Mengoordinasikan tindakan yang dilakukan oleh kumpulan instans yang berkolaborasi dalam aplikasi terdistribusi dengan memilih satu instans sebagai pemimpin yang bertanggung jawab untuk mengelola instans lain. Ini dapat membantu memastikan instans tidak bertentangan satu sama lain, menyebabkan perselisihan untuk sumber daya bersama, atau secara tidak sengaja mengganggu pekerjaan yang dilakukan instans lain.
Konteks dan masalah
Aplikasi cloud umumnya memiliki banyak tugas yang berfungsi secara terkoordinasi. Tugas-tugas ini semua bisa menjadi instans yang menjalankan kode yang sama dan membutuhkan akses ke sumber daya yang sama, atau mereka mungkin bekerja sama secara paralel untuk melakukan masing-masing bagian dari perhitungan yang kompleks.
Instans tugas mungkin sering berjalan secara terpisah, tetapi mungkin juga perlu mengoordinasikan tindakan setiap instans untuk memastikan bahwa mereka tidak bertentangan, menyebabkan perselisihan untuk sumber daya bersama, atau secara tidak sengaja mengganggu pekerjaan yang dilakukan instans tugas lain.
Contohnya:
- Dalam sistem berbasis cloud yang menerapkan penskalaan horizontal, beberapa instans tugas yang sama dapat berjalan pada saat yang sama dengan setiap instans yang melayani pengguna yang berbeda. Jika instans ini ditulis ke sumber daya bersama, perlu untuk mengoordinasikan tindakan mereka agar setiap instans tidak menimpa perubahan yang dibuat oleh orang lain.
- Jika tugas melakukan elemen individu dari perhitungan yang kompleks secara paralel, hasilnya harus dikumpulkan begitu semuanya selesai.
Instans tugas adalah semuanya rekan, jadi tidak ada pemimpin alami yang dapat bertindak sebagai koordinator atau agregator.
Solusi
Satu instans tugas harus dipilih untuk bertindak sebagai pemimpin, dan instans ini harus mengoordinasikan tindakan instans tugas bawahan lainnya. Jika semua instans tugas menjalankan kode yang sama, mereka masing-masing mampu bertindak sebagai pemimpin. Oleh karena itu, proses pemilihan harus dikelola dengan hati-hati untuk mencegah dua atau lebih instans mengambil alih posisi pemimpin pada saat yang sama.
Sistem harus menyediakan mekanisme yang kuat untuk memilih pemimpin. Metode ini harus mengatasi peristiwa seperti gangguan jaringan atau kegagalan proses. Dalam banyak solusi, instans tugas bawahan memantau pemimpin melalui beberapa jenis metode detak jantung, atau dengan polling. Jika pemimpin yang ditunjuk berakhir secara tak terduga, atau kegagalan jaringan membuat pemimpin tidak tersedia untuk instans tugas bawahan, penting bagi mereka untuk memilih pemimpin baru.
Ada beberapa strategi untuk memilih pemimpin di antara serangkaian tugas di lingkungan terdistribusi, termasuk:
- Berlomba untuk mendapatkan mutex terdistribusi bersama. Instans tugas pertama yang memperoleh mutex akan menjadi pemimpin. Namun, sistem harus memastikan bahwa, jika pemimpin berakhir atau menjadi terputus dari sistem, mutex akan dilepaskan agar instans tugas lain dapat menjadi pemimpin. Strategi ini ditunjukkan dalam contoh yang disertakan di bawah ini.
- Menerapkan salah satu algoritma pemilihan pemimpin umum seperti Algoritma Bully, Algoritma Konsekuensi Rakit, atau Algoritma Cincin. Algoritma ini mengasumsikan bahwa setiap kandidat dalam pemilihan memiliki ID yang unik, dan dapat berkomunikasi dengan kandidat lain dengan andal.
Masalah dan pertimbangan
Pertimbangkan poin-poin berikut saat memutuskan cara menerapkan pola ini:
- Proses pemilihan pemimpin harus tangguh terhadap kegagalan sementara dan persisten.
