Kecerdasan Buatan menawarkan potensi untuk mengubah ritel seperti yang kita ketahui saat ini. Sangat masuk akal untuk percaya bahwa peritel akan mengembangkan arsitektur pengalaman pelanggan yang didukung oleh AI. Beberapa harapan adalah bahwa platform yang ditingkatkan dengan AI akan memberikan benjolan pendapatan karena personalisasi hiper. Perdagangan digital terus memperketat ekspektasi, preferensi, dan perilaku pelanggan. Tuntutan seperti keterlibatan real-time, rekomendasi yang relevan, dan hyper-personalisasi mendorong kecepatan dan kenyamanan dengan sekali klik tombol. Kami mengaktifkan kecerdasan dalam aplikasi melalui ucapan alami, visi, dan sebagainya. Kecerdasan ini memungkinkan peningkatan ritel yang akan meningkatkan nilai sekaligus mengganggu cara pelanggan berbelanja.
Dokumen ini berfokus pada konsep AI pencarian visual dan menawarkan beberapa pertimbangan utama tentang implementasinya. Dokumen ini memberikan contoh alur kerja dan memetakan tahapannya ke teknologi Azure yang relevan. Konsep ini didasarkan pada pelanggan yang dapat memanfaatkan gambar yang diambil dengan perangkat seluler mereka atau yang terletak di internet. Mereka akan melakukan pencarian item yang relevan dan seperti, tergantung pada niat pengalaman. Dengan demikian, pencarian visual meningkatkan kecepatan dari entri teks ke gambar dengan beberapa titik meta-data untuk dengan cepat memunculkan semua item yang berlaku yang tersedia.
Mesin pencari visual
Mesin pencari visual mengambil informasi menggunakan gambar sebagai input dan sering—tetapi tidak secara eksklusif—sebagai output juga.
Mesin menjadi semakin umum di industri ritel, dan karena alasan yang sangat baik:
- Sekitar 75% pengguna internet mencari gambar atau video produk sebelum melakukan pembelian, menurut laporan Emarketer yang diterbitkan pada 2017.
- 74% konsumen juga menemukan pencarian teks tidak efisien, menurut laporan Slyce (perusahaan pencarian visual) 2015.
Oleh karena itu, pasar pengenalan gambar akan bernilai lebih dari $ 25 miliar pada tahun 2019, menurut penelitian oleh Markets & Markets.
Teknologi ini telah dipegang dengan merek e-niaga utama, yang juga telah berkontribusi secara signifikan terhadap perkembangannya. Pengadopsi awal yang paling menonjol mungkin:
- eBay dengan alat Image Search dan "Find It on eBay" di aplikasi mereka (saat ini hanya pengalaman seluler).
- Pinterest dengan alat penemuan visual Lens mereka.
- Microsoft dengan Bing Visual Search.
Mengadopsi dan mengadaptasi
Untungnya, Anda tidak memerlukan sejumlah besar daya komputasi untuk mendapatkan keuntungan dari pencarian visual. Bisnis apa pun dengan katalog gambar dapat memanfaatkan keahlian AI Microsoft yang terpasang dalam layanan Azure-nya.
Bing Visual Search API menyediakan cara untuk mengekstrak informasi konteks dari gambar, mengidentifikasi—misalnya—perabot rumah tangga, mode, beberapa jenis produk, dan sebagainya.
Ini juga akan mengembalikan gambar yang mirip secara visual dari katalognya sendiri, produk dengan sumber belanja relatif, pencarian terkait. Meskipun menarik, ini akan menjadi penggunaan terbatas jika perusahaan Anda bukan salah satu sumber tersebut.
Bing juga akan menyediakan:
- Tag yang memungkinkan Anda menjelajahi objek atau konsep yang ditemukan dalam gambar.
- Kotak pembatas untuk wilayah yang menarik dalam gambar (seperti untuk pakaian atau barang furnitur).
Anda dapat mengambil informasi tersebut untuk mengurangi ruang pencarian (dan waktu) ke dalam katalog produk perusahaan secara signifikan, membatasinya ke objek seperti yang ada di wilayah dan kategori minat.
Terapkan sendiri
Ada beberapa komponen utama yang perlu dipertimbangkan saat menerapkan pencarian visual:
- Menyerap dan memfilter gambar
- Teknik penyimpanan dan pengambilan
- Fiturisasi, pengodean, atau "hashing"
- Ukuran atau jarak dan peringkat kesamaan

Gambar 1: Contoh Alur Pencarian Visual
Sumber gambar
Jika Anda tidak memiliki katalog gambar, Anda mungkin perlu melatih algoritma pada himpunan data yang tersedia secara terbuka, seperti MNIST mode, mode mendalam, dan sebagainya. Mereka berisi beberapa kategori produk dan umumnya digunakan untuk tolok ukur kategorisasi gambar dan algoritma pencarian.

Gambar 2: Contoh dari himpunan data DeepFashion
Memfilter gambar
Sebagian besar himpunan data tolok ukur, seperti yang disebutkan sebelumnya, telah diproses sebelumnya.
Jika Anda membangun tolok ukur Anda sendiri, minimal Anda akan ingin gambar semuanya memiliki ukuran yang sama, sebagian besar ditentukan oleh input yang dilatih model Anda.
Dalam banyak kasus, yang terbaik juga adalah menormalkan luminositas gambar. Tergantung pada tingkat detail pencarian Anda, warna mungkin juga informasi redundan, sehingga mengurangi hitam dan putih akan membantu memproses waktu.
Terakhir tetapi tidak kalah pentingnya, himpunan data gambar harus diseimbangkan di berbagai kelas yang diwakilinya.
Database gambar
Lapisan data adalah komponen arsitektur Anda yang sangat halus. Ini akan berisi:
- Gambar
- Metadata apa pun tentang gambar (ukuran, tag, SKU produk, deskripsi)
- Data yang dihasilkan oleh model pembelajaran mesin (misalnya vektor numerik 4096 elemen per gambar)
Saat Anda mengambil gambar dari sumber yang berbeda atau menggunakan beberapa model pembelajaran mesin untuk performa optimal, struktur data akan berubah. Oleh karena itu penting untuk memilih teknologi atau kombinasi yang dapat menangani data semi terstruktur dan tidak ada skema tetap.
Anda mungkin juga ingin memerlukan jumlah minimum titik data yang berguna (seperti pengidentifikasi gambar atau kunci, sku produk, deskripsi, atau bidang tag).
Azure Cosmos DB menawarkan fleksibilitas yang diperlukan dan berbagai mekanisme akses untuk aplikasi yang dibangun di atasnya (yang akan membantu pencarian katalog Anda). Namun, seseorang harus berhati-hati untuk mendorong harga/performa terbaik. Azure Cosmos DB memungkinkan lampiran dokumen disimpan, tetapi ada batas total per akun dan mungkin merupakan proposisi yang mahal. Ini adalah praktik umum untuk menyimpan file gambar aktual dalam blob dan menyisipkan tautan ke file tersebut dalam database. Dalam kasus Azure Cosmos DB ini menyiratkan pembuatan dokumen yang berisi properti katalog yang terkait dengan gambar tersebut (seperti SKU, tag, dan sebagainya) dan lampiran yang berisi URL file gambar (misalnya, pada penyimpanan Azure Blob, OneDrive, dan sebagainya).

Gambar 3: Model Sumber Daya Hierarkis Azure Cosmos DB
Jika Anda berencana untuk memanfaatkan distribusi global Azure Cosmos DB, perhatikan bahwa itu akan mereplikasi dokumen dan lampiran, tetapi bukan file yang ditautkan. Anda mungkin ingin mempertimbangkan jaringan distribusi konten untuk jaringan tersebut.
Teknologi lain yang berlaku adalah kombinasi dari Azure SQL Database (jika skema tetap dapat diterima) dan blob, atau bahkan Tabel dan blob Azure untuk penyimpanan dan pengambilan yang murah dan cepat.
Ekstraksi fitur & pengodean
Proses pengodean mengekstrak fitur penting dari gambar dalam database dan memetakan masing-masing ke vektor "fitur" jarang (vektor dengan banyak nol) yang dapat memiliki ribuan komponen. Vektor ini adalah representasi numerik dari fitur (seperti tepi dan bentuk) yang mencirikan gambar. Ini mirip dengan kode.
Teknik ekstraksi fitur biasanya menggunakan mekanisme pembelajaran transfer. Ini terjadi ketika Anda memilih jaringan neural yang telah dilatih sebelumnya, jalankan setiap gambar melaluinya dan simpan vektor fitur yang dihasilkan kembali di database gambar Anda. Dengan cara itu, Anda "mentransfer" pembelajaran dari siapa pun yang melatih jaringan. Microsoft telah mengembangkan dan menerbitkan beberapa jaringan pra-terlatih yang telah banyak digunakan untuk tugas pengenalan gambar, seperti ResNet50.
Tergantung pada jaringan saraf, vektor fitur akan lebih atau kurang panjang dan jarang, sehingga persyaratan memori dan penyimpanan akan bervariasi.
Selain itu, Anda mungkin menemukan bahwa jaringan yang berbeda berlaku untuk kategori yang berbeda, oleh karena itu implementasi pencarian visual dapat benar-benar menghasilkan vektor fitur dengan berbagai ukuran.
Jaringan neural yang telah dilatih sebelumnya relatif mudah digunakan tetapi mungkin tidak seefisien model kustom yang dilatih pada katalog gambar Anda. Jaringan yang telah dilatih sebelumnya biasanya dirancang untuk klasifikasi himpunan data tolok ukur daripada mencari kumpulan gambar spesifik Anda.
Anda mungkin ingin memodifikasi dan melatihnya kembali sehingga menghasilkan prediksi kategori dan vektor padat (yaitu vektor yang lebih kecil, tidak jarang), yang akan sangat berguna untuk membatasi ruang pencarian, mengurangi persyaratan memori dan penyimpanan. Vektor biner dapat digunakan dan sering disebut sebagai " hash semantik" - istilah yang berasal dari teknik pengodean dan pengambilan dokumen. Representasi biner menyederhanakan perhitungan lebih lanjut.
