Model kustom: skor akurasi dan keyakinan
Konten ini berlaku untuk:![]() v4.0 (pratinjau)
v4.0 (pratinjau)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Catatan
- Model neural kustom tidak memberikan skor akurasi selama pelatihan.
- Skor keyakinan untuk tabel, baris tabel, dan sel tabel tersedia dimulai dengan versi API pratinjau 2024-02-29 untuk model kustom.
Model templat kustom menghasilkan perkiraan skor akurasi saat dilatih. Dokumen yang dianalisis dengan model kustom menghasilkan skor keyakinan untuk bidang yang diekstraksi. Dalam artikel ini, belajar menafsirkan skor akurasi dan keyakinan serta praktik terbaik untuk menggunakan skor tersebut untuk meningkatkan hasil akurasi dan keyakinan.
Skor akurasi
Output dari build operasi model kustom (v3.0) atau train (v2.1) mencakup perkiraan skor akurasi. Skor ini mewakili kemampuan model untuk memprediksi nilai berlabel secara akurat pada dokumen yang serupa secara visual.
Rentang nilai akurasi adalah persentase antara 0% (rendah) dan 100% (tinggi). Akurasi yang diperkirakan dihitung dengan menjalankan beberapa kombinasi berbeda dari data pelatihan untuk memprediksi nilai berlabel.
Model kustom Terlatih Studio Kecerdasan
Dokumen (faktur)
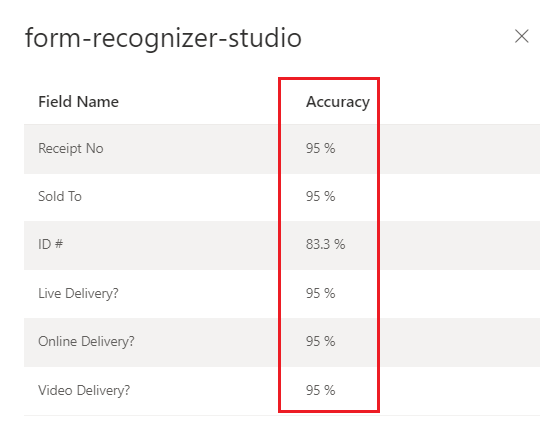
Skor kepercayaan
Catatan
- Skor keyakinan tabel, baris, dan sel sekarang disertakan dengan versi API pratinjau 2024-02-29.
- Skor keyakinan untuk sel tabel dari model kustom ditambahkan ke API yang dimulai dengan API pratinjau 2024-02-29.
Hasil analisis Kecerdasan Dokumen mengembalikan perkiraan keyakinan untuk kata yang diprediksi, pasangan kunci-nilai, tanda pilihan, wilayah, dan tanda tangan. Saat ini, tidak semua bidang dokumen menampilkan skor keyakinan.
Keyakinan lapangan menunjukkan perkiraan probabilitas antara 0 dan 1 bahwa prediksi tersebut benar. Misalnya, nilai keyakinan 0,95 (95%) menunjukkan bahwa prediksi kemungkinan benar 19 dari 20 kali. Untuk skenario di mana akurasi sangat penting, keyakinan dapat digunakan untuk menentukan apakah akan secara otomatis menerima prediksi atau menandainya untuk tinjauan manusia.
Document Intelligence Studio
Menganalisis model faktur bawaan faktur
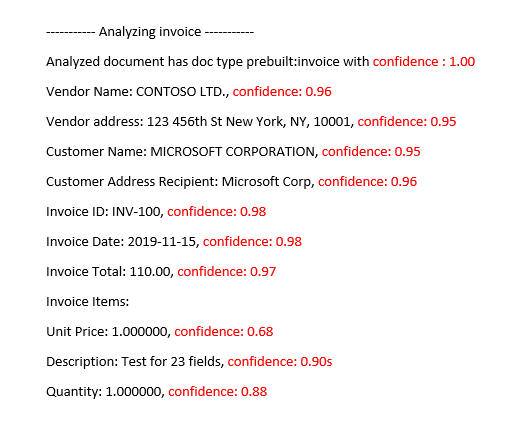
Menginterpretasikan skor akurasi dan keyakinan untuk model kustom
Saat menafsirkan skor keyakinan dari model kustom, Anda harus mempertimbangkan semua skor keyakinan yang dikembalikan dari model. Mari kita mulai dengan daftar semua skor keyakinan.
- Skor keyakinan jenis dokumen: Keyakinan jenis dokumen adalah indikator dokumen yang dianalisis dengan erat menyerupai dokumen dalam himpunan data pelatihan. Ketika keyakinan jenis dokumen rendah, itu menunjukkan templat atau variasi struktural dalam dokumen yang dianalisis. Untuk meningkatkan keyakinan jenis dokumen, beri label dokumen dengan variasi tertentu tersebut dan tambahkan ke himpunan data pelatihan Anda. Setelah model dilatih kembali, model harus lebih dilengkapi untuk menangani kelas variasi tersebut.
