Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam tutorial ini, Anda akan membuat aplikasi Java Retrieval Augmented Generation (RAG) menggunakan Spring Boot, Azure OpenAI, dan Azure AI Search dan menyebarkannya ke Azure App Service. Aplikasi ini menunjukkan cara menerapkan antarmuka obrolan yang mengambil informasi dari dokumen Anda sendiri dan memanfaatkan layanan AI dalam Azure untuk memberikan jawaban yang akurat dan sadar kontekstual dengan kutipan yang tepat. Solusi ini menggunakan identitas terkelola untuk autentikasi tanpa kata sandi antar layanan.
Petunjuk / Saran
Meskipun tutorial ini menggunakan Spring Boot, konsep inti membangun aplikasi RAG dengan Azure OpenAI dan Azure AI Search berlaku untuk aplikasi web Java apa pun. Jika Anda menggunakan opsi hosting yang berbeda di App Service, seperti Tomcat atau JBoss EAP, Anda dapat menyesuaikan pola autentikasi dan penggunaan Azure SDK yang ditunjukkan di sini ke kerangka kerja pilihan Anda.
Dalam tutorial ini, Anda akan belajar cara:
- Sebarkan aplikasi Spring Boot yang menggunakan pola RAG dengan layanan AI di Azure.
- Konfigurasikan Azure OpenAI dan Azure AI Search untuk pencarian hibrid.
- Unggah dan indeks dokumen untuk digunakan dalam aplikasi yang didukung AI Anda.
- Gunakan identitas terkelola untuk komunikasi layanan-ke-layanan yang aman.
- Uji implementasi RAG Anda secara lokal dengan layanan produksi.
Gambaran umum arsitektur
Sebelum memulai penyebaran, sangat membantu untuk memahami arsitektur aplikasi yang akan Anda bangun. Diagram berikut berasal dari pola kustom RAG untuk Azure AI Search:
diagram 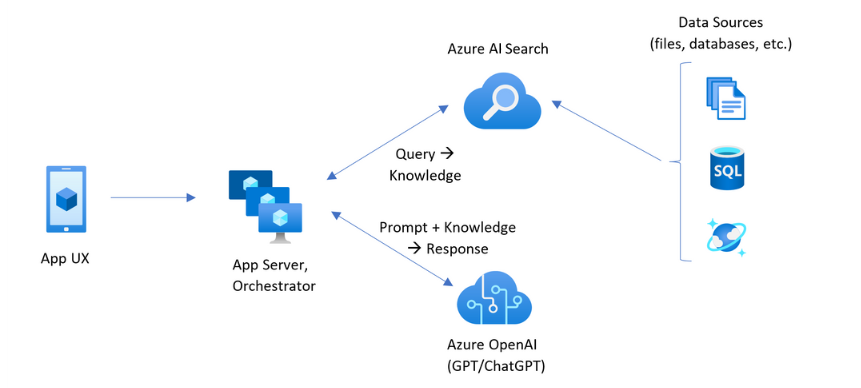
Dalam tutorial ini, aplikasi Blazer di App Service mengurus UX aplikasi dan server aplikasi. Namun, hal ini tidak membuat kueri pengetahuan terpisah untuk Azure AI Search. Sebaliknya, ini memberi tahu Azure OpenAI untuk melakukan kueri pada pengetahuan dengan menetapkan Azure AI Search sebagai sumber data. Arsitektur ini menawarkan beberapa keuntungan utama:
- Vektorisasi Terintegrasi: Kemampuan vektorisasi terintegrasi Azure AI Search memudahkan dan mempercepat pengindeksan seluruh dokumen Anda untuk pencarian, tanpa memerlukan penulisan kode tambahan untuk menghasilkan embedding.
- Simplified API Access: Dengan menggunakan pola Azure OpenAI On Your Data dengan Azure AI Search sebagai sumber data untuk penyelesaian OpenAI Azure, tidak perlu menerapkan pencarian vektor kompleks atau pembuatan penyematan. Ini hanya satu panggilan API dan Azure OpenAI menangani semuanya, termasuk rekayasa cepat dan pengoptimalan kueri.
- Kemampuan Pencarian Tingkat Lanjut: Vektorisasi terintegrasi menyediakan semua yang diperlukan untuk pencarian hibrid tingkat lanjut dengan reranking semantik, yang menggabungkan kekuatan pencocokan kata kunci, kesamaan vektor, dan peringkat bertenaga AI.
