Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Storage
Membuat indeks di atas bidang di penyimpanan data yang sering dirujuk oleh kueri. Pola ini dapat meningkatkan performa kueri dengan memungkinkan aplikasi lebih cepat menemukan lokasi data yang akan diambil dari penyimpanan data.
Konteks dan masalah
Banyak penyimpanan data mengatur data untuk kumpulan entitas menggunakan kunci primer. Aplikasi dapat menggunakan kunci ini untuk mencari dan mengambil data. Gambar menunjukkan contoh penyimpanan data yang menyimpan informasi pelanggan. Kunci primer adalah ID Pelanggan. Gambar menunjukkan informasi pelanggan yang diatur oleh kunci primer (ID Pelanggan).
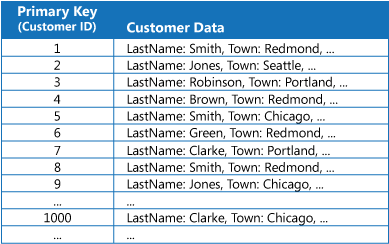
Meskipun kunci primer berharga untuk kueri yang mengambil data berdasarkan nilai kunci ini, aplikasi mungkin tidak dapat menggunakan kunci primer jika perlu mengambil data berdasarkan bidang lain. Dalam contoh pelanggan, aplikasi tidak dapat menggunakan kunci primer ID Pelanggan untuk mengambil pelanggan jika aplikasi mengkueri data hanya dengan mereferensikan nilai beberapa atribut lain, seperti kota tempat pelanggan berada. Untuk melakukan kueri seperti ini, aplikasi mungkin harus mengambil dan memeriksa setiap catatan pelanggan, yang mungkin merupakan proses yang lambat.
Banyak sistem manajemen database relasional mendukung indeks sekunder. Indeks sekunder adalah struktur data terpisah yang diatur oleh satu atau beberapa bidang kunci nonprimer (sekunder), dan indeks sekunder menunjukkan tempat data untuk setiap nilai yang diindeks disimpan. Item dalam indeks sekunder biasanya diurutkan berdasarkan nilai kunci sekunder untuk memungkinkan pencarian data yang cepat. Indeks ini biasanya dipelihara secara otomatis oleh sistem manajemen database.
Anda dapat membuat indeks sekunder sebanyak yang Anda perlukan untuk mendukung berbagai kueri yang dijalankan aplikasi. Misalnya, dalam tabel Pelanggan dalam database hubungan di mana ID Pelanggan adalah kunci primer, akan bermanfaat untuk menambahkan indeks sekunder di atas bidang kota jika aplikasi sering mencari pelanggan berdasarkan kota tempat mereka tinggal.
Namun, meskipun indeks sekunder umum dalam sistem relasional, beberapa penyimpanan data NoSQL yang digunakan oleh aplikasi cloud tidak menyediakan fitur yang setara.
Solusi
Jika penyimpanan data tidak mendukung indeks sekunder, Anda dapat menirunya secara manual dengan membuat tabel indeks Anda sendiri. Tabel indeks mengatur data dengan kunci tertentu. Tiga strategi biasanya digunakan untuk menyusun tabel indeks, bergantung pada jumlah indeks sekunder yang diperlukan dan sifat kueri yang dijalankan aplikasi.
Strategi pertama adalah menduplikasi data di setiap tabel indeks tetapi mengaturnya dengan kunci yang berbeda (denormalisasi lengkap). Gambar berikutnya menunjukkan tabel indeks yang mengatur informasi pelanggan yang sama berdasarkan Town dan LastName.
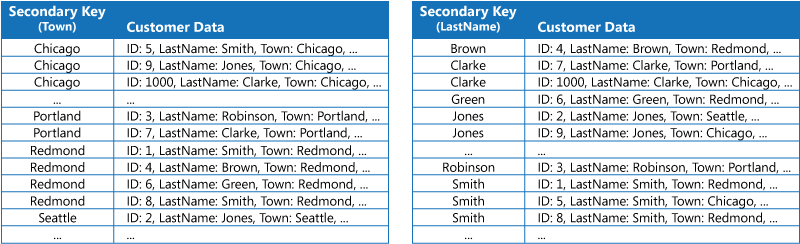
Strategi ini sesuai jika data relatif statik dibandingkan dengan berapa kali data dikueri menggunakan setiap kunci. Jika data lebih dinamis, biaya pemrosesan untuk mempertahankan setiap tabel indeks menjadi terlalu besar untuk pendekatan ini agar berguna. Selain itu, jika volume data tinggi, jumlah ruang yang diperlukan untuk menyimpan data duplikat signifikan.
