Model baca Kecerdasan Dokumen
Penting
- Rilis pratinjau publik Kecerdasan Dokumen menyediakan akses awal ke fitur yang sedang dalam pengembangan aktif.
- Fitur, pendekatan, dan proses dapat berubah, sebelum Ketersediaan Umum (GA), berdasarkan umpan balik pengguna.
- Versi pratinjau publik pustaka klien Kecerdasan Dokumen default ke REST API versi 2024-02-29-preview.
- Pratinjau publik versi 2024-02-29-preview saat ini hanya tersedia di wilayah Azure berikut:
- US Timur
- US Barat2
- Eropa Barat
Konten ini berlaku untuk:![]() v4.0 (pratinjau) | Versi sebelumnya:
v4.0 (pratinjau) | Versi sebelumnya:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Konten ini berlaku untuk:![]() v3.1 (GA) | Versi terbaru:
v3.1 (GA) | Versi terbaru:![]() v4.0 (pratinjau) | Versi sebelumnya:
v4.0 (pratinjau) | Versi sebelumnya:![]() v3.0
v3.0
Konten ini berlaku untuk:![]() v3.0 (GA) | Versi terbaru:
v3.0 (GA) | Versi terbaru:![]() v4.0 (pratinjau)
v4.0 (pratinjau)![]() v3.1
v3.1
Catatan
Untuk mengekstrak teks dari gambar eksternal seperti label, tanda jalan, dan poster, gunakan fitur Azure AI Image Analysis v4.0 Read yang dioptimalkan untuk gambar umum non-dokumen dengan API sinkron yang ditingkatkan performanya yang memudahkan penyematan OCR dalam skenario pengalaman pengguna Anda.
Model Pengenalan Karakter Optik Baca Kecerdasan Dokumen (OCR) berjalan pada resolusi yang lebih tinggi daripada Azure AI Vision Read dan mengekstrak teks cetak dan tulisan tangan dari dokumen PDF dan gambar yang dipindai. Ini juga termasuk dukungan untuk mengekstrak teks dari dokumen Microsoft Word, Excel, PowerPoint, dan HTML. Ini mendeteksi paragraf, baris teks, kata, lokasi, dan bahasa. Model Baca adalah mesin OCR yang mendasari untuk model bawaan Inteligensi Dokumen lainnya seperti dokumen Tata Letak, Dokumen Umum, Faktur, Tanda Terima, Identitas (ID), Kartu asuransi kesehatan, W2 selain model kustom.
Apa itu OCR untuk dokumen?
Pengenalan Karakter Optik (OCR) untuk dokumen dioptimalkan untuk dokumen teks-berat besar dalam beberapa format file dan bahasa global. Ini termasuk fitur seperti pemindaian gambar dokumen resolusi lebih tinggi untuk penanganan teks yang lebih kecil dan padat; deteksi paragraf; dan manajemen formulir yang dapat diisi. Kemampuan OCR juga mencakup skenario lanjutan seperti kotak karakter tunggal dan ekstraksi bidang kunci yang akurat yang umumnya ditemukan dalam faktur, tanda terima, dan skenario bawaan lainnya.
Opsi pengembangan
Kecerdasan Dokumen v4.0 (2024-02-29-preview, 2023-10-31-preview) mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Membaca model OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
baca bawaan |
Kecerdasan Dokumen v3.1 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Membaca model OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
baca bawaan |
Kecerdasan Dokumen v3.0 mendukung alat, aplikasi, dan pustaka berikut:
| Fitur | Sumber | ID Model |
|---|---|---|
| Membaca model OCR | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
baca bawaan |
Persyaratan input
Untuk hasil terbaik, berikan satu foto yang jelas atau pemindaian berkualitas tinggi per dokumen.
