Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Front Door
Azure API Management
Azure Kubernetes Service (AKS)
Azure Application Gateway
Dynamics 365
Keberhasilan solusi cloud Anda tergantung pada keandalannya. Keandalan dapat didefinisikan secara luas sebagai probabilitas bahwa sistem berfungsi seperti yang diharapkan, di bawah kondisi lingkungan yang ditentukan, dalam waktu tertentu. Rekayasa keandalan situs (SRE) adalah seperangkat prinsip dan praktik untuk menciptakan sistem perangkat lunak yang dapat diskalakan dan sangat andal. Makin banyak SRE yang digunakan selama rancangan layanan digital untuk memastikan keandalan yang lebih besar.
Untuk informasi selengkapnya tentang strategi SRE, lihat AZ-400: Mengembangkan strategi Rekayasa Keandalan Situs (SRE).
Kemungkinan kasus penggunaan
Konsep dalam artikel ini berlaku untuk:
- Layanan cloud berbasis API.
- Aplikasi web yang menghadap ke publik.
- Beban kerja berbasis IoT atau berbasis peristiwa.
Sistem

Unduh file PowerPoint arsitektur ini.
Arsitektur yang dipertimbangkan di sini adalah platform API yang dapat diskalakan. Solusi ini terdiri dari beberapa layanan mikro yang menggunakan berbagai database dan layanan penyimpanan, termasuk solusi software as a service (SaaS) seperti Dynamics 365 dan Microsoft 365.
Artikel ini membahas solusi yang menangani skenario penggunaan marketplace dan e-Commerce dengan kompleksitas tinggi untuk mengilustrasikan blok yang ditampilkan dalam diagram. Kasus penggunaannya adalah:
- Penjelajahan produk.
- Pendaftaran dan login.
- Melihat konten seperti artikel berita.
- Manajemen pesanan dan langganan.
Aplikasi klien seperti aplikasi web, aplikasi seluler, dan bahkan aplikasi layanan menggunakan layanan platform API melalui jalur akses terpadu, https://api.contoso.com.
Komponen
- Azure Front Door menyediakan titik masuk terpadu yang aman untuk semua permintaan ke solusi. Untuk informasi selengkapnya, lihat Gambaran umum arsitektur perutean.
- Azure API Management menyediakan lapisan tata kelola di atas semua API yang diterbitkan. Anda dapat menggunakan kebijakan Azure API Management untuk menerapkan kemampuan tambahan pada lapisan API, seperti pembatasan akses, penembolokan, dan transformasi data. API Management mendukung autoscaling di tingkat Standar dan Premium.
- Azure Kubernetes Service (AKS) adalah implementasi Azure dari kluster Kubernetes sumber terbuka. Sebagai layanan Kubernetes yang di-host, Azure menangani tugas-tugas penting, seperti pemantauan dan pemeliharaan kesehatan. Karena Azure mengelola server API Kubernetes, Anda hanya mengelola dan memelihara simpul agen. Dalam arsitektur ini, semua layanan mikro digunakan di AKS.
- Azure Application Gateway adalah layanan pengontrol pengiriman aplikasi. Layanan ini beroperasi pada lapisan 7, lapisan aplikasi, dan memiliki berbagai kemampuan penyeimbangan beban. Application Gateway Ingress Controller (AGIC) adalah aplikasi Kubernetes yang memungkinkan pelanggan Azure Kubernetes Service (AKS) menggunakan load-balancer Azure Native Application Gateway L7 untuk mengekspos perangkat lunak cloud ke Internet. Penskalaan otomatis dan redundansi zona didukung dalam SKU v2.
- Azure Storage, Azure Data Lake Storage, Azure Cosmos DB, dan Azure SQL dapat menyimpan konten terstruktur dan tidak terstruktur. Kontainer dan database Azure Cosmos DB dapat dibuat dengan throughput skala otomatis.
- Microsoft Dynamics 365 adalah penawaran software as a service (SaaS) dari Microsoft yang menyediakan beberapa aplikasi bisnis untuk Layanan Pelanggan, Penjualan, Pemasaran, dan keuangan. Dalam arsitektur ini, Dynamics 365 terutama digunakan untuk mengelola katalog produk dan untuk manajemen Layanan Pelanggan. Unit skala memberikan ketahanan terhadap aplikasi Dynamics 365.