Strategi kedua adalah membuat tabel indeks yang dinormalisasi yang diatur oleh kunci yang berbeda dan mereferensikan data asli dengan menggunakan kunci primer daripada menduplikasinya, seperti yang ditunjukkan pada gambar berikut. Data asli disebut tabel fakta.
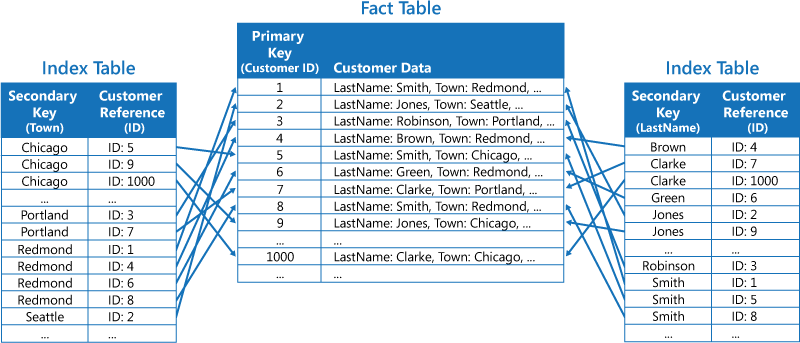
Teknik ini menghemat ruang dan mengurangi biaya pemeliharaan data duplikat. Kerugiannya adalah aplikasi harus melakukan dua operasi pencarian untuk menemukan data menggunakan kunci sekunder. Aplikasi harus menemukan kunci primer untuk data dalam tabel indeks, dan kemudian menggunakan kunci primer untuk mencari data di tabel fakta.
Strategi ketiga adalah membuat tabel indeks yang dinormalisasi sebagian yang diatur oleh kunci berbeda yang menduplikasi bidang yang sering diambil. Referensikan tabel fakta untuk mengakses bidang yang jarang diakses. Gambar berikut menunjukkan bagaimana data yang sering diakses diduplikasi di setiap tabel indeks.
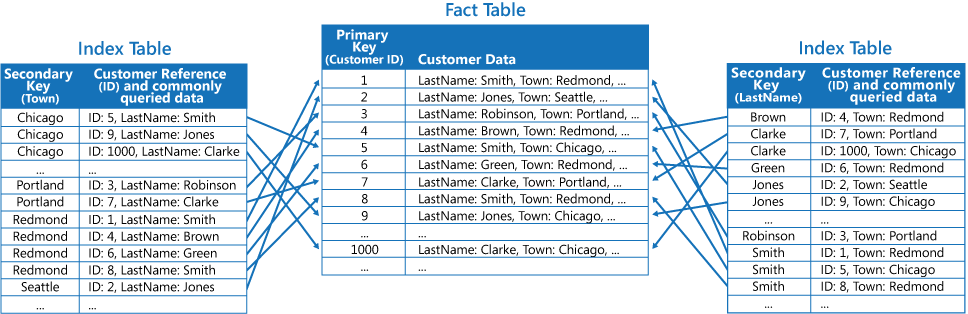
Dengan strategi ini, Anda dapat mencapai keseimbangan antara dua pendekatan pertama. Data untuk kueri umum dapat diambil dengan cepat dengan menggunakan satu pencarian, sementara ruang dan biaya pemeliharaan tidak sepenting menduplikasi seluruh himpunan data.
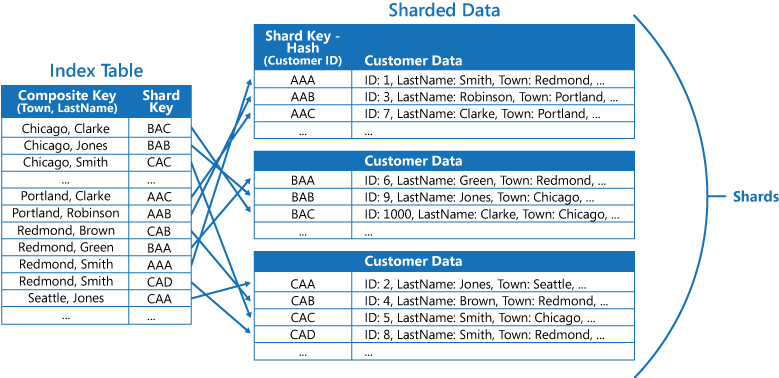
Jika aplikasi sering mengkueri data dengan menentukan kombinasi nilai (misalnya, "Temukan semua pelanggan yang tinggal di Redmond dan yang memiliki nama belakang Smith"), Anda dapat menerapkan kunci ke item dalam tabel indeks sebagai rangkaian dari atribut Town dan atribut LastName. Gambar berikutnya menunjukkan tabel indeks berdasarkan kunci komposit. Kunci diurutkan berdasarkan Town, lalu berdasarkan LastName untuk rekaman yang memiliki nilai yang sama untuk Town.

Tabel indeks dapat mempercepat operasi kueri pada data yang dipecah, dan sangat berguna jika kunci pecahan di-hash. Gambar berikutnya menunjukkan contoh di mana kunci pecahan adalah hash dari ID Pelanggan. Tabel indeks dapat mengatur data berdasarkan nilai non-hash (Town dan LastName), dan menyediakan kunci pecahan hash sebagai data pencarian. Hal ini dapat menghindarkan aplikasi dari penghitungan kunci hash berulang kali (operasi yang mahal) jika perlu mengambil data yang berada dalam rentang, atau perlu mengambil data sesuai urutan kunci non-hash. Misalnya, kueri seperti "Temukan semua pelanggan yang tinggal di Redmond" dapat diselesaikan dengan cepat dengan menempatkan item yang cocok di tabel indeks, di mana semua item yang cocok disimpan dalam blok yang berdekatan. Kemudian, ikuti referensi ke data pelanggan menggunakan kunci pecahan yang disimpan di tabel indeks.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
Biaya mengelola indeks sekunder dapat menjadi signifikan. Anda harus menganalisis dan memahami kueri yang digunakan aplikasi. Buat tabel indeks hanya jika kemungkinan besar akan digunakan secara teratur. Jangan membuat tabel indeks spekulatif untuk mendukung kueri yang tidak dijalankan oleh aplikasi, atau hanya sesekali dijalankan.
Menduplikasi data dalam tabel indeks dapat menambah biaya penyimpanan yang signifikan dan upaya yang diperlukan untuk memelihara banyak salinan data.
Menerapkan tabel indeks sebagai struktur normal yang mereferensikan data asli memerlukan aplikasi untuk melakukan dua operasi pencarian untuk menemukan data. Operasi pertama mencari tabel indeks untuk mengambil kunci primer, dan yang kedua menggunakan kunci primer untuk mengambil data.
Jika sistem menggabungkan sejumlah tabel indeks melalui himpunan data besar, mungkin sulit untuk mempertahankan konsistensi antara tabel indeks dan data asli. Ada kemungkinan untuk dapat merancang aplikasi di sekitar model konsistensi akhir. Misalnya, untuk menyisipkan, memperbarui, atau menghapus data, aplikasi dapat mengirim pesan ke antrean dan membiarkan tugas terpisah melakukan operasi serta memelihara tabel indeks yang mereferensikan data ini secara asinkron. Untuk informasi selengkapnya tentang menerapkan konsistensi akhir, lihat Data Consistency Primer.
Petunjuk / Saran
Tabel penyimpanan Microsoft Azure mendukung pembaruan transaksional untuk perubahan yang dibuat pada data yang disimpan di partisi yang sama (disebut sebagai transaksi grup entitas). Jika Anda dapat menyimpan data untuk tabel fakta dan satu atau beberapa tabel indeks di partisi yang sama, Anda dapat menggunakan fitur ini untuk membantu memastikan konsistensi.
Tabel indeks dapat dipartisi atau dipecah.
Kapan menggunakan pola ini
Gunakan pola ini untuk meningkatkan performa kueri saat aplikasi sering kali perlu mengambil data dengan menggunakan kunci selain kunci primer (atau pecahan).
Pola ini mungkin tidak berguna jika:
- Data tidak stabil. Tabel indeks dapat menjadi kedaluwarsa dengan sangat cepat, membuatnya tidak efektif atau membuat biaya pemeliharaan tabel indeks lebih besar daripada penghematan yang dilakukan dengan menggunakannya.
- Bidang yang dipilih sebagai kunci sekunder untuk tabel indeks tidak diskriminatif dan hanya dapat memiliki kumpulan nilai yang kecil (misalnya, jenis kelamin).
- Keseimbangan nilai data untuk bidang yang dipilih sebagai kunci sekunder untuk tabel indeks sangat tidak seimbang. Misalnya, jika 90% dari rekaman berisi nilai yang sama dalam suatu bidang, maka membuat dan memelihara tabel indeks untuk mencari data berdasarkan bidang ini mungkin membuat lebih banyak biaya daripada memindai data secara berurutan. Tetapi, jika kueri sangat sering menargetkan nilai yang terletak di 10% sisanya, indeks ini dapat berguna. Anda harus memahami kueri yang dijalankan aplikasi Anda, dan seberapa sering kueri tersebut dijalankan.
Desain beban kerja
Arsitek harus mengevaluasi bagaimana pola Tabel Indeks dapat digunakan dalam desain beban kerja mereka untuk mengatasi tujuan dan prinsip yang tercakup dalam pilar Azure Well-Architected Framework. Contohnya:
| Pilar | Bagaimana pola ini mendukung tujuan pilar |
|---|---|
| Keputusan desain keandalan membantu beban kerja Anda menjadi tahan terhadap kerusakan dan untuk memastikan bahwa keputusan tersebut pulih ke status berfungsi penuh setelah kegagalan terjadi. | Karena klien diarahkan ke shard, partisi, atau titik akhir mereka melalui proses pencarian, Anda dapat menggunakan pola ini untuk memfasilitasi pendekatan failover untuk akses data. - Pemartisian data RE:06 - RE:09 Pemulihan bencana |
| Efisiensi Performa membantu beban kerja Anda memenuhi tuntutan secara efisien melalui pengoptimalan dalam penskalaan, data, kode. | Klien diarahkan ke shard, partisi, atau titik akhir mereka, yang dapat mengaktifkan partisi data dinamis untuk pengoptimalan performa. - PE:05 Penskalaan dan pemartisian - Performa DATA PE:08 |
Seperti halnya keputusan desain apa pun, pertimbangkan tradeoff terhadap tujuan pilar lain yang mungkin diperkenalkan dengan pola ini.
Contoh
Tabel penyimpanan Azure menyediakan penyimpanan data kunci/nilai yang sangat dapat diskalakan untuk aplikasi yang berjalan di cloud. Aplikasi menyimpan dan mengambil nilai data dengan menentukan kunci. Nilai data ini dapat berisi beberapa bidang, tetapi struktur item data tidak terlihat oleh penyimpanan tabel, yang memperlakukan setiap item sebagai larik byte.
Tabel penyimpanan Azure juga mendukung sharding. Kunci sharding mencakup dua elemen, kunci partisi dan kunci baris. Item yang memiliki kunci partisi yang sama disimpan di partisi yang sama (pecahan), dan item disimpan dalam urutan kunci baris dalam pecahan. Penyimpanan tabel dioptimalkan untuk melakukan kueri yang mengambil data yang berada dalam rentang nilai kunci baris yang berdekatan dalam partisi. Jika sedang membangun aplikasi cloud yang menyimpan informasi di tabel Azure, Anda harus menyusun data dengan mempertimbangkan fitur ini.
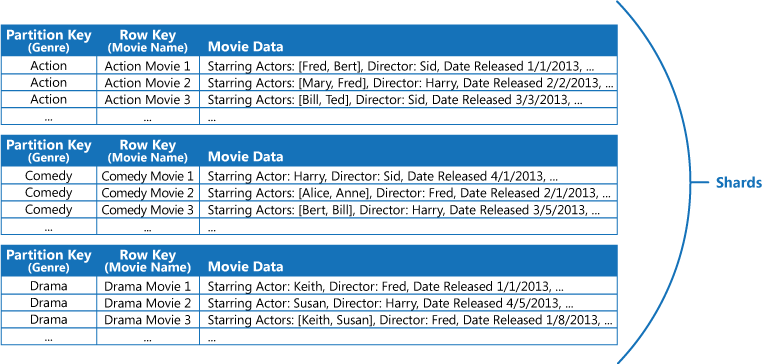
Misalnya, pertimbangkan aplikasi yang menyimpan informasi tentang film. Aplikasi ini sering kali mencari film berdasarkan jenis seperti aksi, dokumenter, sejarah, komedi, dan drama. Anda dapat membuat tabel Azure dengan partisi untuk setiap genre dengan menggunakan genre sebagai kunci partisi, dan menentukan nama film sebagai kunci baris, seperti yang ditunjukkan pada gambar berikutnya.
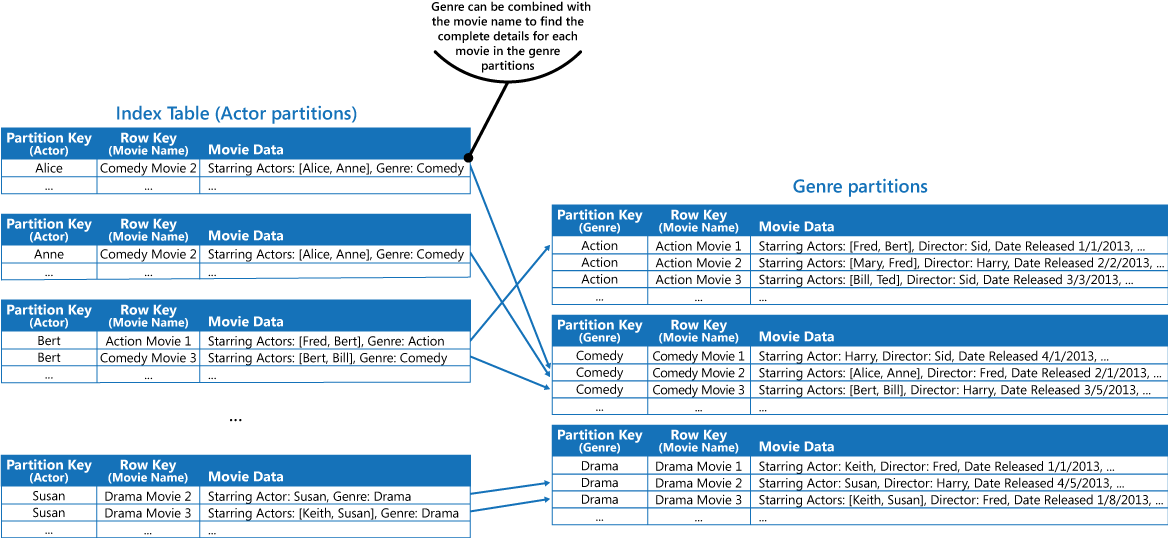
Pendekatan ini kurang efektif jika aplikasi juga perlu mengkueri film dengan aktor yang membintangi. Dalam kasus ini, Anda dapat membuat tabel Azure terpisah yang berfungsi sebagai tabel indeks. Kunci partisi adalah aktor dan kunci baris adalah nama film. Data untuk setiap aktor akan disimpan dalam partisi terpisah. Jika film dibintangi oleh lebih dari satu aktor, film yang sama akan muncul di beberapa partisi.
Anda dapat menduplikasi data film dalam nilai yang dipegang oleh setiap partisi dengan mengadopsi pendekatan pertama yang dijelaskan di bagian Solusi di atas. Tetapi, kemungkinan setiap film akan direplikasi beberapa kali (sekali untuk setiap aktor), jadi mungkin lebih efisien untuk mendenormalisasi sebagian data untuk mendukung kueri paling umum (seperti nama aktor lain) dan mengaktifkan aplikasi untuk mengambil detail yang tersisa dengan memasukkan kunci partisi yang diperlukan untuk menemukan informasi lengkap dalam partisi genre. Pendekatan ini dijelaskan oleh opsi ketiga di bagian Solusi. Gambar berikut menunjukkan pendekatan ini.
Langkah berikutnya
- Primer Konsistensi Data. Tabel indeks harus dipertahankan saat data yang diindeks berubah. Di cloud, mungkin tidak mungkin atau tidak tepat untuk melakukan operasi yang memperbarui indeks sebagai bagian dari transaksi yang sama yang mengubah data. Dalam kasus ini, pendekatan konsisten akhir lebih cocok. Memberikan informasi tentang masalah seputar konsistensi akhir.
Sumber daya terkait
Pola berikut mungkin juga relevan saat menerapkan pola ini:
- Pola sharding. Pola Tabel Indeks sering digunakan bersama dengan data yang dipartisi dengan menggunakan pecahan. Pola Sharding memberikan lebih banyak informasi tentang cara membagi penyimpanan data menjadi satu set pecahan.
- Pola Tampilan Terwujud. Daripada mengindeks data untuk mendukung kueri yang merangkum data, mungkin lebih tepat untuk membuat tampilan materialisasi data. Menjelaskan cara mendukung kueri ringkasan yang efisien dengan menghasilkan tampilan data yang telah terisi sebelumnya.