Format file yang didukung:
Model PDF Gambar:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), dan HTMLRead ✔ ✔ ✔ Tata letak ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokumen Umum ✔ ✔ Bawaan ✔ ✔ Ekstraksi kustom ✔ ✔ Klasifikasi kustom ✔ ✔ ✔ (Pratinjau 2024-02-29) Untuk PDF dan TIFF, hingga 2000 halaman yang dapat diproses (dengan langganan tingkat gratis, hanya dua halaman pertama yang diproses).
Ukuran file untuk menganalisis dokumen adalah 500 MB untuk tingkat berbayar (S0) dan 4 MB secara gratis (F0).
Dimensi gambar harus antara 50 x 50 piksel dan 10.000 piksel x 10.000 piksel.
Jika PDF Anda dikunci dengan kata sandi, Anda harus menghapus kunci sebelum pengiriman.
Tinggi minimum teks yang akan diekstrak adalah 12 piksel untuk gambar piksel 1024 x 768. Dimensi ini sesuai dengan teks sekitar
8-point pada 150 titik per inci (DPI).Untuk pelatihan model kustom, jumlah maksimum halaman untuk data pelatihan adalah 500 untuk model template kustom dan 50.000 untuk model neural kustom.
Untuk pelatihan model ekstraksi kustom, ukuran total data pelatihan adalah 50 MB untuk model templat dan 1G-MB untuk model neural.
Untuk pelatihan model klasifikasi kustom, ukuran total data pelatihan adalah
1GBdengan maksimum 10.000 halaman.
Mulai menggunakan model Baca
Coba ekstrak teks dari formulir dan dokumen menggunakan Studio Kecerdasan Dokumen. Anda memerlukan aset berikut:
Langganan Azure—Anda dapat membuatnya secara gratis.
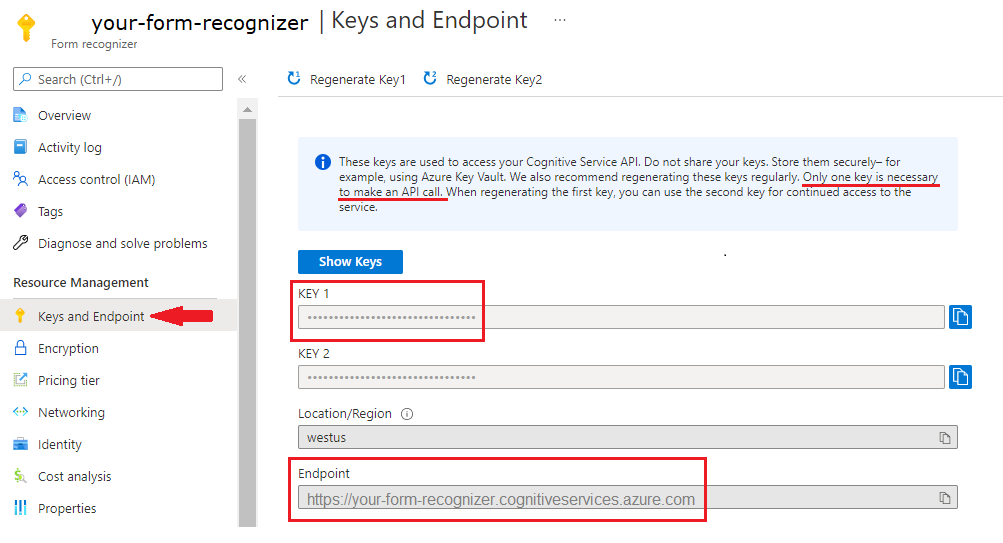
Instans Kecerdasan Dokumen di portal Azure. Anda dapat menggunakan tingkat harga gratis (
F0) untuk mencoba layanan. Setelah sumber daya Anda disebarkan, pilih Buka sumber daya untuk mendapatkan kunci dan titik akhir Anda.
Catatan
Saat ini, Document Intelligence Studio tidak mendukung format file Microsoft Word, Excel, PowerPoint, dan HTML.