- Dukungan Kutipan Lengkap: Respons secara otomatis menyertakan kutipan ke dokumen sumber, membuat informasi dapat diverifikasi dan dapat dilacak.
Prasyarat
- Akun Azure dengan langganan aktif - Buat akun secara gratis.
- GitHub akun untuk menggunakan GitHub Codespaces - Pelajari selengkapnya tentang GitHub Codespaces.
1. Buka sampel dengan Codespace
Cara term mudah untuk memulai adalah dengan menggunakan GitHub Codespaces, yang menyediakan lingkungan pengembangan lengkap dengan semua alat yang diperlukan yang telah diinstal sebelumnya.
Navigasi ke repositori GitHub di https://github.com/Azure-Samples/app-service-rag-openai-ai-search-java.
Pilih tombol Kode, pilih tab Codespaces, dan klik Buat codespace pada utama.
Tunggu beberapa saat agar Codespace Anda diinisialisasi. Setelah siap, Anda akan melihat lingkungan VS Code yang dikustomisasi sepenuhnya di browser Anda.
2. Sebarkan arsitektur contoh
Di terminal, masuk ke Azure menggunakan Azure Developer CLI:
azd auth loginIkuti instruksi untuk menyelesaikan proses autentikasi.
Provisikan sumber daya Azure dengan templat AZD:
azd provisionSaat diminta, berikan jawaban berikut:
Pertanyaan Jawaban Masukkan nama lingkungan baru: Ketik nama unik. Pilih Langganan Azure yang akan digunakan: Pilih langganan. Pilih grup sumber daya yang akan digunakan: Pilih Buat grup sumber daya baru. Pilih lokasi untuk membuat grup sumber daya di: Pilih wilayah mana pun. Sumber daya sebenarnya akan dibuat di East US 2. Masukkan nama untuk grup sumber daya baru: Ketik Enter. Tunggu hingga penerapan selesai. Proses ini akan:
- Buat semua sumber daya Azure yang diperlukan.
- Sebarkan aplikasi ke Azure App Service.
- Konfigurasikan autentikasi layanan ke layanan yang aman menggunakan identitas terkelola.
- Siapkan penetapan peran yang diperlukan untuk akses aman antar layanan.
Nota
Untuk mempelajari selengkapnya tentang cara kerja identitas terkelola, lihat Apa identitas terkelola untuk sumber daya Azure? dan Cara menggunakan identitas terkelola dengan App Service.
Setelah penyebaran berhasil, Anda akan melihat URL untuk aplikasi yang disebarkan. Catat URL ini, tetapi belum mengaksesnya karena Anda masih perlu menyiapkan indeks pencarian.
3. Unggah dokumen dan buat indeks pencarian
Sekarang setelah infrastruktur disebarkan, Anda perlu mengunggah dokumen dan membuat indeks pencarian yang akan digunakan aplikasi:
Di portal Azure, arahkan ke akun penyimpanan yang dibuat selama penyebaran. Nama akan dimulai dengan nama lingkungan yang Anda berikan sebelumnya.
PilihKontainer> data dari menu navigasi kiri dan buka kontainer dokumen.
