Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini adalah bagian dari seri. Mulailah dengan gambaran umum.
Jika pemeriksaan kluster yang Anda lakukan pada langkah sebelumnya sudah jelas, periksa kesehatan simpul pekerja Azure Kubernetes Service (AKS). Ikuti enam langkah dalam artikel ini untuk memeriksa kesehatan simpul, menentukan alasan simpul yang tidak sehat, dan mengatasi masalah tersebut.
Langkah 1: Periksa kesehatan node pekerja
Berbagai faktor dapat berkontribusi pada simpul yang tidak sehat dalam kluster AKS. Salah satu alasan umum adalah gangguan komunikasi antara lapisan kontrol dan simpul. Miskomunikasi ini sering disebabkan oleh kesalahan pengaturan dalam aturan perutean dan firewall.
Saat mengonfigurasi kluster AKS untuk perutean yang ditentukan pengguna, Anda harus mengonfigurasi jalur keluar melalui appliance virtual jaringan (NVA) atau firewall, seperti firewall Azure. Untuk mengatasi masalah kesalahan konfigurasi, kami sarankan Anda mengonfigurasi firewall untuk mengizinkan port yang diperlukan dan nama domain yang sepenuhnya memenuhi syarat (FQDN) sesuai dengan panduan lalu lintas keluar AKS.
Alasan lain untuk simpul yang tidak sehat mungkin sumber daya komputasi, memori, atau penyimpanan yang tidak memadai yang menciptakan tekanan kubelet. Dalam kasus seperti itu, meningkatkan skala sumber daya dapat menyelesaikan masalah secara efektif.
Dalam kluster AKS privat, masalah resolusi Sistem Nama Domain (DNS) dapat menyebabkan masalah komunikasi antara sarana kontrol dan simpul. Anda harus memverifikasi bahwa nama DNS server API Kubernetes diselesaikan ke alamat IP privat server API. Konfigurasi server DNS kustom yang salah adalah penyebab umum kegagalan resolusi DNS. Jika Anda menggunakan server DNS kustom, pastikan Anda menentukannya dengan benar sebagai server DNS di jaringan virtual tempat simpul disediakan. Konfirmasikan juga bahwa server API privat AKS dapat diselesaikan melalui server DNS kustom.
Setelah Anda mengatasi potensi masalah ini yang terkait dengan komunikasi sarana kontrol dan resolusi DNS, Anda dapat menangani dan mengatasi masalah kesehatan simpul secara efektif dalam kluster AKS Anda.
Anda dapat mengevaluasi kesehatan simpul Anda dengan menggunakan salah satu metode berikut.
Tampilan kesehatan kontainer dalam Azure Monitor
Untuk melihat kesehatan simpul, pod pengguna, dan pod sistem di kluster AKS Anda, ikuti langkah-langkah berikut:
- Di portal Azure, buka Azure Monitor.
- Di bagian Wawasan panel navigasi, pilih Kontainer.
- Pilih Kluster yang dipantau untuk daftar kluster AKS yang sedang dipantau.
- Pilih kluster AKS dari daftar untuk melihat kesehatan simpul, pod pengguna, dan pod sistem.

Tampilan simpul AKS
Untuk memastikan bahwa semua simpul di kluster AKS Anda dalam status siap, ikuti langkah-langkah berikut:
- Di portal Microsoft Azure, buka kluster AKS Anda.
- Di bagian Pengaturan panel navigasi, pilih Kumpulan simpul.
- Pilih Node.
- Verifikasi bahwa semua simpul dalam status siap.

Pemantauan dalam kluster dengan Prometheus dan Grafana
Jika Anda menyebarkan Prometheus dan Grafana di kluster AKS, Anda dapat menggunakan Dasbor Detail Kluster K8 untuk mendapatkan wawasan. Dasbor ini menunjukkan metrik kluster Prometheus dan menyajikan informasi penting, seperti penggunaan CPU, penggunaan memori, aktivitas jaringan, dan penggunaan sistem file. Ini juga menunjukkan statistik terperinci untuk masing-masing pod, kontainer, dan layanan sistemd .
