Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam artikel ini, Anda mempelajari cara menskalakan beban kerja GPU secara otomatis pada Azure Kubernetes Service (AKS) dengan menggunakan metrik GPU yang dikumpulkan oleh pengekspor NVIDIA Data Center GPU Manager (DCGM). Metrik ini diekspos melalui Azure Managed Prometheus dan digunakan oleh Kubernetes Event-Driven Autoscaling (KEDA) untuk secara otomatis menskalakan beban kerja berdasarkan pemanfaatan GPU real time. Solusi ini membantu mengoptimalkan penggunaan sumber daya GPU dan mengontrol biaya operasional dengan menyesuaikan skala aplikasi secara dinamis sebagai respons terhadap permintaan beban kerja.
Prasyarat
-
Azure CLI versi 2.60.0 atau yang lebih baru. Jalankan
az --versionuntuk menemukan versinya. Jika Anda perlu menginstal atau memperbarui, lihat Install Azure CLI. - Helm versi 3.17.0 atau yang lebih baru terinstal.
- kubectl versi 1.28.9 atau yang lebih baru terinstal.
- Kuota GPU NVIDIA di langganan Azure Anda. Contoh ini menggunakan
Standard_NC40ads_H100_v5SKU, tetapi SKU VM NVIDIA H100 lainnya juga didukung.
Sebelum melanjutkan, pastikan kluster AKS Anda dikonfigurasi dengan yang berikut:
- Integrasikan KEDA dengan kluster Azure Kubernetes Service Anda.
- Pantau metrik GPU dari pengekspor NVIDIA DCGM dengan Azure Managed Prometheus dan Azure Managed Grafana.
Pada titik ini, Anda harus memiliki:
- Kluster AKS dengan kumpulan simpul yang dilengkapi GPU NVIDIA, dan GPU yang dapat dijadwalkan telah dikonfirmasi.
- Azure Managed Prometheus dan Grafana diaktifkan pada kluster AKS Anda. KEDA diaktifkan pada kluster Anda.
- Identitas Terkelola yang Ditetapkan oleh Pengguna yang digunakan oleh KEDA menetapkan peran
Monitoring Data Readeryang diberikan cakupan ke Ruang Kerja Azure Monitor yang terkait dengan cluster AKS Anda.
Buat skaler KEDA baru dengan metrik dari pengekspor NVIDIA DCGM
Untuk membuat scaler KEDA, Anda memerlukan dua komponen:
- Titik akhir kueri Prometheus.
- Identitas Terkelola yang Ditetapkan Pengguna.
Mengambil titik akhir kueri Azure Managed Prometheus
Anda dapat menemukan nilai ini di bagian Gambaran Umum ruang kerja Azure Monitor yang dilampirkan ke kluster AKS Anda di portal Microsoft Azure.
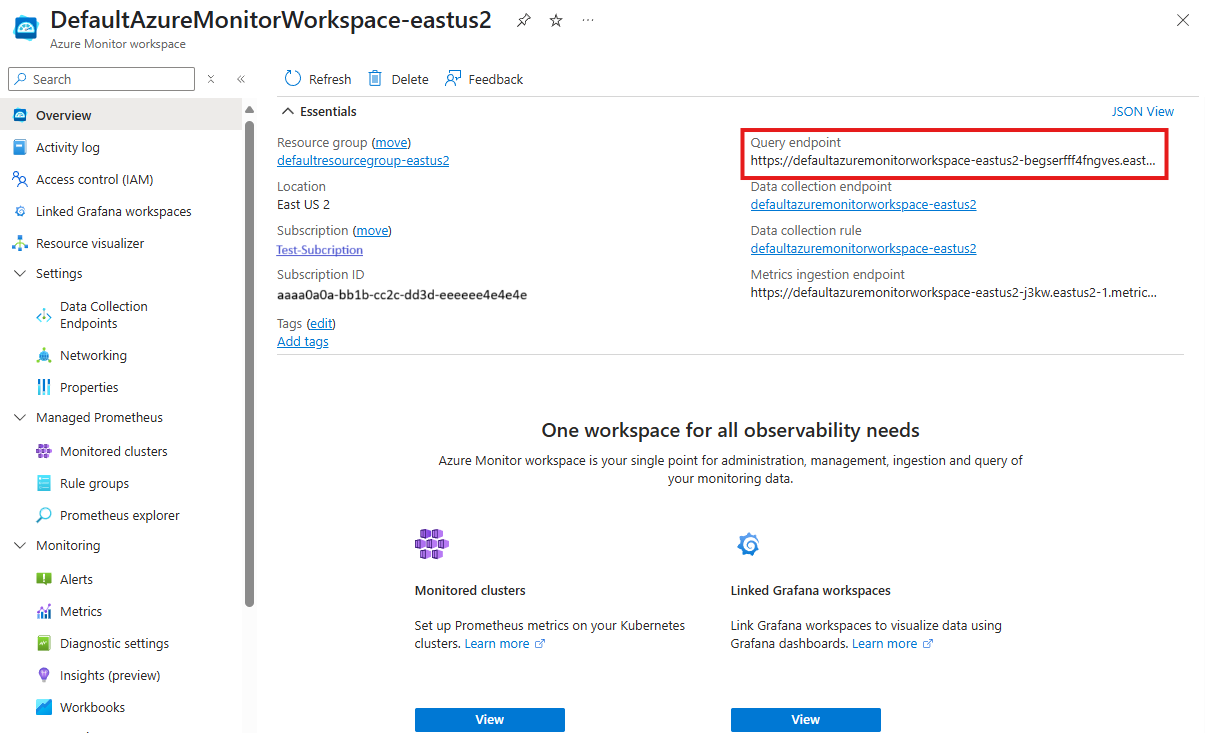
Ekspor titik akhir kueri Azure Managed Prometheus ke variabel lingkungan:
export PROMETHEUS_QUERY_ENDPOINT="https://example.prometheus.monitor.azure.com"
Mengambil Identitas Terkelola yang Ditetapkan Pengguna
Identitas Terkelola yang Ditetapkan Pengguna sebelumnya dibuat mengikuti langkah-langkah integrasi KEDA. Jika diperlukan, muat ulang nilai ini dengan az identity show perintah :
export USER_ASSIGNED_CLIENT_ID="$(az identity show --resource-group $RESOURCE_GROUP --name $USER_ASSIGNED_IDENTITY_NAME --query 'clientId' -o tsv)"
Buat manifes penskala KEDA
Manifes ini membuat TriggerAuthentication dan ScaledObject untuk penskalaan otomatis berdasarkan pemanfaatan GPU yang diukur oleh metrik DCGM_FI_DEV_GPU_UTIL.
Nota
Contoh ini menggunakan DCGM_FI_DEV_GPU_UTIL metrik, yang mengukur pemanfaatan GPU. Metrik lain juga tersedia dari pengekspor DCGM tergantung pada persyaratan beban kerja Anda. Untuk daftar lengkap metrik yang tersedia, lihat dokumentasi Pengekspor NVIDIA DCGM.
| Lapangan | Deskripsi |
|---|---|
metricName |
Menentukan metrik GPU untuk dipantau.
DCGM_FI_DEV_GPU_UTIL melaporkan persentase waktu GPU secara aktif memproses beban kerja. Nilai ini biasanya berkisar antara 0 hingga 100. |
query |
Kueri PromQL yang menghitung penggunaan GPU rata-rata di semua pod dalam deployment my-gpu-workload. Ini memastikan keputusan penskalakan didasarkan pada penggunaan GPU secara keseluruhan, bukan satu pod pun. |
threshold |
Persentase pemanfaatan GPU rata-rata target yang memicu penskalaan. Jika rata-rata melebihi 5%, scaler akan meningkatkan jumlah replika pod. |
activationThreshold |
Pemanfaatan GPU rata-rata minimum yang diperlukan untuk mengaktifkan penskalaan. Jika pemanfaatan di bawah 2%, tindakan penskalaan tidak akan terjadi, mencegah penskalaan yang tidak perlu selama periode aktivitas rendah. |
Buat manifes KEDA berikut:
cat <<EOF > keda-gpu-scaler-prometheus.yaml apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: azure-managed-prometheus-trigger-auth spec: podIdentity: provider: azure-workload identityId: ${USER_ASSIGNED_CLIENT_ID} --- apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: my-gpu-workload spec: scaleTargetRef: name: my-gpu-workload minReplicaCount: 1 maxReplicaCount: 20 triggers: - type: prometheus metadata: serverAddress: ${PROMETHEUS_QUERY_ENDPOINT} metricName: DCGM_FI_DEV_GPU_UTIL query: avg(DCGM_FI_DEV_GPU_UTIL{deployment="my-gpu-workload"}) threshold: '5' activationThreshold: '2' authenticationRef: name: azure-managed-prometheus-trigger-auth EOFTerapkan manifes ini menggunakan
kubectl applyperintah :kubectl apply -f keda-gpu-scaler-prometheus.yaml
Menguji kemampuan penskalakan baru
Buat sampel beban kerja yang menggunakan sumber daya GPU di kluster AKS Anda. Anda dapat memulai dengan contoh berikut:
cat <<EOF > my-gpu-workload.yaml apiVersion: apps/v1 kind: Deployment metadata: name: my-gpu-workload namespace: default spec: replicas: 1 selector: matchLabels: app: my-gpu-workload template: metadata: labels: app: my-gpu-workload spec: tolerations: - key: "sku" operator: "Equal" value: "gpu" effect: "NoSchedule" containers: - name: my-gpu-workload image: mcr.microsoft.com/azuredocs/samples-tf-mnist-demo:gpu command: ["/bin/sh"] args: ["-c", "while true; do python /app/main.py --max_steps=500; done"] resources: limits: nvidia.com/gpu: 1 EOFTerapkan manifes penyebaran ini menggunakan perintah
kubectl applykubectl apply -f my-gpu-workload.yamlNota
Jika saat ini tidak ada simpul GPU yang tersedia, pod akan tetap dalam keadaan
Pendinghingga node disediakan, menunjukkan pesan berikut:Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 3m19s default-scheduler 0/2 nodes are available: 2 Insufficient nvidia.com/gpu. preemption: 0/2 nodes are available: 2 No preemption victims found for incoming pod.Pada akhirnya, autoscaler kluster akan memulai dan menyediaka node GPU yang baru.
Normal TriggeredScaleUp 2m43s cluster-autoscaler pod triggered scale-up: [{aks-gpunp-36854149-vmss 0->1 (max: 2)}]Nota
Tergantung pada ukuran SKU GPU yang disediakan, penyediaan simpul mungkin memerlukan waktu beberapa menit.
Untuk memverifikasi kemajuan, periksa peristiwa Horizontal Pod Autoscaler (HPA) dengan perintah
kubectl describe:kubectl describe hpa my-gpu-workloadOutput akan terlihat seperti berikut:
Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA successfully calculated a replica count from external metric s0-prometheus(&LabelSelector{MatchLabels:map[string]string{scaledobject.keda.sh/name: my-gpu-workload}}) ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica countKonfirmasikan bahwa simpul GPU telah ditambahkan dan pod berjalan dengan
kubectl getperintah :kubectl get nodesOutput akan terlihat seperti berikut:
NAME STATUS ROLES AGE VERSION aks-gpunp-36854149-vmss000005 Ready <none> 4m36s v1.31.7 aks-nodepool1-34179260-vmss000002 Ready <none> 26h v1.31.7 aks-nodepool1-34179260-vmss000003 Ready <none> 26h v1.31.7
Menurunkan skala kumpulan simpul GPU
Untuk menurunkan skala kumpulan simpul GPU, hapus penyebaran beban kerja Anda menggunakan kubectl delete perintah :
kubectl delete deployment my-gpu-workload
Nota
Anda dapat mengonfigurasi kumpulan simpul untuk menurunkan skala ke nol dengan mengaktifkan autoscaler kluster dan mengatur min-count ke 0 pada waktu pembuatan kumpulan simpul. Contohnya:
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name gpunp \
--node-count 1 \
--node-vm-size Standard_NC40ads_H100_v5 \
--node-taints sku=gpu:NoSchedule \
--enable-cluster-autoscaler \
--min-count 0 \
--max-count 3
Langkah selanjutnya
- Sebarkan beban kerja GPU multi-instans (MIG) di AKS.
- Jelajahi KAITO di AKS untuk inferensi dan penyempurnaan AI.
- Pelajari selengkapnya tentang kluster Ray di AKS.
Berkolaborasi dengan kami di GitHub
Sumber untuk konten ini dapat ditemukan di GitHub, yang juga dapat Anda gunakan untuk membuat dan meninjau masalah dan menarik permintaan. Untuk informasi selengkapnya, lihat panduan kontributor kami.

Azure Kubernetes Service