Artikel ini menjelaskan pertimbangan untuk mengelola data di dalam arsitektur layanan mikro. Karena setiap layanan mikro mengelola datanya sendiri, integritas dan konsistensi data adalah tantangan kritis.
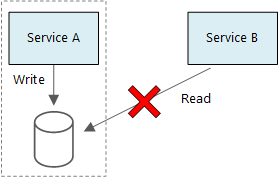
Prinsip dasar layanan mikro adalah setiap layanan mengelola datanya sendiri. Dua layanan tidak boleh berbagi penyimpanan data. Sebaliknya, setiap layanan bertanggung jawab atas penyimpanan data pribadinya sendiri, yang tidak dapat diakses oleh layanan lain secara langsung.
Alasan aturan ini adalah untuk menghindari sambungan yang tidak disengaja antara layanan, yang dapat terjadi jika layanan berbagi skema data dasar yang sama. Jika ada perubahan pada skema data, perubahan harus dikoordinasikan di setiap layanan yang bergantung pada database itu. Dengan mengisolasi penyimpanan data masing-masing layanan, kita dapat membatasi ruang lingkup perubahan, dan menjaga kelincahan penyebaran yang benar-benar independen. Alasan lain adalah setiap layanan mikro mungkin memiliki model data, kueri, atau pola baca/tulisnya sendiri. Menggunakan penyimpanan data bersama membatasi kemampuan setiap tim untuk mengoptimalkan penyimpanan data untuk layanan khusus mereka.
Pendekatan ini secara alami mengarah pada persistensi poliglot — penggunaan beberapa teknologi penyimpanan data dalam satu aplikasi. Satu layanan mungkin memerlukan kemampuan skema-on-read database dokumen. Yang lain mungkin membutuhkan integritas referensial yang disediakan oleh RDBMS. Setiap tim bebas membuat pilihan terbaik bagi layanan mereka.
Catatan
Layanan bisa berbagi server database fisik yang sama. Masalah terjadi ketika layanan berbagi skema yang sama, atau membaca dan menulis ke kumpulan tabel database yang sama.
Tantangan
Beberapa tantangan muncul dari pendekatan terdistribusi ini untuk mengelola data. Pertama, mungkin ada redundansi di seluruh penyimpanan data, dengan item data yang sama muncul di beberapa tempat. Misalnya, data dapat disimpan sebagai bagian dari transaksi, kemudian disimpan di tempat lain untuk analisis, pelaporan, atau pengarsipan. Data yang terduplikasi atau terpartisi dapat menyebabkan masalah integritas dan konsistensi data. Ketika hubungan data mencakup beberapa layanan, Anda tidak dapat menggunakan teknik manajemen data tradisional untuk menerapkan hubungan.
Pemodelan data tradisional menggunakan aturan "satu fakta di satu tempat." Setiap entitas muncul tepat satu kali di dalam skema. Entitas lain mungkin memiliki referensinya, tetapi tidak menduplikasinya. Keuntungan yang jelas dari pendekatan tradisional adalah pembaruan dilakukan di satu tempat, dan hal ini menghindari masalah dengan konsistensi data. Dalam arsitektur layanan mikro, Anda harus mempertimbangkan cara pembaruan disebarluaskan di seluruh layanan, dan cara mengelola konsistensi akhirnya ketika data muncul di beberapa tempat tanpa konsistensi yang kuat.
Pendekatan untuk mengelola data
Tidak ada pendekatan tunggal yang benar di dalam semua kasus, tetapi berikut adalah beberapa panduan umum untuk mengelola data dalam arsitektur layanan mikro.
Tentukan tingkat konsistensi yang diperlukan per komponen, lebih memilih konsistensi akhir jika memungkinkan. Pahami tempat-tempat dalam sistem yang membutuhkan konsistensi yang kuat atau transaksi ACID, dan tempat-tempat yang dapat menerima konsistensi akhirnya. Tinjau Menggunakan DDD taktis untuk merancang layanan mikro untuk panduan komponen lebih lanjut.
Bila Anda memerlukan jaminan konsistensi yang kuat, satu layanan dapat mewakili sumber kebenaran untuk entitas yang diberikan, yang diekspos melalui API. Layanan lain mungkin memiliki salinan data mereka sendiri, atau sebagian data, yang pada akhirnya konsisten dengan data master tetapi tidak dianggap sebagai sumber kebenaran. Misalnya, bayangkan sebuah sistem e-commerce dengan layanan pesanan pelanggan dan layanan rekomendasi. Layanan rekomendasi mungkin mendengarkan kejadian dari layanan pesanan, tetapi jika pelanggan meminta pengembalian dana, layanan pesananlah yang memiliki riwayat transaksi lengkap, bukan layanan rekomendasi.
Untuk transaksi, gunakan pola seperti Scheduler Agent Supervisor dan Transaksi Kompensasi untuk menjaga data tetap konsisten di beberapa layanan. Anda mungkin perlu menyimpan sepotong data tambahan yang menangkap keadaan unit kerja yang mencakup beberapa layanan, untuk menghindari kegagalan parsial di antara beberapa layanan. Misalnya, simpan item kerja di antrean yang tahan lama saat transaksi multilangkah sedang berlangsung.
Simpan hanya data yang dibutuhkan oleh layanan. Layanan mungkin hanya memerlukan sebagian informasi tentang entitas domain. Misalnya, dalam konteks batas Pengiriman, kita perlu tahu pelanggan mana yang terkait dengan pengiriman tertentu. Tetapi kita tidak memerlukan alamat penagihan pelanggan — yang dikelola oleh konteks batas Akun. Kehati-hatian dalam berpikir tentang domain dan menggunakan pendekatan DDD dapat membantu di sini.
Pertimbangkan apakah layanan Anda tersambung dengan koheren dan longgar. Jika dua layanan terus bertukar informasi dengan satu sama lain dan menghasilkan chatty API, Anda mungkin perlu menggambar ulang batas layanan Anda, dengan menggabungkan dua layanan atau memfaktorkan ulang fungsi keduanya.
Gunakan gaya arsitektur yang didorong oleh kejadian. Dalam gaya arsitektur ini, layanan menerbitkan suatu kejadian ketika ada perubahan pada model atau entitas publiknya. Layanan yang tertarik dapat berlangganan kejadian ini. Misalnya, layanan lain dapat menggunakan kejadian untuk membangun tampilan data berwujud yang lebih cocok untuk kueri.
Layanan yang memiliki kejadian harus menerbitkan skema yang dapat digunakan untuk mengotomatiskan serialisasi dan deserialisasi kejadian, untuk menghindari sambungan ketat antara penerbit dan pelanggan. Pertimbangkan skema JSON atau kerangka kerja seperti Microsoft Bond, Protobuf, atau Avro.
Pada skala tinggi, kejadian dapat menjadi hambatan pada sistem, jadi pertimbangkan untuk menggunakan agregasi atau batching guna mengurangi total beban.
Contoh: Memilih penyimpanan data untuk aplikasi Pengiriman Drone
Artikel sebelumnya dalam seri ini membahas tentang layanan pengiriman drone sebagai contoh yang sedang berjalan. Anda dapat membaca selengkapnya tentang skenario dan implementasi referensi yang sesuai di sini. Contoh ini sangat ideal untuk industri pesawat dan dirgantara.
Untuk rekap, aplikasi ini menentukan beberapa layanan mikro untuk menjadwalkan pengiriman dengan drone. Ketika pengguna menjadwalkan pengiriman baru, permintaan klien mencakup informasi tentang pengiriman, seperti lokasi penjemputan dan pengantaran, serta tentang paket, seperti ukuran dan berat. Informasi ini menentukan unit kerja.
Berbagai layanan belakang peduli tentang bagian yang berbeda dari informasi dalam permintaan, serta memiliki profil baca dan tulis yang berbeda.
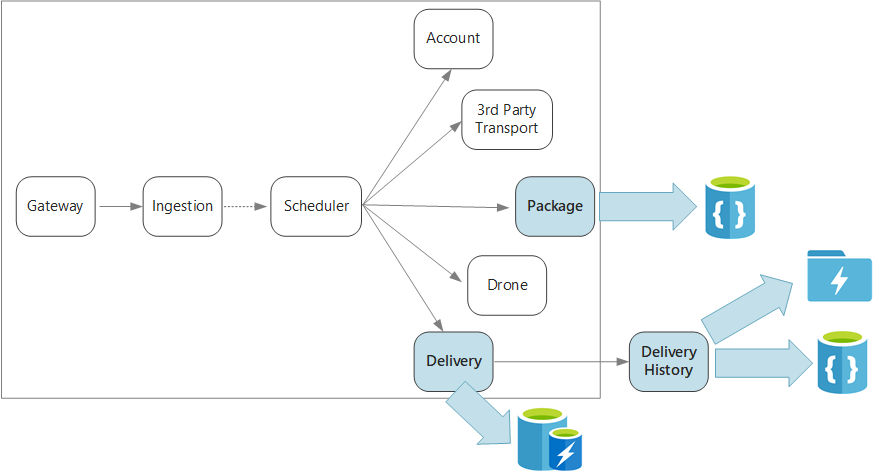
Layanan pengiriman
Layanan pengiriman menyimpan informasi tentang setiap pengiriman yang saat ini sudah dijadwalkan atau sedang berlangsung. Layanan ini mendengarkan kejadian dari drone dan melacak status pengiriman yang sedang berlangsung. Ini juga mengirimkan kejadian dengan pembaruan status pengiriman kepada domain.
