Peluasan skala Azure Analysis Services
Dengan peluasan skala, kueri klien dapat didistribusikan di antara beberapa replika kueri dalam kumpulan kueri, mengurangi waktu respons selama beban kerja kueri tinggi. Anda juga dapat memisahkan pemrosesan dari kumpulan kueri, memastikan kueri klien tidak terpengaruh secara merugikan oleh operasi pemrosesan. Peluasan skala dapat dikonfigurasi di portal Azure atau dengan menggunakan API REST Azure Analysis Services.
Peluasan skala tersedia untuk server di tingkat harga Standar. Setiap replika kueri ditagih dengan tarif yang sama dengan server Anda. Semua replika kueri dibuat di wilayah yang sama dengan server Anda. Jumlah replika kueri yang dapat Anda konfigurasikan dibatasi oleh wilayah tempat server Anda berada. Untuk mempelajari lebih lanjut, lihat Ketersediaan menurut wilayah. Peluasan skala tidak meningkatkan jumlah memori yang tersedia untuk server Anda. Untuk menambah memori, Anda perlu meningkatkan paket Anda.
Mengapa peluasan skala?
Dalam penyebaran server yang khas, satu server berfungsi sebagai server pemrosesan dan server kueri. Jika jumlah kueri klien terhadap model di server Anda melebihi Unit Pemrosesan Kueri (QPU) untuk paket server, atau pemrosesan model terjadi bersamaan dengan beban kerja kueri yang tinggi, performa dapat menurun.
Dengan peluasan skala, Anda dapat membuat kumpulan kueri dengan hingga tujuh sumber daya replika kueri lagi (total delapan, termasuk server utama Anda). Anda dapat menskalakan jumlah replika di kumpulan kueri untuk memenuhi permintaan QPU pada saat kritis, dan Anda dapat memisahkan server pemrosesan dari kumpulan kueri kapan saja.
Terlepas dari jumlah replika kueri yang Anda miliki di kumpulan kueri, beban kerja pemrosesan tidak didistribusikan di antara replika kueri. Server utama berfungsi sebagai server pemrosesan. Replika kueri hanya melayani kueri terhadap database model yang disinkronkan antara server utama dan setiap replika di kumpulan kueri.
Saat Anda meluaskan skala, diperlukan waktu hingga lima menit agar replika kueri baru ditambahkan secara bertahap ke kumpulan kueri. Saat semua replika kueri baru aktif dan berjalan, sambungan klien baru akan diseimbangkan muatan di seluruh sumber daya di kumpulan kueri. Koneksi klien yang ada tidak diubah dari sumber daya yang saat ini tersambung dengannya. Saat Anda menskalakan, koneksi klien yang ada ke sumber daya kumpulan kueri yang sedang dihapus dari kumpulan kueri dihentikan. Klien dapat menyambungkan kembali ke sumber daya kumpulan kueri yang tersisa.
Cara kerjanya
Saat Anda mengonfigurasi peluasan skala untuk pertama kalinya, database model di server utama Anda secara otomatis disinkronkan dengan replika baru di kumpulan kueri baru. Sinkronisasi secara otomatis hanya terjadi sekali. Selama sinkronisasi otomatis, file data server utama (dienkripsi saat tidak aktif di penyimpanan blob) disalin ke lokasi kedua, juga dienkripsi saat tidk aktif di penyimpanan blob. Replika di kumpulan kueri kemudian dihidrasi dengan data dari set file kedua.
Meskipun sinkronisasi otomatis dilakukan hanya ketika Anda menskalakan server untuk pertama kalinya, Anda juga dapat melakukan sinkronisasi manual. Sinkronisasi memastikan data pada replika di kumpulan kueri cocok dengan server utama. Saat memproses (merefresh) model di server utama, sinkronisasi harus dilakukan setelah operasi pemrosesan selesai. Sinkronisasi ini menyalin data yang diperbarui dari file server utama di penyimpanan blob ke set file kedua. Replika di kumpulan kueri kemudian dihidrasi dengan data yang diperbarui dari set file kedua dalam penyimpanan blob.
Saat Anda melakukan operasi peluasan skala berikutnya, misalnya, meningkatkan jumlah replika di kumpulan kueri dari dua menjadi lima, replika baru dihidrasi dengan data dari kumpulan file kedua dalam penyimpanan blob. Tidak ada sinkronisasi. Jika Anda kemudian melakukan sinkronisasi setelah memperluas skala, replika baru di kumpulan kueri akan terhidrasi dua kali - hidrasi redundan. Saat melakukan operasi peluasan skala berikutnya, penting untuk diingat:
Lakukan sinkronisasi sebelum operasi peluasan skala untuk menghindari hidrasi berlebihan dari replika yang ditambahkan. Sinkronisasi bersamaan dan operasi peluasan skala yang berjalan pada saat yang sama tidak diizinkan.
Saat mengotomatiskan pemrosesan dan operasi peluasan skala, penting untuk terlebih dahulu memproses data di server utama, kemudian melakukan sinkronisasi, dan kemudian melakukan operasi peluasan skala. Urutan ini memastikan dampak minimal pada QPU dan sumber daya memori.
Selama operasi peluasan skala, semua server di kumpulan kueri, termasuk server utama, untuk sementara offline.
Sinkronisasi diizinkan bahkan ketika tidak ada replika di kumpulan kueri. Jika Anda melakukan penskalaan dari nol ke satu atau beberapa replika dengan data baru dari operasi pemrosesan di server utama, lakukan sinkronisasi terlebih dahulu tanpa replika di kumpulan kueri, lalu peluasan skala. Menyinkronkan sebelum penskalaan menghindari hidrasi redundan dari replika yang baru ditambahkan.
Saat Anda menghapus database model dari server utama, database tersebut tidak secara otomatis dihapus dari replika di kumpulan kueri. Anda harus melakukan operasi sinkronisasi dengan menggunakan perintah PowerShell Sync-AzAnalysisServicesInstance yang menghapus file untuk database tersebut dari lokasi penyimpanan blob berbagi replika dan kemudian menghapus database model pada replika di kumpulan kueri. Untuk memastikan apakah database model ada pada replika di kumpulan kueri bukan di server utama, pastikan pengaturan Pisahkan server pemrosesan dari kumpulan kueri adalah Ya. Kemudian gunakan SQL Server Management Studio (SSMS) untuk menyambungkan ke server utama menggunakan
:rwkualifikasi untuk melihat apakah database ada. Kemudian sambungkan ke replika di kumpulan kueri dengan menyambungkan tanpa pengualifikasi:rwuntuk melihat apakah database yang sama juga ada. Jika database ada di replika di kumpulan kueri tetapi tidak di server utama, jalankan operasi sinkronisasi.Saat Anda mengganti nama database di server utama, ada langkah lain yang diperlukan untuk memastikan database disinkronkan dengan benar ke replika apa pun. Setelah mengganti nama, lakukan sinkronisasi dengan menggunakan perintah Sync-AzAnalysisServicesInstance yang menetapkan parameter
-Databasedengan nama database lama. Sinkronisasi ini menghapus database dan file dengan nama lama dari replika apa pun. Kemudian lakukan sinkronisasi lain yang menetapkan parameter-Databasedengan nama database baru. Sinkronisasi kedua menyalin database yang baru diberi nama ke set file kedua dan menghidrasi replika apa pun. Sinkronisasi ini tidak dapat dilakukan dengan menggunakan perintah Sinkronkan model di portal.
Mode sinkronisasi
Secara default, replika kueri direhidrasi secara penuh, tidak secara bertahap. Rehidrasi terjadi secara bertahap. Rehidrasi dicopot dan dilampirkan dua sekaligus (dengan asumsi setidaknya ada tiga replika) untuk memastikan setidaknya satu replika disimpan online untuk kueri pada waktu tertentu. Dalam beberapa kasus, klien mungkin perlu menyambung kembali ke salah satu replika online saat proses ini berlangsung. Dengan menggunakan pengaturan ReplicaSyncMode, sekarang Anda dapat menentukan sinkronisasi replika kueri yang terjadi secara paralel. Sinkronisasi paralel memberikan keuntungan berikut:
- Pengurangan waktu sinkronisasi yang signifikan.
- Data di seluruh replika lebih cenderung konsisten selama proses sinkronisasi.
- Karena database disimpan secara online di semua replika selama proses sinkronisasi, klien tidak perlu terhubung kembali.
- Cache dalam memori diperbarui secara bertahap dengan hanya data yang diubah, yang bisa lebih cepat daripada merehidrasi model sepenuhnya.
Mengatur ReplicaSyncMode
Gunakan Management Studio untuk mengatur ReplicaSyncMode di Properti Tingkat Lanjut. Nilai yang mungkin adalah:
1(default): Rehidrasi database replika penuh dalam tahapan (bertambah bertahap).2: optimalkan sinkronisasi secara paralel.
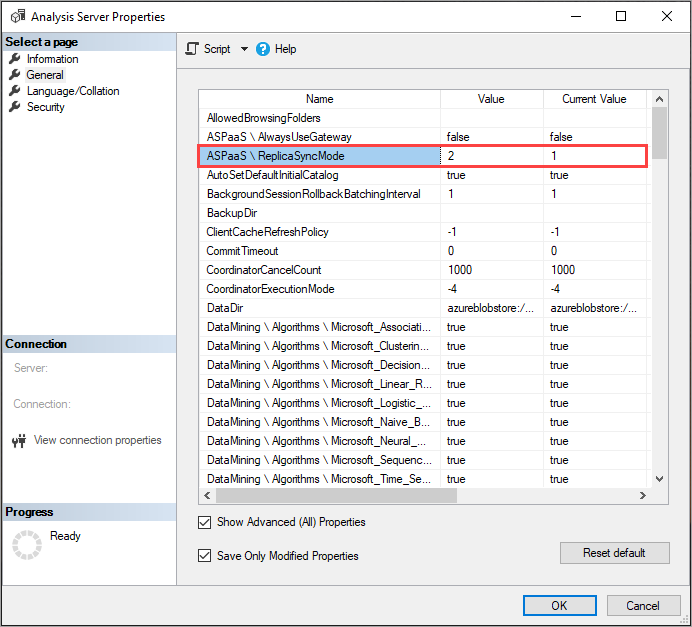
Saat mengatur ReplicaSyncMode=2, tergantung pada berapa banyak cache yang perlu diperbarui, lebih banyak memori yang mungkin digunakan oleh replika kueri. Agar database tetap online dan tersedia untuk kueri, bergantung pada seberapa banyak data yang telah berubah, operasi dapat memerlukan hingga memori dua kali lipat pada replika karena segmen lama dan baru disimpan dalam memori secara bersamaan. Simpul replika memiliki alokasi memori yang sama dengan simpul utama, dan biasanya ada memori tambahan pada simpul utama untuk operasi refresh, sehingga mungkin tidak mungkin replika akan kehabisan memori. Selain itu, skenario umum adalah bahwa database secara bertahap diperbarui pada simpul utama, dan oleh karena itu persyaratan untuk menggandakan memori seharusnya tidak umum. Jika operasi Sinkronisasi memang mengalami kesalahan kehabisan memori, operasi akan mencoba kembali menggunakan teknik default (lampirkan/lepaskan dua per satu).
Pemrosesan terpisah dari kumpulan kueri
Untuk performa maksimum untuk pemrosesan dan operasi kueri, Anda dapat memilih untuk memisahkan server pemrosesan dari kumpulan kueri. Saat dipisahkan, sambungan klien baru ditetapkan ke replika kueri di kumpulan kueri saja. Jika operasi pemrosesan hanya membutuhkan waktu yang singkat, Anda dapat memilih untuk memisahkan server pemrosesan dari kumpulan kueri hanya untuk jumlah waktu yang diperlukan untuk melakukan operasi pemrosesan dan sinkronisasi, lalu memasukkannya kembali ke dalam kumpulan kueri. Memisahkan server pemrosesan dari kumpulan kueri atau menambahkannya kembali ke kumpulan kueri dapat memakan waktu hingga lima menit agar operasi selesai.
Memantau penggunaan QPU
Untuk menentukan apakah perlu peluasan skala untuk server Anda, pantau metrik server Anda di portal Azure. Jika QPU Anda sering mencapai batas maksimal, itu berarti jumlah kueri terhadap model melebihi batas QPU untuk paket Anda. Metrik panjang antrean pekerjaan kumpulan kueri juga meningkat saat jumlah kueri dalam antrean kumpulan alur kueri melebihi QPU yang tersedia.
Metrik bagus lainnya untuk diperhatikan adalah QPU rata-rata oleh ServerResourceType. Metrik ini membandingkan QPU rata-rata untuk server utama dengan kumpulan kueri.
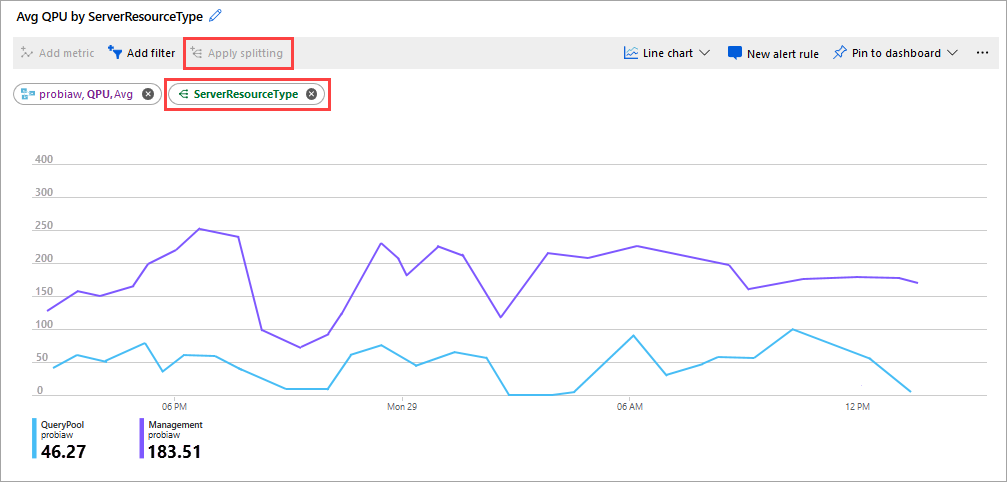
Untuk mengonfigurasi QPU menurut ServerResourceType
- Di bagan garis Metrik, klik Tambahkan metrik.
- Di SUMBER DAYA, pilih server Anda, lalu di NAMESPACE METRIK, pilih Metrik standar Azure Analysis Services, lalu di METRIK, pilih QPU, lalu di AGGREGASI, pilih Rata-rata.
- Klik Terapkan Pemisahan.
- Di NILAI, pilih ServerResourceType.
Pembuatan log diagnostik terperinci
Gunakan Log Azure Monitor untuk diagnostik yang lebih mendetail tentang sumber daya server yang diluaskan skalanya. Dengan log, Anda dapat menggunakan kueri Analitik Log untuk membagi QPU dan memori menurut server dan replika. Untuk informasi selengkapnya, lihat Menganalisis log di ruang kerja Analitik Log. Misalnya kueri, lihat Contoh kueri Kusto.
Mengonfigurasi peluasan skala
Di portal Azure
Di portal, klik Pelusan skala. Gunakan penggeser untuk memilih jumlah server replika kueri. Jumlah replika yang Anda pilih adalah tambahan untuk server yang sudah ada.
Di Pisahkan server pemrosesan dari kumpulan kueri, pilih ya untuk mengecualikan server pemrosesan Anda dari server kueri. Koneksi klien yang menggunakan string sambungan default (tanpa
:rw) dialihkan ke replika di kumpulan kueri.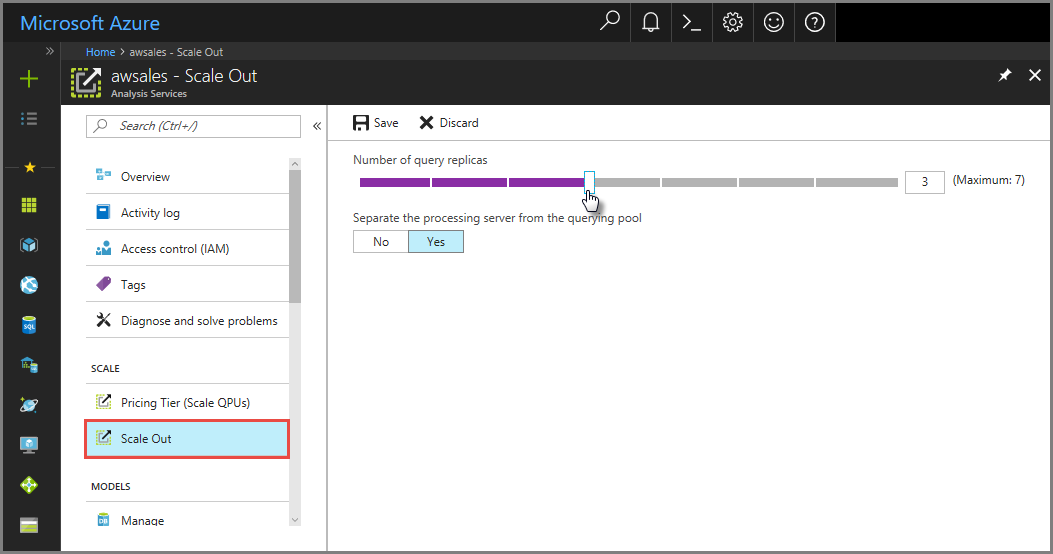
Klik Simpan untuk memprovisikan server replika kueri baru Anda.
Saat Anda mengonfigurasi peluasan skala untuk server pertama kalinya, model di server utama Anda secara otomatis disinkronkan dengan replika di kumpulan kueri. Sinkronisasi otomatis hanya terjadi sekali, saat Anda pertama kali mengonfigurasi peluasan skala ke satu atau beberapa replika. Perubahan berikutnya pada jumlah replika di server yang sama tidak memicu sinkronisasi otomatis lainnya. Sinkronisasi otomatis tidak terjadi lagi bahkan jika Anda mengatur server ke nol replika dan kemudian kembali meluaskan skala ke sejumlah replika.
Menyinkronkan
Operasi sinkronisasi harus dilakukan secara manual atau dengan menggunakan REST API.
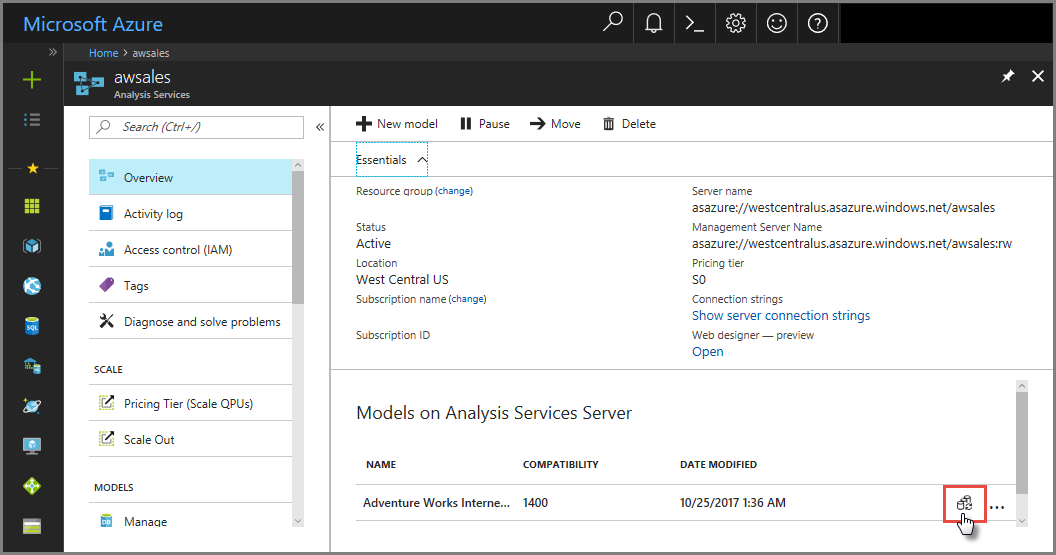
Di portal Azure
Dalam model >Gambaran Umum> Sinkronkan model.
REST API
Gunakan operasi sinkronisasi.
Menyinkronkan model
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
Mendapatkan status sinkronisasi
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
Kode status pengembalian:
| Kode | Deskripsi |
|---|---|
| -1 | Tidak valid |
| 0 | Mereplikasi |
| 1 | Merehidrasi |
| 2 | Selesai |
| 3 | Gagal |
| 4 | Menyelesaikan |
PowerShell
Catatan
Sebaiknya Anda menggunakan modul Azure Az PowerShell untuk berinteraksi dengan Azure. Untuk memulai, lihat Menginstal Azure PowerShell. Untuk mempelajari cara bermigrasi ke modul Az PowerShell, lihat Memigrasikan Azure PowerShell dari AzureRM ke Az.
Sebelum menggunakan PowerShell, pasang atau perbarui modul Azure PowerShell terbaru.
Untuk menjalankan sinkronisasi, gunakan Sync-AzAnalysisServicesInstance.
Untuk mengatur jumlah replika kueri, gunakan Set-AzAnalysisServicesServer. Tentukan parameter opsional -ReadonlyReplicaCount.
Untuk memisahkan server pemrosesan dari kumpulan kueri, gunakan Set-AzAnalysisServicesServer. Tentukan parameter opsional -DefaultConnectionMode untuk menggunakan Readonly.
Untuk mempelajari lebih lanjut, lihat Menggunakan perwakilan layanan dengan modul Az.AnalysisServices.
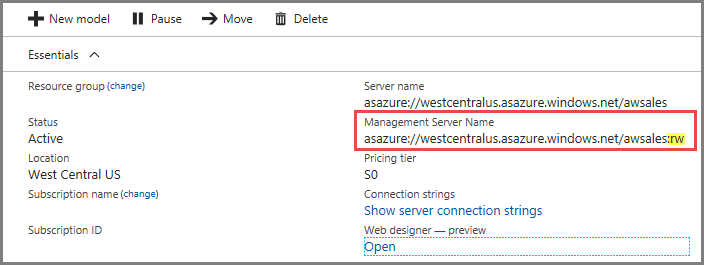
Koneksi
Di halaman Gambaran Umum server Anda, ada dua nama server. Jika Anda belum mengonfigurasi peluasan skala untuk server, kedua nama server berfungsi sama. Setelah mengonfigurasi peluasan skala untuk server, Anda perlu menentukan nama server yang sesuai tergantung pada jenis sambungan.
Untuk sambungan klien pengguna akhir seperti Power BI Desktop, Excel, dan aplikasi kustom, gunakan Nama server.
Untuk Management Studio, Visual Studio, dan string sambungan di PowerShell, Aplikasi fungsi Azure, dan AMO, gunakan Nama server manajemen. Nama server manajemen menyertakan pengualifikasi khusus :rw (baca-tulis). Semua operasi pemrosesan terjadi di server manajemen (utama).
Penyempitan skala, Penurunan skala vs. Peluasan skala
Anda dapat mengubah tingkat harga di server dengan beberapa replika. Tingkat harga yang sama berlaku untuk semua replika. Operasi skala terlebih dahulu menurunkan semua replika sekaligus kemudian memunculkan semua replika pada tingkat harga baru.
Pecahkan masalah
Masalah: Pengguna mendapatkan kesalahan tidak dapat menemukan instans server '<Nama server>' dalam mode koneksi 'ReadOnly'.
Solusi: Saat memilih opsi Pisahkan server pemrosesan dari kumpulan kueri, sambungan klien yang menggunakan string sambungan default (tanpa :rw) dialihkan ke replika kumpulan kueri. Jika replika di kumpulan kueri belum online karena sinkronisasi belum selesai, koneksi klien yang dialihkan bisa gagal. Untuk mencegah sambungan yang gagal, setidaknya harus ada dua server di kumpulan kueri saat melakukan sinkronisasi. Setiap server disinkronkan satu per satu sementara yang lain tetap online. Jika Anda memilih untuk tidak memiliki server pemrosesan di kumpulan kueri selama pemrosesan, Anda dapat memilih untuk menghapusnya dari kumpulan untuk diproses, lalu menambahkannya kembali ke kumpulan setelah pemrosesan selesai, tetapi sebelum sinkronisasi. Gunakan metrik Memori dan QPU untuk memantau status sinkronisasi.
Informasi terkait
Memantau Azure Analysis ServicesMengelola Azure Analysis Services