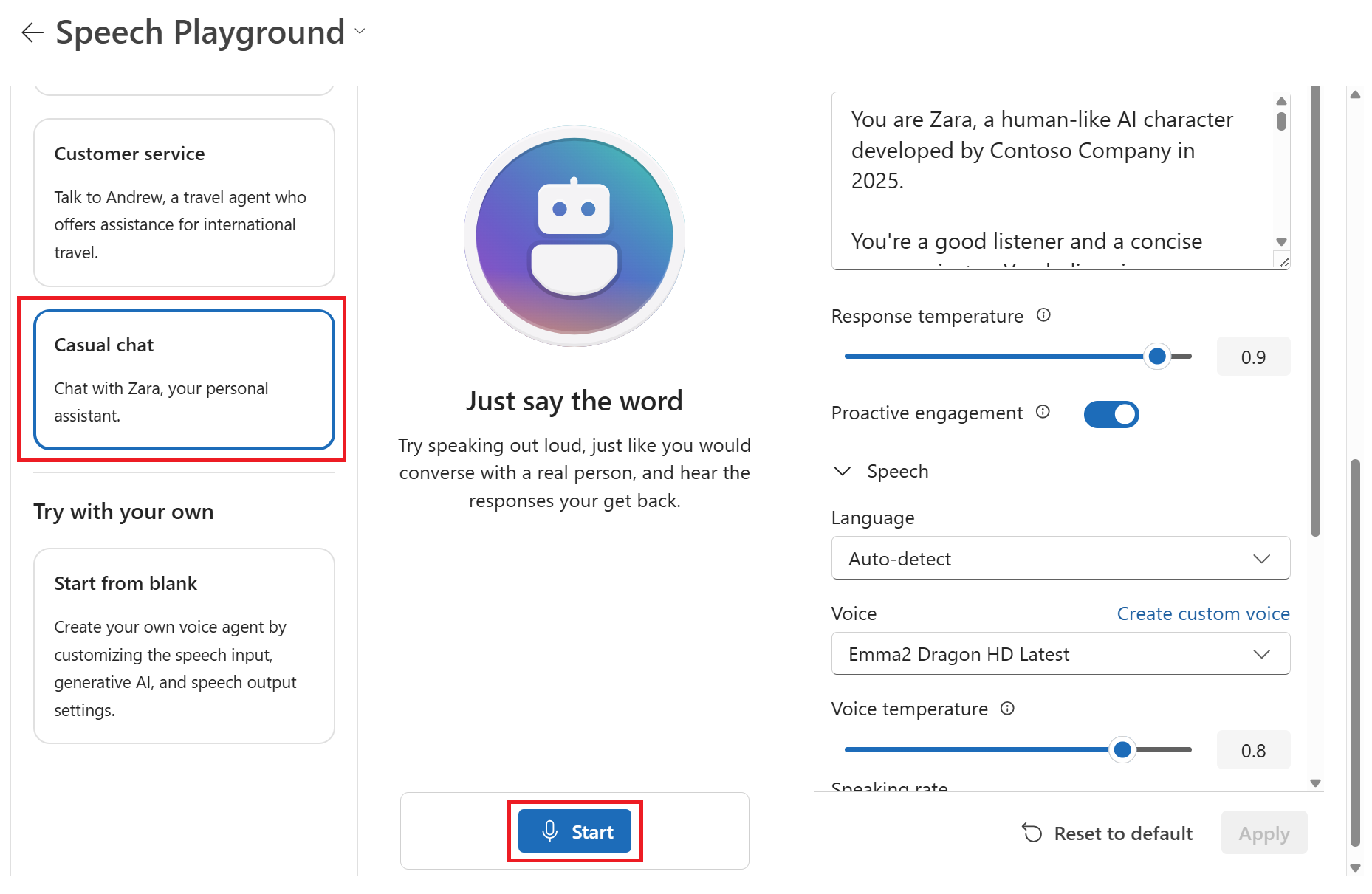
Pilih Mulai untuk mulai mengobrol dengan agen obrolan.
Pilih Akhiri untuk mengakhiri sesi obrolan.
Pilih model AI generatif baru dari daftar drop-down melalui Konfigurasi>GenAI>Model AI Generatif.
Nota
Anda juga dapat memilih agen yang Anda konfigurasi di lingkungan Agen.