- Proses ini harus dapat mendeteksi kapan pemimpin gagal atau menjadi tidak tersedia (seperti karena kegagalan komunikasi). Seberapa cepat deteksi diperlukan tergantung pada sistem. Beberapa sistem mungkin dapat berfungsi dalam waktu yang singkat tanpa pemimpin, saat kesalahan sementara dapat diperbaiki. Dalam kasus lain, mungkin perlu mendeteksi kegagalan pemimpin segera dan memicu pemilihan baru.
- Dalam sistem yang menerapkan penskalaan otomatis horizontal, pemimpin dapat dihentikan jika sistem menskalakan ulang dan mematikan beberapa sumber daya komputasi.
- Menggunakan mutex terdistribusi bersama akan memperkenalkan dependensi pada layanan eksternal yang menyediakan mutex. Layanan ini merupakan satu titik kegagalan. Jika menjadi tidak tersedia karena alasan apa pun, sistem tidak akan dapat memilih pemimpin.
- Menggunakan satu proses khusus sebagai pemimpin adalah pendekatan langsung. Namun, jika prosesnya gagal, mungkin ada penundaan yang signifikan saat dimulai ulang. Latensi yang dihasilkan dapat memengaruhi waktu performa dan respons proses lain jika mereka menunggu pemimpin untuk mengoordinasikan operasi.
- Menerapkan salah satu algoritma pemilihan pemimpin secara manual memberikan fleksibilitas terbesar untuk menyetel dan mengoptimalkan kode.
- Hindari membuat pemimpin menjadi hambatan dalam sistem. Tujuan pemimpin adalah untuk mengoordinasikan pekerjaan tugas bawahan, dan tidak harus berpartisipasi dalam pekerjaan ini sendiri—meskipun harus dapat melakukannya jika tugas tidak dipilih sebagai pemimpin.
Kapan menggunakan pola ini
Gunakan pola ini jika tugas dalam aplikasi terdistribusi, seperti solusi yang di-hosting cloud, perlu koordinasi yang cermat dan tidak ada pemimpin alami.
Pola ini mungkin tidak berguna jika:
- Ada pemimpin alami atau proses khusus yang selalu dapat bertindak sebagai pemimpin. Misalnya, dapat menerapkan proses tunggal yang mengoordinasikan instans tugas. Jika proses ini gagal atau menjadi tidak sehat, sistem dapat mematikannya dan memulai ulang.
- Koordinasi antar tugas dapat dicapai dengan menggunakan metode yang lebih ringan. Misalnya, jika beberapa instans tugas hanya memerlukan akses terkoordinasi ke sumber daya bersama, solusi yang lebih baik adalah menggunakan penguncian optimis atau pesimis untuk mengontrol akses.
- Solusi pihak ketiga, seperti Apache Zookeper mungkin merupakan solusi yang lebih efisien.
Desain beban kerja
Arsitek harus mengevaluasi bagaimana pola Pemilihan Pemimpin dapat digunakan dalam desain beban kerja mereka untuk mengatasi tujuan dan prinsip yang tercakup dalam pilar Azure Well-Architected Framework. Contohnya:
| Pilar | Bagaimana pola ini mendukung tujuan pilar |
|---|---|
| Keputusan desain keandalan membantu beban kerja Anda menjadi tahan terhadap kerusakan dan untuk memastikan bahwa keputusan tersebut pulih ke status berfungsi penuh setelah kegagalan terjadi. | Pola ini mengurangi efek kerusakan simpul dengan mengalihkan pekerjaan dengan andal. Ini juga menerapkan failover melalui algoritma konsekuensi ketika pemimpin tidak berfungsi. - RE:05 Redundansi - RE:07 Penyembuhan Diri |
Seperti halnya keputusan desain apa pun, pertimbangkan tradeoff terhadap tujuan pilar lain yang mungkin diperkenalkan dengan pola ini.
Contoh
Sampel Pemilihan Pemimpin di GitHub menunjukkan cara menggunakan sewa pada blob Azure Storage untuk menyediakan mekanisme untuk menerapkan mutex bersama dan terdistribusi. Mutex ini dapat digunakan untuk memilih pemimpin di antara sekelompok instans pekerja yang tersedia. Instans pertama untuk memperoleh sewa dipilih sebagai pemimpin dan tetap menjadi pemimpin sampai melepaskan sewa atau tidak dapat memperbarui sewa. Instans pekerja lain dapat terus memantau sewa blob jika pemimpin tidak lagi tersedia.
