Untuk memverifikasi bahwa aplikasi dan layanan berkinerja dengan benar, Anda dapat menggunakan pola Pemantauan Titik Akhir Kesehatan. Pola ini menentukan penggunaan pemeriksaan fungsi dalam aplikasi. Alat eksternal dapat mengakses pemeriksaan ini secara berkala melalui titik akhir yang diekspos.
Konteks dan masalah
Ini adalah praktik yang baik untuk memantau aplikasi web dan layanan back-end. Pemantauan membantu memastikan bahwa aplikasi dan layanan tersedia dan berkinerja dengan benar. Persyaratan bisnis sering kali mencakup pemantauan.
Terkadang lebih sulit untuk memantau layanan cloud daripada layanan lokal. Salah satu alasannya adalah Anda tidak memiliki kontrol penuh terhadap lingkungan hosting. Yang lain adalah bahwa layanan biasanya bergantung pada layanan lain yang disediakan vendor platform dan lainnya.
Banyak faktor yang memengaruhi aplikasi yang dihosting cloud. Contohnya termasuk latensi jaringan, performa dan ketersediaan sistem komputasi dan penyimpanan yang mendasar, dan bandwidth jaringan di antara mereka. Layanan dapat gagal sepenuhnya atau sebagian karena salah satu faktor ini. Untuk memastikan tingkat ketersediaan yang diperlukan, Anda harus memverifikasi secara berkala bahwa layanan Anda bekerja dengan benar. Perjanjian tingkat layanan (SLA) Anda mungkin menentukan tingkat yang perlu Anda penuhi.
Solusi
Terapkan pemantauan kesehatan dengan mengirim permintaan ke titik akhir pada aplikasi Anda. Aplikasi harus melakukan pemeriksaan yang diperlukan dan kemudian mengembalikan indikasi statusnya.
Pemeriksaan pemantauan kesehatan biasanya menggabungkan dua faktor:
- Pemeriksaan (jika ada) yang dilakukan aplikasi atau layanan sebagai respons terhadap permintaan ke titik akhir verifikasi kesehatan
- Analisis hasil oleh alat atau kerangka kerja yang melakukan pemeriksaan verifikasi kesehatan
Kode respons menunjukkan status aplikasi. Secara opsional, kode respons juga menyediakan status komponen dan layanan yang digunakan aplikasi. Alat pemantauan atau kerangka kerja melakukan pemeriksaan latensi atau waktu respons.
Gambar berikut memberikan gambaran umum tentang pola.
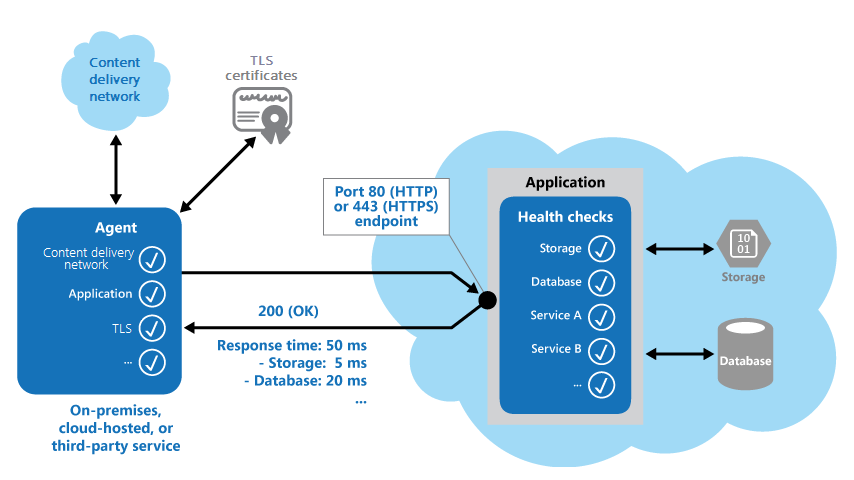
Kode pemantauan kesehatan dalam aplikasi mungkin juga menjalankan pemeriksaan lain untuk menentukan:
- Ketersediaan dan waktu respons penyimpanan cloud atau database.
- Status sumber daya atau layanan lain yang digunakan aplikasi. Sumber daya dan layanan ini mungkin ada di aplikasi atau di luarnya.