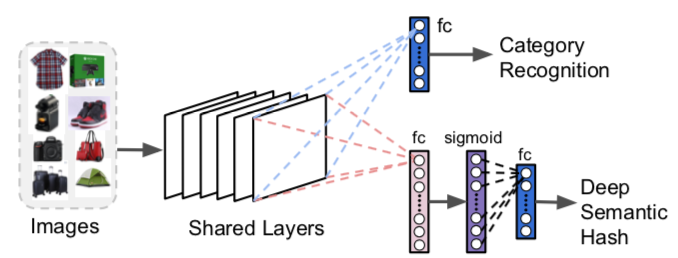
Gambar 4: Modifikasi pada ResNet untuk Pencarian Visual – F. Yang et al., 2017
Apakah Anda memilih model yang telah dilatih sebelumnya atau untuk mengembangkan model Anda sendiri, Anda masih perlu memutuskan di mana menjalankan fiturisasi dan/atau pelatihan model itu sendiri.
Azure menawarkan beberapa opsi: VM, Azure Batch, Batch AI, kluster Databricks. Namun, dalam semua kasus, harga/performa terbaik diberikan oleh penggunaan GPU.
Microsoft juga baru-baru ini mengumumkan ketersediaan FPGA untuk komputasi cepat dengan sebagian kecil dari biaya GPU (proyek Brainwave). Namun, pada saat penulisan, penawaran ini terbatas pada arsitektur jaringan tertentu, jadi Anda harus mengevaluasi performanya dengan ketat.
Ukuran atau jarak kesamaan
Ketika gambar diwakili dalam ruang vektor fitur, menemukan kesamaan menjadi pertanyaan untuk menentukan ukuran jarak antara titik-titik di ruang tersebut. Setelah jarak ditentukan, Anda dapat menghitung kluster gambar serupa dan/atau menentukan matriks kesamaan. Bergantung pada metrik jarak yang dipilih, hasilnya dapat bervariasi. Ukuran jarak Euclidean yang paling umum atas vektor angka nyata, misalnya, mudah dipahami: ia menangkap besarnya jarak. Namun, itu agak tidak efisien dalam hal komputasi.
Jarak kosinus sering digunakan untuk menangkap orientasi vektor, daripada besarnya.
Alternatif seperti Jarak hamming atas representasi biner memperdagangkan beberapa akurasi untuk efisiensi dan kecepatan.
Kombinasi ukuran vektor dan ukuran jarak akan menentukan seberapa intensif komputasi dan intensif memori pencarian.
Pencarian & peringkat
Setelah kesamaan didefinisikan, kita perlu merancang metode yang efisien untuk mengambil item N terdekat dengan yang diteruskan sebagai input, lalu mengembalikan daftar pengidentifikasi. Ini juga dikenal sebagai "peringkat gambar". Pada himpunan data besar, waktu untuk menghitung setiap jarak dilarang, jadi kami menggunakan perkiraan algoritma tetangga terdekat. Beberapa pustaka sumber terbuka ada untuk pustaka tersebut, sehingga Anda tidak perlu mengkodekannya dari awal.
Akhirnya, persyaratan memori dan komputasi akan menentukan pilihan teknologi penyebaran untuk model terlatih, serta ketersediaan tinggi. Biasanya, ruang pencarian akan dipartisi, dan beberapa instans algoritma peringkat akan berjalan secara paralel. Salah satu opsi yang memungkinkan skalabilitas dan ketersediaan adalah kluster Azure Kubernetes . Dalam hal ini, disarankan untuk menyebarkan model peringkat di beberapa kontainer (menangani partisi ruang pencarian masing-masing) dan beberapa simpul (untuk ketersediaan tinggi).
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Giovanni Marchetti | Manajer, Arsitek Solusi Azure
- Mariya Zorotovich | Head of Customer Experience, HLS & Emerging Technology
Kontributor lain:
- Scott Seely | Arsitek Perangkat Lunak
Langkah berikutnya
Menerapkan pencarian visual tidak perlu kompleks. Anda dapat menggunakan Bing atau membangun sendiri dengan layanan Azure, sambil mendapatkan manfaat dari penelitian dan alat AI Microsoft.
Kembangkan
- Untuk mulai membuat layanan yang disesuaikan, lihat Gambaran Umum Bing Visual Search API
- Untuk membuat permintaan pertama Anda, lihat mulai cepat: C# | Java | node.js | Python
- Biasakan diri Anda dengan Referensi VISUAL Search API.
Latar belakang
- Segmentasi Gambar Pembelajaran Mendalam: Makalah Microsoft menjelaskan proses pemisahan gambar dari latar belakang
- Pencarian Visual di Ebay: Penelitian Cornell University
- Penemuan Visual di penelitian Pinterest Cornell University
- Penelitian Semantic Hashing University of Toronto