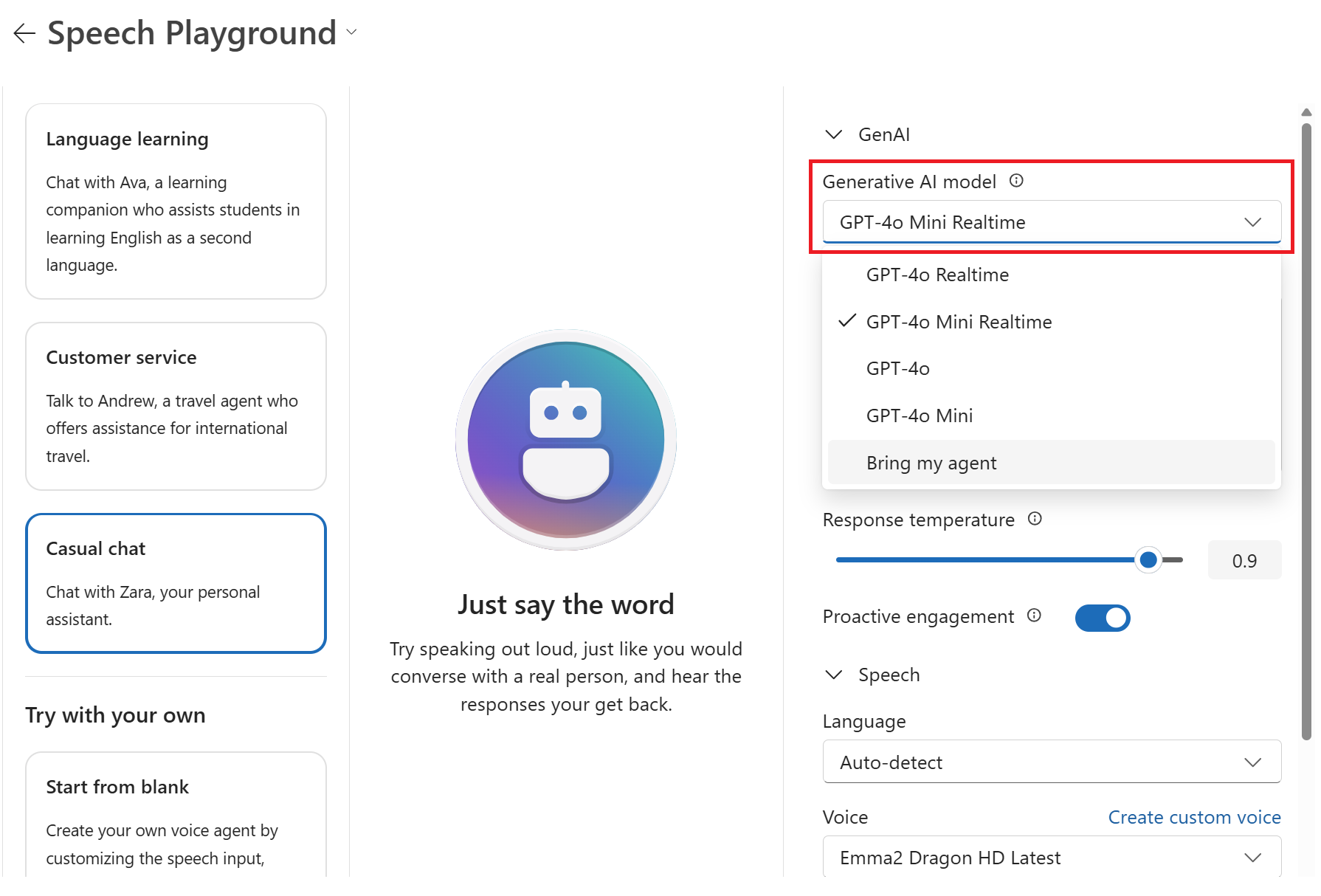
Edit pengaturan lain sesuai kebutuhan, seperti instruksi Respons, Suara, dan Tingkat bicara.
Pilih Mulai untuk mulai berbicara lagi dan pilih Akhiri untuk mengakhiri sesi obrolan.



Prasyarat
- Sebuah langganan Azure. Buat akun gratis.
- Python 3.8 atau versi yang lebih baru. Sebaiknya gunakan Python 3.10 atau yang lebih baru, tetapi diperlukan setidaknya Python 3.8. Jika Anda tidak memiliki versi Python yang sesuai yang terinstal, Anda dapat mengikuti instruksi dalam Tutorial Python Visual Studio Code untuk cara term mudah menginstal Python pada sistem operasi Anda.