Di dasbor, pilih Kondisi simpul untuk melihat metrik tentang kesehatan dan performa kluster Anda. Anda dapat melacak simpul yang mungkin memiliki masalah, seperti masalah dengan jadwalnya, jaringan, tekanan disk, tekanan memori, tekanan derivatif integral proporsional (PID), atau ruang disk. Pantau metrik ini, sehingga Anda dapat secara proaktif mengidentifikasi dan mengatasi masalah potensial yang memengaruhi ketersediaan dan performa kluster AKS Anda.

Memantau layanan terkelola untuk Prometheus dan Azure Managed Grafana
Anda dapat menggunakan dasbor bawaan untuk memvisualisasikan dan menganalisis metrik Prometheus. Untuk melakukannya, Anda harus menyiapkan kluster AKS untuk mengumpulkan metrik Prometheus di Monitor layanan terkelola untuk Prometheus, dan menghubungkan ruang kerja Monitor Anda ke ruang kerja Azure Managed Grafana. Dasbor ini memberikan tampilan komprehensif tentang performa dan kesehatan kluster Kubernetes Anda.
Dasbor disediakan dalam instans Azure Managed Grafana yang ditentukan di folder Prometheus yang Dikelola. Beberapa dasbor meliputi:
- Kubernetes / Sumber Daya Komputasi / Kluster
- Kubernetes / Compute Resources / Namespace (Pods)
- Kubernetes / Compute Resources / Node (Pods)
- Kubernetes / Compute Resources / Pod
- Kubernetes / Komputasi Sumber Daya / Namespace (Beban Kerja)
- Kubernetes / Sumber Daya Komputasi / Beban Kerja
- Kubernetes / Kubelet
- Node Exporter / USE Method / Node
- Node Exporter / Nodes
- Kubernetes / Compute Resources / Cluster (Windows)
- Kubernetes / Compute Resources / Namespace (Windows)
- Kubernetes / Compute Resources / Pod (Windows)
- Kubernetes / USE Method / Cluster (Windows)
- Kubernetes / USE Method / Node (Windows)
Dasbor bawaan ini banyak digunakan dalam komunitas sumber terbuka untuk memantau kluster Kubernetes dengan Prometheus dan Grafana. Gunakan dasbor ini untuk melihat metrik, seperti penggunaan sumber daya, kesehatan pod, dan aktivitas jaringan. Anda juga dapat membuat dasbor kustom yang disesuaikan dengan kebutuhan pemantauan Anda. Dasbor membantu Anda memantau dan menganalisis metrik Prometheus secara efektif di kluster AKS, yang memungkinkan Anda mengoptimalkan performa, memecahkan masalah, dan memastikan kelancaran pengoperasian beban kerja Kubernetes Anda.
Anda dapat menggunakan dasbor Kubernetes / Compute Resources / Node (Pods) untuk melihat metrik untuk node agen Linux Anda. Anda dapat memvisualisasikan penggunaan CPU, kuota CPU, penggunaan memori, dan kuota memori untuk setiap pod.

Jika kluster Anda menyertakan simpul agen Windows, Anda dapat menggunakan dasbor Kubernetes / USE Method / Node (Windows) untuk memvisualisasikan metrik Prometheus yang dikumpulkan dari simpul ini. Dasbor ini menyediakan tampilan komprehensif tentang konsumsi dan performa sumber daya untuk simpul Windows dalam kluster Anda.
Manfaatkan dasbor khusus ini sehingga Anda dapat dengan mudah memantau dan menganalisis metrik penting yang terkait dengan CPU, memori, dan sumber daya lainnya di simpul agen Linux dan Windows. Visibilitas ini memungkinkan Anda mengidentifikasi potensi hambatan, mengoptimalkan alokasi sumber daya, dan memastikan operasi yang efisien di seluruh kluster AKS Anda.