- Keyakinan tingkat bidang: Setiap bidang berlabel yang diekstrak memiliki skor keyakinan terkait. Skor ini mencerminkan keyakinan model pada posisi nilai yang diekstrak. Saat mengevaluasi skor keyakinan, Anda juga harus melihat keyakinan ekstraksi yang mendasar untuk menghasilkan keyakinan komprehensif untuk hasil yang diekstraksi. Evaluasi hasil
OCRuntuk ekstraksi teks atau tanda pilihan tergantung pada jenis bidang untuk menghasilkan skor keyakinan komposit untuk bidang tersebut. - Skor keyakinan Word Setiap kata yang diekstrak dalam dokumen memiliki skor keyakinan terkait. Skor mewakili keyakinan transkripsi. Array halaman berisi array kata dan setiap kata memiliki rentang terkait dan skor keyakinan. Rentang dari nilai yang diekstrak bidang kustom cocok dengan rentang kata yang diekstrak.
- Skor keyakinan tanda pilihan: Array halaman juga berisi array tanda pilihan. Setiap tanda pilihan memiliki skor keyakinan yang mewakili keyakinan tanda pilihan dan deteksi status pilihan. Saat bidang berlabel memiliki tanda pilihan, pilihan bidang kustom yang dikombinasikan dengan keyakinan tanda pilihan adalah representasi akurasi keyakinan keseluruhan yang akurat.
Tabel berikut menunjukkan cara menginterpretasikan skor akurasi dan keyakinan untuk mengukur performa model kustom Anda.
| Akurasi | Keyakinan | Hasil |
|---|---|---|
| Sangat Penting | Sangat Penting | • Model berkinerja baik dengan kunci berlabel dan format dokumen. • Anda memiliki himpunan data pelatihan yang seimbang. |
| Sangat Penting | Kurang Penting | • Dokumen yang dianalisis tampak berbeda dari himpunan data pelatihan. • Model akan mendapat manfaat dari pelatihan ulang dengan setidaknya lima dokumen berlabel lagi. • Hasil ini juga dapat menunjukkan variasi format antara himpunan data pelatihan dan dokumen yang dianalisis. Pertimbangkan untuk menambahkan model baru. |
| Rendah | Tinggi | • Hasil ini paling tidak mungkin. • Untuk skor akurasi rendah, tambahkan lebih banyak data berlabel atau pisahkan dokumen yang berbeda secara visual menjadi beberapa model. |
| Kurang Penting | Kurang Penting | • Tambahkan lebih banyak data berlabel. • Membagi dokumen yang berbeda secara visual menjadi beberapa model. |
Keyakinan tabel, baris, dan sel
Dengan penambahan tabel, baris, dan keyakinan sel dengan 2024-02-29-preview API, berikut adalah beberapa pertanyaan umum yang akan membantu menginterpretasikan skor tabel, baris, dan sel:
T: Apakah mungkin untuk melihat skor keyakinan tinggi untuk sel, tetapi skor kepercayaan diri yang rendah untuk baris?
J: Ya. Tingkat keyakinan tabel yang berbeda (sel, baris, dan tabel) dimaksudkan untuk menangkap kebenaran prediksi pada tingkat tertentu. Sel yang diprediksi dengan benar yang termasuk dalam baris dengan kemungkinan kesalahan lainnya akan memiliki keyakinan sel yang tinggi, tetapi keyakinan baris harus rendah. Demikian pula, baris yang benar dalam tabel dengan tantangan dengan baris lain akan memiliki keyakinan baris tinggi sedangkan keyakinan keseluruhan tabel akan rendah.
T: Berapa skor keyakinan yang diharapkan saat sel digabungkan? Karena penggabungan menghasilkan jumlah kolom yang diidentifikasi berubah, bagaimana skor terpengaruh?
J: Terlepas dari jenis tabel, harapan untuk sel yang digabungkan adalah bahwa mereka harus memiliki nilai keyakinan yang lebih rendah. Selain itu, sel yang hilang (karena digabungkan dengan sel yang berdekatan) harus memiliki NULL nilai dengan keyakinan yang lebih rendah juga. Seberapa rendah nilai-nilai ini mungkin tergantung pada himpunan data pelatihan, tren umum dari sel yang digabungkan dan hilang yang memiliki skor yang lebih rendah harus ditahan.
T: Apa skor keyakinan saat nilai bersifat opsional? Haruskah Anda mengharapkan sel dengan NULL nilai dan skor keyakinan tinggi jika nilai hilang?
J: Jika himpunan data pelatihan Anda mewakili opsionalitas sel, ini membantu model mengetahui seberapa sering nilai cenderung muncul dalam set pelatihan, dan dengan demikian apa yang diharapkan selama inferensi. Fitur ini digunakan saat menghitung keyakinan prediksi atau tidak membuat prediksi sama sekali (NULL). Anda harus mengharapkan bidang kosong dengan keyakinan tinggi untuk nilai yang hilang yang sebagian besar kosong dalam set pelatihan juga.
T: Bagaimana skor keyakinan terpengaruh jika bidang bersifat opsional dan tidak ada atau terlewatkan? Apakah harapan bahwa skor keyakinan menjawab pertanyaan itu?
A: Saat nilai hilang dari baris, sel memiliki NULL nilai dan keyakinan yang ditetapkan. Skor keyakinan tinggi di sini harus berarti bahwa prediksi model (dari sana tidak ada nilai) lebih mungkin benar. Sebaliknya, skor rendah harus menandakan lebih banyak ketidakpastian dari model (dan dengan demikian kemungkinan kesalahan, seperti nilai yang terlewatkan).
T: Apa yang harus menjadi harapan untuk keyakinan sel dan keyakinan baris saat mengekstrak tabel multi-halaman dengan pemisahan baris di seluruh halaman?
A: Harapkan keyakinan sel tinggi dan keyakinan baris berpotensi lebih rendah daripada baris yang tidak dibagi. Proporsi baris terpisah dalam himpunan data pelatihan dapat memengaruhi skor keyakinan. Secara umum, baris terpisah terlihat berbeda dari baris lain dalam tabel (dengan demikian, model kurang yakin bahwa itu benar).
T: Untuk tabel lintas halaman dengan baris yang berakhir dengan bersih dan dimulai di batas halaman, apakah benar untuk mengasumsikan bahwa skor keyakinan konsisten di seluruh halaman?
J: Ya. Karena baris terlihat mirip dalam bentuk dan konten, terlepas dari di mana baris berada dalam dokumen (atau di halaman mana), skor keyakinan masing-masing harus konsisten.
T: Apa cara terbaik untuk menggunakan skor keyakinan baru?
A: Lihat semua tingkat kepercayaan tabel yang dimulai dengan pendekatan atas ke bawah: mulailah dengan memeriksa keyakinan tabel secara keseluruhan, lalu telusuri ke tingkat baris dan lihat baris individual, akhirnya lihat keyakinan tingkat sel. Bergantung pada jenis tabel, ada beberapa hal yang perlu diperhatikan:
Untuk tabel tetap, keyakinan tingkat sel sudah menangkap sedikit informasi tentang kebenaran hal-hal. Ini berarti bahwa hanya melalui setiap sel dan melihat keyakinannya bisa cukup untuk membantu menentukan kualitas prediksi. Untuk tabel dinamis, tingkat dimaksudkan untuk membangun di atas satu sama lain, sehingga pendekatan atas ke bawah lebih penting.
Memastikan akurasi model yang tinggi
Varians dalam struktur visual dokumen Anda memengaruhi akurasi model Anda. Skor akurasi yang dilaporkan dapat menjadi tidak konsisten jika dokumen yang dianalisis berbeda dari dokumen yang digunakan dalam pelatihan. Ingatlah bahwa kumpulan dokumen dapat terlihat serupa saat dilihat oleh manusia tetapi tampak berbeda dengan model AI. Untuk diikuti, adalah daftar praktik terbaik untuk model pelatihan dengan akurasi tertinggi. Mengikuti panduan ini akan menghasilkan model dengan akurasi dan skor keyakinan yang lebih tinggi selama analisis dan mengurangi jumlah dokumen yang ditandai untuk ditinjau oleh manusia.
Pastikan bahwa semua variasi dokumen disertakan dalam himpunan data pelatihan. Variasi termasuk format yang berbeda, misalnya, PDF digital versus yang dipindai.
Tambahkan setidaknya lima sampel dari setiap jenis ke himpunan data pelatihan jika Anda mengharapkan model menganalisis kedua jenis dokumen PDF.
Pisahkan jenis dokumen yang berbeda secara visual untuk melatih model yang berbeda.
- Sebagai aturan umum, jika Anda menghapus semua nilai yang dimasukkan pengguna dan dokumen terlihat serupa, Anda perlu menambahkan lebih banyak data pelatihan ke model yang ada.
- Jika dokumennya berbeda, pisahkan data latihan Anda ke dalam folder yang berbeda dan latih model untuk setiap variasi. Anda kemudian dapat menyusun variasi yang berbeda menjadi satu model.
Pastikan Anda tidak memiliki label asing.
Pastikan bahwa pelabelan tanda tangan dan wilayah tidak menyertakan teks di sekitarnya.