- Sebuah sumber daya Azure AI Foundry yang dibuat di salah satu wilayah yang didukung. Untuk informasi selengkapnya tentang ketersediaan wilayah, lihat dokumentasi ringkasan Voice Live API.
Petunjuk / Saran
Untuk menggunakan Voice Live API, Anda tidak perlu menyebarkan model audio dengan sumber daya Azure AI Foundry Anda. Voice Live API dikelola sepenuhnya, dan model digunakan secara otomatis untuk Anda. Untuk informasi selengkapnya tentang ketersediaan model, lihat dokumentasi ringkasan Voice Live API.
Prasyarat ID Microsoft Entra
Untuk autentikasi tanpa kunci yang direkomendasikan dengan ID Microsoft Entra, Anda perlu:
- Instal Azure CLI yang digunakan untuk autentikasi tanpa kunci dengan ID Microsoft Entra.
- Tetapkan peran
Cognitive Services Userke akun pengguna Anda. Anda dapat menetapkan peran di portal Microsoft Azure di bawah Kontrol akses (IAM)>Menambahkan penetapan peran.
Pengaturan
Buat folder
voice-live-quickstartbaru dan buka folder mulai cepat dengan perintah berikut:mkdir voice-live-quickstart && cd voice-live-quickstartBuat lingkungan virtual. Jika Anda sudah menginstal Python 3.10 atau yang lebih tinggi, Anda dapat membuat lingkungan virtual menggunakan perintah berikut:
Mengaktifkan lingkungan Python berarti bahwa ketika Anda menjalankan
pythonataupipdari baris perintah, Anda kemudian menggunakan interpreter Python yang terkandung dalam.venvfolder aplikasi Anda. Anda dapat menggunakandeactivateperintah untuk keluar dari lingkungan virtual python, dan nantinya dapat mengaktifkannya kembali saat diperlukan.Petunjuk / Saran
Kami menyarankan agar Anda membuat dan mengaktifkan lingkungan Python baru untuk digunakan untuk menginstal paket yang Anda butuhkan untuk tutorial ini. Jangan instal paket ke dalam penginstalan python global Anda. Anda harus selalu menggunakan lingkungan virtual atau conda saat menginstal paket python, jika tidak, Anda dapat memutuskan penginstalan global Python Anda.
Buat file bernama requirements.txt. Tambahkan paket berikut ke file:
aiohttp==3.11.18 azure-core==1.34.0 azure-identity==1.22.0 certifi==2025.4.26 cffi==1.17.1 cryptography==44.0.3 numpy==2.2.5 pycparser==2.22 python-dotenv==1.1.0 requests==2.32.3 sounddevice==0.5.1 typing_extensions==4.13.2 urllib3==2.4.0 websockets==15.0.1Instal paket:
pip install -r requirements.txtUntuk autentikasi tanpa kunci yang direkomendasikan dengan ID Microsoft Entra, instal
azure-identitypaket dengan:pip install azure-identity
Mengambil informasi sumber daya
Anda perlu mengambil informasi berikut untuk mengautentikasi aplikasi Anda dengan sumber daya Azure AI Foundry Anda:
| Nama variabel | Nilai |
|---|---|
AZURE_VOICE_LIVE_ENDPOINT |
Nilai ini dapat ditemukan di bagian Keys dan Endpoint saat memeriksa sumber daya Anda di portal Azure. |
VOICE_LIVE_MODEL |
Model yang ingin Anda gunakan. Misalnya, gpt-4o atau gpt-4o-mini-realtime-preview. Untuk informasi selengkapnya tentang ketersediaan model, lihat dokumentasi ringkasan Voice Live API. |
AZURE_VOICE_LIVE_API_VERSION |
Versi API yang ingin Anda gunakan. Contohnya, 2025-05-01-preview. |
Pelajari selengkapnya tentang autentikasi tanpa kunci dan mengatur variabel lingkungan.
Mulai percakapan
voice-live-quickstart.pyBuat file dengan kode berikut:from __future__ import annotations import os import uuid import json import asyncio import base64 import logging import threading import numpy as np import sounddevice as sd from collections import deque from dotenv import load_dotenv from azure.identity import DefaultAzureCredential from azure.core.credentials_async import AsyncTokenCredential from azure.identity.aio import DefaultAzureCredential, get_bearer_token_provider from typing import Dict, Union, Literal, Set from typing_extensions import AsyncIterator, TypedDict, Required from websockets.asyncio.client import connect as ws_connect from websockets.asyncio.client import ClientConnection as AsyncWebsocket from websockets.asyncio.client import HeadersLike from websockets.typing import Data from websockets.exceptions import WebSocketException # This is the main function to run the Voice Live API client. async def main() -> None: # Set environment variables or edit the corresponding values here. endpoint = os.environ.get("AZURE_VOICE_LIVE_ENDPOINT") or "https://your-endpoint.azure.com/" model = os.environ.get("VOICE_LIVE_MODEL") or "gpt-4o" api_version = os.environ.get("AZURE_VOICE_LIVE_API_VERSION") or "2025-05-01-preview" api_key = os.environ.get("AZURE_VOICE_LIVE_API_KEY") or "your_api_key" # For the recommended keyless authentication, get and # use the Microsoft Entra token instead of api_key: scopes = "https://cognitiveservices.azure.com/.default" credential = DefaultAzureCredential() token = await credential.get_token(scopes) client = AsyncAzureVoiceLive( azure_endpoint = endpoint, api_version = api_version, token = token.token, #api_key = api_key, ) async with client.connect(model = model) as connection: session_update = { "type": "session.update", "session": { "instructions": "You are a helpful AI assistant responding in natural, engaging language.", "turn_detection": { "type": "azure_semantic_vad", "threshold": 0.3, "prefix_padding_ms": 200, "silence_duration_ms": 200, "remove_filler_words": False, "end_of_utterance_detection": { "model": "semantic_detection_v1", "threshold": 0.01, "timeout": 2, }, }, "input_audio_noise_reduction": { "type": "azure_deep_noise_suppression" }, "input_audio_echo_cancellation": { "type": "server_echo_cancellation" }, "voice": { "name": "en-US-Ava:DragonHDLatestNeural", "type": "azure-standard", "temperature": 0.8, }, }, "event_id": "" } await connection.send(json.dumps(session_update)) print("Session created: ", json.dumps(session_update)) send_task = asyncio.create_task(listen_and_send_audio(connection)) receive_task = asyncio.create_task(receive_audio_and_playback(connection)) keyboard_task = asyncio.create_task(read_keyboard_and_quit()) print("Starting the chat ...") await asyncio.wait([send_task, receive_task, keyboard_task], return_when=asyncio.FIRST_COMPLETED) send_task.cancel() receive_task.cancel() print("Chat done.") # --- End of Main Function --- logger = logging.getLogger(__name__) AUDIO_SAMPLE_RATE = 24000 class AsyncVoiceLiveConnection: _connection: AsyncWebsocket def __init__(self, url: str, additional_headers: HeadersLike) -> None: self._url = url self._additional_headers = additional_headers self._connection = None async def __aenter__(self) -> AsyncVoiceLiveConnection: try: self._connection = await ws_connect(self._url, additional_headers=self._additional_headers) except WebSocketException as e: raise ValueError(f"Failed to establish a WebSocket connection: {e}") return self async def __aexit__(self, exc_type, exc_value, traceback) -> None: if self._connection: await self._connection.close() self._connection = None enter = __aenter__ close = __aexit__ async def __aiter__(self) -> AsyncIterator[Data]: async for data in self._connection: yield data async def recv(self) -> Data: return await self._connection.recv() async def recv_bytes(self) -> bytes: return await self._connection.recv() async def send(self, message: Data) -> None: await self._connection.send(message) class AsyncAzureVoiceLive: def __init__( self, *, azure_endpoint: str | None = None, api_version: str | None = None, token: str | None = None, api_key: str | None = None, ) -> None: self._azure_endpoint = azure_endpoint self._api_version = api_version self._token = token self._api_key = api_key self._connection = None def connect(self, model: str) -> AsyncVoiceLiveConnection: if self._connection is not None: raise ValueError("Already connected to the Voice Live API.") if not model: raise ValueError("Model name is required.") url = f"{self._azure_endpoint.rstrip('/')}/voice-live/realtime?api-version={self._api_version}&model={model}" url = url.replace("https://", "wss://") auth_header = {"Authorization": f"Bearer {self._token}"} if self._token else {"api-key": self._api_key} request_id = uuid.uuid4() headers = {"x-ms-client-request-id": str(request_id), **auth_header} self._connection = AsyncVoiceLiveConnection( url, additional_headers=headers, ) return self._connection class AudioPlayerAsync: def __init__(self): self.queue = deque() self.lock = threading.Lock() self.stream = sd.OutputStream( callback=self.callback, samplerate=AUDIO_SAMPLE_RATE, channels=1, dtype=np.int16, blocksize=2400, ) self.playing = False def callback(self, outdata, frames, time, status): if status: logger.warning(f"Stream status: {status}") with self.lock: data = np.empty(0, dtype=np.int16) while len(data) < frames and len(self.queue) > 0: item = self.queue.popleft() frames_needed = frames - len(data) data = np.concatenate((data, item[:frames_needed])) if len(item) > frames_needed: self.queue.appendleft(item[frames_needed:]) if len(data) < frames: data = np.concatenate((data, np.zeros(frames - len(data), dtype=np.int16))) outdata[:] = data.reshape(-1, 1) def add_data(self, data: bytes): with self.lock: np_data = np.frombuffer(data, dtype=np.int16) self.queue.append(np_data) if not self.playing and len(self.queue) > 10: self.start() def start(self): if not self.playing: self.playing = True self.stream.start() def stop(self): with self.lock: self.queue.clear() self.playing = False self.stream.stop() def terminate(self): with self.lock: self.queue.clear() self.stream.stop() self.stream.close() async def listen_and_send_audio(connection: AsyncVoiceLiveConnection) -> None: logger.info("Starting audio stream ...") stream = sd.InputStream(channels=1, samplerate=AUDIO_SAMPLE_RATE, dtype="int16") try: stream.start() read_size = int(AUDIO_SAMPLE_RATE * 0.02) while True: if stream.read_available >= read_size: data, _ = stream.read(read_size) audio = base64.b64encode(data).decode("utf-8") param = {"type": "input_audio_buffer.append", "audio": audio, "event_id": ""} data_json = json.dumps(param) await connection.send(data_json) except Exception as e: logger.error(f"Audio stream interrupted. {e}") finally: stream.stop() stream.close() logger.info("Audio stream closed.") async def receive_audio_and_playback(connection: AsyncVoiceLiveConnection) -> None: last_audio_item_id = None audio_player = AudioPlayerAsync() logger.info("Starting audio playback ...") try: while True: async for raw_event in connection: event = json.loads(raw_event) print(f"Received event:", {event.get("type")}) if event.get("type") == "session.created": session = event.get("session") logger.info(f"Session created: {session.get('id')}") elif event.get("type") == "response.audio.delta": if event.get("item_id") != last_audio_item_id: last_audio_item_id = event.get("item_id") bytes_data = base64.b64decode(event.get("delta", "")) audio_player.add_data(bytes_data) elif event.get("type") == "error": error_details = event.get("error", {}) error_type = error_details.get("type", "Unknown") error_code = error_details.get("code", "Unknown") error_message = error_details.get("message", "No message provided") raise ValueError(f"Error received: Type={error_type}, Code={error_code}, Message={error_message}") except Exception as e: logger.error(f"Error in audio playback: {e}") finally: audio_player.terminate() logger.info("Playback done.") async def read_keyboard_and_quit() -> None: print("Press 'q' and Enter to quit the chat.") while True: # Run input() in a thread to avoid blocking the event loop user_input = await asyncio.to_thread(input) if user_input.strip().lower() == 'q': print("Quitting the chat...") break if __name__ == "__main__": try: logging.basicConfig( filename='voicelive.log', filemode="w", level=logging.DEBUG, format='%(asctime)s:%(name)s:%(levelname)s:%(message)s' ) load_dotenv() asyncio.run(main()) except Exception as e: print(f"Error: {e}")Masuk ke Azure dengan perintah berikut:
az loginJalankan file Python.
python voice-live-quickstart.pyVoice Live API mulai mengembalikan audio seiring dengan respons awal dari model. Anda dapat mengganggu model dengan berbicara. Masukkan "q" untuk keluar dari percakapan.
Keluaran
Hasil skrip ditampilkan ke konsol. Anda melihat pesan yang menunjukkan status koneksi, aliran audio, dan pemutaran. Audio diputar kembali melalui speaker atau headphone Anda.
Session created: {"type": "session.update", "session": {"instructions": "You are a helpful AI assistant responding in natural, engaging language.","turn_detection": {"type": "azure_semantic_vad", "threshold": 0.3, "prefix_padding_ms": 200, "silence_duration_ms": 200, "remove_filler_words": false, "end_of_utterance_detection": {"model": "semantic_detection_v1", "threshold": 0.1, "timeout": 4}}, "input_audio_noise_reduction": {"type": "azure_deep_noise_suppression"}, "input_audio_echo_cancellation": {"type": "server_echo_cancellation"}, "voice": {"name": "en-US-Ava:DragonHDLatestNeural", "type": "azure-standard", "temperature": 0.8}}, "event_id": ""}
Starting the chat ...