Langkah 2: Verifikasi konektivitas sarana kontrol dan simpul pekerja
Jika node pekerja sehat, Anda harus memeriksa konektivitas antara pesawat kontrol AKS yang dikelola dan node pekerja kluster. AKS memungkinkan komunikasi antara server API Kubernetes dan kubelets simpul individu melalui metode komunikasi terowongan yang terjamin keamanannya. Komponen-komponen ini dapat berkomunikasi bahkan jika mereka berada di jaringan virtual yang berbeda. Terowongan dilindungi dengan enkripsi Keamanan Lapisan Transportasi Bersama (mTLS). Terowongan utama yang digunakan AKS disebut Konnectivity (sebelumnya dikenal sebagai apiserver-network-proxy). Pastikan bahwa semua aturan jaringan dan FQDN mematuhi aturan jaringan Azure yang diperlukan.
Untuk memverifikasi konektivitas antara sarana kontrol AKS terkelola dan node pekerja kluster kluster AKS, Anda dapat menggunakan alat baris perintah kubectl .
Untuk memastikan bahwa pod agen Konnectivity berfungsi dengan baik, jalankan perintah berikut:
kubectl get deploy konnectivity-agent -n kube-system
Pastikan pod dalam keadaan siap untuk digunakan.
Jika ada masalah dengan konektivitas antara sarana kontrol dan simpul pekerja, tetapkan konektivitas setelah Anda memastikan bahwa aturan lalu lintas keluar AKS yang diperlukan diizinkan.
Jalankan perintah berikut untuk memulai ulang konnectivity-agent pod.
kubectl rollout restart deploy konnectivity-agent -n kube-system
Jika menghidupkan ulang pod tidak memperbaiki koneksi, periksa log untuk anomali apa pun. Jalankan perintah berikut untuk melihat log konnectivity-agent pod:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
Log harus menampilkan output berikut:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Nota
Ketika kluster AKS disiapkan dengan integrasi jaringan virtual server API dan antarmuka jaringan kontainer Azure (CNI) atau Azure CNI dengan penetapan IP pod dinamis, anda tidak perlu menyebarkan agen Konnectivity. Pod server API terintegrasi dapat membangun komunikasi langsung dengan simpul pekerja kluster melalui jaringan privat.
Namun, ketika Anda menggunakan integrasi jaringan virtual server API dengan Azure CNI Overlay atau membawa CNI (BYOCNI) Anda sendiri, Konnectivity dikerahkan untuk memfasilitasi komunikasi antara server API dan alamat IP pod. Komunikasi antara simpul pekerja dan server API tetap langsung.
Anda juga dapat mencari log kontainer di layanan pengelogan dan pemantauan untuk mengambil log. Untuk contoh yang mencari kesalahan konektivitas aks-link , lihat Log kueri dari wawasan kontainer.
Jalankan kueri berikut untuk mengambil log:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Jalankan kueri berikut untuk mencari log kontainer untuk pod yang gagal di namespace tertentu:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Jika Anda tidak bisa mendapatkan log dengan menggunakan kueri atau alat kubectl, gunakan autentikasi Secure Shell (SSH). Contoh ini menemukan pod tunnelfront setelah menyambungkan ke simpul melalui SSH.
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Langkah 3: Memvalidasi resolusi DNS saat membatasi egress
Resolusi DNS adalah aspek penting dari kluster AKS Anda. Jika resolusi DNS tidak berfungsi dengan benar, hal ini dapat menyebabkan kesalahan pesawat kontrol atau kegagalan menarik gambar kontainer. Untuk memastikan bahwa resolusi DNS ke server API Kubernetes berfungsi dengan benar, ikuti langkah-langkah berikut:
Jalankan perintah kubectl exec untuk membuka shell perintah dalam kontainer yang berjalan di pod.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashPeriksa apakah alat nslookup atau gali diinstal dalam kontainer.
Jika tidak ada alat yang dipasang di pod, jalankan perintah berikut untuk membuat pod utilitas di namespace yang sama.
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shAnda dapat mengambil alamat server API dari halaman gambaran umum kluster AKS Anda di portal Microsoft Azure, atau Anda dapat menjalankan perintah berikut.
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvJalankan perintah berikut untuk mencoba menyelesaikan server API AKS. Untuk informasi selengkapnya, lihat Pemecahan masalah kegagalan resolusi DNS dari dalam pod tetapi tidak dari node pekerja.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioPeriksa server DNS upstream dari pod untuk menentukan apakah resolusi DNS berfungsi dengan benar. Misalnya, untuk Azure DNS, jalankan
nslookupperintah .nslookup microsoft.com 168.63.129.16Jika langkah-langkah sebelumnya tidak memberikan masukan, sambungkan ke salah satu simpul pekerja, dan upayakan resolusi DNS dari simpul. Langkah ini membantu mengidentifikasi apakah masalah terkait dengan AKS atau konfigurasi jaringan.
Jika resolusi DNS berhasil dari simpul tetapi bukan dari pod, masalahnya mungkin terkait dengan DNS Kubernetes. Untuk langkah-langkah men-debug resolusi DNS dari pod, lihat Memecahkan masalah kegagalan resolusi DNS.
Jika resolusi DNS gagal dari node, tinjau pengaturan jaringan untuk memastikan jalur perutean dan port yang sesuai terbuka untuk memfasilitasi resolusi DNS.
Langkah 4: Periksa kesalahan kubelet
Verifikasi kondisi proses kubelet yang berjalan pada setiap node pekerja, dan pastikan tidak mengalami tekanan. Potensi tekanan mungkin berkaitan dengan CPU, memori, atau penyimpanan. Untuk memverifikasi status kubelet pada node individual, Anda dapat menggunakan salah satu metode berikut.
Buku kerja kubelet AKS
Untuk memastikan bahwa kubelet node agen berfungsi dengan baik, ikuti langkah-langkah berikut:
Buka klaster AKS Anda di portal Azure.
Di bagian Pemantauan panel navigasi, pilih Buku Kerja.
Pilih buku kerja Kubelet.
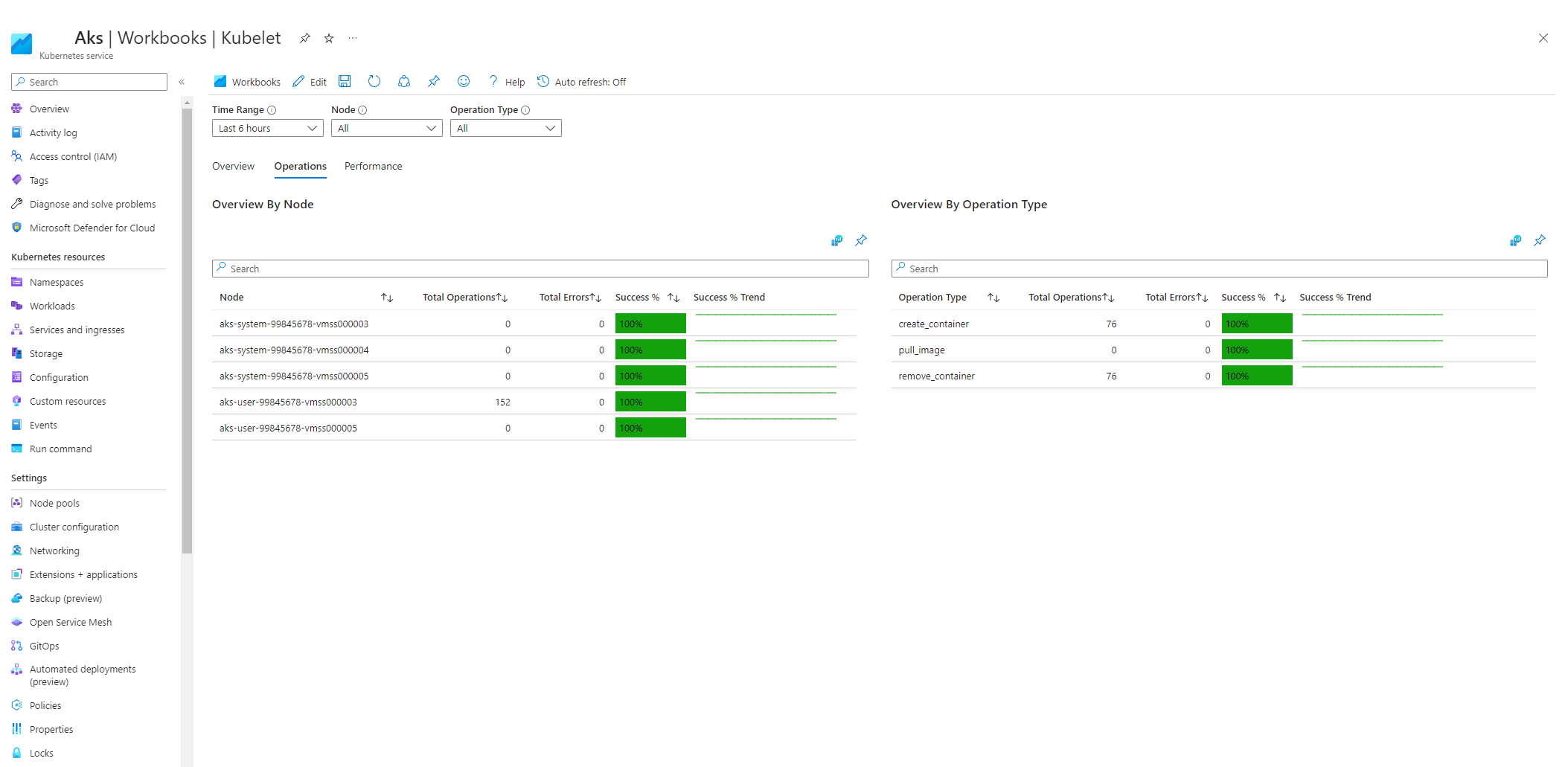
Pilih Operasi dan pastikan operasi untuk semua node pekerja selesai.


Pemantauan dalam kluster dengan Prometheus dan Grafana
Jika Anda menyebarkan Prometheus dan Grafana di kluster AKS, Anda dapat menggunakan dasbor Kubernetes / Kubelet untuk mendapatkan wawasan tentang kesehatan dan performa kubelet simpul individu.

Memantau layanan terkelola untuk Prometheus dan Azure Managed Grafana
Anda dapat menggunakan dasbor bawaan Kubernetes / Kubelet untuk memvisualisasikan dan menganalisis metrik Prometheus untuk kubelet simpul pekerja. Untuk melakukannya, Anda harus menyiapkan kluster AKS untuk mengumpulkan metrik Prometheus di Monitor layanan terkelola untuk Prometheus, dan menghubungkan ruang kerja Monitor Anda ke ruang kerja Azure Managed Grafana.

Tekanan meningkat ketika kubelet dijalankan ulang dan menyebabkan perilaku sporadis dan tidak dapat diprediksi. Pastikan jumlah kesalahan tidak tumbuh terus menerus. Kesalahan sesekali dapat diterima, tetapi pertumbuhan konstan menunjukkan masalah yang mendasar yang harus Anda selidiki dan selesaikan.
Langkah 5: Gunakan alat pendeteksi masalah node (NPD) untuk memeriksa kesehatan node
NPD adalah alat Kubernetes yang dapat Anda gunakan untuk mengidentifikasi dan melaporkan masalah terkait simpul. Ini beroperasi sebagai layanan systemd pada setiap node dalam kluster. Ini mengumpulkan metrik dan informasi sistem, seperti penggunaan CPU, penggunaan disk, dan status konektivitas jaringan. Ketika masalah terdeteksi, alat NPD menghasilkan laporan tentang peristiwa dan kondisi simpul. Di AKS, alat NPD digunakan untuk memantau dan mengelola simpul dalam kluster Kubernetes yang dihosting di cloud Azure. Untuk informasi selengkapnya, lihat NPD di simpul AKS.