- Microsoft 365 (sebelumnya Office 365) digunakan sebagai sistem manajemen konten perusahaan yang dibangun di Microsoft 365 SharePoint di Microsoft 365. Ini digunakan untuk membuat, mengelola, dan memublikasikan konten seperti aset media dan dokumen.
Alternatif
Karena solusi ini menggunakan arsitektur berbasis layanan mikro yang sangat dapat diskalakan, pertimbangkan alternatif ini untuk bidang komputasi:
- Azure Functions untuk layanan API tanpa server
- Azure Spring Apps untuk layanan mikro berbasis Java
Keandalan yang sesuai
Tingkat keandalan yang diperlukan untuk solusi tergantung pada konteks bisnis. Toko outlet ritel yang buka selama 14 jam, dan yang memiliki puncak penggunaan sistem dalam rentang tersebut, memiliki persyaratan yang berbeda dari bisnis online yang menerima pesanan setiap saat. Praktik SRE dapat disesuaikan untuk mencapai tingkat keandalan yang sesuai.
Keandalan ditentukan dan diukur menggunakan tujuan tingkat layanan (tujuan tingkat layanan (SLA)) yang menentukan tingkat keandalan target untuk layanan. Mencapai tingkat target memastikan bahwa konsumen puas. Tujuan SLO dapat berkembang atau berubah tergantung pada tuntutan bisnis. Namun, pemilik layanan harus terus mengukur keandalan terhadap SLO untuk mendeteksi masalah dan mengambil tindakan korektif. SLO biasanya didefinisikan sebagai pencapaian persentase selama satu periode.
Istilah penting lainnya yang perlu diperhatikan adalah indikator tingkat layanan (indikator tingkat layanan (SLI)), yaitu metrik yang digunakan untuk menghitung SLO. SLI didasarkan pada wawasan yang berasal dari data yang ditangkap saat pelanggan menggunakan layanan. SLI selalu diukur dari sudut pandang pelanggan.
SLO dan SLI selalu berjalan beriringan, dan biasanya didefinisikan secara berulang. SLO didorong oleh tujuan bisnis utama, sedangkan SLI didorong oleh apa yang mungkin diukur saat menerapkan layanan.
Gambar berikut menunjukkan hubungan antara metrik yang dipantau, SLI, dan SLO:
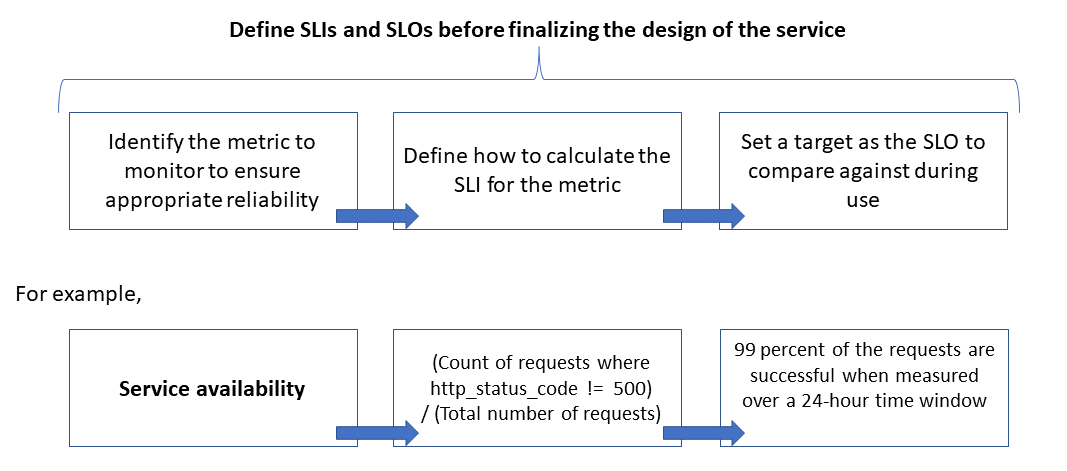
Untuk informasi selengkapnya tentang proses ini, lihat Menentukan metrik SLI untuk menghitung SLA.
Skala pemodelan dan ekspektasi performa
Untuk sistem perangkat lunak, performa umumnya mengacu pada respons keseluruhan sistem ketika melakukan tindakan dalam waktu tertentu, sementara skalabilitas adalah kemampuan sistem untuk menangani peningkatan beban pengguna tanpa merusak performa.
Sistem dianggap sebagai dapat diskalakan jika sumber daya yang mendasarinya tersedia secara dinamis untuk mendukung peningkatan beban. Aplikasi cloud harus dirancang untuk skala, dan volume lalu lintas terkadang sulit diprediksi. Lonjakan musiman dapat meningkatkan persyaratan skala, terutama ketika layanan menangani permintaan untuk beberapa penyewa.
Ini adalah praktik yang baik untuk merancang aplikasi sehingga skala sumber daya cloud naik dan turun secara otomatis sesuai kebutuhan untuk memenuhi beban. Pada dasarnya, sistem harus beradaptasi dengan peningkatan beban kerja dengan menyediakan atau mengalokasikan sumber daya secara bertahap untuk memenuhi permintaan. Skalabilitas tidak hanya berkaitan dengan instans komputasi, tetapi juga elemen lain seperti penyimpanan data dan infrastruktur olahpesan.
Artikel ini menunjukkan bagaimana Anda dapat memastikan keandalan yang sesuai untuk aplikasi cloud dengan melakukan pemodelan skala dan performa skenario beban kerja, serta menggunakan hasil untuk menentukan monitor, SLA, dan SLA.
Pertimbangan
Lihat pilar Keandalan dan Efisiensi Performa dari Azure Well Architected Framework untuk panduan membangun aplikasi yang dapat diskalakan dan andal.
Artikel ini mengeksplorasi cara menerapkan teknik skalabilitas dan pemodelan performa untuk menyempurnakan arsitektur dan rancangan solusi. Teknik-teknik ini mengidentifikasi perubahan pada alur transaksi untuk pengalaman pengguna yang optimal. Dasarkan keputusan teknis Anda pada persyaratan non-fungsional dari solusi. Prosesnya adalah:
- Identifikasi persyaratan skalabilitas.
- Modelkan beban yang diharapkan.
- Tentukan SLI dan SLO untuk skenario pengguna.
Catatan
Azure Application Insights, bagian dari Azure Monitor, adalah alat manajemen performa aplikasi (APM) yang kuat yang dapat Anda integrasikan dengan mudah dengan aplikasi Anda untuk mengirim telemetri dan menganalisis metrik khusus aplikasi. Ini juga menyediakan dasbor siap pakai dan penjelajah metrik yang dapat Anda gunakan untuk menganalisis data untuk mengeksplorasi kebutuhan bisnis.
Menangkap persyaratan skalabilitas
Asumsikan metrik beban puncak ini:
- Jumlah konsumen yang menggunakan Platform API: 1,5 juta
- Konsumen aktif per jam (30 persen dari 1,5 juta): 450.000
- Persentase beban untuk setiap aktivitas:
- Penelusuran produk: 75 persen
- Pendaftaran termasuk pembuatan profil, dan login: 10 persen
- Manajemen pesanan dan langganan: 10 persen
- Tampilan konten: 5 persen
Beban menghasilkan persyaratan skala berikut, di bawah beban puncak normal, untuk API yang di-host oleh platform:
- Layanan mikro produk: sekitar 500 permintaan per detik (RPS)
- Buat profil layanan mikro: sekitar 100 RPS
- Layanan mikro pesanan dan pembayaran: sekitar 100 RPS
- Layanan mikro konten: sekitar 50 RPS
Persyaratan skala ini tidak mempertimbangkan puncak musiman dan acak, serta puncak selama peristiwa khusus seperti promosi pemasaran. Selama puncak, persyaratan skala untuk beberapa aktivitas pengguna hingga 10 kali beban puncak normal. Ingatlah batasan dan ekspektasi ini ketika Anda membuat pilihan rancangan untuk layanan mikro.
Menentukan metrik SLI untuk menghitung SLO
Metrik SLI menunjukkan sejauh mana layanan memberikan pengalaman yang memuaskan, dan dapat dinyatakan sebagai rasio peristiwa baik terhadap total peristiwa.
Untuk layanan API, peristiwa mengacu pada metrik khusus aplikasi yang ditangkap selama eksekusi sebagai telemetri atau data yang diproses. Contoh ini memiliki metrik SLI berikut:
| Metrik | Deskripsi |
|---|---|
| Ketersediaan | Apakah permintaan tersebut dilayani oleh API |
| Latensi | Waktu bagi API untuk memproses permintaan dan mengembalikan balasan |
| Daya Tampung | Jumlah permintaan yang ditangani API |
| Tingkat Keberhasilan | Jumlah permintaan yang berhasil ditangani API |
| Tingkat Kesalahan | Jumlah kesalahan untuk permintaan yang ditangani API |
| Kesegaran | Berapa kali pengguna menerima data terbaru untuk operasi baca di API, meskipun penyimpanan data yang mendasarinya diperbarui dengan latensi tulis tertentu |
Catatan
Pastikan untuk mengidentifikasi SLI tambahan yang penting untuk solusi Anda.