Dapat diduga bahwa pengguna akan sering memeriksa status pengiriman saat menunggu paket mereka. Oleh karena itu, layanan Pengiriman memerlukan penyimpanan data yang menekankan throughput (baca dan tulis) daripada penyimpanan jangka panjang. Juga, layanan Pengiriman tidak melakukan kueri atau analisis yang kompleks, layanan ini hanya mengambil status terbaru untuk suatu pengiriman tertentu. Tim layanan Pengiriman memilih Azure Cache for Redis karena kinerja baca-tulisnya yang tinggi. Informasi yang disimpan di Redis relatif berumur pendek. Setelah pengiriman selesai, layanan Riwayat Pengiriman adalah sistem rekaman.
Layanan Riwayat Pengiriman
Layanan Riwayat Pengiriman mendengarkan kejadian status pengiriman dari layanan Pengiriman. Layanan menyimpan data ini di dalam penyimpanan jangka panjang. Ada dua kasus penggunaan yang berbeda untuk data historis ini, dan keduanya memiliki persyaratan penyimpanan data yang berbeda.
Skenario pertama adalah mengagregasikan data untuk tujuan analisis data, guna mengoptimalkan bisnis atau meningkatkan kualitas layanan. Mohon dicatat bahwa layanan Riwayat Pengiriman tidak melakukan analisis data yang sebenarnya. Layanan ini hanya bertanggung jawab atas konsumsi dan penyimpanan. Untuk skenario ini, penyimpanan harus dioptimalkan untuk analisis data melalui serangkaian besar data, menggunakan pendekatan skema-on-read untuk mengakomodasi sumber data yang beragam. Azure Data Lake Store sangat cocok untuk skenario ini. Data Lake Store adalah sistem file Apache Hadoop yang kompatibel dengan Sistem File Terdistribusi Hadoop (HDFS), dan diatur untuk kinerja untuk skenario analisis data.
Skenario lainnya adalah memungkinkan pengguna untuk mencari riwayat pengiriman setelah pengiriman selesai. Azure Data Lake tidak dioptimalkan untuk skenario ini. Untuk kinerja optimal, Microsoft menyarankan untuk menyimpan data deret waktu di Data Lake, di dalam folder yang dipartisi berdasarkan tanggal. (Lihat Menyetel Azure Data Lake Store untuk kinerja). Namun, struktur itu tidak optimal untuk mencari catatan individu berdasarkan ID. Kecuali jika Anda mengetahui stempel waktunya, pencarian dengan ID memerlukan pemindaian seluruh koleksi. Oleh karena itu, layanan Riwayat Pengiriman juga menyimpan subset data historis di Azure Cosmos DB untuk pencarian yang lebih cepat. Catatan tidak perlu tinggal di Azure Cosmos DB tanpa batas waktu. Pengiriman yang lebih lama dapat diarsipkan — katakanlah, setelah satu bulan. Ini bisa dilakukan dengan menjalankan proses batch berkala. Pengarsipan data yang lebih lama dapat mengurangi biaya untuk Cosmos DB sambil tetap menyimpan data yang tersedia untuk pelaporan historis dari Data Lake.
Layanan Paket
Layanan Paket menyimpan informasi tentang semua paket. Persyaratan penyimpanan untuk Paket adalah:
- Penyimpanan jangka panjang.
- Mampu menangani volume paket yang tinggi, membutuhkan throughput tulis yang tinggi.
- Mendukung kueri sederhana berdasarkan ID paket. Tidak ada gabungan atau persyaratan yang kompleks untuk integritas referensial.
Karena data paket tidak relasional, database berorientasi dokumen sesuai, dan Azure Cosmos DB dapat mencapai throughput tinggi dengan menggunakan koleksi pecahan. Tim yang bekerja pada layanan Paket terbiasa dengan tumpukan MEAN (MongoDB, Express.js, AngularJS, dan Node.js), sehingga mereka memilih MONGODB API untuk Azure Cosmos DB. Itu memungkinkan mereka memanfaatkan pengalaman mereka yang ada dengan MongoDB, sambil mendapatkan manfaat dari Azure Cosmos DB, yang merupakan layanan Azure terkelola.
Langkah berikutnya
Pelajari pola desain yang dapat membantu mengurangi beberapa tantangan umum dalam arsitektur layanan mikro.