Unggah dokumen sampel dengan mengklik Unggah. Anda dapat menggunakan dokumen sampel dari folder
sample-docsdi repositori, atau file PDF, Word, atau teks Anda sendiri.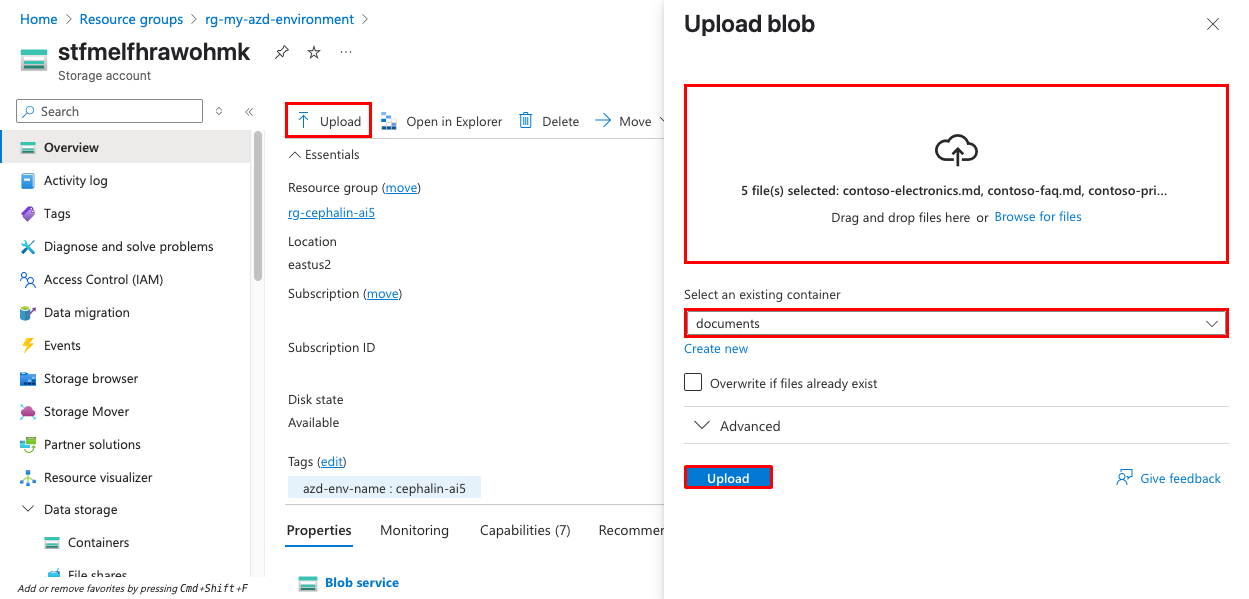
Navigasi ke layanan Azure AI Search Anda di portal Azure.
Pilih Impor data (baru) untuk memulai proses pembuatan indeks pencarian.
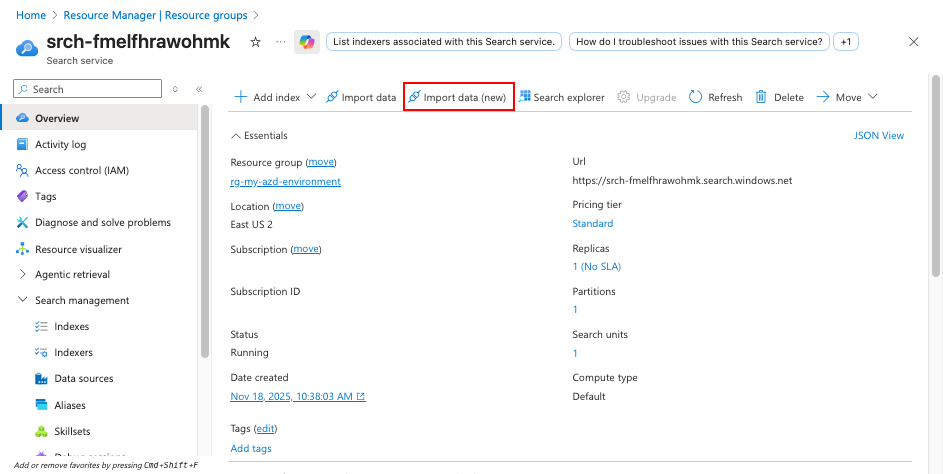
Di langkah Sambungkan ke data Anda :
- Pilih Azure Blob Storage sebagai Sumber Data.
- Pilih RAG.
- Pilih akun penyimpanan Anda dan kontainer dokumen .
- Pilih Autentikasi menggunakan identitas terkelola.
- Pilih Selanjutnya.
Di langkah Vektorisasi teks Anda :
- Pilih layanan OpenAI Azure Anda.
- Pilih text-embedding-ada-002 sebagai model penyematan. Templat AZD sudah menyebarkan model ini untuk Anda.
- Pilih Identitas yang ditetapkan sistem untuk autentikasi.
- Pilih kotak centang pengakuan untuk biaya tambahan.
- Pilih Selanjutnya.
Petunjuk / Saran
Pelajari lebih lanjut tentang pencarian Vector di Azure AI Search dan penyematan Teks di Azure OpenAI.
Di langkah Vektorisasi dan perkaya gambar Anda :
- Pertahankan pengaturan default.
- Pilih Selanjutnya.
Di langkah Pengaturan tingkat lanjut :
- Pastikan Aktifkan peringkat semantik dipilih.
- (Opsional) Pilih jadwal pengindeksan. Ini berguna jika Anda ingin me-refresh indeks Anda secara teratur dengan perubahan file terbaru.
- Pilih Selanjutnya.
Di langkah Tinjau dan buat :
- Salin nilai awalan nama Objek . Ini adalah nama indeks pencarian Anda.
- Pilih Buat untuk memulai proses pengindeksan.
Tunggu hingga proses pengindeksan selesai. Ini mungkin memakan waktu beberapa menit tergantung pada ukuran dan jumlah dokumen Anda.
Untuk menguji impor data, pilih Mulai pencarian dan coba kueri pencarian seperti "Beri tahu saya tentang perusahaan Anda."
Kembali ke terminal Codespace Anda, atur nama indeks pencarian sebagai variabel lingkungan AZD:
azd env set SEARCH_INDEX_NAME <your-search-index-name>Ganti
<your-search-index-name>dengan nama indeks yang Anda salin sebelumnya. AZD menggunakan variabel ini dalam penyebaran berikutnya untuk mengatur pengaturan aplikasi App Service.
4. Uji aplikasi dan sebarkan
Jika Anda lebih suka menguji aplikasi secara lokal sebelum atau sesudah penyebaran, Anda dapat menjalankannya langsung dari Codespace Anda:
Di terminal Codespace Anda, dapatkan nilai lingkungan AZD:
azd env get-valuesBuka src/main/resources/application.properties. Gunakan output terminal untuk memperbarui nilai berikut di masing-masing tempat penampung
<input-manually-for-local-testing>.azure.openai.endpointazure.search.urlazure.search.index.name
Masuk ke Azure dengan Azure CLI:
az loginIni memungkinkan pustaka klien Azure Identity dalam kode sampel untuk menerima token autentikasi untuk pengguna yang masuk.
Jalankan aplikasi secara lokal:
mvn spring-boot:runSaat Anda melihat Aplikasi Anda yang berjalan di port 8080 tersedia, pilih Buka di Browser.
Coba ajukan beberapa pertanyaan di antarmuka obrolan. Jika Anda mendapatkan respons, aplikasi Anda berhasil tersambung ke sumber daya OpenAI Azure.
Hentikan server pengembangan dengan Ctrl+C.
Terapkan konfigurasi
SEARCH_INDEX_NAMEbaru di Azure dan sebarkan kode aplikasi sampel:azd up
5. Uji aplikasi RAG yang disebarkan
Dengan aplikasi yang sepenuhnya disebarkan dan dikonfigurasi, Anda sekarang dapat menguji fungsionalitas RAG:
Buka URL aplikasi yang disediakan di akhir penyebaran.
Anda melihat antarmuka obrolan tempat Anda dapat memasukkan pertanyaan tentang konten dokumen yang Anda unggah.
Coba ajukan pertanyaan khusus untuk konten dokumen Anda. Misalnya, jika Anda mengunggah dokumen di folder sample-docs , Anda dapat mencoba pertanyaan-pertanyaan berikut:
- Bagaimana Contoso menggunakan data pribadi saya?