Contoh dokumen yang diproses dengan Document Intelligence Studio
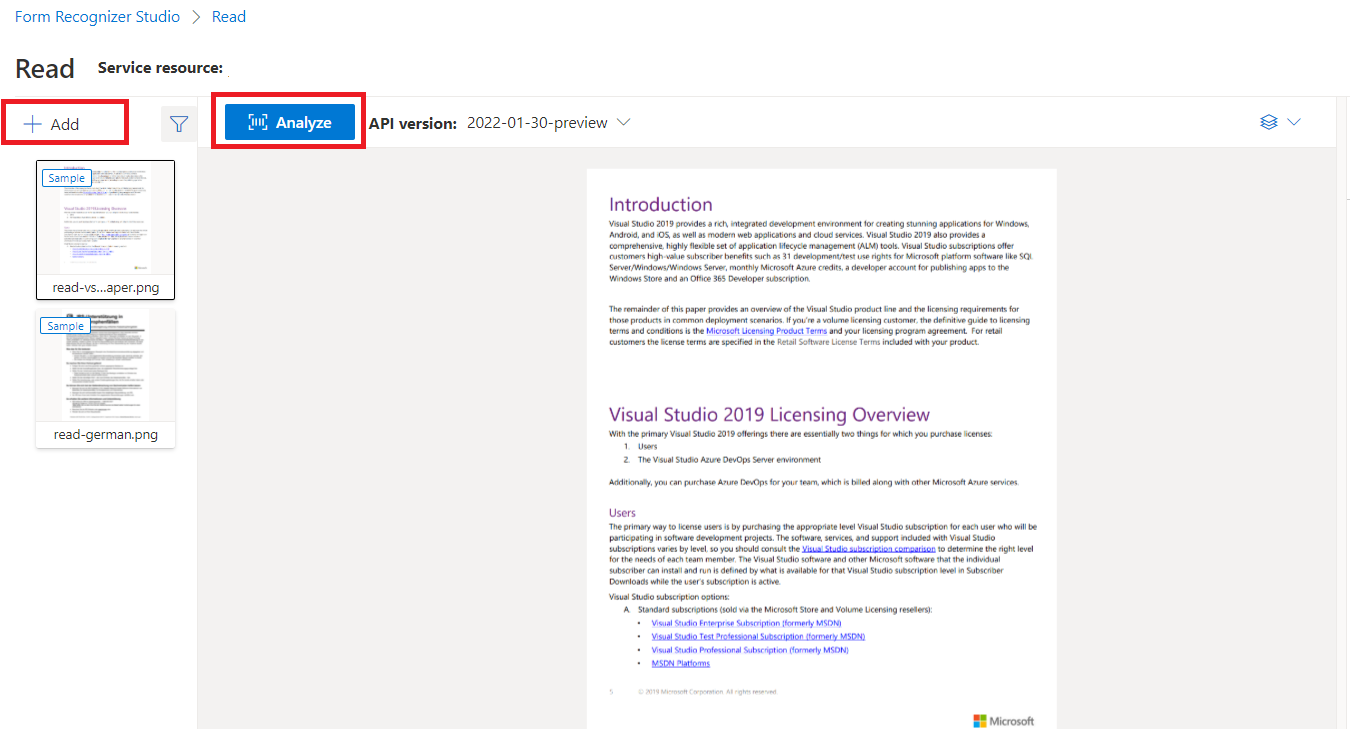
Pada beranda Studio Kecerdasan Dokumen, pilih Baca.
Anda dapat menganalisis contoh dokumen atau mengunggah file Anda sendiri.
Pilih tombol Jalankan analisis dan, jika perlu, konfigurasikan opsi Analisis:

Coba Studio Kecerdasan Dokumen.
Bahasa dan lokal yang didukung
Lihat halaman Dukungan Bahasa—model analisis dokumen untuk daftar lengkap bahasa yang didukung.
