Arsitektur data besar dirancang untuk menangani penyerapan, pemrosesan, dan analisis data yang terlalu besar atau kompleks untuk sistem database tradisional.

Solusi mahadata biasanya melibatkan satu atau beberapa jenis beban kerja berikut:
- Pemrosesan batch atas sumber mahadata yang tidak aktif.
- Pemrosesan real time data besar yang bergerak.
- Eksplorasi interaktif mahadata.
- Analisis prediktif dan pembelajaran mesin.
Sebagian besar arsitektur data besar mencakup beberapa atau semua komponen berikut:
Sumber data: Semua solusi data besar dimulai dengan satu atau beberapa sumber data. Contohnya meliputi:
- Penyimpanan data aplikasi, seperti database relasional.
- File statik yang dihasilkan oleh aplikasi, seperti file log server web.
- Sumber data real-time, seperti perangkat IoT.
Penyimpanan data: Data untuk operasi pemrosesan batch biasanya disimpan dalam penyimpanan file terdistribusi yang dapat menyimpan file dalam jumlah besar dengan berbagai format. Penyimpanan semacam ini sering disebut data lake. Opsi untuk menerapkan penyimpanan ini termasuk Azure Data Lake Store atau kontainer blob di Azure Storage.
Pemrosesan batch: Karena himpunan data sangat besar, solusi data besar sering kali harus memproses file data menggunakan pekerjaan batch yang berjalan lama untuk memfilter, menggabungkan, dan menyiapkan data untuk analisis. Biasanya pekerjaan ini melibatkan membaca file sumber, memprosesnya, dan menulis output ke file baru. Opsinya meliputi menjalankan pekerjaan U-SQL di Azure Data Lake Analytics, menggunakan Apache Hive, Pig, atau custom Map/Reduce jobs dalam kluster HDInsight Hadoop, atau menggunakan program Java, Scala, atau Python dalam kluster HDInsight Spark.
Penyerapan pesan real-time: Jika solusinya mencakup sumber real-time, arsitektur harus menyertakan cara untuk mengambil dan menyimpan pesan real time untuk pemrosesan aliran. Ini mungkin berupa penyimpanan data sederhana, tempat pesan masuk diletakkan ke folder untuk diproses. Namun, banyak solusi yang membutuhkan penyimpanan penyerapan pesan untuk bertindak sebagai buffer pesan, dan mendukung pemrosesan peluasan skala, pengiriman yang andal, dan semantik antrean pesan lainnya. Opsinya termasuk Azure Event Hubs, Azure IoT Hubs, dan Kafka.
Pemrosesan aliran: Setelah mengambil pesan real-time, solusi harus memprosesnya dengan memfilter, menggabungkan, dan menyiapkan data untuk analisis. Data aliran yang diproses kemudian ditulis ke sink output. Azure Stream Analytics dilengkapi dengan layanan pemrosesan aliran terkelola berdasarkan kueri SQL yang terus berjalan yang beroperasi di aliran tak terbatas. Anda juga dapat menggunakan teknologi streaming apache sumber terbuka seperti Spark Streaming dalam kluster HDInsight.
Penyimpanan data analitis: Banyak solusi data besar menyiapkan data untuk dianalisis dan kemudian melayani data yang diproses dalam format terstruktur yang dapat dikueri menggunakan alat analitik. Penyimpanan data analitis yang digunakan untuk melayani kueri ini bisa menjadi gudang data relasional bergaya Kimball, seperti yang terlihat di sebagian besar solusi inteligensi bisnis tradisional (BI). Sebagai alternatif, data dapat disajikan melalui teknologi NoSQL latensi rendah seperti HBase, atau database Interactive Hive yang menyediakan abstraksi metadata melalui file data di penyimpanan data terdistribusi. Azure Synapse Analytics menyediakan layanan terkelola untuk pergudangan data berbasis cloud dengan skala besar. HDInsight mendukung Interactive Hive, HBase, dan Spark SQL, yang juga dapat digunakan untuk menyajikan data untuk analisis.
