Penembolokan adalah teknik umum yang bertujuan untuk meningkatkan kinerja dan skalabilitas suatu sistem. Ini menyimpan data dengan menyalin data yang sering diakses untuk sementara waktu ke penyimpanan cepat yang terletak dekat dengan aplikasi. Jika penyimpanan data cepat ini terletak lebih dekat ke aplikasi daripada sumber aslinya, maka penembolokan dapat secara signifikan meningkatkan waktu respons untuk aplikasi klien dengan menyajikan data lebih cepat.
Penembolokan paling efektif ketika instans klien berulang kali membaca data yang sama, terutama jika semua kondisi berikut berlaku untuk penyimpanan data asli:
- Ini tetap relatif statis.
- Ini lambat dibandingkan dengan kecepatan cache.
- Ini tunduk pada tingkat pertengkaran yang tinggi.
- Ini jauh ketika latensi jaringan dapat menyebabkan akses menjadi lambat.
Cache dalam aplikasi terdistribusi
Aplikasi terdistribusi biasanya menerapkan salah satu atau kedua strategi berikut saat penembolokan (caching) data:
- Mereka menggunakan cache privat, di mana data disimpan secara lokal di komputer yang menjalankan instans aplikasi atau layanan.
- Mereka menggunakan cache bersama, berfungsi sebagai sumber umum yang dapat diakses oleh beberapa proses dan mesin.
Dalam kedua kasus, cache dapat dilakukan di sisi klien dan sisi server. Cache sisi klien dilakukan oleh proses yang menyediakan antarmuka pengguna untuk suatu sistem, seperti browser web atau aplikasi desktop. Penembolokan (caching) sisi server dilakukan dengan proses yang menyediakan layanan bisnis yang berjalan dari jarak jauh.
Cache pribadi
Jenis cache yang paling dasar adalah penyimpanan di dalam memori. Cache disimpan di ruang alamat dari satu proses dan diakses langsung oleh kode yang berjalan dalam proses itu. Cache ini berjenis cepat diakses. Ini juga dapat memberikan cara yang efektif untuk menyimpan data statis dalam jumlah sederhana. Ukuran cache biasanya dibatasi oleh jumlah memori yang tersedia pada komputer yang menghosting proses.
Jika Anda perlu meng-cache lebih banyak informasi daripada jumlah yang dapat ditampung secara fisik di memori, Anda dapat menulis data cache ke sistem file lokal. Proses ini akan lebih lambat untuk diakses daripada data yang disimpan dalam memori, tetapi seharusnya masih lebih cepat dan lebih dapat diandalkan daripada mengambil data di seluruh jaringan.
Jika Anda memiliki beberapa instans aplikasi yang menggunakan model ini berjalan bersamaan, setiap instans aplikasi memiliki cache independennya sendiri yang menyimpan salinan datanya sendiri.
Anggaplah cache sebagai snapshot dari data asli di beberapa titik di masa lalu. Jika data ini tidak statis, kemungkinan instans aplikasi yang berbeda menyimpan versi data yang berbeda di cache mereka. Oleh karena itu, kueri yang sama yang dilakukan oleh instans ini dapat mengembalikan hasil yang berbeda, seperti yang ditunjukkan pada Gambar 1.
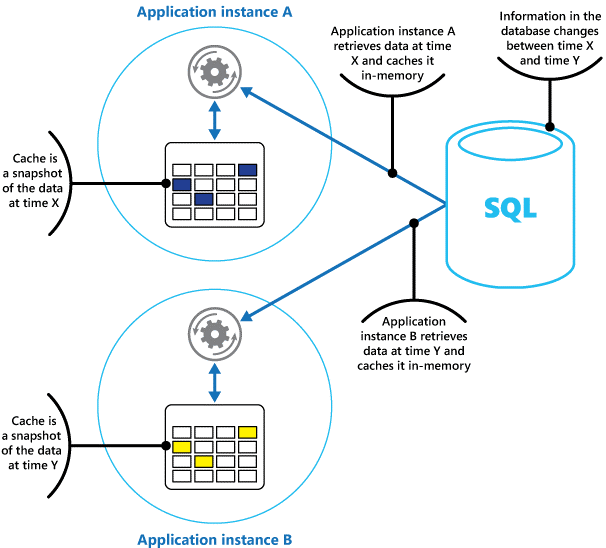
Gambar 1: Menggunakan cache dalam memori dalam berbagai instans aplikasi.
Cache bersama
Jika Anda menggunakan cache bersama, cache tersebut dapat membantu meringankan kekhawatiran bahwa data mungkin berbeda di setiap cache, yang dapat terjadi dengan penembolokan dalam memori. Cache bersama memastikan bahwa instans aplikasi yang berbeda melihat tampilan yang sama dengan data cache. Ini menemukan cache di lokasi terpisah, yang biasanya dihosting sebagai bagian dari layanan terpisah, seperti yang ditunjukkan pada Gambar 2.
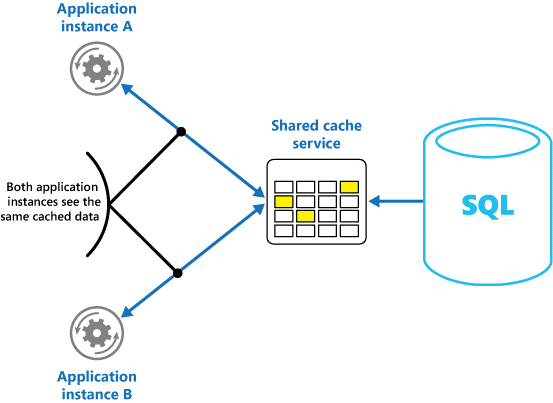
Gambar 2: Menggunakan cache bersama.
Keuntungan penting dari pendekatan cache bersama adalah skalabilitas yang diberikannya. Banyak layanan cache bersama diimplementasikan dengan menggunakan sekelompok server dan menggunakan perangkat lunak untuk mendistribusikan data di seluruh kluster secara transparan. Instans aplikasi hanya mengirim permintaan ke layanan cache. Infrastruktur yang mendasari menentukan lokasi data cache di kluster. Anda dapat dengan mudah menskalakan cache dengan menambahkan lebih banyak server.
Ada dua kelemahan utama dari pendekatan cache bersama:
- Cache lebih lambat diakses karena tidak lagi disimpan secara lokal ke setiap instans aplikasi.
- Persyaratan untuk mengimplementasikan layanan cache terpisah mungkin menambah kerumitan pada solusi.
Pertimbangan untuk menggunakan cache
Bagian berikut menjelaskan secara lebih rinci pertimbangan untuk mendesain dan menggunakan cache.
Putuskan kapan harus meng-cache data
Penembolokan dapat meningkatkan performa, skalabilitas, dan ketersediaan secara drastis. Semakin banyak data yang Anda miliki dan semakin besar jumlah pengguna yang perlu mengakses data ini, maka akan semakin besar manfaat cache. Penembolokan mengurangi latensi dan ketidakcocokan yang terkait dengan penanganan volume besar permintaan bersamaan di penyimpanan data asli.
Misalnya, database mungkin mendukung sejumlah koneksi bersamaan. Namun, mengambil data dari cache bersama daripada database yang mendasarinya akan memungkinkan aplikasi klien untuk mengakses data ini bahkan jika jumlah koneksi yang tersedia saat ini habis. Selain itu, jika database menjadi tidak tersedia, aplikasi klien mungkin dapat melanjutkan dengan menggunakan data yang disimpan dalam cache.
Pertimbangkan untuk menyimpan data dalam cache yang sering dibaca tetapi jarang dimodifikasi (misalnya, data yang memiliki proporsi operasi baca yang lebih tinggi daripada operasi tulis). Namun, kami tidak menyarankan Anda menggunakan cache sebagai penyimpanan resmi informasi penting. Sebagai gantinya, pastikan bahwa semua perubahan yang tidak dapat hilang aplikasi Anda selalu disimpan ke penyimpanan data persisten. Jika cache tidak tersedia, aplikasi Anda masih dapat terus beroperasi dengan menggunakan penyimpanan data, dan Anda tidak akan kehilangan informasi penting.
Tentukan cara meng-cache data secara efektif
Kunci dalam menggunakan cache secara efektif terletak pada penentuan data yang paling tepat yang akan ditembolokkan, dan penembolokan pada waktu yang tepat. Data dapat ditambahkan ke cache sesuai permintaan saat pertama kali diambil oleh aplikasi. Aplikasi perlu mengambil data hanya sekali dari penyimpanan data, dan akses berikutnya dapat dipenuhi dengan menggunakan cache.
Atau, cache dapat diisi sebagian atau seluruhnya dengan data sebelumnya, biasanya saat aplikasi dimulai (pendekatan yang dikenal sebagai seeding). Namun, mungkin tidak disarankan untuk menerapkan seeding untuk cache yang besar karena pendekatan ini dapat menyebabkan beban tinggi yang tiba-tiba pada penyimpanan data asli saat aplikasi mulai berjalan.
Seringkali analisis pola penggunaan dapat membantu Anda memutuskan apakah akan mengisi cache secara penuh atau sebagian, dan memilih data untuk di-cache. Misalnya, Anda dapat menyemai cache dengan data profil pengguna statis untuk pelanggan yang menggunakan aplikasi secara teratur (mungkin setiap hari), tetapi tidak untuk pelanggan yang menggunakan aplikasi hanya seminggu sekali.
Penembolokan biasanya bekerja dengan baik dengan data yang tidak dapat diubah atau yang jarang berubah. Contohnya termasuk informasi referensi seperti informasi produk dan harga dalam aplikasi e-niaga, atau sumber daya statik bersama yang mahal untuk dibuat. Beberapa atau semua data ini dapat dimuat ke dalam cache saat startup aplikasi untuk mengecilkan permintaan sumber daya dan untuk meningkatkan performa. Anda mungkin juga ingin memiliki proses latar belakang yang secara berkala memperbarui data referensi dalam cache untuk memastikannya terbaru. Atau, proses latar belakang dapat merefresh cache saat data referensi berubah.
Caching kurang berguna untuk data dinamis, meskipun ada beberapa pengecualian untuk pertimbangan ini (lihat bagian Cache data yang sangat dinamis nanti di artikel ini untuk informasi selengkapnya). Ketika data asli berubah secara teratur, informasi yang di-cache menjadi basi dengan cepat atau overhead sinkronisasi cache dengan penyimpanan data asli mengurangi efektivitas penembolokan.
Cache tidak harus menyertakan data lengkap untuk entitas. Misalnya, jika item data mewakili objek multinila, seperti pelanggan bank dengan nama, alamat, dan saldo akun, beberapa elemen ini mungkin tetap statis, seperti nama dan alamat. Elemen lain, seperti saldo akun, mungkin lebih dinamis. Dalam situasi ini, dapat berguna untuk menyimpan bagian statis data dan mengambil (atau menghitung) hanya informasi yang tersisa ketika diperlukan.
Kami menyarankan Anda melakukan pengujian performa dan analisis penggunaan untuk menentukan apakah pra-pengisian atau pemuatan cache sesuai permintaan, atau kombinasi keduanya, sesuai. Keputusan harus didasarkan pada volatilitas dan pola penggunaan data. Pemanfaatan cache dan analisis performa penting dalam aplikasi yang mengalami beban berat dan harus sangat dapat diskalakan. Misalnya, dalam skenario yang sangat dapat diskalakan, Anda dapat menyemai cache untuk mengurangi beban pada penyimpanan data pada waktu sibuk.
Cache juga dapat digunakan untuk menghindari komputasi berulang saat aplikasi sedang berjalan. Jika suatu operasi mengubah data atau melakukan perhitungan yang rumit, aplikasi dapat menyimpan hasil operasinya dalam cache. Jika perhitungan yang sama diperlukan setelahnya, aplikasi dapat dengan mudah mengambil hasil dari cache.
Aplikasi dapat memodifikasi data yang disimpan dalam cache. Namun, kami menyarankan untuk menganggap cache sebagai penyimpanan data sementara yang dapat hilang kapan saja. Jangan menyimpan data berharga dalam cache saja; pastikan Anda mempertahankan informasi di penyimpanan data asli juga. Hal ini berarti bahwa jika cache menjadi tidak tersedia, Anda meminimalkan kemungkinan kehilangan data.
Cache data yang sangat dinamis
Saat Anda menyimpan informasi yang berubah dengan cepat di penyimpanan data yang persisten, hal tersebut dapat membebani sistem. Misalnya, pertimbangkan perangkat yang terus melaporkan status atau pengukuran lainnya. Jika aplikasi memilih untuk tidak menyimpan data ini dalam cache karena informasi yang di-cache hampir selalu usang, maka pertimbangan yang sama dapat berlaku saat menyimpan dan mengambil informasi ini dari penyimpanan data. Dalam waktu yang diperlukan untuk menyimpan dan mengambil data ini, mungkin telah berubah.
Dalam situasi seperti ini, pertimbangkan manfaat menyimpan informasi dinamis secara langsung di cache daripada di penyimpanan data persisten. Jika data bersifat noncritik dan tidak memerlukan audit, maka tidak masalah jika perubahan sesekali hilang.
Kelola kedaluwarsa data dalam cache
Dalam kebanyakan kasus, data yang disimpan dalam cache adalah salinan data yang disimpan di penyimpanan data asli. Data di penyimpanan data asli mungkin berubah setelah di-cache, menyebabkan data yang di-cache menjadi kedaluwarsa. Banyak sistem cache memungkinkan Anda untuk mengonfigurasi cache agar mengakhiri data dan mengurangi periode data yang mungkin akan kedaluwarsa.
Ketika data yang di-cache kedaluwarsa, data tersebut dihapus dari cache, dan aplikasi harus mengambil data dari penyimpanan data asli (hal ini dapat mengembalikan informasi yang baru diambil ke dalam cache). Anda dapat menetapkan kebijakan kedaluwarsa default saat mengonfigurasi cache. Di banyak layanan cache, Anda juga dapat menetapkan periode kedaluwarsa untuk masing-masing objek saat Anda menyimpannya secara terprogram dalam cache. Beberapa cache memungkinkan Anda menentukan periode kedaluwarsa sebagai nilai absolut, atau sebagai nilai geser yang menyebabkan item dihapus dari cache jika tidak diakses dalam waktu yang ditentukan. Pengaturan ini mengesampingkan kebijakan kedaluwarsa seluruh cache, tetapi hanya untuk objek yang ditentukan.
Catatan
Pertimbangkan periode kedaluwarsa untuk cache dan objek yang dimuatnya dengan hati-hati. Jika Anda membuatnya terlalu pendek, objek akan kedaluwarsa terlalu cepat dan Anda akan mengurangi manfaat menggunakan cache. Jika Anda membuat periode terlalu lama, maka data berisiko menjadi kedaluwarsa.
Mungkin juga cache akan terisi jika data dibiarkan tetap ada untuk waktu yang lama. Dalam hal ini, setiap permintaan untuk menambahkan item baru ke cache dapat menyebabkan beberapa item dihapus secara paksa dalam proses yang dikenal sebagai pengeluaran. Layanan cache biasanya mengeluarkan data dengan basis yang paling jarang digunakan (LRU), tetapi Anda biasanya dapat mengganti kebijakan ini dan mencegah item dihapus. Namun, jika mengadopsi pendekatan ini, Anda berisiko melebihi memori yang tersedia di cache. Aplikasi yang mencoba menambahkan item ke cache akan gagal dengan pengecualian.
Beberapa implementasi cache mungkin memberikan kebijakan pengeluaran tambahan. Ada beberapa jenis kebijakan pengeluaran. Ini termasuk:
- Kebijakan yang terakhir digunakan (dengan harapan bahwa data tidak akan diperlukan lagi).
- Kebijakan first-in-first-out (data tertua dikeluarkan terlebih dahulu).
- Kebijakan penghapusan eksplisit berdasarkan peristiwa yang dipicu (seperti data yang sedang dimodifikasi).
Membatalkan data dalam cache sisi klien
Data yang disimpan di cache sisi klien umumnya dianggap berada di luar naungan layanan yang menyediakan data ke klien. Layanan tidak dapat secara langsung memaksa klien untuk menambahkan atau menghapus informasi dari cache sisi klien.
Ini berarti bahwa klien yang menggunakan cache yang dikonfigurasi dengan buruk dapat terus menggunakan informasi usang. Misalnya, jika kebijakan kedaluwarsa cache tidak diterapkan dengan benar, klien mungkin menggunakan informasi usang yang di-cache secara lokal saat informasi di sumber data asli telah berubah.
Jika Anda membangun aplikasi web yang melayani data melalui koneksi HTTP, Anda dapat secara implisit memaksa klien web (seperti browser atau proksi web) untuk mengambil informasi terbaru. Anda dapat melakukan ini jika sumber daya diperbarui dengan perubahan URI sumber daya itu. Klien web biasanya menggunakan URI sumber daya sebagai kunci dalam cache sisi klien, jadi jika URI berubah, klien web mengabaikan versi sumber daya yang di-cache sebelumnya dan mengambil versi baru sebagai gantinya.
Mengelola konkurensi dalam cache
Cache sering dirancang untuk dibagikan oleh beberapa instans aplikasi. Setiap instans aplikasi dapat membaca dan memodifikasi data dalam cache. Akibatnya, masalah konkurensi yang sama yang muncul dengan penyimpanan data bersama juga berlaku untuk cache. Dalam situasi di mana aplikasi perlu memodifikasi data yang disimpan di cache, Anda mungkin perlu memastikan bahwa pembaruan yang dibuat oleh satu instans aplikasi tidak menimpa perubahan yang dibuat oleh instans lain.
Bergantung pada sifat data dan kemungkinan tabrakan, Anda dapat mengadopsi salah satu dari dua pendekatan untuk konkurensi:
- Optimis. Segera sebelum memperbarui data, aplikasi memeriksa untuk melihat apakah data dalam cache telah berubah sejak diambil. Jika datanya masih sama, perubahan dapat dilakukan. Jika tidak, aplikasi harus memutuskan apakah akan memperbaruinya. (Logika bisnis yang mendorong keputusan ini akan spesifik untuk aplikasi.) Pendekatan ini cocok untuk situasi di mana pembaruan jarang terjadi, atau di mana tabrakan tidak mungkin terjadi.
- Pesimistis. Saat mengambil data, aplikasi menguncinya di cache untuk mencegah instans lain mengubahnya. Proses ini memastikan bahwa tabrakan tidak dapat terjadi, tetapi mereka juga dapat memblokir instans lain yang perlu memproses data yang sama. Konkurensi pesimis dapat mempengaruhi skalabilitas solusi dan direkomendasikan hanya untuk operasi jangka pendek. Pendekatan ini mungkin sesuai untuk situasi di mana tabrakan lebih mungkin terjadi, terutama jika aplikasi memperbarui beberapa item dalam cache dan harus memastikan bahwa perubahan ini diterapkan secara konsisten.
Menerapkan ketersediaan dan skalabilitas tinggi, dan meningkatkan performa
Hindari penggunaan cache sebagai penyimpanan data utama; ini adalah peran penyimpanan data asli tempat cache diisi. Penyimpanan data asli bertanggung jawab untuk memastikan persistensi data.
Berhati-hatilah untuk tidak memasukkan dependensi kritis pada ketersediaan layanan cache bersama ke dalam solusi Anda. Aplikasi harus dapat terus berfungsi jika layanan yang menyediakan cache bersama tidak tersedia. Aplikasi tidak boleh menjadi tidak responsif atau gagal saat menunggu layanan cache dilanjutkan.
Oleh karena itu, aplikasi harus siap untuk mendeteksi ketersediaan layanan cache dan kembali ke penyimpanan data asli jika cache tidak dapat diakses. Pola Circuit-Breaker berguna untuk menangani skenario ini. Layanan yang menyediakan cache dapat dipulihkan, dan setelah tersedia, cache dapat diisi ulang saat data dibaca dari penyimpanan data asli, mengikuti strategi seperti Pola Cache-aside.
Namun, skalabilitas sistem mungkin dapat terpengaruh jika aplikasi kembali ke penyimpanan data asli saat cache tidak tersedia untuk sementara. Saat penyimpanan data sedang dipulihkan, penyimpanan data asli dapat dibanjiri permintaan data, yang mengakibatkan batas waktu dan koneksi gagal.
Pertimbangkan untuk mengimplementasikan cache pribadi lokal di setiap instans aplikasi, bersama dengan cache bersama yang diakses oleh semua instans aplikasi. Saat aplikasi mengambil item, aplikasi dapat memeriksa terlebih dahulu di cache lokalnya, lalu di cache bersama, dan terakhir di penyimpanan data asli. Cache lokal dapat diisi menggunakan data di cache bersama, atau di database jika cache bersama tidak tersedia.
Pendekatan ini memerlukan konfigurasi yang hati-hati untuk mencegah cache lokal menjadi terlalu kedaluwarsa sehubungan dengan cache bersama. Namun, cache lokal bertindak sebagai buffer jika cache bersama tidak dapat dijangkau. Gambar 3 menunjukkan struktur ini.
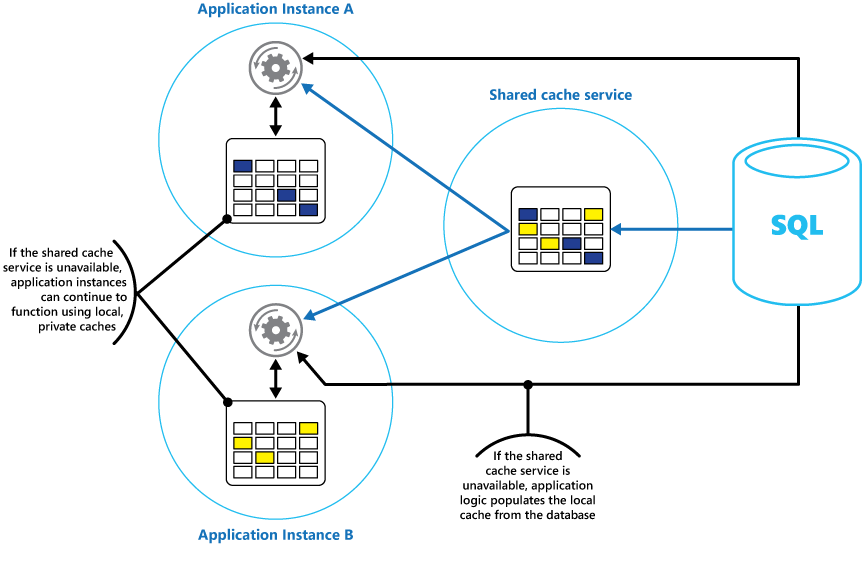
Gambar 3: Menggunakan cache pribadi lokal dengan cache bersama.
Untuk mendukung cache besar yang menyimpan data yang relatif berjangka panjang, beberapa layanan cache menyediakan opsi ketersediaan tinggi yang mengimplementasikan failover otomatis jika cache menjadi tidak tersedia. Pendekatan ini biasanya melibatkan replikasi data cache yang disimpan di server cache utama ke server cache sekunder, dan beralih ke server sekunder jika server utama gagal atau konektivitas terputus.
Untuk mengurangi latensi yang terkait dengan penulisan ke beberapa tujuan, replikasi ke server sekunder mungkin terjadi secara tidak sinkron saat data ditulis ke cache di server utama. Pendekatan ini mengarah pada kemungkinan bahwa beberapa informasi cache mungkin hilang jika ada kegagalan, tetapi proporsi data ini harus kecil, dibandingkan dengan ukuran keseluruhan cache.
Jika cache bersama berukuran besar, mungkin bermanfaat untuk mempartisi data cache di seluruh node untuk mengurangi kemungkinan pertengkaran dan meningkatkan skalabilitas. Banyak cache bersama mendukung kemampuan untuk menambahkan (dan menghapus) node secara dinamis dan menyeimbangkan kembali data di seluruh partisi. Pendekatan ini mungkin melibatkan pengelompokan, di mana kumpulan node disajikan ke aplikasi klien sebagai cache tunggal yang mulus. Secara internal, bagaimanapun, data tersebar di antara node mengikuti strategi distribusi yang telah ditentukan sebelumnya yang menyeimbangkan beban secara merata. Untuk informasi selengkapnya tentang kemungkinan strategi pemartisian, lihat Panduan pemartisian data.
Pengklusteran juga dapat meningkatkan ketersediaan cache. Jika sebuah node gagal, sisa cache masih dapat diakses. Pengklusteran sering digunakan dalam hubungannya dengan replikasi dan failover. Setiap node dapat direplikasi, dan replika dapat dengan cepat dibuat online jika node gagal.
Banyak operasi baca dan tulis cenderung melibatkan nilai atau objek data tunggal. Namun, kadang-kadang mungkin perlu untuk menyimpan atau mengambil data dalam jumlah besar dengan cepat. Misalnya, penyemaian cache dapat melibatkan penulisan ratusan atau ribuan item ke cache. Aplikasi mungkin juga perlu mengambil sejumlah besar item terkait dari cache sebagai bagian dari permintaan yang sama.
Banyak cache skala besar menyediakan operasi batch untuk tujuan ini. Hal ini memungkinkan aplikasi klien untuk memaketkan sejumlah besar item ke dalam satu permintaan dan mengurangi overhead yang terkait dengan melakukan sejumlah besar permintaan kecil.
Cache dan konsistensi peristiwa
Agar pola selain cache berfungsi, instans aplikasi yang mengisi cache harus memiliki akses ke versi data terbaru dan konsisten. Dalam sistem yang menerapkan konsistensi peristiwa (seperti penyimpanan data yang direplikasi), hal ini mungkin tidak terjadi.
Salah satu instans aplikasi dapat memodifikasi item data dan membatalkan versi cache dari item tersebut. Instans lain dari aplikasi mungkin mencoba membaca item ini dari cache, yang menyebabkan cache-miss, sehingga instans membaca data dari penyimpanan data dan menambahkannya ke cache. Namun, jika penyimpanan data belum sepenuhnya disinkronkan dengan replika lain, instans aplikasi dapat membaca dan mengisi cache dengan nilai lama.
Untuk informasi selengkapnya tentang menangani konsistensi data, lihat Dasar konsistensi data.
Lindungi data cache
Terlepas dari layanan cache yang Anda gunakan, pertimbangkan cara melindungi data yang disimpan di cache dari akses yang tidak sah. Ada dua masalah utama:
- Privasi data dalam cache.
- Privasi data saat mengalir antara cache dan aplikasi yang menggunakan cache.
Untuk melindungi data dalam cache, layanan cache mungkin menerapkan mekanisme autentikasi yang mengharuskan aplikasi menentukan hal berikut:
- Identitas mana yang dapat mengakses data dalam cache.
- Operasi mana (baca dan tulis) yang diizinkan untuk dilakukan oleh identitas ini.
Untuk mengurangi overhead yang terkait dengan membaca dan menulis data, setelah identitas diberikan akses tulis atau baca ke cache, identitas tersebut dapat menggunakan data apa pun di cache.
Jika Anda perlu membatasi akses ke subset data yang di-cache, Anda dapat melakukan salah satu hal berikut:
- Pisahkan cache menjadi beberapa partisi (dengan menggunakan server cache yang berbeda) dan hanya berikan akses ke identitas untuk partisi yang seharusnya diizinkan untuk digunakan.
- Enkripsi data di setiap subset dengan menggunakan kunci yang berbeda, dan berikan kunci enkripsi hanya untuk identitas yang seharusnya memiliki akses ke setiap subset. Aplikasi klien mungkin masih dapat mengambil semua data dalam cache, tetapi hanya dapat mendekripsi data yang memiliki kuncinya.
Anda juga harus melindungi data saat mengalir masuk dan keluar dari cache. Untuk melakukannya, Anda bergantung pada fitur keamanan yang disediakan oleh infrastruktur jaringan yang digunakan aplikasi klien untuk menyambung ke cache. Jika cache diimplementasikan menggunakan server di tempat dalam organisasi yang sama yang menghosting aplikasi klien, maka isolasi jaringan itu sendiri mungkin tidak mengharuskan Anda untuk mengambil langkah tambahan. Jika cache terletak dari jarak jauh dan memerlukan koneksi TCP atau HTTP melalui jaringan publik (seperti Internet), pertimbangkan untuk menerapkan SSL.
Pertimbangan untuk menerapkan cache di Azure
Azure Cache for Redis adalah implementasi cache Redis sumber terbuka yang berjalan sebagai layanan di pusat data Azure. Azure Cache for Redis menyediakan layanan cache yang dapat diakses dari aplikasi Azure apa pun, apakah aplikasi diimplementasikan sebagai layanan cloud, situs web, atau di dalam mesin virtual Azure. Cache dapat dibagikan oleh aplikasi klien yang memiliki kunci akses yang sesuai.
Azure Cache for Redis adalah solusi cache berperforma tinggi yang menyediakan ketersediaan, skalabilitas, dan keamanan. Solusi ini biasanya berjalan sebagai layanan yang tersebar di satu atau lebih mesin khusus. Solusi ini mencoba untuk menyimpan informasi sebanyak mungkin dalam memori untuk memastikan akses cepat. Arsitektur ini dimaksudkan untuk memberikan latensi rendah dan throughput tinggi dengan mengurangi kebutuhan untuk melakukan operasi I/O yang lambat.
Azure Cache for Redis kompatibel dengan berbagai banyak API yang digunakan oleh aplikasi klien. Jika Anda memiliki aplikasi yang sudah menggunakan Azure Cache for Redis yang berjalan lokal, Azure Cache for Redis menyediakan jalur migrasi cepat ke cache di cloud.
Fitur Redis
Redis lebih dari sekadar server cache sederhana. Redis menyediakan database dalam memori terdistribusi dengan set perintah ekstensif yang mendukung banyak skenario umum. Hal ini akan dijelaskan nanti dalam dokumen ini, di bagian Menggunakan cache Redis. Bagian ini merangkum beberapa fitur utama yang disediakan Redis.
Redis sebagai database dalam memori
Redis mendukung operasi baca dan tulis. Di Redis, penulisan dapat dilindungi dari kegagalan sistem baik dengan disimpan secara berkala dalam file snapshot lokal atau dalam file log tambahan saja. Situasi ini tidak terjadi dalam banyak cache, yang harus dianggap sebagai penyimpanan data transitori.
Semua penulisan bersifat asinkron dan tidak memblokir klien untuk membaca dan menulis data. Ketika Redis mulai berjalan, redis akan membaca data dari snapshot atau file log dan menggunakannya untuk membuat cache di dalam memori. Untuk informasi selengkapnya, lihat Persistensi Redis di situs web Redis.
Catatan
Redis tidak menjamin bahwa semua tulisan akan disimpan jika ada kegagalan bencana, tetapi pada yang terburuk Anda mungkin kehilangan hanya beberapa detik data. Ingatlah bahwa cache tidak dimaksudkan untuk bertindak sebagai sumber data otoritatif, dan merupakan tanggung jawab aplikasi yang menggunakan cache untuk memastikan bahwa data penting berhasil disimpan ke penyimpanan data yang sesuai. Untuk informasi selengkapnya, lihat Pola Cache-aside.
Jenis data Redis
Redis adalah penyimpanan nilai kunci, tempat nilai dapat berisi struktur data berjenis sederhana atau kompleks seperti hash, daftar, dan set. Redis mendukung satu set operasi atom pada jenis data ini. Kunci dapat bersifat permanen atau di-tag dengan waktu aktif yang terbatas, di mana kunci dan nilai terkaitnya secara otomatis dihapus dari cache. Untuk informasi selengkapnya tentang kunci dan nilai Redis, kunjungi halaman Pengantar jenis dan abstraksi data Redis di situs web Redis.
Replikasi dan pengklusteran Redis
Redis mendukung replikasi utama/subordinat untuk membantu memastikan ketersediaan dan mempertahankan throughput. Operasi tulis ke node utama Redis direplikasi ke satu atau lebih node subordinat. Operasi baca dapat ditampilkan oleh primer atau salah satu subordinat.
Jika Anda memiliki partisi jaringan, subordinat dapat terus melayani data dan kemudian secara transparan menyinkronkan ulang dengan yang utama ketika koneksi direestablish. Untuk detail selengkapnya, kunjungi halaman Replikasi di situs web Redis.
Redis juga menyediakan pengklusteran, yang memungkinkan Anda mempartisi data secara transparan ke dalam pecahan di seluruh server dan menyebarkan beban. Fitur ini meningkatkan skalabilitas, karena server Redis baru dapat ditambahkan dan data dipartisi ulang saat ukuran cache meningkat.
Selanjutnya, setiap server dalam kluster dapat direplikasi dengan menggunakan replikasi primer/subordinat. Hal ini memastikan ketersediaan di setiap node dalam kluster. Untuk informasi selengkapnya tentang pengklusteran dan pemecahan, kunjungi halaman tutorial kluster Redis di situs web Redis.
Penggunaan memori redis
Cache Redis memiliki ukuran terbatas yang bergantung pada sumber daya yang tersedia di komputer host. Saat Anda mengonfigurasi server Redis, Anda dapat menentukan jumlah maksimum memori yang dapat digunakannya. Anda juga dapat mengonfigurasi kunci dalam cache Redis untuk memiliki waktu kedaluwarsa, setelah itu secara otomatis dihapus dari cache. Fitur ini dapat membantu mencegah cache dalam memori terisi dengan data lama atau kedaluwarsa.
Saat memori terisi, Redis dapat secara otomatis mengeluarkan kunci dan nilainya dengan mengikuti sejumlah kebijakan. Defaultnya adalah LRU (paling tidak baru digunakan), tetapi Anda juga dapat memilih kebijakan lain seperti mengeluarkan kunci secara acak atau mematikan pengeluaran sama sekali (di mana, kasus mencoba menambahkan item ke cache gagal jika penuh). Halaman Menggunakan Redis sebagai cache LRU memberikan informasi selengkapnya.
Transaksi dan batch Redis
Redis memungkinkan aplikasi klien untuk mengirimkan serangkaian operasi yang membaca dan menulis data dalam cache sebagai transaksi atom. Semua perintah dalam transaksi dijamin berjalan secara berurutan, dan tidak ada perintah yang dikeluarkan oleh klien bersamaan lainnya yang akan terjalin di antara mereka.
Namun, ini bukan transaksi yang benar karena database relasional akan melakukannya. Pemrosesan transaksi terdiri dari dua tahap - yang pertama adalah saat perintah diantrekan, dan yang kedua adalah saat perintah dijalankan. Selama tahap antrean perintah, perintah yang terdiri dari transaksi dikiriman oleh klien. Jika beberapa jenis kesalahan terjadi pada titik ini (seperti kesalahan sintaks, atau jumlah parameter yang salah) maka Redis menolak untuk memproses seluruh transaksi dan membuangnya.
Selama fase eksekusi, Redis melakukan setiap perintah yang diantrekan secara berurutan. Jika perintah gagal selama fase ini, Redis melanjutkan dengan perintah antrean berikutnya dan tidak mengembalikan efek perintah apa pun yang telah dijalankan. Bentuk transaksi yang disederhanakan ini membantu menjaga performa dan menghindari masalah performa yang disebabkan oleh ketidaksesuaian.
Redis memang menerapkan bentuk penguncian optimis untuk membantu menjaga konsistensi. Untuk informasi mendetail tentang transaksi dan penguncian dengan Redis, kunjungi halaman Transaksi di situs web Redis.
Redis juga mendukung batch permintaan nontransaksi. Protokol Redis yang digunakan klien untuk mengirim perintah ke server Redis memungkinkan klien mengirim serangkaian operasi sebagai bagian dari permintaan yang sama. Hal ini dapat membantu mengurangi fragmentasi paket di jaringan. Ketika batch diproses, setiap perintah akan dilakukan. Jika salah satu perintah ini salah bentuk, perintah tersebut akan ditolak (yang tidak terjadi dengan transaksi), tetapi perintah yang tersisa akan dilakukan. Juga tidak ada jaminan tentang urutan di mana perintah dalam batch akan diproses.
Keamanan Redis
Redis berfokus murni pada penyediaan akses cepat ke data, dan dirancang untuk berjalan di dalam lingkungan tepercaya yang hanya dapat diakses oleh klien tepercaya. Redis mendukung model keamanan terbatas berdasarkan autentikasi kata sandi. (Dimungkinkan untuk menghapus autentikasi sepenuhnya, meskipun kami tidak merekomendasikan ini.)
Semua klien yang diautentikasi berbagi kata sandi global yang sama dan memiliki akses ke sumber daya yang sama. Jika Anda memerlukan keamanan kredensial masuk yang lebih komprehensif, Anda harus menerapkan lapisan keamanan Anda sendiri di depan server Redis, dan semua permintaan klien harus melewati lapisan tambahan ini. Redis tidak boleh langsung terekspos ke klien yang tidak tepercaya atau tidak diautentikasi.
Anda dapat membatasi akses ke perintah dengan menonaktifkannya atau mengganti namanya (dan dengan hanya menyediakan klien istimewa dengan nama baru).
Redis tidak secara langsung mendukung segala bentuk enkripsi data, sehingga semua pengodean harus dilakukan oleh aplikasi klien. Selain itu, Redis tidak menyediakan segala bentuk keamanan transportasi. Jika Anda perlu melindungi data saat mengalir di seluruh jaringan, sebaiknya terapkan proxy SSL.
Untuk informasi selengkapnya, kunjungi halaman Keamanan Redis di situs web Redis.
Catatan
Azure Cache for Redis menyediakan lapisan keamanannya sendiri yang digunakan klien untuk terhubung. Server Redis yang mendasar tidak terekspos ke jaringan publik.
Cache Azure Redis
Azure Cache for Redis menyediakan akses ke server Redis yang dihosting di pusat data Azure. Ini bertindak sebagai façade yang menyediakan kontrol akses dan keamanan. Anda dapat menyediakan cache dengan menggunakan portal Microsoft Azure.
Portal menyediakan sejumlah konfigurasi yang telah ditentukan sebelumnya. Ini berkisar dari cache 53 GB yang berjalan sebagai layanan khusus yang mendukung komunikasi SSL (untuk privasi) dan replikasi master/subordinat dengan perjanjian tingkat layanan (SLA) dengan ketersediaan 99,9%, hingga cache 250 MB tanpa replikasi (tidak ada jaminan ketersediaan) yang berjalan pada perangkat keras bersama.
Menggunakan portal Microsoft Azure, Anda juga dapat mengonfigurasi kebijakan pengeluaran cache, dan mengontrol akses ke cache dengan menambahkan pengguna ke peran yang disediakan. Peran ini, yang menentukan operasi yang dapat dilakukan anggota, termasuk Pemilik, Kontributor, dan Pembaca. Misalnya, anggota peran Pemilik memiliki kontrol penuh atas cache (termasuk keamanan) dan isinya, anggota peran Kontributor dapat membaca dan menulis informasi dalam cache, dan anggota peran Pembaca hanya dapat mengambil data dari cache.
Sebagian besar tugas administratif dilakukan melalui portal Microsoft Azure. Untuk alasan ini, banyak perintah administratif yang tersedia dalam versi standar Redis tidak tersedia, termasuk kemampuan untuk memodifikasi konfigurasi secara terprogram, mematikan server Redis, mengonfigurasi subordinat tambahan, atau menyimpan data secara paksa ke disk.
Portal Microsoft Azure menyertakan tampilan grafis praktis yang memungkinkan Anda memantau performa cache. Misalnya, Anda dapat melihat jumlah koneksi yang dibuat, jumlah permintaan yang dilakukan, volume membaca dan menulis, dan jumlah cache hit versus cache misses. Dengan menggunakan informasi ini, Anda dapat menentukan efektivitas cache dan jika perlu, beralih ke konfigurasi lain atau mengubah kebijakan pengusiran.
Selain itu, Anda dapat membuat pemberitahuan yang mengirim pesan email ke administrator jika satu atau beberapa metrik penting berada di luar rentang yang diharapkan. Misalnya, Anda mungkin ingin memberi tahu administrator jika jumlah cache yang hilang melebihi nilai yang ditentukan dalam satu jam terakhir, karena itu berarti cache mungkin terlalu kecil atau data mungkin dikeluarkan terlalu cepat.
Anda juga dapat memantau penggunaan CPU, memori, dan jaringan untuk cache.
Untuk informasi selengkapnya dan contoh yang menunjukkan cara membuat dan mengonfigurasi Azure Cache for Redis, kunjungi halaman Seputar Azure Cache for Redis di blog Azure.
Keadaan sesi cache dan output HTML
Jika Anda membuat aplikasi web ASP.NET yang berjalan dengan menggunakan peran web Azure, Anda dapat menyimpan informasi status sesi dan output HTML di Azure Cache for Redis. Penyedia status sesi untuk Azure Cache for Redis memungkinkan Anda berbagi informasi sesi antara berbagai instans aplikasi web ASP.NET, dan sangat berguna dalam situasi farm web di mana afinitas server klien tidak tersedia dan penembolokan data sesi dalam memori tidak akan sesuai.
Menggunakan penyedia status sesi dengan Azure Cache for Redis memberikan beberapa manfaat, termasuk:
- Membagikan keadaan sesi dengan sejumlah besar instans aplikasi web ASP.NET.
- Memberikan skalabilitas ditingkatkan.
- Mendukung akses konkuren yang terkontrol ke data keadaan sesi yang sama untuk banyak pembaca dan satu penulis.
- Menggunakan pemadatan untuk menghemat memori dan meningkatkan performa jaringan.
Untuk informasi selengkapnya, lihat Penyedia status sesi ASP.NET untuk Azure Cache for Redis.
Catatan
Jangan gunakan penyedia status sesi untuk Azure Cache for Redis dengan aplikasi ASP.NET yang berjalan di luar lingkungan Azure. Latensi mengakses cache dari luar Azure dapat menghilangkan manfaat performa dari cache data.
Demikian pula, penyedia cache output untuk Azure Cache for Redis memungkinkan Anda untuk menyimpan respons HTTP yang dihasilkan oleh aplikasi web ASP.NET. Menggunakan penyedia cache output dengan Azure Cache for Redis dapat meningkatkan waktu respons aplikasi yang merender output HTML yang kompleks. Instans aplikasi yang menghasilkan respons serupa dapat menggunakan fragmen output bersama dalam cache daripada menghasilkan output HTML ini lagi. Untuk informasi selengkapnya, lihat Penyedia cache output ASP.NET untuk Azure Cache for Redis.
Membangun cache Redis kustom
Azure Cache for Redis bertindak sebagai façade ke server Redis yang mendasarinya. Jika Anda memerlukan konfigurasi tingkat lanjut yang tidak tercakup oleh cache Azure Redis (seperti cache yang lebih besar dari 53 GB) Anda dapat membangun dan menghosting server Redis Anda sendiri dengan menggunakan Azure Virtual Machines.
Ini adalah proses yang berpotensi kompleks karena Anda mungkin perlu membuat beberapa mesin virtual untuk bertindak sebagai node utama dan subordinat jika Anda ingin menerapkan replikasi. Selanjutnya, jika Anda ingin membuat sebuah kluster, maka Anda memerlukan beberapa server utama dan server subordinat. Topologi replikasi berkluster minimal yang menyediakan tingkat ketersediaan dan skalabilitas yang tinggi terdiri dari setidaknya enam mesin virtual yang diatur sebagai tiga pasang server utama/subordinat (sebuah kluster harus berisi setidaknya tiga node utama).
Setiap pasangan utama/subordinat harus ditempatkan berdekatan untuk mengecilkan latensi. Namun, setiap set pasangan dapat berjalan di pusat data Azure yang berbeda yang terletak di wilayah yang berbeda, jika Anda ingin menemukan data yang di-cache dekat dengan aplikasi yang kemungkinan besar akan menggunakannya. Untuk contoh membangun dan mengonfigurasi node Redis yang berjalan sebagai mesin virtual Azure, lihat Menjalankan Redis pada mesin virtual CentOS Linux di Azure.
Catatan
Jika Anda menerapkan cache Redis Anda sendiri dengan cara ini, Anda bertanggung jawab untuk memantau, mengelola, dan mengamankan layanan.
Pemartisian cache Redis
Pemartisian cache melibatkan pemisahan cache di beberapa komputer. Struktur ini memberi Anda beberapa keuntungan dibandingkan menggunakan server cache tunggal, termasuk:
- Membuat cache yang jauh lebih besar daripada yang dapat disimpan di satu server.
- Mendistribusikan data di seluruh server, meningkatkan ketersediaan. Jika salah satu server gagal atau menjadi tidak dapat diakses, data yang disimpannya tidak tersedia, tetapi data di server yang tersisa masih dapat diakses. Untuk cache, ini tidak penting karena data yang di-cache hanyalah salinan sementara data yang disimpan dalam database. Data yang di-cache di server yang menjadi tidak dapat diakses dapat di-cache di server yang berbeda.
- Menyebarkan beban di seluruh server, sehingga meningkatkan performa dan skalabilitas.
- Geolokasi data dekat dengan pengguna yang mengaksesnya, sehingga mengurangi latensi.
Untuk cache, bentuk partisi yang paling umum adalah sharding. Dalam strategi ini, setiap partisi (atau pecahan) adalah cache Redis dalam dirinya sendiri. Data diarahkan ke partisi tertentu dengan menggunakan logika sharding, yang dapat menggunakan berbagai pendekatan untuk mendistribusikan data. Pola sharding memberikan informasi selengkapnya tentang penerapan sharding.
Untuk menerapkan pemartisian dalam cache Redis, Anda dapat mengambil salah satu pendekatan berikut:
- Perutean kueri sisi server. Dalam teknik ini, aplikasi klien mengirimkan permintaan ke salah satu server Redis yang terdiri dari cache (mungkin server terdekat). Setiap server Redis menyimpan metadata yang menjelaskan partisi yang dipegangnya, dan juga berisi informasi tentang partisi mana yang terletak di server lain. Server Redis memeriksa permintaan klien. Jika dapat diselesaikan secara lokal, server Redis akan melakukan operasi yang diminta. Jika tidak, permintaan akan diteruskan ke server yang sesuai. Model ini diterapkan oleh pengelompokan Redis, dan dijelaskan secara lebih rinci di halaman tutorial kluster Redis di situs web Redis. Pengklusteran Redis transparan untuk aplikasi klien, dan server Redis tambahan dapat ditambahkan ke kluster (dan data yang dipartisi ulang) tanpa mengharuskan Anda mengonfigurasi ulang klien.
- Pemartisian sisi klien. Dalam model ini, aplikasi klien berisi logika (mungkin dalam bentuk pustaka) yang mengarahkan permintaan ke server Redis yang sesuai. Pendekatan ini dapat digunakan dengan Azure Cache for Redis. Buat beberapa Azure Cache for Redis (satu untuk setiap partisi data) dan terapkan logika sisi klien yang merutekan permintaan ke cache yang benar. Jika skema partisi berubah (misalnya, jika Azure Cache for Redis tambahan dibuat), aplikasi klien mungkin perlu dikonfigurasi ulang.
- Partisi yang dibantu proxy. Dalam skema ini, aplikasi klien mengirim permintaan ke layanan proxy perantara yang memahami bagaimana data dipartisi dan kemudian mengarahkan permintaan ke server Redis yang sesuai. Pendekatan ini juga dapat digunakan dengan Azure Cache for Redis; layanan proxy dapat diimplementasikan sebagai layanan cloud Azure. Pendekatan ini memerlukan tingkat kerumitan tambahan untuk mengimplementasikan layanan, dan permintaan mungkin membutuhkan waktu lebih lama untuk dijalankan daripada menggunakan partisi sisi klien.
Halaman Pemartisian: cara membagi data di antara beberapa instans Redis di situs web Redis memberikan informasi selengkapnya tentang penerapan pemartisian dengan Redis.
Menerapkan aplikasi klien cache Redis
Redis mendukung aplikasi klien yang ditulis dalam berbagai bahasa pemrogram. Jika Anda membangun aplikasi baru dengan menggunakan .NET Framework, kami sarankan Anda menggunakan pustaka klien StackExchange.Redis. Pustaka ini menyediakan model objek .NET Framework yang mengabstraksi detail untuk menyambungkan ke server Redis, mengirim perintah, dan menerima respons. Ini tersedia di Visual Studio sebagai paket NuGet. Anda dapat menggunakan pustaka yang sama ini untuk menyambungkan ke Azure Cache for Redis, atau cache Redis kustom yang dihosting di mesin virtual.
Untuk menyambung ke server Redis, Anda menggunakan metode Connect statik dari kelas ConnectionMultiplexer. Koneksi yang dibuat metode ini dirancang untuk digunakan sepanjang masa pakai aplikasi klien, dan koneksi yang sama dapat digunakan oleh beberapa utas bersamaan. Jangan sambungkan kembali dan putuskan sambungan setiap kali Anda melakukan operasi Redis karena ini dapat menurunkan performa.
Anda dapat menentukan parameter koneksi, seperti alamat host Redis dan kata sandi. Jika Anda menggunakan Azure Cache for Redis, kata sandi adalah kunci primer atau sekunder yang dihasilkan untuk Azure Cache for Redis dengan menggunakan portal Azure.
Setelah tersambung ke server Redis, Anda bisa mendapatkan handel pada Database Redis yang bertindak sebagai cache. Koneksi Redis menyediakan metode GetDatabase untuk melakukan ini. Anda kemudian dapat mengambil item dari cache dan menyimpan data dalam cache dengan menggunakan metode StringGet dan StringSet. Metode ini mengharapkan kunci sebagai parameter, dan mengembalikan item dalam cache yang memiliki nilai yang cocok (StringGet) atau menambahkan item ke cache dengan kunci ini (StringSet).
Bergantung pada lokasi server Redis, banyak operasi mungkin menimbulkan beberapa latensi saat permintaan dikirim ke server dan respons dikembalikan ke klien. Pustaka StackExchange menyediakan versi asinkron dari banyak metode yang dieksposnya untuk membantu aplikasi klien tetap responsif. Metode ini mendukung Pola Asinkron berbasis tugas di .NET Framework.
Cuplikan kode berikut menunjukkan metode bernama RetrieveItem. Cuplikan kode tersebut menggambarkan implementasi pola cache-aside berdasarkan pustaka Redis dan StackExchange. Metode ini mengambil nilai kunci untai (karakter) dan mencoba untuk mengambil item yang sesuai dari cache Redis dengan memanggil metode StringGetAsync (versi asinkron dari StringGet).
Jika item tidak ditemukan, item diambil dari sumber data yang mendasar menggunakan GetItemFromDataSourceAsync metode (yang merupakan metode lokal dan bukan bagian dari pustaka StackExchange). Kemudian ditambahkan ke cache dengan menggunakan metode StringSetAsync sehingga dapat diambil lebih cepat di lain waktu.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
Metode StringGet dan StringSet tidak dibatasi untuk mengambil atau menyimpan nilai string. Mereka dapat mengambil item apa pun yang diserialisasi sebagai array byte. Jika Anda perlu menyimpan objek .NET, Anda dapat membuat serial sebagai aliran byte dan menggunakan metode StringSet untuk menulisnya ke cache.
Demikian pula, Anda dapat membaca objek dari cache dengan menggunakan metode StringGet dan melakukan deserialisasi sebagai objek .NET. Kode berikut menunjukkan sekumpulan metode ekstensi untuk antarmuka IDatabase (metode GetDatabase dari koneksi Redis mengembalikan objek IDatabase), dan beberapa kode contoh yang menggunakan metode ini untuk membaca dan menulis objek BlogPost ke cache:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
Kode berikut mengilustrasikan metode bernama RetrieveBlogPost yang menggunakan metode ekstensi ini untuk membaca dan menulis objek BlogPost yang dapat disambungkan ke cache dengan mengikuti pola cache-aside:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
Redis mendukung pipelining perintah jika aplikasi klien mengirimkan beberapa permintaan asinkron. Redis dapat melakukan multiplex permintaan menggunakan koneksi yang sama daripada menerima dan menanggapi perintah dalam urutan yang ketat.
Pendekatan ini membantu mengurangi latensi dengan membuat penggunaan jaringan lebih efisien. Cuplikan kode berikut menunjukkan contoh yang mengambil detail dua pelanggan secara bersamaan. Kode mengirimkan dua permintaan dan kemudian melakukan beberapa pemrosesan lain (tidak ditampilkan) sebelum menunggu untuk menerima hasilnya. Metode Wait objek cache mirip dengan metode .NET Framework Task.Wait:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Untuk informasi tambahan tentang menulis aplikasi klien yang dapat menggunakan Azure Cache for Redis, lihat dokumentasi Azure Cache for Redis. Informasi selengkapnya juga tersedia di StackExchange.Redis.
Halaman Pipelines and multiplexers di situs web yang sama memberikan informasi selengkapnya tentang operasi asinkron dan pipelining dengan Redis dan pustaka StackExchange.
Menggunakan cache Redis
Penggunaan Redis yang paling sederhana untuk kepentingan cache adalah pasangan kunci-nilai di mana nilainya adalah untai (karakter) panjang arbitrer yang tidak ditafsirkan yang dapat berisi data biner apa pun. (Ini pada dasarnya adalah array byte yang dapat diperlakukan sebagai string). Skenario ini diilustrasikan di bagian Menerapkan aplikasi klien Redis Cache sebelumnya di artikel ini.
Perhatikan bahwa kunci juga berisi data yang tidak ditafsirkan, sehingga Anda dapat menggunakan informasi biner apa pun sebagai kunci. Namun, semakin panjang kuncinya, semakin banyak ruang yang dibutuhkan untuk menyimpan, dan semakin lama waktu yang dibutuhkan untuk melakukan operasi pencarian. Untuk kegunaan dan kemudahan perawatan, rancang keyspace Anda dengan hati-hati dan gunakan kunci yang bermakna (tetapi panjang).
Misalnya, gunakan kunci terstruktur seperti "customer:100" untuk mewakili kunci bagi pelanggan dengan ID 100, bukan dengan hanya "100". Skema ini memungkinkan Anda untuk membedakan dengan mudah antara nilai yang menyimpan jenis data yang berbeda. Misalnya, Anda juga dapat menggunakan kunci "orders:100" untuk mewakili kunci pesanan dengan ID 100.
Terlepas dari untai (karakter) biner satu dimensi, nilai dalam pasangan kunci-nilai Redis juga dapat menyimpan informasi yang lebih terstruktur, termasuk daftar, set (diurutkan dan tidak diurutkan), dan hash. Redis menyediakan kumpulan perintah komprehensif yang dapat memanipulasi jenis ini, dan banyak dari perintah ini tersedia untuk aplikasi .NET Framework melalui pustaka klien seperti StackExchange. Halaman Pengantar jenis data dan abstraksi Redis di situs web Redis memberikan ringkasan yang lebih mendetail tentang jenis ini dan perintah yang dapat Anda gunakan untuk memanipulasinya.
Bagian ini merangkum beberapa kasus penggunaan umum untuk jenis data dan perintah ini.
Melakukan operasi atom dan batch
Redis mendukung serangkaian operasi get-and-set atom pada nilai untai (karakter). Operasi ini menghilangkan kemungkinan bahaya ras yang mungkin terjadi saat menggunakan perintah GET dan SET yang terpisah. Operasi yang tersedia meliputi:
INCR,INCRBY,DECR, danDECRBY, yang melakukan operasi penambahan dan pengurangan atom pada nilai data numerik bilangan bulat. Pustaka StackExchange menyediakan versi metodeIDatabase.StringIncrementAsyncdanIDatabase.StringDecrementAsyncyang kelebihan beban untuk melakukan operasi ini dan mengembalikan nilai yang dihasilkan yang disimpan dalam cache. Cuplikan kode berikut mengilustrasikan cara menggunakan metode ini:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSET, yang mengambil nilai yang terkait dengan kunci dan mengubahnya ke nilai baru. Pustaka StackExchange membuat operasi ini tersedia melalui metodeIDatabase.StringGetSetAsync. Cuplikan kode di bawah ini menunjukkan contoh metode ini. Kode ini mengembalikan nilai saat ini yang terkait dengan kunci "data: counter" dari contoh sebelumnya. Kemudian mengatur ulang nilai untuk kunci ini kembali ke nol, semua sebagai bagian dari operasi yang sama:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETdanMSET, yang dapat mengembalikan atau mengubah kumpulan nilai untai (karakter) sebagai operasi tunggal. MetodeIDatabase.StringGetAsyncdanIDatabase.StringSetAsynckelebihan beban untuk mendukung fungsi ini, seperti yang ditunjukkan pada contoh berikut:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Anda juga dapat menggabungkan beberapa operasi ke dalam satu transaksi Redis seperti yang dijelaskan di bagian transaksi dan kumpulan Redis di awal artikel ini. Pustaka StackExchange menyediakan dukungan untuk transaksi melalui antarmuka ITransaction.
Anda membuat objek ITransaction dengan menggunakan metode IDatabase.CreateTransaction. Anda menjalankan perintah untuk transaksi dengan menggunakan metode yang disediakan oleh objek ITransaction.
Antarmuka ITransaction menyediakan akses ke kumpulan metode yang serupa dengan yang diakses oleh antarmuka IDatabase, kecuali bahwa semua metode tidak sinkron. Ini berarti bahwa mereka hanya dilakukan ketika ITransaction.Execute metode dipanggil. Nilai yang dikembalikan oleh metode ITransaction.Execute menunjukkan apakah transaksi berhasil dibuat (benar) atau gagal (salah).
Cuplikan kode berikut menunjukkan contoh penambahan dan pengurangan dua penghitung sebagai bagian dari transaksi yang sama:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Ingatlah bahwa transaksi Redis tidak seperti transaksi dalam database relasional. Metode Execute hanya mengantrekan semua perintah yang terdiri dari transaksi yang akan dijalankan, dan jika salah satunya salah format maka transaksi dihentikan. Jika semua perintah telah berhasil diantrekan, setiap perintah berjalan secara asinkron.
Jika ada perintah yang gagal, yang lain masih melanjutkan pemrosesan. Jika Anda perlu memverifikasi bahwa sebuah perintah telah berhasil diselesaikan, Anda harus mengambil hasil dari perintah tersebut dengan menggunakan properti Result dari tugas terkait, seperti yang ditunjukkan pada contoh di atas. Membaca properti Result akan memblokir utas panggilan hingga tugas selesai.
Untuk informasi selengkapnya, lihat Transaksi di Redis.
Saat melakukan operasi batch, Anda dapat menggunakan antarmuka IBatch dari pustaka StackExchange. Antarmuka ini menyediakan akses ke set metode yang serupa dengan yang diakses oleh antarmuka IDatabase, kecuali bahwa semua metode tidak sinkron.
Anda membuat objek IBatch dengan menggunakan metode IDatabase.CreateBatch, lalu menjalankan kumpulan dengan menggunakan metode IBatch.Execute, seperti yang diperlihatkan dalam contoh berikut. Kode ini hanya menetapkan nilai string, menambah dan mengurangi penghitung yang sama yang digunakan pada contoh sebelumnya, dan menampilkan hasilnya:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
Penting untuk dipahami bahwa tidak seperti transaksi, jika perintah dalam batch gagal karena salah bentuk, perintah lain mungkin masih berjalan. Metode IBatch.Execute ini tidak mengembalikan indikasi keberhasilan atau kegagalan.
Melakukan operasi cache fire and forget
Redis mendukung operasi fire and forget dengan menggunakan bendera perintah. Dalam situasi ini, klien hanya memulai operasi tetapi tidak tertarik pada hasilnya dan tidak menunggu perintah selesai. Contoh di bawah ini menunjukkan bagaimana melakukan perintah INCR sebagai operasi fire and forget:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Tentukan kunci yang kedaluwarsa secara otomatis
Saat Anda menyimpan item dalam cache Redis, Anda dapat menentukan batas waktu setelah item tersebut akan dihapus secara otomatis dari cache. Anda juga dapat menanyakan berapa lama waktu yang dimiliki kunci sebelum habis masa berlakunya dengan menggunakan perintah TTL. Perintah ini tersedia untuk aplikasi StackExchange dengan menggunakan metode IDatabase.KeyTimeToLive.
Cuplikan kode berikut menunjukkan cara menyetel waktu kedaluwarsa 20 detik pada kunci, dan mengkueri sisa masa pakai kunci:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Anda juga dapat mengatur waktu kedaluwarsa ke tanggal dan waktu tertentu dengan menggunakan perintah EXPIRE, yang tersedia di pustaka StackExchange sebagai metode KeyExpireAsync:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Tip
Anda dapat menghapus item dari cache secara manual menggunakan perintah DEL, yang tersedia melalui pustaka StackExchange sebagai metode IDatabase.KeyDeleteAsync.
Gunakan tag untuk item yang di-cache lintas korelasi
Set Redis adalah kumpulan beberapa item yang berbagi satu kunci. Anda dapat membuat satu set dengan menggunakan perintah SADD. Anda dapat mengambil item dalam satu set dengan menggunakan perintah SMEMBERS. Pustaka StackExchange mengimplementasikan perintah SADD dengan metode IDatabase.SetAddAsync, dan perintah SMEMBERS dengan metode IDatabase.SetMembersAsync.
Anda juga dapat menggabungkan set yang ada untuk membuat set baru dengan menggunakan perintah SDIFF (set difference), SINTER (set intersection), dan SUNION (set union). Pustaka StackExchange menyatukan operasi ini dalam metode IDatabase.SetCombineAsync. Parameter pertama untuk metode ini menentukan operasi yang ditetapkan untuk dilakukan.
Cuplikan kode berikut menunjukkan bagaimana set dapat berguna untuk menyimpan dan mengambil koleksi item terkait dengan cepat. Kode ini menggunakan jenis BlogPost yang dijelaskan di bagian Menerapkan Aplikasi Klien Redis Cache di awal artikel ini.
Objek BlogPost berisi empat bidang—ID, judul, skor peringkat, dan kumpulan tag. Cuplikan kode pertama di bawah ini menunjukkan contoh data yang digunakan untuk mengisi daftar C# dari objek BlogPost:
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Anda dapat menyimpan tag untuk setiap objek BlogPost sebagai kumpulan dalam cache Redis dan mengaitkan setiap kumpulan dengan ID BlogPost. Ini memungkinkan aplikasi untuk dengan cepat menemukan semua tag yang dimiliki oleh posting blog tertentu. Untuk mengaktifkan pencarian ke arah yang berlawanan dan menemukan semua posting blog yang berbagi tag tertentu, Anda dapat membuat set lain yang menahan posting blog yang merujuk ID tag dalam kunci:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Struktur ini memungkinkan Anda melakukan banyak kueri umum dengan sangat efisien. Misalnya, Anda dapat menemukan dan menampilkan semua tag untuk posting blog 1 seperti ini:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Anda dapat menemukan semua tag yang umum untuk posting blog 1 dan posting blog 2 dengan melakukan operasi persimpangan set, sebagai berikut:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
Dan Anda dapat menemukan semua posting blog yang berisi tag tertentu:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Temukan item yang baru saja diakses
Tugas umum yang diperlukan dari banyak aplikasi adalah menemukan item yang paling baru diakses. Misalnya, situs blog mungkin ingin menampilkan informasi tentang postingan blog yang paling baru dibaca.
Anda dapat menerapkan fungsionalitas ini dengan menggunakan daftar Redis. Daftar Redis berisi beberapa item yang berbagi kunci yang sama. Daftar ini bertindak sebagai antrean ganda. Anda dapat mendorong item ke salah satu ujung daftar dengan menggunakan perintah LPUSH (left push) dan RPUSH (right push). Anda dapat mengambil item dari salah satu ujung daftar dengan menggunakan perintah LPOP dan RPOP. Anda juga dapat mengembalikan sekumpulan elemen dengan menggunakan perintah LRANGE dan RRANGE.
Cuplikan kode di bawah ini menunjukkan bagaimana Anda dapat melakukan operasi ini dengan menggunakan pustaka StackExchange. Kode ini menggunakan jenis BlogPost dari contoh sebelumnya. Saat posting blog dibaca oleh pengguna, metode IDatabase.ListLeftPushAsync mendorong judul entri blog ke daftar yang terkait dengan kunci "blog:recent_posts" di cache Redis.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Karena lebih banyak posting blog dibaca, judulnya didorong ke daftar yang sama. Daftar diurutkan berdasarkan urutan judul yang ditambahkan. Posting blog yang paling baru dibaca ada di ujung kiri daftar. (Jika posting blog yang sama dibaca lebih dari sekali, maka akan memiliki beberapa entri dalam daftar.)
Anda dapat menampilkan judul posting yang terakhir dibaca dengan menggunakan metode IDatabase.ListRange. Metode ini mengambil kunci yang berisi daftar, titik awal, dan titik akhir. Kode berikut mengambil judul dari 10 posting blog (item dari 0 hingga 9) di ujung paling kiri daftar:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Perhatikan bahwa ListRangeAsync metode tidak menghapus item dari daftar. Untuk melakukannya, Anda dapat menggunakan metode IDatabase.ListLeftPopAsync dan IDatabase.ListRightPopAsync.
Untuk mencegah daftar bertambah tanpa batas, Anda dapat secara berkala memisahkan item dengan memangkas daftar. Cuplikan kode di bawah ini menunjukkan cara menghapus semua kecuali lima item paling kiri dari daftar:
await cache.ListTrimAsync(redisKey, 0, 5);
Menerapkan papan peringkat
Secara default, item dalam set tidak disimpan dalam urutan tertentu. Anda dapat membuat set terurut dengan menggunakan perintah ZADD (metode IDatabase.SortedSetAdd di pustaka StackExchange). Item diurutkan dengan menggunakan nilai numerik yang disebut skor, yang disediakan sebagai parameter untuk perintah.
Cuplikan kode berikut menambahkan judul posting blog ke daftar berurutan. Dalam contoh ini, setiap posting blog juga memiliki bidang skor yang berisi peringkat posting blog.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Anda dapat mengambil judul dan skor posting blog dalam urutan skor menaik dengan menggunakan metode IDatabase.SortedSetRangeByRankWithScores:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Catatan
Pustaka StackExchange juga menyediakan IDatabase.SortedSetRangeByRankAsync metode , yang mengembalikan data dalam urutan skor, tetapi tidak mengembalikan skor.
Anda juga dapat mengambil item dalam urutan skor yang menurun, dan membatasi jumlah item yang dikembalikan dengan memberikan parameter tambahan ke metode IDatabase.SortedSetRangeByRankWithScoresAsync. Contoh berikut menampilkan judul dan skor dari 10 posting blog peringkat teratas:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
Contoh berikutnya menggunakan metode IDatabase.SortedSetRangeByScoreWithScoresAsync, yang dapat Anda gunakan untuk membatasi item yang dikembalikan ke item yang termasuk dalam rentang skor tertentu:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Mengirimkan pesan dengan menggunakan saluran
Selain bertindak sebagai cache data, server Redis menyediakan olahpesan melalui mekanisme database penerbit/pelanggan berperforma tinggi. Aplikasi klien dapat berlangganan saluran, dan aplikasi atau layanan lain dapat memublikasikan pesan ke saluran. Aplikasi yang berlangganan kemudian akan menerima pesan-pesan ini dan dapat memprosesnya.
Redis menyediakan perintah SUBSCRIBE untuk aplikasi klien yang digunakan untuk berlangganan saluran. Perintah ini mengharapkan nama satu atau lebih saluran tempat aplikasi akan menerima pesan. Pustaka StackExchange menyertakan antarmuka ISubscription, yang memungkinkan aplikasi .NET Framework untuk berlangganan dan menerbitkan ke saluran.
Anda membuat objek ISubscription dengan menggunakan metode GetSubscriber sambungan ke server Redis. Kemudian Anda mendengarkan pesan di saluran dengan menggunakan metode SubscribeAsync dari objek ini. Contoh kode berikut menunjukkan cara berlangganan saluran bernama "messages:blogPosts":
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
Parameter pertama metode Subscribe adalah nama saluran. Nama ini mengikuti konvensi yang sama yang digunakan oleh kunci dalam cache. Nama ini dapat berisi data biner apa pun, tetapi kami sarankan Anda menggunakan string yang relatif pendek dan bermakna untuk membantu memastikan performa dan ketahanan yang baik.
Perhatikan juga bahwa namespace layanan yang digunakan oleh saluran terpisah dari yang digunakan oleh tombol. Ini berarti Anda dapat memiliki saluran dan kunci yang memiliki nama yang sama, meskipun ini dapat membuat kode aplikasi Anda lebih sulit untuk dipertahankan.
Parameter kedua adalah delegasi Tindakan. Delegasi ini berjalan secara asinkron setiap kali pesan baru muncul di saluran. Contoh ini hanya menampilkan pesan di konsol (pesan akan berisi judul posting blog).
Untuk mempublikasikan ke saluran, aplikasi dapat menggunakan perintah Redis PUBLISH. Pustaka StackExchange menyediakan metode IServer.PublishAsync untuk melakukan operasi ini. Cuplikan kode berikutnya menunjukkan cara memublikasikan pesan ke saluran "messages:blogPosts":
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Ada beberapa poin yang harus Anda pahami tentang mekanisme publikasi/berlangganan:
- Beberapa pelanggan dapat berlangganan saluran yang sama, dan mereka semua akan menerima pesan yang diterbitkan ke saluran tersebut.
- Pelanggan hanya menerima pesan yang telah diterbitkan setelah berlangganan. Saluran tidak di-buffer, dan setelah pesan diterbitkan, infrastruktur Redis mendorong pesan ke setiap pelanggan lalu menghapusnya.
- Secara default, pesan diterima oleh pelanggan dalam urutan pengirimannya. Dalam sistem yang sangat aktif dengan sejumlah besar pesan dan banyak pelanggan dan penerbit, pengiriman pesan berurutan yang dijamin dapat memperlambat performa sistem. Jika setiap pesan independen dan urutannya tidak penting, Anda dapat mengaktifkan pemrosesan bersamaan oleh sistem Redis, yang dapat membantu meningkatkan daya tanggap. Anda dapat mencapai ini di klien StackExchange dengan menyetel PreserveAsyncOrder dari koneksi yang digunakan oleh pelanggan ke false:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Pertimbangan serialisasi
Saat Anda memilih format serialisasi, pertimbangkan pengorbanan antara performa, interoperabilitas, penerapan versi, kompatibilitas dengan sistem yang ada, pemadatan data, dan overhead memori. Saat Anda mengevaluasi performa, ingatlah bahwa tolok ukur sangat bergantung pada konteks. Tolok ukur mungkin tidak mencerminkan beban kerja Anda yang sebenarnya, dan mungkin tidak mempertimbangkan pustaka atau versi yang lebih baru. Tidak ada serializer "tercepat" tunggal untuk semua skenario.
Beberapa opsi untuk dipertimbangkan meliputi:
Protocol Buffers (juga disebut protobuf) adalah format serialisasi yang dikembangkan oleh Google untuk membuat serialisasi data terstruktur secara efisien. Format serialisasi tersebut menggunakan file definisi yang diketik dengan kuat untuk menentukan struktur pesan. File definisi ini kemudian dikompilasi ke kode khusus bahasa untuk membuat serial dan deserialisasi pesan. Protobuf dapat digunakan melalui mekanisme RPC yang ada, atau dapat menghasilkan layanan RPC.
Apache Thrift menggunakan pendekatan serupa, dengan file definisi yang diketik dengan kuat dan langkah kompilasi untuk menghasilkan kode serialisasi dan layanan RPC.
Apache Avro menyediakan fungsionalitas serupa dengan Buffer Protokol dan Thrift, tetapi tidak ada langkah kompilasi. Sebaliknya, data serial selalu menyertakan skema yang menggambarkan struktur.
JSON adalah standar terbuka yang menggunakan bidang teks yang dapat dibaca manusia. Format ini memiliki dukungan lintas platform yang luas. JSON tidak menggunakan skema pesan. Menjadi format berbasis teks, ini tidak terlalu efisien melalui kawat. Namun, dalam beberapa kasus, Anda mungkin mengembalikan item yang di-cache langsung ke klien melalui HTTP, dalam hal ini menyimpan JSON dapat menghemat biaya deserialisasi dari format lain dan kemudian membuat serialisasi ke JSON.
binary JSON (BSON) adalah format serialisasi biner yang menggunakan struktur yang mirip dengan JSON. BSON dirancang agar ringan, mudah dipindai, dan cepat untuk membuat serialisasi dan deserialisasi, relatif terhadap JSON. Payload sebanding dalam ukuran dengan JSON. Bergantung pada datanya, payload BSON mungkin lebih kecil atau lebih besar dari payload JSON. BSON memiliki beberapa jenis data tambahan yang tidak tersedia di JSON, terutama BinData (untuk array byte) dan Tanggal.
MessagePack adalah format serialisasi biner yang dirancang agar ringkas untuk transmisi melalui kawat. Tidak ada skema pesan atau pemeriksaan jenis pesan.
Bond adalah kerangka kerja lintas platform untuk bekerja dengan data skema. Ini mendukung serialisasi dan deserialisasi lintas bahasa. Perbedaan mencolok dari sistem lain yang tercantum di sini adalah dukungan untuk pewarisan, alias jenis, dan generik.
gRPC adalah sistem RPC sumber terbuka yang dikembangkan oleh Google. Secara default, format ini menggunakan Protocol Buffers sebagai bahasa definisi dan format pertukaran pesan yang mendasarinya.
Langkah berikutnya
- Dokumentasi Azure Cache for Redis
- Tanya Jawab Umum Azure Cache for Redis
- Pola Asinkron berbasis tugas
- Dokumentasi Redis
- StackExchange.Redis
- Panduan partisi data
Sumber daya terkait
Pola berikut mungkin juga relevan dengan skenario Anda saat Anda menerapkan cache di aplikasi Anda:
Pola Cache-aside: Pola ini menjelaskan cara memuat data sesuai permintaan ke dalam cache dari penyimpanan data. Pola ini juga membantu menjaga konsistensi antara data yang disimpan di cache dan data di penyimpanan data asli.
Pola sharding memberikan informasi tentang penerapan partisi horizontal untuk membantu meningkatkan skalabilitas saat menyimpan dan mengakses data dalam jumlah besar.