Sewa blob adalah kunci tulis eksklusif di atas blob. Satu blob dapat menjadi subjek hanya satu sewa pada setiap titik waktu. Instans pekerja dapat meminta sewa atas blob tertentu, dan akan diberikan sewa jika tidak ada instans pekerja lain yang memegang sewa atas blob yang sama. Jika tidak, permintaan akan melemparkan pengecualian.
Untuk menghindari instans pemimpin yang rusak mempertahankan sewa tanpa batas waktu, tentukan masa pakai untuk sewa. Saat ini berakhir, sewa menjadi tersedia. Namun, sementara instans memegang sewa, instans dapat meminta agar sewa diperbarui, dan akan diberikan sewa untuk jangka waktu lebih lanjut. Instans pemimpin dapat terus mengulangi proses ini jika ingin mempertahankan sewa. Untuk informasi selengkapnya tentang cara menyewa blob, lihat Menyewa Blob (REST API).
Kelas BlobDistributedMutex dalam contoh C# di bawah ini berisi RunTaskWhenMutexAcquired metode yang memungkinkan instans pekerja untuk mencoba memperoleh sewa atas blob tertentu. Detail blob (nama, kontainer, dan akun penyimpanan) diteruskan ke konstruktor dalam objek BlobSettings saat objek BlobDistributedMutex dibuat (objek ini adalah struktur sederhana yang termasuk dalam kode sampel). Konstruktor juga menerima yang mereferensikan Task kode yang harus dijalankan instans pekerja jika berhasil memperoleh sewa atas blob dan dipilih sebagai pemimpin. Harap diingat bahwa kode yang menangani detail tingkat rendah untuk memperoleh sewa akan diterapkan dalam kelas pembantu terpisah bernama BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
Metode RunTaskWhenMutexAcquired dalam sampel kode di atas memanggil metode RunTaskWhenBlobLeaseAcquired yang ditunjukkan dalam sampel kode berikut agar benar-benar memperoleh sewa. Metode RunTaskWhenBlobLeaseAcquired akan berjalan secara asinkron. Jika sewa berhasil diperoleh, instans pekerja telah dipilih sebagai pemimpin. Tujuan delegasi taskToRunWhenLeaseAcquired adalah untuk melakukan pekerjaan yang mengoordinasikan instans pekerja lainnya. Jika sewa tidak diperoleh, instans pekerja lain telah dipilih sebagai pemimpin dan instans pekerja saat ini tetap menjadi bawahan. Harap diingat bahwa metode TryAcquireLeaseOrWait adalah metode pembantu yang menggunakan objek BlobLeaseManager untuk memperoleh sewa.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
Tugas yang dimulai oleh pemimpin juga akan berjalan secara asinkron. Saat tugas ini berjalan, metode RunTaskWhenBlobLeaseAcquired yang ditunjukkan dalam sampel kode berikut secara berkala mencoba memperpanjang sewa. Ini membantu memastikan bahwa instans pekerja tetap menjadi pemimpin. Dalam solusi sampel, penundaan antara permintaan perpanjangan kurang dari waktu yang ditentukan selama durasi sewa untuk mencegah instans pekerja lain dipilih sebagai pemimpin. Jika perpanjangan gagal karena alasan apa pun, tugas khusus pemimpin dibatalkan.
Jika sewa gagal diperpanjang atau tugas dibatalkan (mungkin akibat instans pekerja dimatikan), sewa akan dilepaskan. Pada titik ini, instans pekerja ini atau lainnya dapat dipilih sebagai pemimpin. Ekstrak kode di bawah ini menunjukkan bagian dari proses ini.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
Metode KeepRenewingLease adalah metode pembantu lain yang menggunakan objek BlobLeaseManager untuk memperpanjang sewa. Metode CancelAllWhenAnyCompletes membatalkan tugas yang ditentukan sebagai dua parameter pertama. Diagram berikut menggambarkan penggunaan kelas BlobDistributedMutex untuk memilih pemimpin dan menjalankan tugas yang mengoordinasikan operasi.
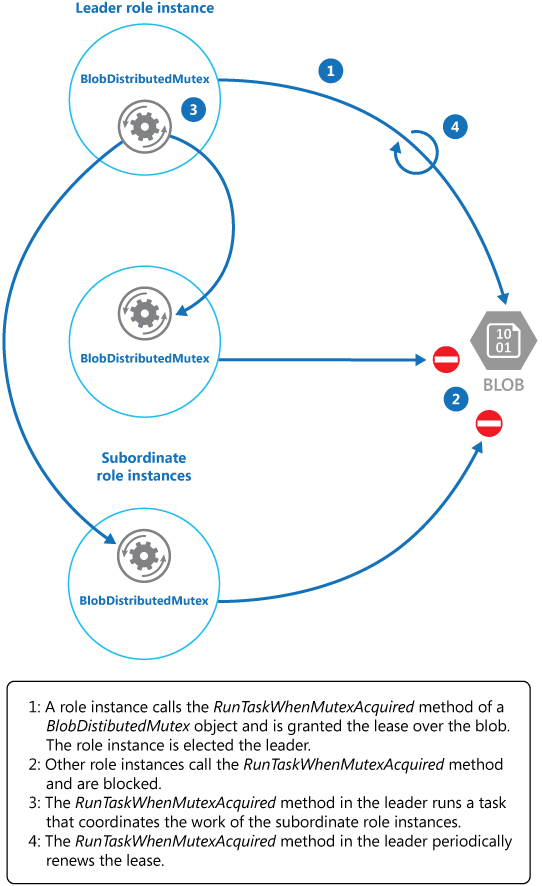
Contoh kode berikut menunjukkan cara menggunakan BlobDistributedMutex kelas dalam instans pekerja. Kode ini memperoleh sewa atas blob bernama MyLeaderCoordinatorTask dalam kontainer sewa Azure Blob Storage, dan menentukan bahwa kode yang ditentukan dalam MyLeaderCoordinatorTask metode harus berjalan jika instans pekerja dipilih sebagai pemimpin.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Perhatikan poin-poin berikut tentang solusi sampel:
- Blob adalah satu titik kegagalan yang potensial. Jika layanan blob menjadi tidak tersedia, atau tidak dapat diakses, pemimpin tidak akan dapat memperbarui sewa dan tidak ada instans pekerja lain yang akan dapat memperoleh sewa. Dalam hal ini, tidak ada instans pekerja yang akan dapat bertindak sebagai pemimpin. Namun, layanan blob dirancang agar tangguh, sehingga kegagalan total layanan blob dianggap sangat tidak mungkin terjadi.
- Jika tugas yang dilakukan oleh pemimpin warung, pemimpin mungkin terus memperbarui sewa, mencegah instans pekerja lain memperoleh sewa dan mengambil alih posisi pemimpin untuk mengoordinasikan tugas. Di dunia nyata, kondisi pemimpin harus diperiksa secara berkala.
- Proses pemilihan tidak ditentukan. Anda tidak dapat membuat asumsi tentang instans pekerja mana yang akan memperoleh sewa blob dan menjadi pemimpin.
- Blob yang digunakan sebagai target sewa blob tidak boleh digunakan untuk tujuan lain. Jika instans pekerja mencoba menyimpan data dalam blob ini, data ini tidak akan dapat diakses kecuali instans pekerja adalah pemimpin dan menyimpan sewa blob.
Langkah berikutnya
Panduan berikut bisa jadi relevan saat menerapkan pola berikut ini:
- Pola ini memiliki aplikasi sampel yang dapat diunduh.
- Panduan Penskalaan Otomatis. Ini dapat memulai dan menghentikan instans host tugas karena beban pada aplikasi bervariasi. Penskalaan otomatis dapat membantu mempertahankan throughput dan performa selama waktu pemrosesan puncak.
- Pola Asinkron berbasis tugas.
- Contoh yang menggambarkan Algoritma Bully.
- Contoh yang menggambarkan Algoritma Cincin.
- Apache Curator pustaka klien untuk Apache ZooKeeper.
- Artikel Menyewa Blob (REST API) tentang MSDN.