Berikut adalah contoh SLI:
- (Jumlah permintaan yang berhasil diselesaikan dalam waktu kurang dari 1.000 ms)/(Jumlah permintaan)
- (Jumlah hasil pencarian yang kembali, dalam waktu tiga detik, produk apa pun yang dipublikasikan ke katalog)/(Jumlah pencarian)
Setelah Anda menentukan SLI, tentukan peristiwa atau telemetri apa yang akan ditangkap untuk mengukurnya. Misalnya, untuk mengukur ketersediaan, Anda menangkap peristiwa untuk menunjukkan apakah layanan API berhasil memproses permintaan. Untuk layanan berbasis HTTP, keberhasilan atau kegagalan ditunjukkan dengan kode status HTTP. Rancangan dan implementasi API harus memberikan kode yang tepat. Secara umum, metrik SLI merupakan input penting untuk implementasi API.
Untuk sistem berbasis cloud, Anda dapat memperoleh beberapa metrik dengan menggunakan dukungan diagnostik dan pemantauan yang tersedia untuk sumber daya. Azure Monitor adalah solusi komprehensif untuk mengumpulkan, menganalisis, dan bertindak berdasarkan telemetri layanan cloud Anda. Bergantung pada persyaratan SLI Anda, lebih banyak data pemantauan dapat ditangkap untuk menghitung metrik.
Gunakan distribusi persentil
Beberapa SLI dihitung menggunakan teknik distribusi persentil. Ini memberikan hasil yang lebih baik jika ada outlier yang dapat mencondongkan teknik lain seperti distribusi rata-rata atau median.
Misalnya, pertimbangkan bahwa metrik adalah latensi permintaan API dan tiga detik adalah ambang batas untuk performa optimal. Waktu respons yang diurutkan selama satu jam permintaan API menunjukkan bahwa beberapa permintaan memakan waktu lebih dari tiga detik, dan sebagian besar menerima respons dalam batas ambang batas. Ini adalah perilaku yang diharapkan dari sistem.
Distribusi persentil dimaksudkan untuk mengecualikan outlier yang disebabkan oleh masalah bertahap. Misalnya, jika respons layanan yang tepat berada di persentil ke-90 atau ke-95, SLO dianggap terpenuhi.
Pilih periode pengukuran yang tepat
Periode pengukuran untuk mendefinisikan SLO sangat penting. Ini harus menangkap aktivitas, bukan idleness, agar hasilnya bermakna bagi pengalaman pengguna. Jendela ini bisa berlangsung selama lima menit hingga 24 jam tergantung pada bagaimana Anda ingin memantau dan menghitung metrik SLI.
Tetapkan proses tata kelola performa
Performa API harus dikelola dari awal hingga tidak digunakan lagi atau berhenti. Proses tata kelola yang kuat harus diberlakukan untuk memastikan bahwa masalah performa terdeteksi dan diperbaiki lebih awal, sebelum menyebabkan pemadaman besar yang memengaruhi bisnis.
Berikut adalah elemen tata kelola performa:
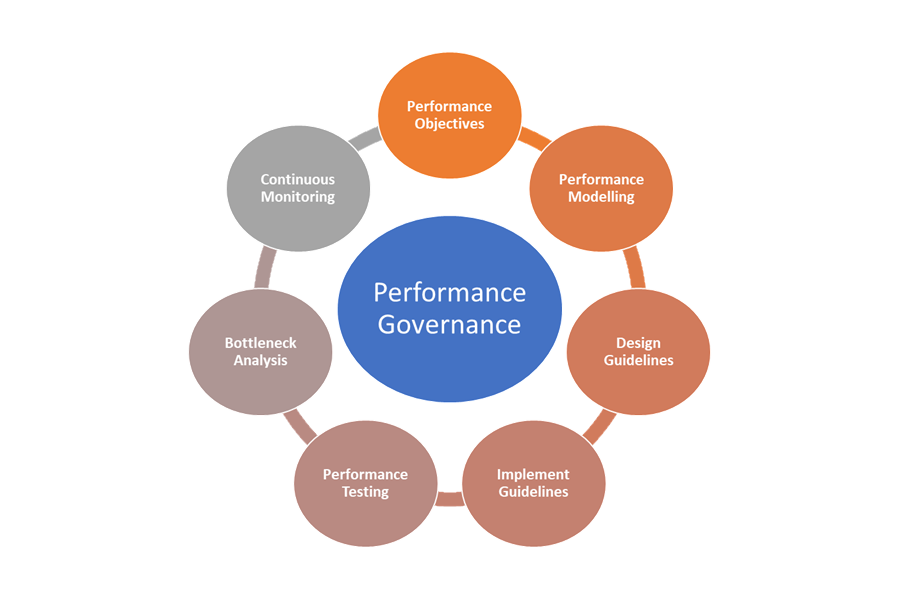
- Tujuan Performa: Menentukan SLO performa aspirasional untuk skenario bisnis.
- Pemodelan Performa: Identifikasi alur kerja dan transaksi yang penting bagi bisnis, dan lakukan pemodelan untuk memahami implikasi terkait performa. Tangkap informasi ini pada tingkat granular untuk prediksi yang lebih akurat.
- Pedoman Rancangan: Siapkan pedoman rancangan performa dan rekomendasikan modifikasi alur kerja bisnis yang sesuai. Pastikan tim memahami pedoman ini.
- Menerapkan Pedoman: Terapkan pedoman rancangan performa untuk komponen solusi, termasuk instrumentasi untuk menangkap metrik. Lakukan ulasan rancangan performa. Sangat penting untuk melacak semua ini menggunakan item backlog arsitektur untuk tim yang berbeda.
- Pengujian Performa: Lakukan pengujian beban dan tekanan sesuai dengan distribusi profil beban untuk menangkap metrik yang terkait dengan kesehatan platform. Anda juga dapat melakukan tes ini untuk beban terbatas untuk membandingkan persyaratan infrastruktur solusi.
- Analisis Penyempitan: Gunakan pemeriksaan kode dan ulasan kode untuk mengidentifikasi, menganalisis, dan menghilangkan penyempitan performa di berbagai komponen. Identifikasi peningkatan penskalaan horizontal atau vertikal yang diperlukan untuk mendukung beban puncak.
- Pemantauan Berkelanjutan: Tetapkan infrastruktur pemantauan dan peringatan berkelanjutan sebagai bagian dari proses DevOps. Pastikan bahwa tim yang bersangkutan diberi tahu ketika waktu respons menurun secara signifikan dibandingkan dengan tolok ukur.
- Tata Kelola Performa: Tetapkan tata kelola performa yang terdiri dari proses dan tim yang didefinisikan dengan baik untuk mempertahankan SLO performa. Lacak kepatuhan setelah setiap rilis untuk menghindari degradasi karena peningkatan build. Secara berkala lakukan ulasan untuk menilai peningkatan beban untuk mengidentifikasi peningkatan solusi.
Pastikan untuk mengulangi langkah-langkah selama pengembangan solusi Anda sebagai bagian dari proses elaborasi progresif.
Lacak tujuan dan ekspektasi performa di backlog Anda
Lacak tujuan performa Anda untuk membantu memastikan pencapaiannya. Tangkap cerita pengguna granular dan terperinci untuk dilacak. Ini akan membantu memastikan bahwa tim pengembangan menjadikan kegiatan tata kelola performa sebagai prioritas tinggi.
Menetapkan SLO aspirasional untuk solusi target
Berikut adalah contoh SLO aspirasional untuk solusi platform API yang sedang dipertimbangkan:
- Merespons 95 persen dari semua permintaan READ selama sehari dalam satu detik.
- Merespons 95 persen dari semua permintaan CREATE dan UPDATE selama sehari dalam waktu tiga detik.
- Merespons 99 persen dari semua permintaan selama sehari dalam waktu lima detik tanpa kegagalan.
- Merespons 99,9 persen dari semua permintaan selama sehari yang berhasil dalam waktu lima menit.
- Kurang dari satu persen permintaan selama kesalahan jendela satu jam puncak.
SLO dapat disesuaikan agar sesuai dengan persyaratan aplikasi tertentu. Namun, sangat penting untuk menjadi cukup terperinci untuk memiliki kejelasan guna memastikan keandalan.
Mengukur SLO awal yang didasarkan pada data dari log
Log pemantauan dibuat secara otomatis saat layanan API sedang digunakan. Asumsikan bahwa seminggu data menunjukkan hasil berikut:
- Permintaan: 123.456
- Permintaan yang berhasil: 123.204
- Latensi persentil ke-90: 497 ms
- Latensi persentil ke-95: 870 ms
- Latensi persentil ke-99: 1.024 ms
Data ini menghasilkan SLI awal berikut:
- Ketersediaan = (123.204/123.456) = 99,8 persen
- Latensi = setidaknya 90 persen dari permintaan dilayani dalam 500 ms
- Latensi = sekitar 98 persen dari permintaan dilayani dalam 1000 ms
Asumsikan bahwa, selama perencanaan, target SLO latensi aspirasional adalah bahwa 90 persen permintaan diproses dalam 500 ms dengan tingkat keberhasilan 99 persen selama satu minggu. Dengan data log, Anda dapat dengan mudah mengidentifikasi apakah target SLO terpenuhi. Jika Anda melakukan analisis jenis ini selama beberapa minggu, Anda dapat mulai melihat tren seputar kepatuhan SLO.
Panduan untuk mitigasi risiko teknis
Gunakan daftar periksa praktik yang direkomendasikan berikut untuk mengurangi skalabilitas dan risiko performa:
- Rancangan untuk skala dan performa.
- Pastikan Anda menangkap persyaratan skala untuk setiap skenario dan beban kerja pengguna, termasuk musiman dan puncak.
- Lakukan pemodelan performa untuk mengidentifikasi kendala dan penyempitan sistem
- Kelola utang teknis.
- Lakukan pelacakan metrik performa yang ekstensif.
- Pertimbangkan untuk menggunakan skrip untuk menjalankan alat seperti K6.io, Karate, dan JMeter pada lingkungan tahap pengembangan Anda dengan berbagai beban pengguna — 50 hingga 100 RPS, misalnya. Ini akan memberikan informasi dalam log untuk mendeteksi masalah rancangan dan implementasi.
- Integrasikan skrip pengujian otomatis sebagai bagian dari proses penyebaran berkelanjutan (CD) Anda untuk mendeteksi build break.
- Miliki pola pikir produksi.
- Sesuaikan ambang batas penskalaan otomatis seperti yang ditunjukkan oleh statistik kesehatan.
- Pilih teknik penskalaan horizontal daripada vertikal.
- Jadilah proaktif dengan penskalaan untuk menangani musiman.
- Pilih penyebaran berbasis cincin.
- Gunakan anggaran kesalahan untuk bereksperimen.
Harga
Keandalan, efisiensi performa, dan pengoptimalan biaya berjalan beriringan. Layanan Azure yang digunakan dalam arsitektur membantu mengurangi biaya, karena melakukan penskalaan otomatis untuk mengakomodasi perubahan beban pengguna.
Untuk AKS, Anda awalnya dapat memulai dengan VM berukuran standar untuk kumpulan node. Anda selanjutnya dapat memantau persyaratan sumber daya selama pengembangan atau penggunaan produksi, dan menyesuaikannya.
Pengoptimalan biaya adalah pilar dari Microsoft Azure Well-Architected Framework. Untuk informasi selengkapnya, lihat Gambaran umum pilar pengoptimalan biaya. Untuk memperkirakan biaya produk dan konfigurasi Azure, gunakan Kalkulator Harga.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Subhajit Chatterjee | Insinyur Perangkat Lunak Utama
Langkah berikutnya
- Dokumentasi Azure
- Kerangka Kerja Microsoft Azure Well-Architected
- Gaya arsitektur layanan mikro
- Desain untuk meluaskan skala
- Memilih layanan komputasi Azure untuk aplikasi Anda
- Arsitektur layanan mikro pada Azure Kubernetes Service
- Apa itu Azure Front Door?
- Tentang API Management
- Apa itu Pengontrol Ingress Application Gateway?
- Azure Kubernetes Service
- Penskalaan Otomatis dan Application Gateway v2 yang Zone-redundant
- Secara otomatis menskalakan kluster untuk memenuhi permintaan aplikasi pada Azure Kubernetes Service (AKS)
- Membuat kontainer dan database Azure Cosmos DB dengan throughput skala otomatis
- Dokumentasi Microsoft Dynamics 365
- Dokumentasi Microsoft 365
- Dokumentasi rekayasa keandalan situs
- AZ-400: Mengembangkan strategi Rekayasa Keandalan Situs (SRE)
- Aplikasi web garis besar dengan redundansi zona