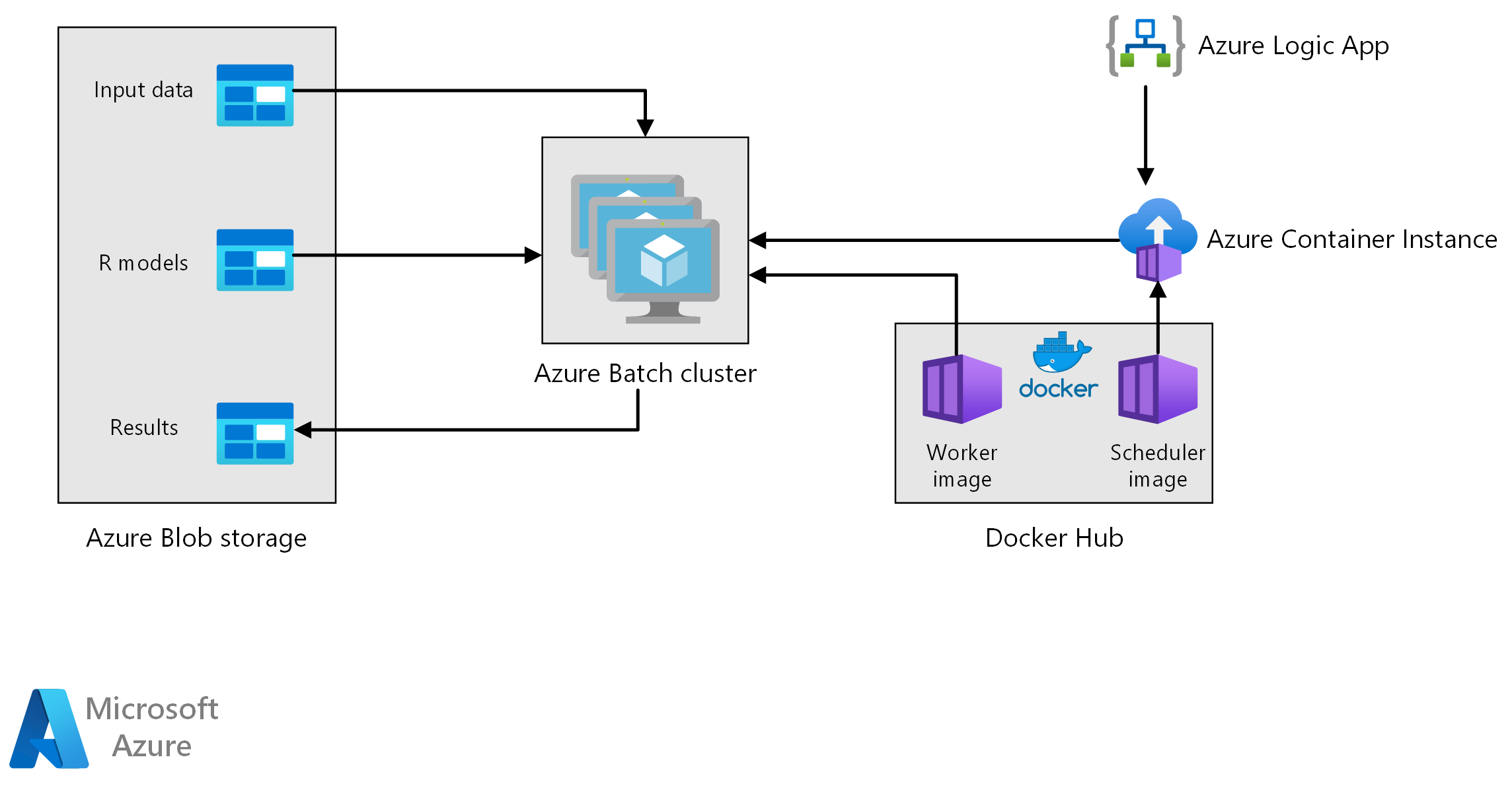
Arsitektur referensi ini menunjukkan cara melakukan penilaian batch dengan model R menggunakan Azure Batch. Azure Batch bekerja dengan baik dengan beban kerja paralel intrinsik dan mencakup penjadwalan pekerjaan dan manajemen komputasi. Inferensi batch (penilaian) banyak digunakan untuk segmen pelanggan, prakiraan penjualan, memprediksi perilaku pelanggan, memprediksi pemeliharaan, atau meningkatkan keamanan cyber.
Unduh file Visio arsitektur ini.
Alur kerja
Arsitektur ini terdiri dari komponen-komponen berikut.
Azure Batch menjalankan pekerjaan pembuatan prakiraan secara paralel pada kluster komputer virtual. Prediksi dibuat menggunakan model pembelajaran mesin pra-terlatih yang diterapkan dalam R. Azure Batch dapat secara otomatis menskalakan jumlah VM berdasarkan jumlah pekerjaan yang dikirimkan ke kluster. Pada setiap node, skrip R berjalan dalam kontainer Docker untuk mencetak data dan menghasilkan prakiraan.
Azure Blob Storage menyimpan data input, model pembelajaran mesin yang telah dilatih sebelumnya, dan hasil prakiraan. Azure Blob Storage memberikan penyimpanan hemat biaya untuk performa yang dibutuhkan beban kerja ini.
Azure Container Instances menyediakan komputasi tanpa server sesuai permintaan. Dalam hal ini, instans kontainer diterapkan pada jadwal untuk memicu pekerjaan Batch yang menghasilkan prakiraan. Pekerjaan Batch dipicu dari skrip R menggunakan paket doAzureParallel. Instans kontainer secara otomatis mati ketika pekerjaan selesai.
Azure Logic Apps memicu seluruh alur kerja dengan menyebarkan instans kontainer sesuai jadwal. Konektor Azure Container Instances di Logic Apps memungkinkan instans disebarkan pada berbagai peristiwa pemicu.
Komponen
Detail solusi
Meskipun skenario berikut didasarkan pada prakiraan penjualan toko ritel, arsitekturnya dapat digeneralisasi untuk skenario apa pun yang memerlukan pembuatan prediksi pada skala yang lebih besar menggunakan model R. Penerapan referensi untuk arsitektur ini tersedia di GitHub.
Kemungkinan kasus penggunaan
Jaringan supermarket perlu prakiraan penjualan produk selama kuartal mendatang. Prakiraan tersebut memungkinkan perusahaan untuk mengelola rantai pasokannya dengan lebih baik dan memastikannya dapat memenuhi permintaan produk di masing-masing tokonya. Perusahaan memperbarui prakiraan setiap minggu karena data penjualan baru dari minggu sebelumnya tersedia dan strategi pemasaran produk untuk kuartal berikutnya ditetapkan. Prakiraan kuantil dihasilkan untuk memperkirakan ketidakpastian prakiraan penjualan individu.
Pemrosesan melibatkan langkah-langkah berikut:
Aplikasi logika Azure memicu proses pembuatan prakiraan sekali per minggu.
Aplikasi logika memulai Azure Container Instance yang menjalankan kontainer Docker penjadwal, yang memicu pekerjaan penilaian pada kluster Batch.
Pekerjaan penilaian berjalan secara paralel di seluruh node kluster Batch. Setiap node:
Tarik gambar Docker pekerja dan mulai kontainer.
Membaca data input dan model R pra-terlatih dari penyimpanan Azure Blob.
Skor data untuk menghasilkan prakiraan.
Menulis hasil prakiraan untuk penyimpanan blob.