Langkah 6: Periksa operasi I/O disk per detik (IOPS) untuk pengaturan batas
Untuk memastikan bahwa IOPS tidak dibatasi dan memengaruhi layanan dan beban kerja dalam kluster AKS, Anda dapat menggunakan salah satu metode berikut.
Buku kerja disk I/O node AKS
Untuk memantau metrik terkait I/O disk dari node pekerja di kluster AKS, Anda dapat menggunakan buku kerja disk I/O simpul . Ikuti langkah-langkah ini untuk mengakses buku kerja:
Buka klaster AKS Anda di portal Azure.
Di bagian Pemantauan panel navigasi, pilih Buku Kerja.
Pilih buku kerja Node Disk IO .
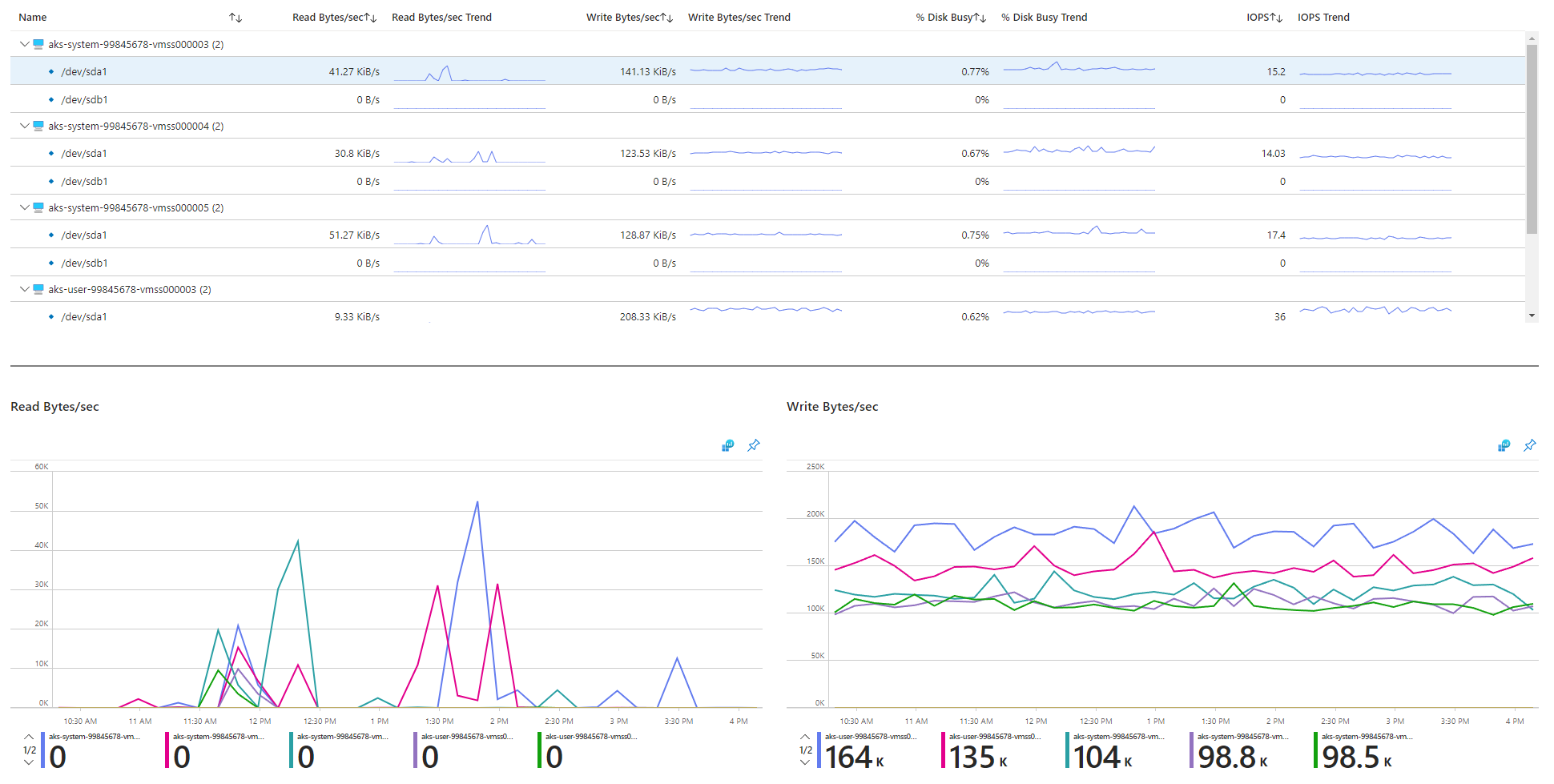
Tinjau metrik terkait I/O.


