Memahami model penyimpanan data
Sistem bisnis modern mengelola volume data heterogen yang makin besar. Heterogenitas ini berarti bahwa satu penyimpanan data biasanya bukan pendekatan terbaik. Sebaliknya, ini sering kali lebih baik untuk menyimpan berbagai jenis data di penyimpanan data yang berbeda, masing-masing berfokus pada beban kerja atau pola penggunaan tertentu. Istilah persistensi poliglot digunakan untuk menjelaskan solusi yang menggunakan campuran teknologi penyimpanan data. Oleh karena itu, penting untuk memahami model penyimpanan utama dan tradeoff-nya.
Memilih penyimpanan data yang tepat untuk persyaratan Anda adalah keputusan rancangan kunci. Ada ratusan implementasi yang dapat dipilih di antara database SQL dan NoSQL. Penyimpanan data sering kali dikategorikan berdasarkan cara data disusun dan jenis operasi yang didukung. Artikel ini menjelaskan beberapa model penyimpanan yang paling umum. Perhatikan bahwa teknologi penyimpanan data tertentu dapat mendukung beberapa model penyimpanan. Misalnya, sistem manajemen database relasional (RDBMS) juga dapat mendukung penyimpanan kunci/nilai atau grafik. Bahkan, ada tren umum untuk apa yang disebut dukungan multi-model, yaitu ketika satu sistem database mendukung beberapa model. Namun, ini masih berguna untuk memahami model yang berbeda pada tingkat tinggi.
Tidak semua penyimpanan data dalam kategori tertentu menyediakan serangkaian fitur yang sama. Sebagian besar penyimpanan data menyediakan fungsionalitas sisi server untuk mengkueri dan memproses data. Terkadang fungsionalitas ini dibangun ke dalam mesin penyimpanan data. Dalam kasus lain, penyimpanan data dan kemampuan pemrosesan dipisahkan, dan mungkin ada beberapa opsi untuk pemrosesan serta analisis. Penyimpanan data juga mendukung antarmuka program dan manajemen yang berbeda.
Umumnya, Anda harus mulai dengan mempertimbangkan model penyimpanan mana yang paling sesuai untuk persyaratan Anda. Selanjutnya pertimbangkan penyimpanan data tertentu dalam kategori tersebut, berdasarkan faktor-faktor seperti serangkaian fitur, biaya, dan kemudahan manajemen.
Catatan
Pelajari selengkapnya cara mengidentifikasi dan mengulas persyaratan layanan data Anda untuk adopsi cloud, di Microsoft Cloud Adoption Framework for Azure. Demikian juga, Anda juga dapat belajar tentang memilih alat dan layanan penyimpanan.
Biaya sistem manajemen database relasional
Database hubungan mengatur data sebagai serangkaian tabel dua dimensi dengan baris dan kolom. Sebagian besar vendor menyediakan dialek Bahasa Permintaan Terstruktur (SQL) untuk mengambil dan mengelola data. RDBMS biasanya menerapkan mekanisme transaksional yang konsisten yang sesuai dengan model ACID (Atom, Konsisten, Terisolasi, Tahan Lama) untuk memperbarui informasi.
RDBMS biasanya mendukung model schema-on-write, di mana struktur data ditentukan sebelumnya, dan semua operasi baca atau tulis harus menggunakan skema.
Model ini sangat berguna ketika jaminan konsistensi yang kuat adalah penting — ketika semua perubahan bersifat atomik, dan transaksi selalu membiarkan data dalam status yang konsisten. Namun, RDBMS umumnya tidak dapat diluaskan skalanya secara horizontal tanpa membagi data dengan cara tertentu. Selain itu, data dalam RDBMS harus dinormalisasi, yang tidak sesuai untuk setiap himpunan data.
Layanan Azure
- Azure SQL Database | (Garis Besar Keamanan)
- Azure Database for MySQL | (Garis Besar Keamanan)
- Azure Database for PostgreSQL | (Garis Besar Keamanan)
- Azure Database for MariaDB | (Garis Besar Keamanan)
Beban kerja
- Rekaman sering dibuat dan diperbarui.
- Beberapa operasi harus diselesaikan dalam satu transaksi.
- Hubungan diberlakukan menggunakan batasan database.
- Indeks digunakan untuk mengoptimalkan performa kueri.
Jenis data
- Data sangat dinormalisasi.
- Skema database diperlukan dan diberlakukan.
- Hubungan banyak ke banyak di antara entitas data dalam database.
- Batasan didefinisikan dalam skema dan diberlakukan pada data apa pun dalam database.
- Data membutuhkan integritas yang tinggi. Indeks dan hubungan perlu dipertahankan secara akurat.
- Data membutuhkan konsistensi yang kuat. Transaksi beroperasi dengan cara yang memastikan semua data 100% konsisten untuk semua pengguna dan proses.
- Entri data individu berukuran kecil hingga menengah.
Contoh
- Manajemen Inventaris
- Manajemen pesanan
- Database pelaporan
- Akuntansi
Penyimpanan kunci/nilai
Penyimpanan kunci/nilai mengaitkan setiap nilai data dengan kunci unik. Sebagian besar penyimpanan kunci/nilai hanya mendukung kueri sederhana, menyisipkan, dan menghapus operasi. Untuk memodifikasi nilai (baik sebagian atau seluruhnya), aplikasi harus menimpa data yang ada untuk seluruh nilai. Dalam kebanyakan implementasi, membaca atau menulis nilai tunggal adalah operasi atomik.
Aplikasi dapat menyimpan data arbitrer sebagai sekumpulan nilai. Informasi skema apa pun harus disediakan oleh aplikasi. Penyimpanan kunci/nilai hanya mengambil atau menyimpan nilai dengan kunci.
Penyimpanan kunci/nilai sangat dioptimalkan untuk aplikasi yang melakukan pencarian sederhana, tetapi kurang cocok jika Anda perlu mengkueri data di berbagai penyimpanan kunci/nilai. Penyimpanan kunci/nilai juga tidak dioptimalkan untuk kueri berdasarkan nilai.
Satu penyimpanan kunci/nilai bisa sangat terukur, karena penyimpanan data dapat dengan mudah mendistribusikan data di beberapa node pada mesin terpisah.
Layanan Azure
- Azure Cosmos DB for Table dan Azure Cosmos DB for NoSQL | (Azure Cosmos DB Security Baseline)
- Azure Cache for Redis | (Garis Besar Keamanan)
- Azure Table Storage | (Garis Besar Keamanan)
Beban kerja
- Data diakses menggunakan satu kunci, seperti kamus.
- Tidak diperlukan gabungan, kunci, atau penyatuan.
- Tidak ada mekanisme agregasi yang digunakan.
- Indeks sekunder umumnya tidak digunakan.
Jenis data
- Setiap kunci dikaitkan dengan satu nilai.
- Tidak ada penegakan skema.
- Tidak ada hubungan di antara entitas.
Contoh
- Penembolokan data
- Manajemen sesi
- Preferensi pengguna dan manajemen profil
- Rekomendasi produk dan penayangan iklan
Database dokumen
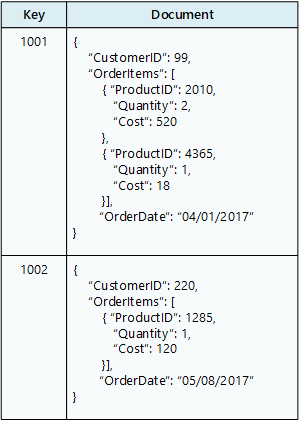
Database dokumen menyimpan kumpulan dokumen, tempat setiap dokumen terdiri dari bidang dan data bernama. Data dapat menjadi nilai sederhana atau elemen kompleks seperti daftar dan koleksi turunan. Dokumen diambil dengan kunci unik.
Biasanya, dokumen berisi data untuk satu entitas, seperti pelanggan atau pesanan. Dokumen mungkin berisi informasi yang akan tersebar di beberapa tabel relasional dalam RDBMS. Dokumen tidak perlu memiliki struktur yang sama. Aplikasi dapat menyimpan beragam data dalam dokumen saat persyaratan bisnis berubah.
Layanan Azure
Beban kerja
- Operasi sisip dan perbarui adalah hal biasa.
- Tidak ada ketidakcocokan impedansi objek-relasional. Dokumen dapat lebih cocok dengan struktur objek yang digunakan dalam kode aplikasi.
- Dokumen individu diambil dan ditulis sebagai satu blok.
- Data memerlukan indeks di berbagai bidang.
Jenis data
- Data dapat dikelola dengan cara denormalisasi.
- Ukuran data dokumen individu relatif kecil.
- Setiap jenis dokumen dapat menggunakan skemanya sendiri.
- Dokumen dapat mencakup bidang opsional.
- Data dokumen bersifat semi-terstruktur, yang berarti bahwa jenis data dari setiap bidang tidak didefinisikan secara ketat.
Contoh
- Katalog produk
- Manajemen konten
- Manajemen Inventaris
Database grafik
Database grafik menyimpan dua jenis informasi, node dan tepi. Tepi menentukan hubungan di antara node. Node dan tepi dapat memiliki properti yang memberikan informasi tentang node atau tepi, mirip dengan kolom dalam tabel. Tepi juga dapat memiliki arah yang menunjukkan sifat hubungan.
Database grafik dapat secara efisien melakukan kueri di seluruh jaringan node dan tepi serta menganalisis hubungan di antara entitas. Diagram berikut menunjukkan database personel organisasi yang tersusun sebagai grafik. Entitas adalah karyawan dan departemen, serta tepi menunjukkan hubungan pelaporan dan departemen tempat karyawan bekerja.
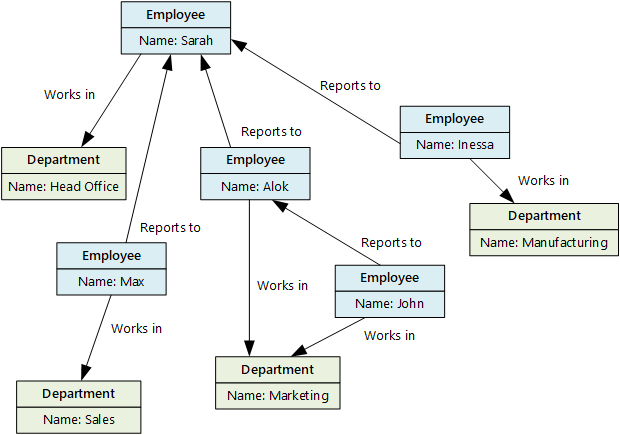
Struktur ini mempermudah untuk melakukan kueri seperti "Temukan semua karyawan yang melapor secara langsung atau tidak langsung kepada Sarah" atau "Siapa yang bekerja di departemen yang sama dengan John?" Untuk grafik besar dengan banyak entitas dan hubungan, Anda dapat melakukan analisis yang sangat kompleks dengan sangat cepat. Banyak database grafik menyediakan bahasa kueri yang dapat Anda gunakan untuk melintasi jaringan hubungan secara efisien.
Layanan Azure
Beban kerja
- Hubungan kompleks di antara item data yang melibatkan banyak lompatan di antara item data terkait.
- Hubungan di antara item data bersifat dinamis dan berubah seiring waktu.
- Hubungan di antara objek adalah warga negara kelas satu, tanpa memerlukan kunci asing dan gabungan untuk melintas.
Jenis data
- Node dan hubungan.
- Node mirip dengan baris tabel atau dokumen JSON.
- Hubungan sama pentingnya dengan node, dan diekspos langsung dalam bahasa kueri.
- Objek komposit, seperti seseorang dengan beberapa nomor telepon, cenderung dipecah menjadi node yang terpisah dan lebih kecil, dikombinasikan dengan hubungan yang dapat dilalui
Contoh
- Bagan organisasi
- Grafik sosial
- Deteksi penipuan
- Mesin rekomendasi
Analitik data
Penyimpanan analitik data menyediakan solusi paralel besar-besaran untuk menyerap, menyimpan, dan menganalisis data. Data didistribusikan di beberapa server untuk memaksimalkan skalabilitas. Format file data besar seperti file pemisah (CSV), parket, dan ORC banyak digunakan dalam analisis data. Data historis biasanya disimpan di penyimpanan data seperti penyimpanan blob atau Azure Data Lake Storage Gen2, yang selanjutnya diakses oleh Azure Synapse, Databricks, atau HDInsight sebagai tabel eksternal. Skenario khas menggunakan data yang disimpan sebagai file parket untuk performa, dijelaskan dalam artikel Menggunakan tabel eksternal dengan Synapse SQL.
Layanan Azure
- Azure Synapse Analytics | (Garis Besar Keamanan)
- Azure Data Lake | (Garis Besar Keamanan)
- Azure Data Explorer | (Garis Besar Keamanan)
- Azure Analysis Services
- HDInsight | (Garis Besar Keamanan)
- Azure Databricks | (Garis Besar Keamanan)
Beban kerja
- Analitik data
- BI Perusahaan
Jenis data
- Data historis dari beberapa sumber.
- Biasanya didenormalisasi dalam skema "bintang" atau "kepingan salju", yang terdiri dari tabel fakta dan dimensi.
- Biasanya dimuat dengan data baru secara terjadwal.
- Tabel dimensi sering kali menyertakan beberapa versi historis suatu entitas, yang disebut sebagai dimensi yang perlahan berubah.
Contoh
- Gudang data perusahaan
Database keluarga kolom
Database keluarga kolom mengatur data menjadi baris dan kolom. Dalam bentuknya yang paling sederhana, database keluarga kolom dapat muncul sangat mirip dengan database hubungan, setidaknya secara konseptual. Kekuatan sebenarnya dari database keluarga kolom terletak pada pendekatan denormalisasi untuk penyusunan data jarang.
Anda dapat menganggap database keluarga kolom sebagai penyimpanan data tabular dengan baris dan kolom, tetapi kolom dibagi menjadi kelompok yang dikenal sebagai keluarga kolom. Setiap keluarga kolom menyimpan serangkaian kolom yang terkait bersama-sama secara logis dan biasanya diambil atau dimanipulasi sebagai satu unit. Data lain yang diakses secara terpisah dapat disimpan dalam kelompok kolom terpisah. Dalam kelompok kolom, kolom baru dapat ditambahkan secara dinamis, dan baris dapat berupa jarang (yaitu, baris tidak perlu memiliki nilai untuk setiap kolom).
Diagram berikut menunjukkan contoh dengan dua kelompok kolom, Identity dan Contact Info. Data untuk satu entitas memiliki kunci baris yang sama di setiap keluarga kolom. Struktur ini, yang baris untuk objek tertentu dalam keluarga kolomnya dapat bervariasi secara dinamis, merupakan manfaat penting dari pendekatan keluarga kolom, yang membuat bentuk penyimpanan data ini sangat cocok untuk menyimpan data terstruktur yang tidak stabil.

Tidak seperti penyimpanan kunci/nilai atau database dokumen, sebagian besar database keluarga kolom menyimpan data dalam urutan kunci, bukan dengan menghitung hash. Banyak implementasi memungkinkan Anda membuat indeks di atas kolom tertentu dalam keluarga kolom. Indeks memungkinkan Anda mengambil data berdasarkan nilai kolom, bukan kunci baris.
Operasi baca dan tulis untuk baris biasanya bersifat atomik dengan satu keluarga kolom, meskipun beberapa implementasi memberikan atomitas di seluruh baris, yang mencakup beberapa keluarga kolom.
Layanan Azure
- Azure Cosmos DB for Apache Cassandra | (Garis Besar Keamanan)
- HBase di HDInsight | (Garis Besar Keamanan)
Beban kerja
- Sebagian besar database keluarga kolom melakukan operasi tulis dengan sangat cepat.
- Operasi perbarui dan hapus jarang terjadi.
- Dirancang untuk menyediakan throughput tinggi dan akses latensi rendah.
- Mendukung akses kueri yang mudah ke serangkaian bidang tertentu dalam rekaman yang jauh lebih besar.
- Dapat diskalakan secara besar-besaran.
Jenis data
- Data disimpan dalam tabel yang terdiri dari kolom kunci dan satu atau beberapa keluarga kolom.
- Kolom tertentu dapat bervariasi menurut baris individual.
- Sel individu diakses melalui perintah get dan put
- Beberapa baris dikembalikan menggunakan perintah scan.
Contoh
- Rekomendasi
- Personalisasi
- Data sensor
- telemetri
- Olahpesan
- Analitik media sosial
- Analitik web
- Pemantauan aktivitas
- Cuaca dan data deret waktu lainnya
Database Mesin Cari
Database mesin cari memungkinkan aplikasi mencari informasi yang disimpan di penyimpanan data eksternal. Database mesin cari dapat mengindeks volume data yang sangat besar dan menyediakan akses hampir real-time ke indeks ini.
Indeks dapat multi-dimensi dan dapat mendukung pencarian teks bebas di volume data teks yang besar. Pengindeksan dapat dilakukan dengan menggunakan model tarik, dipicu oleh database mesin cari, atau menggunakan model push, yang diprakarsai oleh kode aplikasi eksternal.
