Aktifkan aplikasi untuk menangani kegagalan sementara saat mencoba terhubung ke layanan atau sumber daya jaringan, dengan mencoba kembali operasi yang gagal secara transparan. Hal ini dapat meningkatkan stabilitas aplikasi.
Konteks dan masalah
Aplikasi yang berkomunikasi dengan elemen yang berjalan di cloud harus sensitif terhadap kesalahan sementara yang dapat terjadi di lingkungan ini. Kesalahan termasuk hilangnya sesaat konektivitas jaringan ke komponen dan layanan, tidak tersedianya layanan untuk sementara, atau batas waktu yang terjadi saat layanan sibuk.
Kesalahan ini biasanya teratasi dengan sendirinya, dan jika tindakan yang memicu kesalahan diulangi setelah penundaan yang sesuai, kemungkinan besar akan berhasil. Misalnya, layanan database yang memproses sejumlah besar permintaan bersamaan dapat menerapkan strategi pembatasan yang untuk sementara menolak permintaan lebih lanjut sampai beban kerjanya telah mereda. Aplikasi yang mencoba mengakses database mungkin gagal terhubung, tetapi jika mencoba kembali setelah penundaan mungkin berhasil.
Solusi
Di cloud, kesalahan sementara sering terjadi dan aplikasi harus dirancang untuk menanganinya secara efisien dan transparan. Hal ini meminimalkan efek kesalahan pada tugas bisnis yang dilakukan aplikasi.
Jika aplikasi mendeteksi kegagalan saat mencoba mengirim permintaan ke layanan jarak jauh, aplikasi dapat menangani kegagalan menggunakan strategi berikut:
Batalkan. Jika kesalahan menunjukkan bahwa kegagalan tidak sementara atau tidak mungkin berhasil jika diulang, aplikasi harus membatalkan operasi dan melaporkan pengecualian. Misalnya, kegagalan autentikasi yang disebabkan oleh pemberian kredensial yang tidak valid kemungkinan besar tidak akan berhasil tidak peduli berapa kali dicoba.
Coba lagi. Jika kesalahan tertentu yang dilaporkan tidak biasa atau jarang terjadi, kesalahan mungkin disebabkan oleh keadaan yang tidak biasa seperti paket jaringan menjadi rusak saat sedang dikirim. Dalam kasus ini, aplikasi dapat mencoba kembali permintaan yang gagal dengan segera karena kegagalan yang sama tidak mungkin terulang dan permintaan mungkin akan berhasil.
Coba kembali setelah penundaan. Jika kesalahan disebabkan oleh salah satu konektivitas yang lebih umum atau kegagalan sibuk, jaringan atau layanan mungkin memerlukan waktu yang singkat sementara masalah konektivitas diperbaiki atau tumpukan pekerjaan dibersihkan. Aplikasi harus menunggu waktu yang sesuai sebelum mencoba kembali permintaan.
Untuk kegagalan sementara yang lebih umum, periode antara percobaan kembali harus dipilih untuk menyebarkan permintaan dari beberapa instans aplikasi secara merata. Hal ini mengurangi kemungkinan layanan yang sibuk terus mengalami kelebihan beban. Jika banyak instans aplikasi terus-menerus membanjiri layanan dengan permintaan percobaan kembali, layanan akan membutuhkan waktu lebih lama untuk pulih.
Jika permintaan masih gagal, aplikasi dapat menunggu dan melakukan upaya lain. Jika perlu, proses ini dapat diulangi dengan penundaan yang meningkat antara upaya percobaan kembali, hingga beberapa permintaan maksimum telah dicoba. Penundaan dapat ditingkatkan secara bertahap atau eksponensial, bergantung pada jenis kegagalan dan peluang bahwa kegagalan akan diperbaiki secepatnya.
Diagram berikut menggambarkan pemanggilan operasi di layanan yang dihosting menggunakan pola ini. Jika permintaan tidak berhasil setelah beberapa upaya yang telah ditentukan, aplikasi harus memperlakukan kesalahan sebagai pengecualian dan menanganinya dengan sesuai.
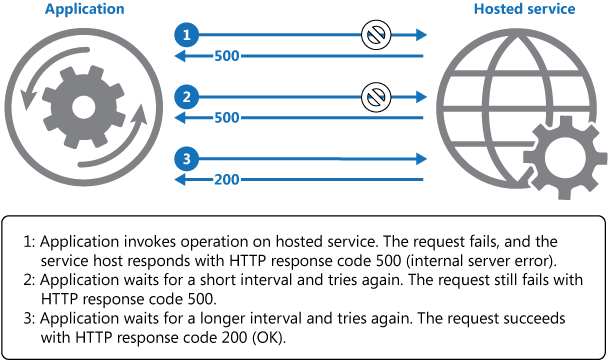
Aplikasi harus membungkus semua upaya untuk mengakses layanan jarak jauh dalam kode yang menerapkan kebijakan percobaan kembali yang cocok dengan salah satu strategi yang tercantum di atas. Permintaan yang dikirim ke layanan yang berbeda dapat tunduk pada kebijakan yang berbeda. Beberapa vendor menyediakan pustaka yang menerapkan kebijakan percobaan kembali, tempat aplikasi dapat menentukan jumlah maksimum percobaan kembali, waktu antara upaya percobaan kembali, dan parameter lainnya.
Aplikasi harus mencatat detail kesalahan dan operasi yang gagal. Informasi ini berguna untuk operator. Oleh karena itu, untuk menghindari membanjiri operator dengan peringatan pada operasi di mana upaya percobaan kembali berikutnya berhasil, yang terbaik adalah mencatat kegagalan awal sebagai entri informasi dan hanya kegagalan terakhir dari upaya percobaan kembali sebagai kesalahan yang sebenarnya. Berikut adalah contoh bagaimana model pengelogan ini akan terlihat.
Jika layanan sering tidak tersedia atau sibuk, biasanya disebabkan karena layanan telah kehabisan sumber dayanya. Anda dapat mengurangi frekuensi kesalahan ini dengan meluaskan skala layanan. Misalnya, jika layanan database terus-menerus kelebihan beban, mungkin bermanfaat untuk mempartisi database dan menyebarkan beban ke beberapa server.
Microsoft Entity Framework menyediakan fasilitas untuk mencoba kembali operasi database. Selain itu, sebagian besar layanan Azure dan SDK klien menyertakan mekanisme percobaan kembali. Untuk informasi selengkapnya, lihat Panduan percobaan kembali untuk layanan tertentu.
Masalah dan pertimbangan
Anda harus mempertimbangkan poin-poin berikut ketika memutuskan bagaimana menerapkan pola ini.
Kebijakan percobaan kembali harus disetel agar sesuai dengan persyaratan bisnis aplikasi dan sifat kegagalan. Untuk beberapa operasi yang tidak penting, lebih baik gagal dengan cepat daripada mencoba kembali beberapa kali dan memengaruhi throughput aplikasi. Misalnya, dalam aplikasi web interaktif yang mengakses layanan jarak jauh, lebih baik gagal setelah sejumlah kecil percobaan kembali dengan hanya penundaan singkat antara upaya percobaan kembali, dan menampilkan pesan yang sesuai kepada pengguna (misalnya, "silakan coba kembali nanti" ). Untuk aplikasi batch, mungkin lebih tepat untuk meningkatkan jumlah upaya percobaan kembali dengan penundaan yang meningkat secara eksponensial di antara upaya.
Kebijakan percobaan kembali yang agresif dengan penundaan yang minimal di antara upaya, dan sejumlah besar percobaan kembali, dapat semakin memperburuk layanan sibuk yang berjalan mendekati atau pada kapasitasnya. Kebijakan percobaan kembali ini juga dapat memengaruhi kecepatan respons aplikasi jika terus mencoba melakukan operasi yang gagal.
Jika permintaan masih gagal setelah sejumlah besar percobaan kembali, lebih baik aplikasi mencegah permintaan selengkapnya masuk ke sumber yang sama dan segera melaporkan kegagalan. Saat periode berakhir, aplikasi dapat secara tentatif mengizinkan satu atau beberapa permintaan untuk melihat apakah permintaan tersebut berhasil. Untuk detail selengkapnya tentang strategi ini, lihat pola Pemutus Sirkuit.
Pertimbangkan apakah operasi tersebut idempoten. Jika benar demikian, secara inheren aman untuk mencoba kembali. Jika tidak, percobaan kembali dapat menyebabkan operasi dijalankan lebih dari sekali, dengan efek samping yang tidak diinginkan. Misalnya, layanan mungkin menerima permintaan, memproses permintaan dengan sukses, tetapi gagal mengirim respons. Pada saat itu, logika percobaan kembali mungkin mengirim ulang permintaan, dengan asumsi bahwa permintaan pertama tidak diterima.