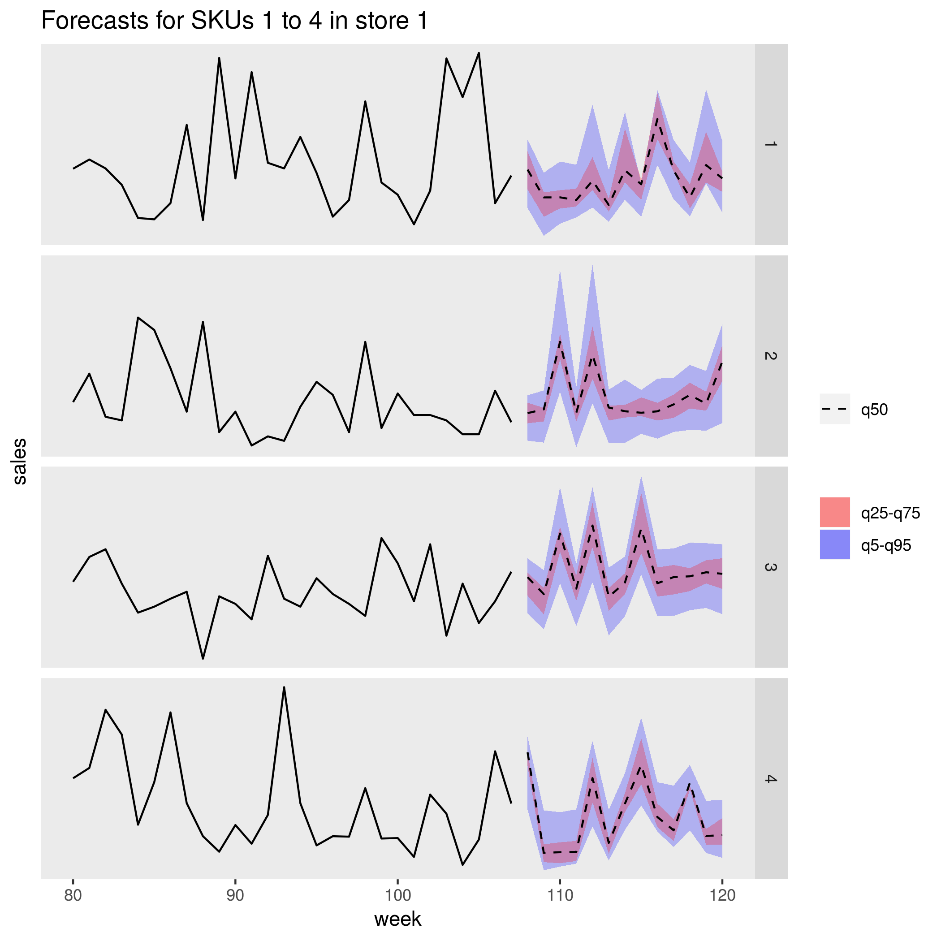
Gambar berikut menunjukkan perkiraan penjualan untuk empat produk (SKU) dalam satu toko. Garis hitam adalah riwayat penjualan, garis putus-putus adalah prakiraan nilai median (q50), band merah muda mewakili persentil ke-25 dan ke-75, dan band biru mewakili persentil ke-50 dan ke-95.
Pertimbangan
Pertimbangan ini mengimplementasikan pilar Azure Well-Architected Framework, yang merupakan serangkaian tenet panduan yang dapat digunakan untuk meningkatkan kualitas beban kerja. Untuk informasi selengkapnya, lihat Microsoft Azure Well-Architected Framework.
Performa
Penyebaran kontainer
Dengan arsitektur ini, semua skrip R berjalan dalam kontainer Docker. Menggunakan kontainer memastikan bahwa skrip berjalan di lingkungan yang konsisten setiap kali, dengan versi R dan versi paket yang sama. Gambar Docker terpisah digunakan untuk penjadwal dan kontainer pekerja, karena masing-masing memiliki rangkaian dependensi paket R yang berbeda.
Azure Container Instances menyediakan lingkungan tanpa server untuk menjalankan kontainer penjadwal. Kontainer penjadwal menjalankan skrip R yang memicu pekerjaan penilaian individual yang berjalan pada kluster Azure Batch.
Setiap node dari kluster Batch menjalankan kontainer pekerja, yang mengeksekusi skrip penilaian.
Paralelkan beban kerja
Saat mencetak data batch dengan model R, pertimbangkan cara menyejajarkan beban kerja. Data input harus dipartisi sehingga operasi penilaian dapat didistribusikan di seluruh node kluster. Cobalah berbagai cara untuk menemukan pilihan terbaik untuk mendistribusikan beban kerja Anda. Berdasarkan kasus per kasus, pertimbangkan:
- Berapa banyak data yang dapat dimuat dan diproses dalam memori satu node.
- Overhead memulai setiap tugas batch.
- Overhead memuat model R.
Dalam skenario yang digunakan untuk contoh ini, objek model besar, dan hanya butuh beberapa detik untuk menghasilkan prakiraan untuk masing-masing produk. Untuk alasan ini, Anda dapat mengelompokkan produk dan menjalankan satu tugas Batch per node. Sebuah perulangan dalam setiap pekerjaan menghasilkan prakiraan untuk produk secara berurutan. Metode ini adalah cara paling efisien untuk menyejajarkan beban kerja khusus ini. Ini menghindari overhead memulai banyak tugas Batch yang lebih kecil dan berulang kali memuat model R.
Pendekatan alternatif adalah memicu satu tugas Batch per produk. Azure Batch secara otomatis membentuk antrean pekerjaan dan mengirimkannya untuk dieksekusi pada kluster saat node tersedia. Gunakan penskalaan otomatis untuk menyesuaikan jumlah simpul dalam kluster, tergantung pada jumlah pekerjaan. Pendekatan ini berguna jika membutuhkan waktu yang relatif lama untuk menyelesaikan setiap operasi penilaian, yang membenarkan overhead memulai pekerjaan dan memuat ulang objek model. Pendekatan ini juga lebih mudah diterapkan dan memberi Anda fleksibilitas untuk menggunakan penskalaan otomatis, pertimbangan penting jika ukuran total beban kerja tidak diketahui sebelumnya.
Memantau pekerjaan Azure Batch
Memantau dan mengakhiri tugas Batch dari panel Pekerjaan akun Batch di portal Microsoft Azure. Pantau kluster batch, termasuk status node individual, dari panel Pools.
Log dengan doAzureParallel
Paket doAzureParallel secara otomatis mengumpulkan log semua stdout /stderr untuk setiap pekerjaan yang dikirimkan di Azure Batch. Log ini dapat ditemukan di akun penyimpanan yang dibuat saat penyiapan. Untuk melihatnya, gunakan alat navigasi penyimpanan seperti Azure Storage Explorer atau portal Azure.
Untuk men-debug pekerjaan Batch dengan cepat selama pengembangan, lihat log di sesi R lokal Anda. Untuk informasi selengkapnya, lihat menggunakan Mengonfigurasi dan mengirimkan eksekusi pelatihan.
Pengoptimalan biaya
Optimalisasi biaya adalah tentang mencari cara untuk mengurangi pengeluaran yang tidak perlu dan meningkatkan efisiensi operasional. Untuk informasi selengkapnya, lihat Gambaran umum pilar pengoptimalan biaya.
Sumber daya komputasi yang digunakan dalam arsitektur referensi ini adalah komponen yang paling mahal. Untuk skenario ini, kluster berukuran tetap dibuat setiap kali pekerjaan dipicu dan kemudian ditutup setelah pekerjaan selesai. Biaya dikeluarkan hanya saat node kluster mulai, berjalan, atau dimatikan. Pendekatan ini cocok untuk skenario di mana sumber daya komputasi yang diperlukan untuk menghasilkan prakiraan tetap relatif konstan dari pekerjaan ke pekerjaan.
Dalam skenario di mana jumlah komputasi yang diperlukan untuk menyelesaikan pekerjaan tidak diketahui sebelumnya, mungkin lebih cocok untuk menggunakan penskalaan otomatis. Dengan pendekatan ini, ukuran kluster ditingkatkan atau di bawah tergantung pada ukuran pekerjaan. Azure Batch mendukung berbagai rumus skala otomatis, yang dapat Anda atur saat menentukan kluster menggunakan API doAzureParallel .
Untuk beberapa skenario, waktu antara pekerjaan mungkin terlalu singkat untuk dimatikan dan memulai kluster. Dalam kasus ini, jaga agar kluster tetap berjalan di antara pekerjaan jika sesuai.
Azure Batch dan doAzureParallel mendukung penggunaan VM prioritas rendah. VM ini datang dengan diskon yang signifikan tetapi berisiko disesuaikan oleh beban kerja prioritas tinggi lainnya. Oleh karena itu, penggunaan VM berprioritas rendah tidak disarankan untuk beban kerja produksi penting. Namun, ini berguna untuk beban kerja eksperimental atau pengembangan.
Menyebarkan skenario ini
Untuk menyebarkan arsitektur referensi ini, ikuti langkah-langkah yang dijelaskan di repo GitHub.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Angus Taylor | Ilmuwan Data Senior
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.