Analisis dan pelaporan: Tujuan dari sebagian besar solusi data besar adalah memberikan wawasan tentang data melalui analisis dan pelaporan. Untuk memberdayakan pengguna dalam menganalisis data, arsitektur dapat mencakup lapisan pemodelan data, seperti kubus OLAP multidimensi atau model data berbentuk tabel di Azure Analysis Services. Ini mungkin juga mendukung BI layanan mandiri, menggunakan teknologi pemodelan dan visualisasi yang ada di Microsoft Power BI atau Microsoft Excel. Analisis dan pelaporan juga dapat berbentuk eksplorasi data interaktif oleh ilmuwan data atau analis data. Untuk skenario ini, banyak layanan Azure yang mendukung notebook analitis, seperti Jupyter, memungkinkan pengguna ini memanfaatkan keterampilannya dengan Python atau R. Untuk eksplorasi data skala besar, Anda dapat menggunakan Microsoft R Server, baik secara mandiri atau dengan Spark.
Orkestrasi: Sebagian besar solusi data besar terdiri dari operasi pemrosesan data berulang, dikemas dalam alur kerja, yang mengubah data sumber, memindahkan data antara beberapa sumber dan sink, memuat data yang diproses ke penyimpanan data analitis, atau menerapkan hasilnya langsung ke laporan atau dasbor. Untuk mengotomatiskan alur kerja ini, Anda dapat menggunakan teknologi orkestrasi seperti Azure Data Factory atau Apache Oozie dan Sqoop.
Azure mencakup banyak layanan yang dapat digunakan dalam arsitektur data besar. Secara garis besar, layanan ini dibagi menjadi dua kategori:
- Layanan terkelola, termasuk Azure Data Lake Store, Azure Data Lake Analytics, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hubs, Azure IoT Hub, dan Azure Data Factory.
- Teknologi sumber terbuka berdasarkan platform Apache Hadoop, termasuk HDFS, HBase, Apache Hive, Spark, Oozie, Sqoop, dan Kafka. Teknologi ini tersedia di Azure di layanan Azure HDInsight.
Opsi ini tidak saling eksklusif, dan banyak solusi menggabungkan teknologi sumber terbuka dengan layanan Azure.
Kapan harus menggunakan arsitektur ini
Pertimbangkan gaya arsitektur ini saat Anda perlu:
- Menyimpan dan memproses data dalam volume yang terlalu besar untuk database tradisional.
- Mengubah data yang tidak terstruktur untuk analisis dan pelaporan.
- Mengambil, memproses, dan menganalisis aliran data yang tidak terbatas secara real time, atau dengan latensi rendah.
- Gunakan Azure Pembelajaran Mesin atau Azure Cognitive Services.
Keuntungan
- Pilihan teknologi. Anda dapat menggabungkan dan mencocokkan layanan terkelola Azure dan teknologi Apache dalam kluster HDInsight, untuk memanfaatkan keterampilan atau investasi teknologi yang ada.
- Performa melalui paralelisme. Solusi data besar memanfaatkan paralelisme, memungkinkan solusi performa tinggi yang menskalakan data dalam jumlah yang besar.
- Skala elastis. Semua komponen dalam arsitektur data besar mendukung provisi peluasan skala, sehingga Anda dapat menyesuaikan solusi Anda dengan beban kerja kecil atau besar, dan hanya membayar sumber daya yang Anda gunakan.
- Interoperabilitas dengan solusi yang ada. Komponen arsitektur data besar juga digunakan untuk pemrosesan IoT dan solusi BI perusahaan, yang memungkinkan Anda membuat solusi terintegrasi di seluruh beban kerja data.
Tantangan
- Kompleksitas. Solusi data besar bisa sangat kompleks, dengan banyak komponen untuk menangani penyerapan data dari beberapa sumber data. Ini bisa menantang untuk membangun, menguji, dan memecahkan masalah proses data besar. Selain itu, mungkin ada sejumlah besar pengaturan konfigurasi di beberapa sistem yang harus digunakan untuk mengoptimalkan performa.
- Keterampilan. Banyak teknologi data besar sangat dikhususkan, dan menggunakan kerangka kerja dan bahasa yang tidak khas dari arsitektur aplikasi yang lebih umum. Di sisi lain, teknologi data besar mengembangkan API baru yang dibangun dalam bahasa yang lebih mapan. Misalnya, bahasa U-SQL di Azure Data Lake Analytics didasarkan pada kombinasi Transact-SQL dan C#. Demikian pula, API berbasis SQL tersedia untuk Apache Hive, HBase, dan Spark.
- Kematangan teknologi. Banyak teknologi yang digunakan dalam data besar mengalami perkembangan. Meski teknologi inti Hadoop seperti Apache Hive dan Pig telah stabil, teknologi yang berkembang seperti Spark menghadirkan perubahan dan peningkatan yang luas dengan setiap rilis baru. Layanan terkelola seperti Azure Data Lake Analytics dan Azure Data Factory relatif baru, dibandingkan dengan layanan Azure lainnya, dan kemungkinan akan berkembang dari waktu ke waktu.
- Keamanan. Solusi data besar biasanya bergantung pada penyimpanan semua data statik di data lake terpusat. Mengamankan akses ke data ini dapat menjadi tantangan, terutama jika data harus diserap dan dikonsumsi oleh beberapa aplikasi dan platform.
Praktik terbaik
Memanfaatkan paralelisme. Sebagian besar teknologi pemrosesan data besar mendistribusikan beban kerja di beberapa unit pemrosesan. Ini mengharuskan file data statik dibuat dan disimpan dalam format yang dapat dipisahkan. Sistem file terdistribusi seperti HDFS dapat mengoptimalkan performa baca dan tulis, dan pemrosesan aktual dilakukan oleh beberapa simpul kluster secara paralel, yang mengurangi waktu kerja secara keseluruhan.
Data partisi. Pemrosesan batch biasanya terjadi pada jadwal berulang - misalnya, mingguan atau bulanan. Partisi file data, dan struktur data seperti tabel, berdasarkan periode temporal yang sesuai dengan jadwal pemrosesan. Ini menyederhanakan penyerapan data dan penjadwalan pekerjaan, dan membuatnya lebih mudah untuk memecahkan masalah kegagalan. Selain itu, tabel partisi yang digunakan dalam kueri Apache Hive, U-SQL, atau SQL dapat meningkatkan performa kueri secara signifikan.
Menerapkan semantik skema-pada-bacaan. Menggunakan data lake memungkinkan Anda menggabungkan penyimpanan untuk file dalam beberapa format, baik terstruktur, semi terstruktur, atau tidak terstruktur. Gunakan semantik skema-pada-pembacaan, yang memproyeksikan skema ke data saat data diproses, bukan saat data disimpan. Ini membangun fleksibilitas ke dalam solusi, dan mencegah penyempitan selama penyerapan data yang disebabkan oleh validasi data dan pemeriksaan jenis.
Memproses data di tempat. Solusi BI tradisional sering kali menggunakan proses ekstrak, transformasi, dan muat (ETL) untuk memindahkan data ke gudang data. Dengan data volume yang lebih besar, dan berbagai format yang lebih besar, solusi data besar umumnya menggunakan variasi ETL, seperti transformasi, ekstrak, dan muat (TEL). Dengan pendekatan ini, data diproses dalam penyimpanan data terdistribusi, mengubahnya menjadi struktur yang diperlukan, sebelum memindahkan data yang ditransformasi ke penyimpanan data analitis.
Menyeimbangkan pemanfaatan dan biaya waktu. Untuk pekerjaan pemrosesan batch, perlu dipertimbangkan dua faktor: Biaya per unit simpul komputasi, dan biaya per menit menggunakan simpul tersebut untuk menyelesaikan pekerjaan. Misalnya, pekerjaan batch mungkin memakan waktu delapan jam dengan empat simpul kluster. Namun, kemungkinan pekerjaan menggunakan keempat simpul hanya selama dua jam pertama, dan setelah itu, hanya dua simpul yang diperlukan. Dalam hal ini, menjalankan seluruh pekerjaan di dua simpul akan meningkatkan total waktu kerja, tetapi tidak akan menggandakannya, sehingga total biayanya akan lebih sedikit. Dalam beberapa skenario bisnis, waktu pemrosesan yang lebih lama mungkin lebih disukai daripada biaya penggunaan sumber daya kluster yang kurang dimanfaatkan.
Memisahkan sumber daya kluster. Saat menyebarkan kluster HDInsight, Anda biasanya akan mencapai performa yang lebih baik dengan memprovisikan sumber daya kluster terpisah untuk setiap jenis beban kerja. Misalnya, meskipun kluster Spark menyertakan Apache Hive, jika perlu melakukan pemrosesan ekstensif dengan Apache Hive dan Spark, Anda harus mempertimbangkan untuk menerapkan kluster Spark dan Hadoop khusus yang terpisah. Demikian pula, jika Anda menggunakan HBase dan Storm untuk pemrosesan aliran latensi rendah dan Apache Hive untuk pemrosesan batch, pertimbangkan kluster terpisah untuk Storm, HBase, dan Hadoop.
Mengatur penyerapan data. Dalam beberapa kasus, aplikasi bisnis yang ada dapat menulis file data untuk pemrosesan batch langsung ke kontainer blob penyimpanan Azure, tempat file data dapat diserap oleh HDInsight atau Azure Data Lake Analytics. Namun, Anda akan sering perlu mengatur penyerapan data dari sumber data lokal atau eksternal ke dalam data lake. Gunakan alur kerja atau alur orkestrasi, seperti yang didukung oleh Azure Data Factory atau Oozie, untuk mencapai hal ini dengan cara yang dapat diprediksi dan dikelola secara terpusat.
Membuang data sensitif lebih awal. Alur kerja konsumsi data harus membuang data sensitif di awal proses, agar tidak tersimpan di data lake.
Arsitektur IoT
Internet of Things (IoT) adalah subset khusus dari solusi data besar. Diagram berikut menunjukkan kemungkinan arsitektur logis untuk IoT. Diagram ini menekankan komponen streaming peristiwa arsitektur.
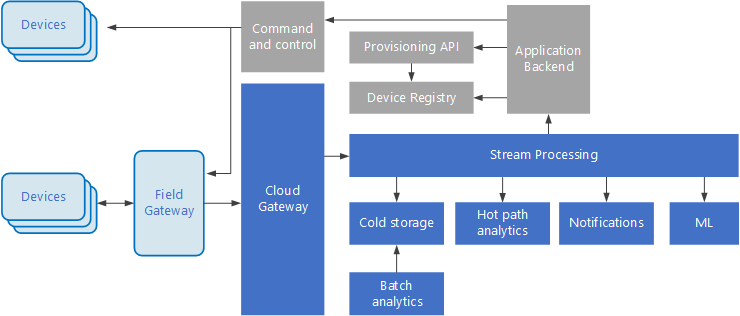
Gateway cloud menyerap peristiwa perangkat di batas cloud, menggunakan sistem pesan latensi rendah yang andal.
Perangkat dapat mengirim peristiwa secara langsung ke gateway cloud, atau melalui gateway bidang. Gateway bidang adalah perangkat atau perangkat lunak khusus, biasanya diletakkan dengan perangkat, yang menerima peristiwa dan meneruskannya ke gateway cloud. Gateway bidang juga dapat memproses peristiwa perangkat mentah, melakukan fungsi seperti pemfilteran, agregasi, atau transformasi protokol.
Setelah penyerapan, peristiwa melalui satu atau lebih pemroses aliran yang dapat merutekan data (misalnya, ke penyimpanan) atau melakukan analitik dan pemrosesan lainnya.
Berikut beberapa jenis pemrosesan yang umum. (Tentu saja tidak semuanya tercantum dalam daftar ini.)
Menulis data peristiwa ke penyimpanan dingin, untuk pengarsipan atau analitik batch.
Analisis jalur panas, menganalisis aliran peristiwa secara (mendekati) real time, untuk mendeteksi anomali, mengenali pola selama periode peluncuran, atau memicu peringatan saat kondisi tertentu terjadi di aliran.
Menangani jenis pesan non-telemetri khusus dari perangkat, seperti pemberitahuan dan alarm.
Pembelajaran mesin.
Kotak yang diarsir abu-abu menunjukkan komponen sistem IoT yang tidak terkait langsung dengan streaming peristiwa, tetapi disertakan di sini sebagai pelengkap.
Registri perangkat adalah database perangkat yang disediakan, termasuk ID perangkat dan biasanya metadata perangkat, seperti lokasi.
API provisi adalah antarmuka eksternal umum untuk menyediakan dan mendaftarkan perangkat baru.
Beberapa solusi IoT memungkinkan pesan perintah dan kontrol dikirim ke perangkat.
Bagian ini telah menyajikan pandangan tingkat tinggi tentang IoT, dan ada banyak kepelikan dan tantangan yang perlu dipertimbangkan. Untuk arsitektur referensi dan diskusi yang lebih rinci, lihat Arsitektur Referensi Microsoft Azure IoT Reference (unduhan PDF).
Langkah berikutnya
- Pelajari arsitektur data besar lebih lanjut.
- Pelajari selengkapnya tentang desain arsitektur Internet of things (IoT).