Pemantauan dalam kluster dengan Prometheus dan Grafana
Jika Anda menyebarkan Prometheus dan Grafana di kluster AKS, Anda dapat menggunakan dasbor USE Method / Node untuk mendapatkan wawasan tentang I/O disk untuk node pekerja kluster.

Memantau layanan terkelola untuk Prometheus dan Azure Managed Grafana
Anda dapat menggunakan dasbor bawaan Node Exporter / Node untuk memvisualisasikan dan menganalisis metrik terkait I/O disk dari simpul pekerja. Untuk melakukannya, Anda harus menyiapkan kluster AKS untuk mengumpulkan metrik Prometheus di Monitor layanan terkelola untuk Prometheus, dan menghubungkan ruang kerja Monitor Anda ke ruang kerja Azure Managed Grafana.

IOPS dan disk Azure
Perangkat penyimpanan fisik memiliki batasan yang melekat dalam hal bandwidth dan jumlah maksimum operasi file yang dapat mereka tangani. Disk Azure digunakan untuk menyimpan sistem operasi yang berjalan pada simpul AKS. Disk tunduk pada batasan penyimpanan fisik yang sama dengan sistem operasi.
Pertimbangkan konsep throughput. Anda dapat mengalikan ukuran I/O rata-rata dengan IOPS untuk menentukan throughput dalam megabyte per detik (MBps). Ukuran I/O yang lebih besar menghasilkan IOPS yang lebih rendah karena adanya throughput tetap dari disk.
Ketika beban kerja melampaui batas layanan IOPS maksimum yang ditetapkan ke disk Azure, kluster mungkin menjadi tidak responsif dan memasuki status tunggu I/O. Dalam sistem berbasis Linux, banyak komponen diperlakukan sebagai file, seperti soket jaringan, CNI, Docker, dan layanan lain yang bergantung pada I/O jaringan. Akibatnya, jika disk tidak dapat dibaca, kegagalan akan meluas ke semua file ini.
Beberapa peristiwa dan skenario dapat memicu pembatasan IOPS, termasuk:
Sejumlah besar kontainer yang berjalan di atas node, karena Docker I/O berbagi diska dari sistem operasi.
Alat kustom atau pihak ketiga yang digunakan untuk keamanan, pemantauan, dan pengelogan, yang mungkin menghasilkan operasi I/O tambahan pada disk sistem operasi.
Peristiwa failover node dan pekerjaan berkala yang mengintensifkan beban kerja atau menskalakan jumlah pod. Peningkatan beban ini meningkatkan kemungkinan pembatasan terjadi, yang berpotensi menyebabkan semua simpul beralih ke keadaan tidak siap sampai operasi I/O selesai.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Paolo Salvatori | Insinyur Pelanggan Utama
- Francis Simy Nazareth | Spesialis Teknis Senior
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.