Pencarian bisa tepat atau fuzzy. Pencarian yang kabur akan menemukan dokumen yang cocok dengan serangkaian istilah dan menghitung seberapa dekat kecocokannya. Beberapa mesin cari juga mendukung analisis linguistik yang dapat mengembalikan kecocokan berdasarkan sinonim, ekspansi genre (misalnya, mencocokkan dogs dengan pets), dan stemming (mencocokkan kata-kata dengan akar yang sama).
Layanan Azure
Beban kerja
- Indeks data dari berbagai sumber dan layanan.
- Kueri bersifat ad-hoc dan bisa kompleks.
- Pencarian teks lengkap diperlukan.
- Kueri layanan mandiri ad hoc diperlukan.
Jenis data
- Teks semi-terstruktur atau tidak terstruktur
- Teks dengan referensi ke data terstruktur
Contoh
- Katalog produk
- Pencarian situs
- Pencatatan
Data deret waktu
Data deret waktu adalah sekumpulan nilai yang diatur oleh waktu. Database deret waktu biasanya mengumpulkan sejumlah besar data secara real time dari sejumlah besar sumber. Pembaruan jarang terjadi, dan penghapusan sering kali dilakukan sebagai operasi massal. Meskipun rekaman yang ditulis ke database deret waktu umumnya kecil, sering kali ada sejumlah besar rekaman, dan ukuran data total dapat tumbuh dengan cepat.
Layanan Azure
Beban kerja
- Rekaman umumnya ditambahkan secara berurutan dalam urutan waktu.
- Proporsi operasi yang besar (95-99%) adalah tulis.
- Pembaruan jarang terjadi.
- Penghapusan terjadi dalam jumlah besar, dan dibuat untuk blok atau rekaman yang berdekatan.
- Data dibaca secara berurutan baik dalam urutan waktu naik maupun turun, sering kali secara paralel.
Jenis data
- Stempel waktu digunakan sebagai kunci utama dan mekanisme pengurutan.
- Tag dapat mendefinisikan informasi tambahan tentang jenis, asal, dan informasi lain tentang entri.
Contoh
- Pemantauan dan telemetri peristiwa.
- Sensor atau data IoT lainnya.
Penyimpanan objek
Penyimpanan objek dioptimalkan untuk menyimpan dan mengambil objek biner besar (gambar, file, aliran video dan audio, objek dan dokumen data aplikasi besar, gambar disk mesin virtual). File data besar juga umumnya digunakan dalam model ini, misalnya, file pemisah (CSV), parket, dan ORC. Penyimpanan objek dapat mengelola sejumlah besar data tidak terstruktur.
Layanan Azure
Beban kerja
- Diidentifikasi dengan kunci.
- Konten biasanya merupakan aset seperti pemisah, gambar, atau file video.
- Konten harus tahan lama dan terlihat ke tingkat aplikasi apa pun.
Jenis data
- Ukuran datanya besar.
- Nilainya buram.
Contoh
- Gambar, video, dokumen kantor, PDF
- HTML status, JSON, CSS
- File log dan audit
- Cadangan database
File bersama
Terkadang, menggunakan file datar sederhana bisa menjadi cara paling efektif untuk menyimpan dan mengambil informasi. Menggunakan berbagi file memungkinkan file diakses di seluruh jaringan. Mengingat keamanan yang sesuai dan mekanisme kontrol akses bersamaan, berbagi data dengan cara ini dapat memungkinkan layanan terdistribusi menyediakan akses data yang sangat terukur untuk melakukan operasi dasar tingkat rendah seperti permintaan baca dan tulis sederhana.
Layanan Azure
Beban kerja
- Migrasi dari aplikasi yang ada yang berinteraksi dengan sistem file.
- Membutuhkan antarmuka SMB.
Jenis data
- File dalam satu rangkaian hierarkis folder.
- Dapat diakses dengan pustaka I/O standar.
Contoh
- Berkas warisan
- Konten bersama yang dapat diakses di antara sejumlah VM atau instans aplikasi
Dibantu dengan pemahaman tentang model penyimpanan data yang berbeda ini, langkah selanjutnya adalah mengevaluasi beban kerja dan aplikasi Anda, serta memutuskan penyimpanan data mana yang akan memenuhi kebutuhan spesifik Anda. Gunakan pohon keputusan penyimpanan data untuk membantu proses ini.
Langkah berikutnya
- Solusi dan Layanan Azure Cloud Storage
- Meninjau opsi penyimpanan Anda
- Pengenalan Azure Storage
- Pengantar Azure Data Explorer
Sumber daya terkait
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk