Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penerjemah Kustom Azure AI memungkinkan Anda ke sistem terjemahan build yang mencerminkan terminologi dan gaya bisnis, industri, dan khusus domain Anda. Melatih dan menyebarkan sistem kustom itu mudah dan tidak memerlukan keterampilan pemrograman apa pun. Sistem terjemahan yang disesuaikan terintegrasi dengan mulus ke dalam aplikasi, alur kerja, dan situs web yang ada dan tersedia di Azure melalui layanan MICROSOFT Text translation API berbasis cloud yang sama yang mendukung miliaran terjemahan setiap hari.
Platform ini memungkinkan pengguna untuk membuat dan menerbitkan sistem terjemahan kustom ke dan dari bahasa Inggris. Penerjemah Kustom mendukung lebih dari 60 bahasa yang memetakan langsung ke bahasa yang tersedia untuk terjemahan mesin Neural (NMT). Untuk daftar lengkapnya, lihatDukungan bahasa penerjemah.
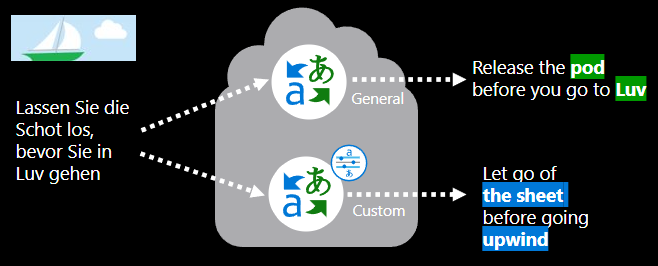
Apakah model terjemahan kustom adalah pilihan yang tepat untuk saya?
Model terjemahan kustom yang terlatih dengan baik menyediakan terjemahan khusus domain yang lebih akurat karena bergantung pada dokumen dalam domain yang diterjemahkan sebelumnya untuk mempelajari terjemahan pilihan. Penerjemah menggunakan istilah dan frasa ini dalam konteks untuk menghasilkan terjemahan yang lancar dalam bahasa target sambil menghormati tata bahasa yang bergantung pada konteks.
Melatih model terjemahan kustom lengkap membutuhkan sejumlah besar data. Jika Anda tidak memiliki setidaknya 10.000 kalimat dokumen yang dilatih sebelumnya, Anda tidak dapat melatih model terjemahan bahasa lengkap. Namun, Anda dapat melatih model yang hanya menggunakan kamus atau menggunakan terjemahan siap pakai berkualitas tinggi yang tersedia dengan API terjemahan Teks.
Apa yang melibatkan pelatihan model terjemahan kustom?
Membangun model terjemahan kustom membutuhkan:
Memahami kasus penggunaan Anda.
Memperoleh data terjemahan dalam domain (lebih disukai terjemahan manusia).
Menilai kualitas terjemahan atau terjemahan bahasa target.
Bagaimana cara mengevaluasi kasus penggunaan saya?
Memiliki kejelasan tentang kasus penggunaan Anda dan seperti apa kesuksesan itu adalah langkah pertama mendapatkan sumber data pelatihan yang mahir. Berikut adalah beberapa pertimbangan:
Apakah hasil yang Anda inginkan ditentukan dan bagaimana hasilnya diukur?
Apakah domain bisnis Anda diidentifikasi?
Apakah Anda memiliki kalimat dalam domain dengan terminologi dan gaya serupa?
Apakah kasus penggunaan Anda melibatkan beberapa domain? Jika ya, haruskah Anda membangun satu sistem terjemahan atau beberapa sistem?
Apakah Anda memiliki persyaratan yang memengaruhi residensi data regional saat tidak aktif dan saat transit?
Apakah target pengguna berada di satu atau beberapa wilayah?
Bagaimana cara mendapatkan data saya?
Menemukan data kualitas dalam domain sering kali merupakan tugas yang menantang yang bervariasi berdasarkan klasifikasi pengguna. Berikut adalah beberapa pertanyaan yang dapat Anda tanyakan pada diri sendiri saat Anda mengevaluasi data apa yang tersedia untuk Anda:
Apakah perusahaan Anda memiliki data terjemahan sebelumnya yang tersedia yang dapat Anda gunakan? Perusahaan sering memiliki banyak data terjemahan yang terakumulasi selama bertahun-tahun menggunakan terjemahan manusia.
Apakah Anda memiliki sejumlah besar data monolingual? Data monolingual adalah data hanya dalam satu bahasa. Jika demikian, bisakah Anda mendapatkan terjemahan untuk data ini?
Bisakah Anda menjelajahi portal online untuk mengumpulkan kalimat sumber dan mensintesis kalimat target?
Apa yang harus saya gunakan untuk materi pelatihan?
| Sumber | Apa fungsinya | Aturan yang harus diikuti |
|---|---|---|
| Dokumen pelatihan bilingual | Mengajarkan sistem terminologi dan gaya Anda. | Jadilah liberal. Terjemahan manusia dalam domain lebih baik daripada terjemahan mesin. Tambahkan dan hapus dokumen sesuai penggunaan dan cobalah untuk meningkatkan skor BLEU. |
| Menyetel dokumen | Melatih parameter Terjemahan Mesin Neural. | Jadilah ketat. Buatlah mereka untuk secara optimal mewakili apa yang akan Anda terjemahkan di masa depan. |
| Dokumen pengujian | Hitung skor BLEU. | Jadilah ketat. Tulis dokumen pengujian agar secara optimal mewakili apa yang Anda rencanakan untuk diterjemahkan di masa mendatang. |
| Kamus frasa | Memaksa terjemahan yang diberikan 100% dari waktu. | Jadilah membatasi. Kamus frasa peka huruf besar/kecil dan kata atau frasa apa pun yang tercantum diterjemahkan dengan cara yang Anda tentukan. Dalam banyak kasus, lebih baik tidak menggunakan kamus frasa dan membiarkan sistem belajar. |
| kamus kalimat | Memaksa terjemahan yang diberikan 100% dari waktu. | Jadilah ketat. Kamus kalimat tidak peka huruf besar/kecil dan baik untuk umum dalam kalimat pendek domain. Agar kecocokan kamus kalimat terjadi, seluruh kalimat yang dikirimkan harus cocok dengan entri kamus sumber. Jika hanya sebagian kalimat yang cocok, entri tidak cocok. |
Apa itu skor BLEU?
BLEU (Bilingual Evaluation Understudy) adalah algoritma untuk mengevaluasi presisi atau akurasi teks yang diterjemahkan mesin dari satu bahasa ke bahasa lain. Penerjemah Kustom Azure AI menggunakan metrik BLEU sebagai salah satu cara menyampaikan akurasi terjemahan.
Skor BLEU adalah angka antara nol dan 100. Skor nol menunjukkan terjemahan berkualitas rendah di mana tidak ada yang cocok dalam terjemahan dengan referensi. Skor 100 menunjukkan terjemahan sempurna yang identik dengan referensi. Tidak perlu mencapai skor 100 - skor BLEU antara 40 dan 60 menunjukkan terjemahan berkualitas tinggi.
Apa yang terjadi jika saya tidak mengirimkan data penyetelan atau pengujian?
Menyetel dan menguji kalimat secara optimal mewakili apa yang Anda rencanakan untuk diterjemahkan di masa depan. Jika Anda tidak mengirimkan data penyetelan atau pengujian apa pun, Penerjemah Kustom Azure AI secara otomatis mengecualikan kalimat dari dokumen pelatihan Anda untuk digunakan sebagai penyetelan dan pengujian data.
| Sistem yang dihasilkan | Pemilihan manual |
|---|---|
| Nyaman. | Memungkinkan penyempurnaan untuk kebutuhan masa depan Anda. |
| Bagus, jika Anda tahu bahwa data pelatihan Anda mewakili apa yang ingin Anda terjemahkan. | Memberikan lebih banyak kebebasan untuk menyusun data pelatihan Anda. |
| Mudah diulang saat Anda membesarkan atau menyusutkan domain. | Memungkinkan lebih banyak data dan cakupan domain yang lebih baik. |
| Mengubah setiap pelatihan yang berjalan. | Tetap statis selama pelatihan berulang |
Bagaimana materi pelatihan diproses oleh Penerjemah Kustom Azure AI?
Untuk mempersiapkan pelatihan, dokumen menjalani serangkaian langkah pemrosesan dan pemfilteran. Pengetahuan tentang proses pemfilteran dapat membantu memahami jumlah kalimat yang ditampilkan serta langkah-langkah yang dapat Anda ambil untuk menyiapkan dokumen pelatihan untuk pelatihan dengan Penerjemah Kustom Azure AI. Langkah-langkah pemfilteran adalah sebagai berikut:
Perataan kalimat
Jika dokumen Anda tidak dalam
XLIFF, ,XLSXTMX, atauALIGNformat, Penerjemah Kustom Azure AI menyelaraskan kalimat dokumen sumber dan target Anda satu sama lain, kalimat demi kalimat. Penerjemah Kustom tidak melakukan penyelarasan dokumen - ini mengikuti konvensi penamaan dokumen Anda untuk menemukan dokumen yang cocok dalam bahasa lain. Dalam teks sumber, Penerjemah Kustom Azure AI mencoba menemukan kalimat yang sesuai dalam bahasa target. Ini menggunakan markup dokumen seperti tag HTML yang disematkan untuk membantu penyelarasan.Jika Anda melihat perbedaan besar antara jumlah kalimat dalam dokumen sumber dan target, dokumen sumber Anda tidak bisa paralel, atau tidak dapat diratakan. Pasangan dokumen dengan perbedaan besar kalimat (>10%) di setiap sisi memerlukan tampilan kedua untuk memastikan pasangan dokumen tersebut memang paralel.
Penyetelan dan pengujian ekstraksi data
Menyetel dan menguji data bersifat opsional. Jika Anda tidak menyediakannya, sistem akan menghapus persentase yang sesuai dari dokumen pelatihan Anda untuk digunakan untuk penyetelan dan pengujian. Penghapusan terjadi secara dinamis sebagai bagian dari proses pelatihan. Karena langkah ini terjadi sebagai bagian dari pelatihan, dokumen yang Anda unggah tidak terpengaruh. Anda dapat melihat jumlah kalimat akhir yang digunakan untuk setiap kategori data—pelatihan, penyetelan, pengujian, dan kamus—di halaman Detail model setelah pelatihan berhasil.
Filter panjang
- Hapus kalimat hanya dengan satu kata di salah satu sisi.
- Hapus kalimat dengan lebih dari 100 kata di salah satu sisi. Bahasa Mandarin, bahasa Jepang, bahasa Korea dikecualikan.
- Hapus kalimat dengan kurang dari tiga karakter. Bahasa Mandarin, bahasa Jepang, bahasa Korea dikecualikan.
- Menghapus kalimat dengan lebih dari 2.000 karakter untuk Bahasa Tionghoa, Jepang, Korea.
- Hapus kalimat yang kurang dari 1% karakter alfanumerik.
- Hapus entri kamus yang berisi lebih dari 50 kata.
Spasi kosong
- Ganti urutan karakter spasi kosong apa pun termasuk tab dan urutan CR/LF dengan karakter satu spasi.
- Menghapus ruang di depan atau di belakang dalam kalimat.
Tanda baca akhir kalimat
Ganti beberapa karakter tanda baca akhir kalimat dengan satu instans. Normalisasi karakter bahasa Jepang.
Mengonversi huruf dan digit lebar penuh menjadi karakter lebar separuh.
Tag XML yang tidak lolos
Mentransformasi tag yang tidak lolos menjadi tag yang lolos:
Etiket Menjadi < & Lt; > & Gt; & & Amp; Karakter tidak valid
Penerjemah Kustom Azure AI menghapus kalimat yang berisi karakter Unicode U+FFFD. Karakter U+FFFD menunjukkan konversi pengodean yang gagal.
Langkah apa yang harus saya ambil sebelum mengunggah data?
- Hapus kalimat dengan pengodean yang tidak valid.
- Hapus karakter kontrol Unicode.
- Ratakan kalimat (sumber ke target), jika memungkinkan.
- Hapus kalimat sumber dan target yang tidak cocok dengan bahasa sumber dan target.
- Ketika kalimat sumber dan target memiliki bahasa campuran, pastikan bahwa kata-kata yang tidak diterjemahkan disengaja, misalnya, nama organisasi dan produk.
- Hindari kesalahan pengajaran ke model Anda dengan memastikan bahwa tata bahasa dan tipografi sudah benar.
- Memiliki satu kalimat sumber yang dipetakan ke satu kalimat target. Meskipun proses pelatihan kami menangani garis sumber dan target yang berisi beberapa kalimat, pemetaan satu-ke-satu adalah praktik terbaik.
Bagaimana cara mengevaluasi hasilnya?
Setelah model Anda berhasil dilatih, Anda dapat melihat skor BLEU model dan skor BLEU model garis besar di halaman detail model. Kami menggunakan kumpulan data pengujian yang sama untuk menghasilkan skor BLEU model dan skor BLEU garis besar. Data ini membantu Anda membuat keputusan berdasarkan informasi mengenai model mana yang akan lebih baik untuk kasus penggunaan Anda.