Layanan dan alat tersedia yang memantau aplikasi web dengan mengirimkan permintaan ke serangkaian titik akhir yang dapat dikonfigurasi. Layanan dan alat ini kemudian mengevaluasi hasil terhadap serangkaian aturan yang dapat dikonfigurasi. Relatif mudah untuk membuat titik akhir layanan untuk tujuan tunggal melakukan beberapa pengujian fungsional pada sistem.
Pemeriksaan umum yang dilakukan alat pemantauan meliputi:
- Memvalidasi kode respons. Misalnya, respons HTTP 200 (OK) menunjukkan bahwa aplikasi merespons tanpa kesalahan. Sistem pemantauan mungkin juga memeriksa kode respons lain untuk memberikan hasil yang lebih komprehensif.
- Memeriksa konten respons untuk mendeteksi kesalahan, bahkan ketika kode status adalah 200 (OK). Dengan memeriksa konten, Anda dapat mendeteksi kesalahan yang hanya memengaruhi bagian halaman web atau respons layanan yang dikembalikan. Misalnya, Anda dapat memeriksa judul halaman atau mencari frasa tertentu yang menunjukkan bahwa aplikasi mengembalikan halaman yang benar.
- Mengukur waktu respons. Nilai termasuk latensi jaringan dan waktu yang dibutuhkan aplikasi untuk mengeluarkan permintaan. Nilai yang meningkat dapat menunjukkan masalah yang muncul pada aplikasi atau jaringan.
- Memeriksa sumber daya atau layanan yang terletak di luar aplikasi. Contohnya adalah jaringan pengiriman konten yang digunakan aplikasi untuk mengirimkan konten dari cache global.
- Memeriksa kedaluwarsa sertifikat TLS.
- Mengukur waktu respons pencarian DNS untuk URL aplikasi. Pemeriksaan ini mengukur latensi DNS dan kegagalan DNS.
- Memvalidasi URL yang dikembalikan pencarian DNS. Dengan memvalidasi, Anda dapat memastikan bahwa entri sudah benar. Anda juga dapat membantu mencegah pengalihan permintaan berbahaya yang mungkin mengakibatkan serangan di server DNS Anda.
Jika memungkinkan, juga berguna untuk menjalankan pemeriksaan ini dari lokasi lokal atau yang dihosting yang berbeda lalu membandingkan waktu respons. Idealnya, Anda harus memantau aplikasi dari lokasi yang dekat dengan pelanggan. Kemudian Anda mendapatkan tampilan performa yang akurat dari setiap lokasi. Praktik ini menyediakan mekanisme pemeriksaan yang lebih kuat. Hasilnya juga dapat membantu Anda membuat keputusan berikut:
- Tempat menyebarkan aplikasi Anda
- Apakah akan menyebarkannya di lebih dari satu pusat data
Untuk memastikan bahwa aplikasi Anda berfungsi dengan benar untuk semua pelanggan, jalankan pengujian terhadap semua instans layanan yang digunakan pelanggan. Misalnya, jika penyimpanan pelanggan tersebar di lebih dari satu akun penyimpanan, proses pemantauan harus memeriksa setiap akun.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat Anda memutuskan cara menerapkan pola ini:
Pikirkan tentang cara memvalidasi respons. Misalnya, tentukan apakah kode status 200 (OK) cukup untuk memverifikasi bahwa aplikasi berfungsi dengan benar. Memeriksa kode status adalah implementasi minimum dari pola ini. Kode status menyediakan ukuran dasar ketersediaan aplikasi. Tetapi kode memberikan sedikit informasi tentang operasi, tren, dan kemungkinan masalah yang akan datang dalam aplikasi.
Tentukan jumlah titik akhir yang akan diekspos untuk aplikasi. Salah satu pendekatannya adalah mengekspos setidaknya satu titik akhir untuk layanan inti yang digunakan aplikasi dan satu lagi untuk layanan berprioritas lebih rendah. Dengan pendekatan ini, Anda dapat menetapkan tingkat kepentingan yang berbeda untuk setiap hasil pemantauan. Pertimbangkan juga untuk mengekspos titik akhir tambahan. Anda dapat mengekspos satu untuk setiap layanan inti untuk meningkatkan granularitas pemantauan. Misalnya, pemeriksaan verifikasi kesehatan mungkin memeriksa database, penyimpanan, dan layanan geocoding eksternal yang digunakan aplikasi. Masing-masing mungkin memerlukan tingkat waktu aktif dan waktu respons yang berbeda. Layanan geocoding atau beberapa tugas latar belakang lainnya mungkin tidak tersedia selama beberapa menit. Tetapi aplikasi mungkin masih sehat.
Putuskan apakah akan menggunakan titik akhir yang sama untuk pemantauan dan untuk akses umum. Anda dapat menggunakan titik akhir yang sama untuk keduanya tetapi merancang jalur tertentu untuk pemeriksaan verifikasi kesehatan. Misalnya, Anda dapat menggunakan /health pada titik akhir akses umum. Dengan pendekatan ini, alat pemantauan dapat menjalankan beberapa pengujian fungsional dalam aplikasi. Contohnya termasuk mendaftarkan pengguna baru, masuk, dan menempatkan urutan pengujian. Pada saat yang sama, Anda juga dapat memverifikasi bahwa titik akhir akses umum tersedia.
Tentukan jenis informasi yang akan dikumpulkan dalam layanan sebagai respons terhadap permintaan pemantauan. Anda juga perlu menentukan cara mengembalikan informasi ini. Sebagian besar alat dan kerangka kerja yang ada hanya melihat kode status HTTP yang dikembalikan oleh titik akhir. Untuk mengembalikan dan memvalidasi informasi tambahan, Anda mungkin harus membuat utilitas atau layanan pemantauan khusus.
Cari tahu berapa banyak informasi yang harus dikumpulkan. Melakukan pemrosesan berlebihan selama pemeriksaan dapat membebani aplikasi dan memengaruhi pengguna lain. Waktu pemrosesan mungkin juga melebihi batas waktu sistem pemantauan. Akibatnya, sistem mungkin menandai aplikasi sebagai tidak tersedia. Sebagian besar aplikasi mencakup instrumentasi seperti penanganan kesalahan dan penghitung kinerja. Alat-alat ini dapat mencatat performa dan informasi kesalahan terperinci, yang mungkin cukup. Pertimbangkan untuk menggunakan data ini alih-alih mengembalikan informasi tambahan dari pemeriksaan verifikasi kesehatan.
Pertimbangkan untuk menyinggahkan status titik akhir. Menjalankan pemeriksaan kesehatan sering mungkin mahal. Misalnya, jika status kesehatan dilaporkan melalui dasbor, Anda tidak ingin setiap permintaan ke dasbor memicu pemeriksaan kesehatan. Sebagai gantinya, periksa kesehatan sistem secara berkala, dan cache statusnya. Mengekspos titik akhir yang mengembalikan status yang di-cache.
Rencanakan cara mengonfigurasi keamanan untuk titik akhir pemantauan. Dengan mengonfigurasi keamanan, Anda dapat membantu melindungi titik akhir dari akses publik, yang mungkin:
- Mengekspos aplikasi ke serangan berbahaya.
- Risiko paparan informasi sensitif.
- Menarik serangan penolakan layanan (DoS).
Biasanya, Anda mengonfigurasi keamanan dalam konfigurasi aplikasi. Kemudian Anda dapat memperbarui pengaturan dengan mudah tanpa memulai ulang aplikasi. Pertimbangkan untuk menggunakan satu atau beberapa teknik berikut:
Amankan titik akhir dengan meminta autentikasi. Jika layanan atau alat pemantauan mendukung autentikasi, Anda dapat menggunakan kunci keamanan autentikasi di header permintaan. Anda juga dapat meneruskan kredensial dengan permintaan. Saat Anda menggunakan autentikasi, pertimbangkan cara mengakses titik akhir pemeriksaan kesehatan Anda. Sebagai contoh, Azure App Service memiliki pemeriksaan kesehatan bawaan yang terintegrasi dengan fitur autentikasi dan otorisasi App Service.
Gunakan titik akhir yang tidak jelas atau tersembunyi. Misalnya, ekspos titik akhir pada alamat IP yang berbeda dari yang digunakan URL aplikasi default. Konfigurasikan titik akhir pada port HTTP nonstandar. Selain itu, pertimbangkan untuk menggunakan jalur kompleks ke halaman pengujian Anda. Anda biasanya dapat menentukan alamat dan port titik akhir tambahan dalam konfigurasi aplikasi. Jika perlu, Anda dapat menambahkan entri untuk titik akhir ini ke server DNS. Kemudian Anda menghindari harus menentukan alamat IP secara langsung.
Mengekspos metode pada titik akhir yang menerima parameter seperti nilai kunci atau nilai mode operasi. Ketika permintaan tiba, kode dapat menjalankan pengujian tertentu yang bergantung pada nilai parameter. Kode dapat mengembalikan kesalahan 404 (Tidak Ditemukan) jika tidak mengenali nilai parameter. Memungkinkan untuk menentukan nilai parameter dalam konfigurasi aplikasi.
Gunakan titik akhir terpisah yang melakukan pengujian fungsional dasar tanpa mengorbankan operasi aplikasi. Dengan pendekatan ini, Anda dapat membantu mengurangi dampak serangan DoS. Idealnya, hindari menggunakan tes yang dapat mengekspos informasi sensitif. Terkadang Anda harus mengembalikan informasi yang mungkin berguna bagi penyerang. Dalam hal ini, pertimbangkan cara melindungi titik akhir dan data dari akses yang tidak sah. Mengandalkan ketidakpastian tidaklah cukup. Pertimbangkan juga menggunakan koneksi HTTPS dan mengenkripsi data sensitif, meskipun pendekatan ini meningkatkan beban di server.
Tentukan cara memastikan bahwa agen pemantauan berkinerja dengan benar. Salah satu pendekatannya adalah mengekspos titik akhir yang mengembalikan nilai dari konfigurasi aplikasi atau nilai acak yang dapat Anda gunakan untuk menguji agen. Pastikan juga bahwa sistem pemantauan melakukan pemeriksaan pada dirinya sendiri. Anda dapat menggunakan pengujian mandiri atau pengujian bawaan untuk mencegah sistem pemantauan mengeluarkan hasil positif palsu.
Kapan menggunakan pola ini
Pola ini berguna untuk:
- Memantau situs web dan aplikasi web untuk memverifikasi ketersediaan.
- Memantau situs web dan aplikasi web untuk memeriksa pengoperasian yang benar.
- Memantau layanan tingkat menengah atau bersama untuk mendeteksi dan mengisolasi kegagalan yang dapat mengganggu aplikasi lain.
- Melengkapi instrumentasi yang ada pada aplikasi, seperti penghitung performa dan penanganan kesalahan. Pemeriksaan verifikasi kesehatan tidak menggantikan persyaratan aplikasi untuk pengelogan dan audit. Instrumentasi dapat memberikan informasi berharga untuk kerangka kerja yang ada yang memantau penghitung dan log kesalahan untuk mendeteksi kegagalan atau masalah lainnya. Tetapi instrumentasi tidak dapat memberikan informasi jika aplikasi tidak tersedia.
Desain beban kerja
Arsitek harus mengevaluasi bagaimana pola Pemantauan Titik Akhir Kesehatan dapat digunakan dalam desain beban kerja mereka untuk mengatasi tujuan dan prinsip yang tercakup dalam pilar Azure Well-Architected Framework. Contohnya:
| Pilar | Bagaimana pola ini mendukung tujuan pilar |
|---|---|
| Keputusan desain keandalan membantu beban kerja Anda menjadi tahan terhadap kerusakan dan untuk memastikan bahwa keputusan tersebut pulih ke status berfungsi penuh setelah kegagalan terjadi. | Titik akhir ini mendukung upaya pemberitahuan dan dasbor keandalan beban kerja. Mereka juga dapat digunakan sebagai sinyal untuk perbaikan penyembuhan diri. - RE:07 Penyembuhan diri dan pelestarian diri - STRATEGI pemantauan dan peringatan RE:10 |
| Keunggulan Operasional membantu memberikan kualitas beban kerja melalui proses standar dan kohesi tim. | Menstandarkan titik akhir kesehatan mana yang akan diekspos, dan tingkat detail dalam hasil, di seluruh beban kerja Anda akan membantu Anda mengatasi masalah triase. - Sistem Pemantauan OE:07 |
| Efisiensi Performa membantu beban kerja Anda memenuhi tuntutan secara efisien melalui pengoptimalan dalam penskalaan, data, kode. | Titik akhir kesehatan meningkatkan logika penyeimbangan beban dengan merutekan lalu lintas hanya ke simpul yang diverifikasi sebagai sehat. Dengan konfigurasi tambahan, Anda juga bisa mendapatkan metrik pada kapasitas simpul yang tersedia. - PE:05 Penskalaan dan pemartisian |
Seperti halnya keputusan desain apa pun, pertimbangkan tradeoff terhadap tujuan pilar lain yang mungkin diperkenalkan dengan pola ini.
Contoh
Anda dapat menggunakan middleware dan pustaka pemeriksaan kesehatan ASP.NET untuk melaporkan kesehatan komponen infrastruktur aplikasi. Kerangka kerja ini menyediakan cara untuk melaporkan pemeriksaan kesehatan dengan cara yang konsisten. Ini mengimplementasikan banyak praktik yang dijelaskan artikel ini. Misalnya, pemeriksaan kesehatan ASP.NET mencakup pemeriksaan eksternal seperti konektivitas database dan konsep tertentu seperti pemeriksaan keaktifan dan kesiapan.
Beberapa contoh implementasi yang menggunakan pemeriksaan kesehatan ASP.NET tersedia di GitHub.
Memantau titik akhir di aplikasi yang dihosting Azure
Opsi untuk memantau titik akhir di aplikasi Azure meliputi:
- Gunakan fitur pemantauan bawaan Azure, seperti Azure Monitor.
- Gunakan layanan pihak ketiga atau kerangka kerja seperti Microsoft System Center Operations Manager.
- Buat utilitas kustom atau layanan yang berjalan di server Anda sendiri atau server yang dihosting.
Meskipun Azure menyediakan opsi pemantauan yang komprehensif, Anda dapat menggunakan layanan dan alat tambahan untuk memberikan informasi tambahan. Application Insights, fitur Monitor, dirancang untuk tim pengembangan. Fitur ini membantu Anda memahami performa aplikasi dan cara aplikasi digunakan. Application Insights memantau tingkat permintaan, waktu respons, tingkat kegagalan, dan tingkat dependensi. Ini dapat membantu Anda menentukan apakah layanan eksternal memperlambat Anda.
Kondisi yang dapat Anda pantau tergantung pada mekanisme hosting yang Anda pilih untuk aplikasi Anda. Semua opsi di bagian ini mendukung aturan pemberitahuan. Aturan pemberitahuan menggunakan titik akhir web yang Anda tentukan di pengaturan untuk layanan Anda. Titik akhir ini harus merespons secara tepat waktu sehingga sistem peringatan dapat mendeteksi bahwa aplikasi beroperasi dengan benar. Untuk informasi selengkapnya, lihat Membuat aturan pemberitahuan baru.
Jika ada pemadaman besar, lalu lintas klien harus dapat dirutekan ke penyebaran aplikasi yang tersedia di seluruh wilayah atau zona lain. Situasi ini adalah kasus yang baik untuk konektivitas lintas lokasi dan penyeimbangan beban global. Pilihan tergantung pada apakah aplikasi berhadapan internal atau eksternal. Layanan seperti Azure Front Door, Azure Traffic Manager, atau jaringan pengiriman konten dapat merutekan lalu lintas di seluruh wilayah berdasarkan data yang disediakan pemeriksaan kesehatan.
Traffic Manager adalah layanan perutean dan penyeimbangan beban. Ini dapat menggunakan berbagai aturan dan pengaturan untuk mendistribusikan permintaan ke instans tertentu dari aplikasi Anda. Selain permintaan perutean, Traffic Manager dapat secara teratur melakukan ping URL, port, dan jalur relatif. Anda menentukan target ping dengan tujuan menentukan instans mana dari aplikasi Anda yang aktif dan merespons permintaan. Jika Traffic Manager mendeteksi kode status 200 (OK), Traffic Manager menandai aplikasi sebagai tersedia. Kode status lainnya menyebabkan Traffic Manager menandai aplikasi sebagai offline. Konsol Traffic Manager menampilkan status setiap aplikasi. Anda dapat mengonfigurasi setiap aturan untuk mengalihkan permintaan ke instans lain dari aplikasi yang merespons.
Traffic Manager menunggu beberapa waktu untuk menerima respons dari URL pemantauan. Pastikan kode verifikasi kesehatan Anda berjalan saat ini. Izinkan latensi jaringan untuk perjalanan pulang pergi dari Traffic Manager ke aplikasi Anda dan kembali lagi.
Langkah berikutnya
Panduan berikut berguna untuk menerapkan pola ini:
- Panduan pemantauan kesehatan dalam aplikasi berbasis layanan mikro
- Memantau kesehatan aplikasi untuk keandalan, bagian dari Azure Well-Architected Framework
- Buat aturan peringatan baru