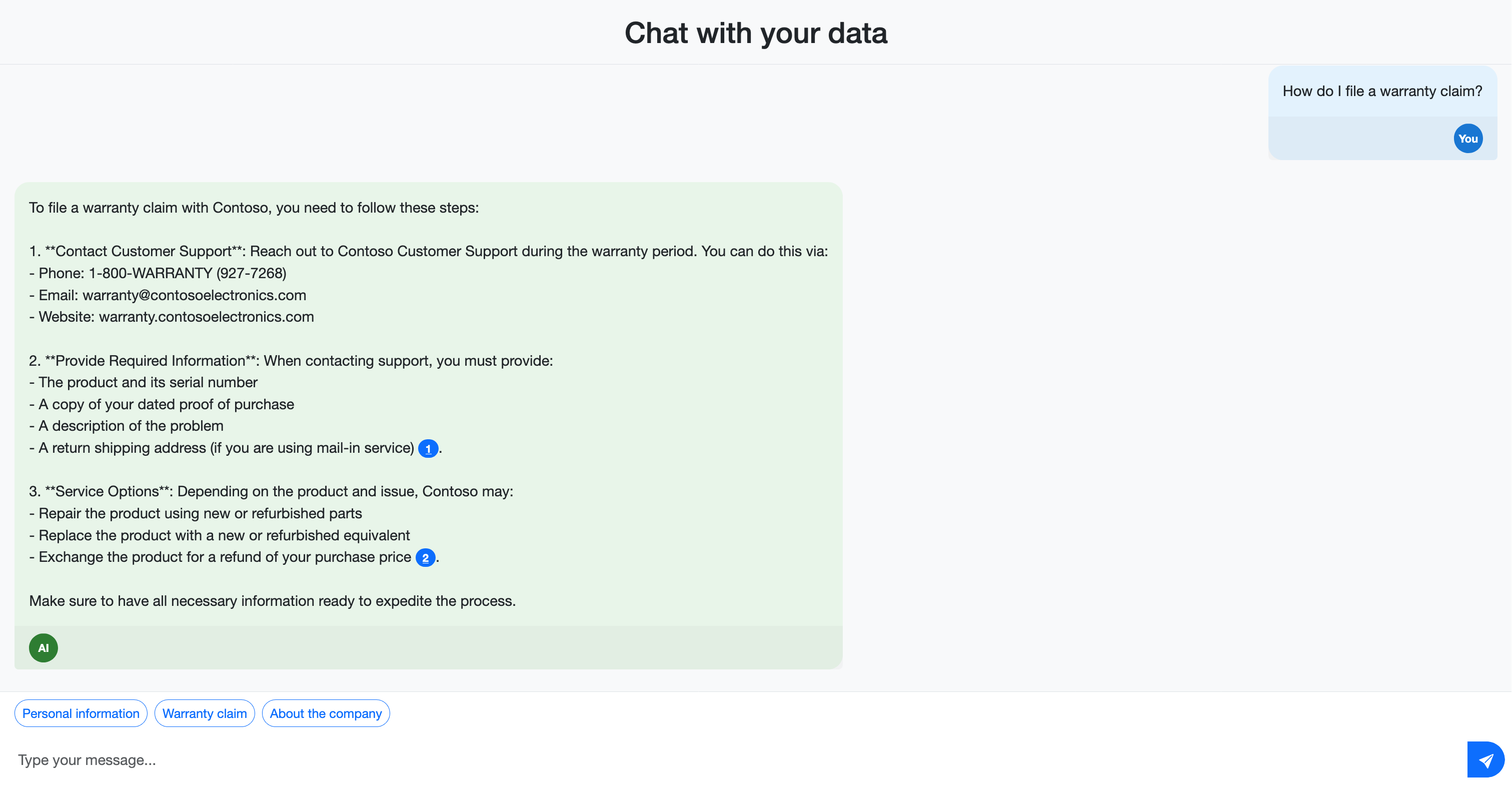
- Bagaimana Anda mengajukan klaim garansi?
Perhatikan bagaimana respons menyertakan kutipan yang mereferensikan dokumen sumber. Kutipan ini membantu pengguna memverifikasi akurasi informasi dan menemukan detail selengkapnya dalam materi sumber.
Uji kemampuan pencarian hibrid dengan mengajukan pertanyaan yang mungkin mendapat manfaat dari berbagai pendekatan pencarian:
- Pertanyaan dengan terminologi tertentu (bagus untuk pencarian kata kunci).
- Pertanyaan tentang konsep yang mungkin dijelaskan menggunakan istilah yang berbeda (baik untuk pencarian vektor).
- Pertanyaan kompleks yang memerlukan konteks pemahaman (baik untuk peringkat semantik).
Membersihkan sumber daya
Setelah selesai dengan aplikasi, Anda dapat menghapus semua sumber daya untuk menghindari timbulnya biaya lebih lanjut:
azd down --purge
Perintah ini menghapus semua sumber daya yang terkait dengan aplikasi Anda.
Tanya jawab umum
- Bagaimana kode sampel mengambil kutipan dari Azure OpenAI Chat Completions?
- Apa keuntungan menggunakan identitas terkelola dalam solusi ini?
- Bagaimana identitas terkelola yang ditetapkan sistem digunakan dalam arsitektur ini dan aplikasi sampel?
- Bagaimana pencarian hibrid dengan ranker semantik diterapkan dalam aplikasi sampel?
- Mengapa semua sumber daya dibuat di East US 2?
- Bisakah saya menggunakan model OpenAI saya sendiri alih-alih model yang disediakan oleh Azure?
- Bagaimana cara meningkatkan kualitas respons?
Bagaimana kode sampel mengambil kutipan dari penyelesaian obrolan Azure OpenAI?
Sampel mengambil kutipan dengan menggunakan AzureSearchChatExtensionConfiguration sebagai sumber data untuk klien obrolan. Saat penyelesaian percakapan diminta, respons akan menyertakan objek Citations dalam konteks pesan. Kode mengekstrak kutipan ini sebagai berikut:
public static ChatResponse fromChatCompletions(ChatCompletions completions) {
ChatResponse response = new ChatResponse();
if (completions.getChoices() != null && !completions.getChoices().isEmpty()) {
var message = completions.getChoices().get(0).getMessage();
if (message != null) {
response.setContent(message.getContent());
if (message.getContext() != null && message.getContext().getCitations() != null) {
var azureCitations = message.getContext().getCitations();
for (int i = 0; i < azureCitations.size(); i++) {
var azureCitation = azureCitations.get(i);
Citation citation = new Citation();
citation.setIndex(i + 1);
citation.setTitle(azureCitation.getTitle());
citation.setContent(azureCitation.getContent());
citation.setFilePath(azureCitation.getFilepath());
citation.setUrl(azureCitation.getUrl());
response.getCitations().add(citation);
}
}
}
}
return response;
}
Dalam respons obrolan, konten menggunakan [doc#] notasi untuk mereferensikan kutipan yang sesuai dalam daftar, memungkinkan pengguna untuk melacak informasi kembali ke dokumen sumber asli. Untuk informasi selengkapnya, lihat:
Apa keuntungan menggunakan identitas terkelola dalam solusi ini?
Identitas terkelola menghilangkan kebutuhan untuk menyimpan kredensial dalam kode atau konfigurasi Anda. Dengan menggunakan identitas terkelola, aplikasi dapat mengakses layanan Azure dengan aman seperti Azure OpenAI dan Azure AI Search tanpa mengelola rahasia. Pendekatan ini mengikuti prinsip keamanan Zero Trust dan mengurangi risiko eksposur kredensial.
Bagaimana identitas terkelola yang ditetapkan sistem digunakan dalam arsitektur ini dan aplikasi sampel?
Penyebaran AZD menghasilkan identitas terkelola yang ditetapkan oleh sistem untuk Azure App Service, Azure OpenAI, dan Azure AI Search. Ini juga membuat penugasan peran masing-masing untuk setiap dari mereka (lihat file main.bicep ). Untuk informasi tentang penetapan peran yang diperlukan, lihat Network dan konfigurasi akses untuk Azure OpenAI On Your Data.
Dalam contoh aplikasi Java, Azure SDKs menggunakan identitas terkelola ini untuk autentikasi aman, sehingga Anda tidak perlu menyimpan kredensial atau rahasia di mana pun. Misalnya, OpenAIAsyncClient diinisialisasi dengan DefaultAzureCredential, yang secara otomatis menggunakan identitas terkelola saat berjalan di Azure:
@Bean
public TokenCredential tokenCredential() {
return new DefaultAzureCredentialBuilder().build();
}
@Bean
public OpenAIAsyncClient openAIClient(TokenCredential tokenCredential) {
return new OpenAIClientBuilder()
.endpoint(openAiEndpoint)
.credential(tokenCredential)
.buildAsyncClient();
}
Demikian pula, saat mengonfigurasi sumber data untuk Azure AI Search, identitas terkelola ditentukan untuk autentikasi:
AzureSearchChatExtensionConfiguration searchConfiguration =
new AzureSearchChatExtensionConfiguration(
new AzureSearchChatExtensionParameters(appSettings.getSearch().getUrl(), appSettings.getSearch().getIndex().getName())
.setAuthentication(new OnYourDataSystemAssignedManagedIdentityAuthenticationOptions())
// ...
);
Penyiapan ini memungkinkan komunikasi tanpa kata sandi yang aman antara aplikasi Spring Boot dan layanan Azure Anda, mengikuti praktik terbaik untuk keamanan Zero Trust. Pelajari selengkapnya tentang DefaultAzureCredential dan pustaka klien Azure Identity untuk Java.
Bagaimana pencarian hibrid dengan ranker semantik diterapkan dalam aplikasi sampel?
Aplikasi sampel mengonfigurasi pencarian hibrid dengan peringkat semantik menggunakan Azure OpenAI dan SDK Azure AI Search Java. Di backend, sumber data disiapkan sebagai berikut:
AzureSearchChatExtensionParameters parameters = new AzureSearchChatExtensionParameters(
appSettings.getSearch().getUrl(),
appSettings.getSearch().getIndex().getName())
// ...
.setQueryType(AzureSearchQueryType.VECTOR_SEMANTIC_HYBRID)
.setEmbeddingDependency(new OnYourDataDeploymentNameVectorizationSource(appSettings.getOpenai().getEmbedding().getDeployment()))
.setSemanticConfiguration(appSettings.getSearch().getIndex().getName() + "-semantic-configuration");
Konfigurasi ini memungkinkan aplikasi untuk menggabungkan pencarian vektor (kesamaan semantik), pencocokan kata kunci, dan peringkat semantik dalam satu kueri. Pemeringkat semantik menyusun ulang hasil untuk mengembalikan jawaban yang paling relevan dan sesuai kontekstual, yang kemudian digunakan oleh Azure OpenAI untuk menghasilkan respons.
Nama konfigurasi semantik secara otomatis ditentukan oleh proses vektorisasi terintegrasi. Ini menggunakan nama indeks pencarian sebagai awalan dan ditambahkan -semantic-configuration sebagai akhiran. Ini memastikan bahwa konfigurasi semantik secara unik dikaitkan dengan indeks yang sesuai dan mengikuti konvensi penamaan yang konsisten.
Mengapa semua sumber daya dibuat di East US 2?
Sampel menggunakan model gpt-4o-mini dan text-embedding-ada-002, dan keduanya tersedia dengan jenis penyebaran Standar di East US 2. Model-model ini juga dipilih karena tidak dijadwalkan untuk segera dihentikan, memberikan stabilitas untuk penyebaran sampel. Ketersediaan model dan jenis penyebaran dapat bervariasi menurut wilayah, sehingga East US 2 dipilih untuk memastikan sampel dapat langsung digunakan. Jika Anda ingin menggunakan wilayah atau model yang berbeda, pastikan untuk memilih model yang tersedia untuk jenis penyebaran yang sama di wilayah yang sama. Saat memilih model Anda sendiri, periksa tanggal ketersediaan dan penghentiannya untuk menghindari gangguan.
- Ketersediaan model: model Azure OpenAI Service
- Tanggal penghentian model: Pensiun dan penghentian dukungan model Azure OpenAI Service.
Dapatkah saya menggunakan model OpenAI saya sendiri alih-alih model yang disediakan oleh Azure?
Solusi ini dirancang untuk bekerja dengan Azure OpenAI Service. Meskipun Anda dapat memodifikasi kode untuk menggunakan model OpenAI lainnya, Anda akan kehilangan fitur keamanan terintegrasi, dukungan identitas terkelola, dan integrasi yang mulus dengan Azure AI Search yang disediakan solusi ini.
Bagaimana cara meningkatkan kualitas respons?
Anda dapat meningkatkan kualitas respons dengan:
- Mengunggah dokumen berkualitas lebih tinggi dan lebih relevan.
- Menyesuaikan strategi pengelompokan dalam jalur pengindeksan Azure AI Search. Namun, Anda tidak dapat menyesuaikan pengelompokan dengan vektorisasi terintegrasi yang ditunjukkan dalam tutorial ini.
- Bereksperimen dengan templat prompt yang berbeda dalam kode aplikasi.
- Menyempurnakan pencarian dengan properti lain di kelas AzureSearchChatExtensionParameters.
- Menggunakan model OpenAI Azure yang lebih khusus untuk domain spesifik Anda.
Sumber daya lainnya
- Jelajahi kemampuan pencarian hibrid di dalam Azure AI Search
- Gunakan Azure OpenAI Pada Data Anda
- Perpustakaan Klien Azure OpenAI untuk Java
- Sampel pustaka klien OpenAI Azure untuk Java