Permintaan ke layanan dapat gagal karena berbagai alasan yang memunculkan pengecualian berbeda bergantung pada sifat kegagalannya. Beberapa pengecualian menunjukkan kegagalan yang dapat diselesaikan dengan cepat, sementara yang lain menunjukkan bahwa kegagalan tersebut bertahan lebih lama. Kebijakan percobaan kembali berguna untuk menyesuaikan waktu antara percobaan kembali berdasarkan jenis pengecualian.
Pertimbangkan bagaimana mencoba kembali operasi yang merupakan bagian dari transaksi akan memengaruhi konsistensi transaksi secara keseluruhan. Sesuaikan kebijakan percobaan kembali untuk operasi transaksional guna memaksimalkan peluang keberhasilan dan mengurangi kebutuhan untuk membatalkan semua langkah transaksi.
Pastikan bahwa semua kode percobaan kembali diuji sepenuhnya terhadap berbagai kondisi kegagalan. Periksa apakah kode percobaan kembali tidak terlalu memengaruhi performa atau keandalan aplikasi, menyebabkan beban berlebihan pada layanan dan sumber daya, atau menghasilkan kondisi percepatan atau penyempitan.
Terapkan logika percobaan kembali hanya jika konteks lengkap dari operasi yang gagal dipahami. Misalnya, jika tugas yang berisi kebijakan percobaan kembali memanggil tugas lain yang juga berisi kebijakan percobaan kembali, lapisan percobaan kembali tambahan ini dapat menambahkan penundaan yang lama pada pemrosesan. Mungkin lebih baik untuk mengonfigurasi tugas tingkat yang lebih rendah agar gagal dengan cepat dan melaporkan alasan kegagalan kembali ke tugas yang memanggilnya. Tugas tingkat yang lebih tinggi ini kemudian dapat menangani kegagalan berdasarkan kebijakannya sendiri.
Penting untuk mencatat semua kegagalan konektivitas yang menyebabkan percobaan kembali sehingga masalah mendasar dengan aplikasi, layanan, atau sumber daya dapat diidentifikasi.
Selidiki kesalahan yang paling mungkin terjadi untuk layanan atau sumber daya guna mengetahui apakah kesalahan tersebut cenderung lama atau sementara. Jika benar demikian, lebih baik untuk menangani kesalahan sebagai pengecualian. Aplikasi dapat melaporkan atau mencatat pengecualian, dan kemudian mencoba melanjutkan dengan memanggil layanan alternatif (jika tersedia), atau dengan menawarkan fungsionalitas yang diturunkan. Untuk informasi selengkapnya tentang cara mendeteksi dan menangani kesalahan jangka panjang, lihat pola Pemutus Sirkuit.
Kapan menggunakan pola ini
Gunakan pola ini ketika aplikasi dapat mengalami kesalahan sementara saat berinteraksi dengan layanan jarak jauh atau mengakses sumber daya jarak jauh. Kesalahan ini diharapkan bersifat sebentar, dan mengulangi permintaan yang sebelumnya gagal dapat berhasil pada upaya berikutnya.
Pola ini mungkin tidak berguna:
- Jika kesalahan kemungkinan akan berlangsung lama, karena hal ini dapat mempengaruhi kecepatan respons aplikasi. Aplikasi mungkin membuang-buang waktu dan sumber daya untuk mencoba mengulangi permintaan yang kemungkinan besar akan gagal.
- Untuk menangani kegagalan yang bukan karena kesalahan sementara, seperti pengecualian internal yang disebabkan oleh kesalahan dalam logika bisnis aplikasi.
- Sebagai alternatif untuk mengatasi masalah skalabilitas dalam sistem. Jika aplikasi sering mengalami kesalahan sibuk, biasanya merupakan tanda bahwa layanan atau sumber daya yang diakses harus ditingkatkan.
Desain beban kerja
Arsitek harus mengevaluasi bagaimana pola Coba Lagi dapat digunakan dalam desain beban kerja mereka untuk mengatasi tujuan dan prinsip yang tercakup dalam pilar Azure Well-Architected Framework. Contohnya:
| Pilar | Bagaimana pola ini mendukung tujuan pilar |
|---|---|
| Keputusan desain keandalan membantu beban kerja Anda menjadi tahan terhadap kerusakan dan untuk memastikan bahwa keputusan tersebut pulih ke status berfungsi penuh setelah kegagalan terjadi. | Mengurangi kesalahan sementara dalam sistem terdistribusi adalah teknik inti untuk meningkatkan ketahanan beban kerja. - RE:07 Pelestarian Mandiri - KESALAHAN SEMENTARA RE:07 |
Seperti halnya keputusan desain apa pun, pertimbangkan tradeoff terhadap tujuan pilar lain yang mungkin diperkenalkan dengan pola ini.
Contoh
Contoh dalam C# ini menggambarkan penerapan pola Percobaan Kembali. Metode OperationWithBasicRetryAsync, yang ditampilkan di bawah, memanggil layanan eksternal secara asinkron melalui metode TransientOperationAsync. Detail metode TransientOperationAsync akan khusus untuk layanan dan dihilangkan dari kode contoh.
private int retryCount = 3;
private readonly TimeSpan delay = TimeSpan.FromSeconds(5);
public async Task OperationWithBasicRetryAsync()
{
int currentRetry = 0;
for (;;)
{
try
{
// Call external service.
await TransientOperationAsync();
// Return or break.
break;
}
catch (Exception ex)
{
Trace.TraceError("Operation Exception");
currentRetry++;
// Check if the exception thrown was a transient exception
// based on the logic in the error detection strategy.
// Determine whether to retry the operation, as well as how
// long to wait, based on the retry strategy.
if (currentRetry > this.retryCount || !IsTransient(ex))
{
// If this isn't a transient error or we shouldn't retry,
// rethrow the exception.
throw;
}
}
// Wait to retry the operation.
// Consider calculating an exponential delay here and
// using a strategy best suited for the operation and fault.
await Task.Delay(delay);
}
}
// Async method that wraps a call to a remote service (details not shown).
private async Task TransientOperationAsync()
{
...
}
Pernyataan yang memanggil metode ini dimuat dalam blok try/catch yang dibungkus dengan perulangan for. Perulangan for keluar jika panggilan ke metode TransientOperationAsync berhasil tanpa mengeluarkan pengecualian. Jika metode TransientOperationAsync gagal, blok catch akan memeriksa alasan kegagalan tersebut. Jika diyakini sebagai kesalahan sementara, kode menunggu beberapa saat sebelum mencoba kembali operasi.
Perulangan for juga melacak berapa kali operasi yang telah dilakukan, dan jika kode gagal tiga kali, pengecualian dianggap lebih lama. Jika pengecualian tidak sementara atau lama, penangan catch mengeluarkan pengecualian. Pengecualian ini keluar dari perulangan for dan harus ditangkap oleh kode yang memanggil metode OperationWithBasicRetryAsync.
Metode IsTransient, yang ditampilkan di bawah, memeriksa sekumpulan pengecualian tertentu yang relevan dengan lingkungan tempat kode dijalankan. Definisi pengecualian sementara akan bervariasi sesuai dengan sumber daya yang diakses dan lingkungan tempat operasi dilakukan.
private bool IsTransient(Exception ex)
{
// Determine if the exception is transient.
// In some cases this is as simple as checking the exception type, in other
// cases it might be necessary to inspect other properties of the exception.
if (ex is OperationTransientException)
return true;
var webException = ex as WebException;
if (webException != null)
{
// If the web exception contains one of the following status values
// it might be transient.
return new[] {WebExceptionStatus.ConnectionClosed,
WebExceptionStatus.Timeout,
WebExceptionStatus.RequestCanceled }.
Contains(webException.Status);
}
// Additional exception checking logic goes here.
return false;
}
Langkah berikutnya
Sebelum menulis logika percobaan kembali kustom, pertimbangkan untuk menggunakan kerangka kerja umum seperti Polly untuk .NET atau Resilience4j untuk Java.
Saat memproses perintah yang mengubah data bisnis, perlu diketahui bahwa percobaan kembali dapat mengakibatkan tindakan dilakukan dua kali, yang dapat menimbulkan masalah jika tindakan tersebut seperti menagih kartu kredit pelanggan. Menggunakan pola Idempoten yang dijelaskan dalam posting blog ini dapat membantu mengatasi situasi ini.
Sumber daya terkait
Pola aplikasi web yang andal menunjukkan kepada Anda cara menerapkan pola coba lagi ke aplikasi web yang berkonvergsi di cloud.
Untuk sebagian besar layanan Azure, SDK klien menyertakan logika percobaan kembali bawaan. Untuk informasi selengkapnya, lihat Panduan percobaan ulang untuk layanan Azure.
Pola Pemutus Sirkuit. Jika kegagalan diperkirakan lebih lama, mungkin lebih tepat untuk menerapkan pola Pemutus Sirkuit. Menggabungkan pola Percobaan Kembali dan Pemutus Sirkuit memberikan pendekatan komprehensif untuk menangani kesalahan.