Received event: {'session.created'}
Press 'q' and Enter to quit the chat.
Received event: {'session.updated'}
Received event: {'input_audio_buffer.speech_started'}
Received event: {'input_audio_buffer.speech_stopped'}
Received event: {'input_audio_buffer.committed'}
Received event: {'conversation.item.input_audio_transcription.completed'}
Received event: {'conversation.item.created'}
Received event: {'response.created'}
Received event: {'response.output_item.added'}
Received event: {'conversation.item.created'}
Received event: {'response.content_part.added'}
Received event: {'response.audio_transcript.delta'}
Received event: {'response.audio_transcript.delta'}
Received event: {'response.audio_transcript.delta'}
REDACTED FOR BREVITY
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
q
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Quitting the chat...
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
REDACTED FOR BREVITY
Received event: {'response.audio.delta'}
Received event: {'response.audio.delta'}
Chat done.
Skrip yang Anda jalankan membuat file log bernama voicelive.log di direktori yang sama dengan skrip.
logging.basicConfig(
filename='voicelive.log',
filemode="w",
level=logging.DEBUG,
format='%(asctime)s:%(name)s:%(levelname)s:%(message)s'
)
File log berisi informasi tentang koneksi ke Voice Live API, termasuk data permintaan dan respons. Anda bisa menampilkan file log untuk melihat detail percakapan.
2025-05-09 06:56:06,821:websockets.client:DEBUG:= connection is CONNECTING
2025-05-09 06:56:07,101:websockets.client:DEBUG:> GET /voice-live/realtime?api-version=2025-05-01-preview&model=gpt-4o HTTP/1.1
<REDACTED FOR BREVITY>
2025-05-09 06:56:07,551:websockets.client:DEBUG:= connection is OPEN
2025-05-09 06:56:07,551:websockets.client:DEBUG:< TEXT '{"event_id":"event_5a7NVdtNBVX9JZVuPc9nYK","typ...es":null,"agent":null}}' [1475 bytes]
2025-05-09 06:56:07,552:websockets.client:DEBUG:> TEXT '{"type": "session.update", "session": {"turn_de....8}}, "event_id": null}' [551 bytes]
2025-05-09 06:56:07,557:__main__:INFO:Starting audio stream ...
2025-05-09 06:56:07,810:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,824:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,844:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,874:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,874:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,905:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,926:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,954:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,954:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...///7/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:07,974:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,004:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,035:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:08,035:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
<REDACTED FOR BREVITY>
2025-05-09 06:56:42,957:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAP//", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:42,984:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+/wAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,005:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": .../////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,034:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,034:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...CAAMA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,055:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...CAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,084:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,114:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...9//3/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,114:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...DAAMA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,134:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,165:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAAAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,184:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+//7/", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,214:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": .../////", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,214:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...+/wAA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,245:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAIA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,264:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...AAP//", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,295:websockets.client:DEBUG:> TEXT '{"type": "input_audio_buffer.append", "audio": ...BAAEA", "event_id": ""}' [1346 bytes]
2025-05-09 06:56:43,295:websockets.client:DEBUG:> CLOSE 1000 (OK) [2 bytes]
2025-05-09 06:56:43,297:websockets.client:DEBUG:= connection is CLOSING
2025-05-09 06:56:43,346:__main__:INFO:Audio stream closed.
2025-05-09 06:56:43,388:__main__:INFO:Playback done.
2025-05-09 06:56:44,512:websockets.client:DEBUG:< CLOSE 1000 (OK) [2 bytes]
2025-05-09 06:56:44,514:websockets.client:DEBUG:< EOF
2025-05-09 06:56:44,514:websockets.client:DEBUG:> EOF
2025-05-09 06:56:44,514:websockets.client:DEBUG:= connection is CLOSED
2025-05-09 06:56:44,514:websockets.client:DEBUG:x closing TCP connection
2025-05-09 06:56:44,514:asyncio:ERROR:Unclosed client session
client_session: <aiohttp.client.ClientSession object at 0x00000266DD8E5400>
Konten terkait
- Pelajari selengkapnya tentang Cara menggunakan API langsung suara
- Lihat referensi peristiwa audio