Ekstraksi data
Catatan
File Microsoft Word dan HTML didukung di v3.1 dan versi yang lebih baru. Dibandingkan dengan PDF dan gambar, fitur di bawah ini tidak didukung:
- Tidak ada sudut, lebar/tinggi, dan unit dengan setiap objek halaman.
- Untuk setiap objek yang terdeteksi, tidak ada poligon pembatas atau wilayah pembatas.
- Rentang halaman (
pages) tidak didukung sebagai parameter. - Tidak ada
linesobjek.
Halaman
Kumpulan halaman adalah daftar halaman dalam dokumen. Setiap halaman diwakili secara berurutan dalam dokumen dan menyertakan sudut orientasi yang menunjukkan apakah halaman diputar dan lebar dan tinggi (dimensi dalam piksel). Unit halaman dalam output model dihitung seperti yang ditunjukkan:
| Format file | Unit halaman terkomputasi | Total halaman |
|---|---|---|
| Gambar (JPEG/JPG, PNG, BMP, HEIF) | Setiap gambar = 1 unit halaman | Total gambar |
| Setiap halaman dalam PDF = 1 unit halaman | Total halaman dalam PDF | |
| TIFF | Setiap gambar dalam Format File Gambar Bertag = 1 unit halaman | Total gambar di TIFF |
| Word (DOCX) | Hingga 3.000 karakter = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Total halaman hingga 3.000 karakter masing-masing |
| Excel (XLSX) | Setiap lembar kerja = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Total lembar kerja |
| PowerPoint (PPTX) | Setiap slide = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Total slide |
| HTML | Hingga 3.000 karakter = 1 unit halaman, gambar yang disematkan atau ditautkan tidak didukung | Total halaman hingga 3.000 karakter masing-masing |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
Pilih halaman untuk ekstraksi teks
Untuk dokumen PDF yang terdiri dari beberapa halaman besar, gunakan parameter kueri pages untuk menunjukkan nomor halaman atau rentang halaman tertentu untuk mengekstrak teks.
Paragraf
Model Baca OCR dalam Kecerdasan Dokumen mengekstrak semua blok teks yang diidentifikasi dalam paragraphs koleksi sebagai objek tingkat atas di bawah analyzeResults. Setiap entri dalam koleksi ini mewakili blok teks dan menyertakan teks yang diekstrak sebagaicontent dan koordinat pembatas polygon . Informasi span menunjuk ke fragmen teks dalam properti tingkat content atas yang berisi teks lengkap dari dokumen.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Teks, baris, dan kata
Model Read OCR mengekstrak teks gaya cetak dan tulisan tangan sebagai lines dan words. Model mengeluarkan koordinat polygon dan confidence untuk kata-kata yang diekstraksi. Koleksi styles mencakup gaya tulisan tangan apa pun untuk garis jika terdeteksi bersama dengan rentang yang menunjuk ke teks terkait. Fitur ini berlaku untuk bahasa komputer tulisan tangan yang didukung.
Untuk Microsoft Word, Excel, PowerPoint, dan HTML, model Baca Inteligensi Dokumen v3.1 dan versi yang lebih baru mengekstrak semua teks yang disematkan apa adanya. Teks dilebarkan sebagai kata dan paragraf. Gambar yang disematkan tidak didukung.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
Gaya tulisan tangan untuk baris teks
Respons meliputi pengklasifikasian apakah setiap baris teks memiliki gaya tulisan tangan atau tidak, bersama dengan skor keyakinan. Untuk informasi selengkapnya, lihatdukungan bahasa tulisan tangan. Contoh berikut menunjukkan contoh cuplikan JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Jika Anda mengaktifkan kemampuan addon font/style, Anda juga mendapatkan hasil font/gaya sebagai bagian styles dari objek.
Langkah berikutnya
Selesaikan mulai cepat Inteligensi Dokumen:
Jelajahi REST API kami: