Tutorial: Melakukan pencarian kesamaan vektor pada penyematan Azure OpenAI menggunakan Azure Cache for Redis
Dalam tutorial ini, Anda akan menelusuri kasus penggunaan pencarian kesamaan vektor dasar. Anda akan menggunakan penyematan yang dihasilkan oleh Azure OpenAI Service dan kemampuan pencarian vektor bawaan tingkat Enterprise Azure Cache for Redis untuk mengkueri himpunan data film untuk menemukan kecocokan yang paling relevan.
Tutorial ini menggunakan himpunan data Wikipedia Movie Plots yang menampilkan deskripsi plot lebih dari 35.000 film dari Wikipedia yang mencakup tahun 1901 hingga 2017. Himpunan data mencakup ringkasan plot untuk setiap film, ditambah metadata seperti tahun film dirilis, sutradara, pemeran utama, dan genre. Anda akan mengikuti langkah-langkah tutorial untuk menghasilkan penyematan berdasarkan ringkasan plot dan menggunakan metadata lain untuk menjalankan kueri hibrid.
Dalam tutorial ini, Anda akan mempelajari cara:
- Membuat instans Azure Cache for Redis yang dikonfigurasi untuk pencarian vektor
- Instal Azure OpenAI dan pustaka Python lain yang diperlukan.
- Unduh himpunan data film dan siapkan untuk analisis.
- Gunakan model text-embedding-ada-002 (Versi 2) untuk menghasilkan penyematan.
- Membuat indeks vektor di Azure Cache for Redis
- Gunakan kesamaan kosinus untuk memberi peringkat hasil pencarian.
- Gunakan fungsionalitas kueri hibrid melalui RediSearch untuk melakukan prafilter data dan membuat pencarian vektor lebih kuat.
Penting
Tutorial ini akan memandu Anda membangun Jupyter Notebook. Anda dapat mengikuti tutorial ini dengan file kode Python (.py) dan mendapatkan hasil yang sama , tetapi Anda harus menambahkan semua blok kode dalam tutorial ini ke dalam .py file dan menjalankan sekali untuk melihat hasil. Dengan kata lain, Jupyter Notebooks memberikan hasil menengah saat Anda menjalankan sel, tetapi ini bukan perilaku yang harus Anda harapkan saat bekerja dalam file kode Python.
Penting
Jika Anda ingin mengikuti di buku catatan Jupyter yang telah selesai, unduh file notebook Jupyter bernama tutorial.ipynb dan simpan ke folder redis-vector baru.
Prasyarat
- Langganan Azure - buat langganan gratis
- Akses yang diberikan ke Azure OpenAI dalam langganan Azure yang diinginkan Saat ini, Anda harus mengajukan permohonan akses ke Azure OpenAI. Anda dapat mengajukan permohonan akses ke Azure OpenAI dengan melengkapi formulir di https://aka.ms/oai/access.
- Python 3.7.1 atau versi lebih baru
- Jupyter Notebooks (opsional)
- Sumber daya Azure OpenAI dengan model text-embedding-ada-002 (Versi 2) disebarkan. Model ini saat ini hanya tersedia di wilayah tertentu. Lihat panduan penyebaran sumber daya untuk instruksi tentang cara menyebarkan model.
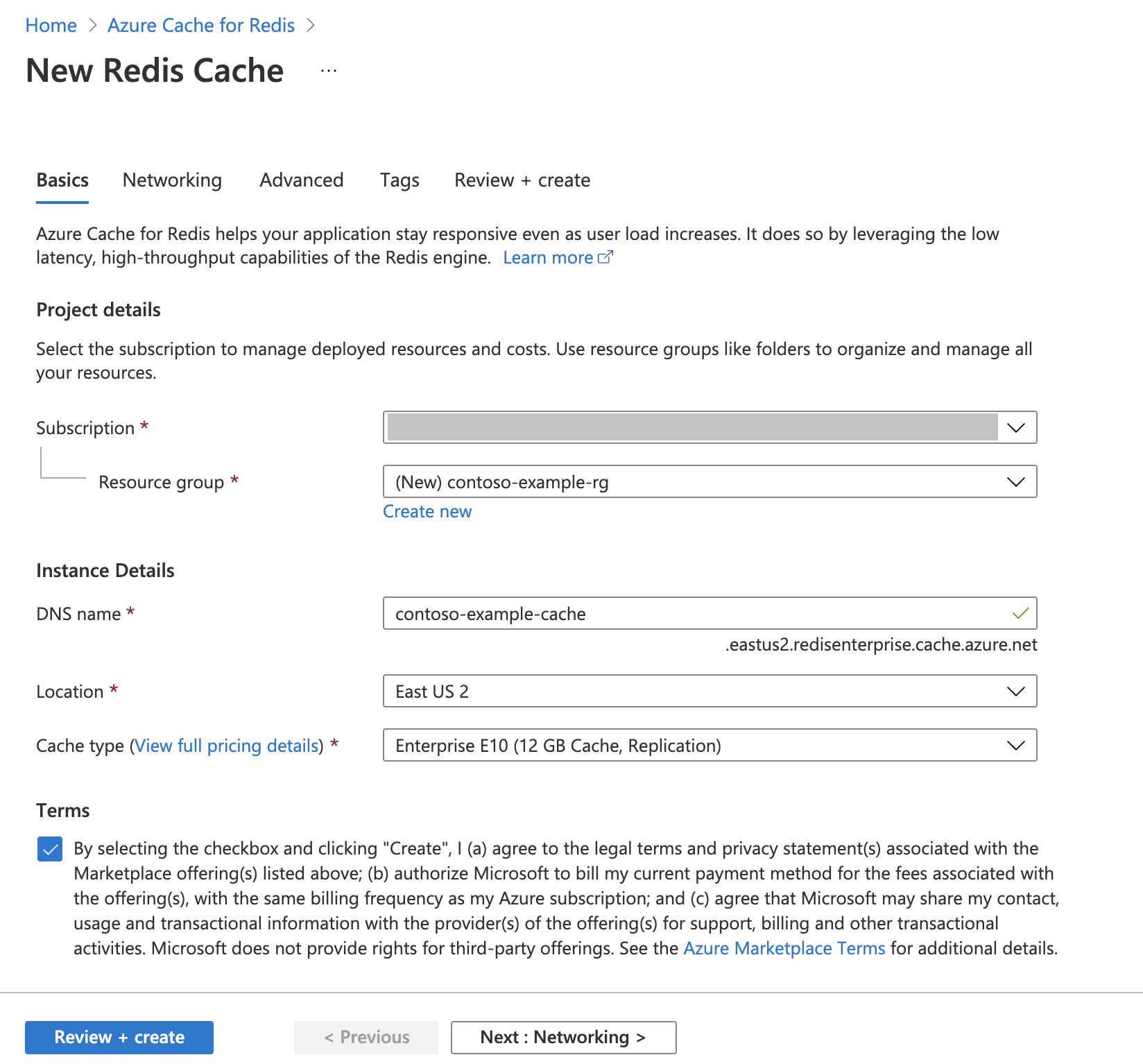
Membuat Instans Azure Cache for Redis
Ikuti panduan Mulai Cepat: Membuat cache Redis Enterprise. Pada halaman Tingkat Lanjut , pastikan Anda telah menambahkan modul RediSearch dan telah memilih Kebijakan Kluster Perusahaan . Semua pengaturan lain dapat cocok dengan default yang dijelaskan dalam mulai cepat.
Dibutuhkan beberapa menit agar cache dibuat. Anda dapat melanjutkan ke langkah berikutnya sementara itu.
Menyiapkan lingkungan pengembangan Anda
Buat folder di komputer lokal Anda bernama redis-vector di lokasi tempat Anda biasanya menyimpan proyek.
Buat file python baru (tutorial.py) atau jupyter notebook (tutorial.ipynb) di folder .
Instal paket Python yang diperlukan:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Mengunduh himpunan data
Di browser web, arahkan ke https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Masuk atau daftar dengan Kaggle. Pendaftaran diperlukan untuk mengunduh file.
Pilih tautan Unduh di Kaggle untuk mengunduh file archive.zip.
Ekstrak file archive.zip dan pindahkan wiki_movie_plots_deduped.csv ke folder redis-vector.
Mengimpor pustaka dan menyiapkan informasi koneksi
Agar berhasil melakukan panggilan terhadap Azure OpenAI, Anda memerlukan titik akhir dan kunci. Anda juga memerlukan titik akhir dan kunci untuk menyambungkan ke Azure Cache for Redis.
Buka sumber daya Azure OpenAI Anda di portal Azure.
Temukan Titik Akhir dan Kunci di bagian Manajemen Sumber Daya. Salin titik akhir dan kunci akses Anda karena keduanya diperlukan untuk mengautentikasi panggilan API Anda. Contoh titik akhir adalah:
https://docs-test-001.openai.azure.com. Anda dapat menggunakanKEY1atauKEY2.Buka halaman Gambaran Umum sumber daya Azure Cache for Redis Anda di portal Azure. Salin titik akhir Anda.
Temukan Kunci akses di bagian Pengaturan . Salin kunci akses Anda. Anda dapat menggunakan
PrimaryatauSecondary.Tambahkan kode berikut ke sel kode baru:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Perbarui nilai
API_KEYdanRESOURCE_ENDPOINTdengan nilai kunci dan titik akhir dari penyebaran Azure OpenAI Anda.DEPLOYMENT_NAMEharus diatur ke nama penyebaran Anda menggunakantext-embedding-ada-002 (Version 2)model penyematan, danMODEL_NAMEharus menjadi model penyematan tertentu yang digunakan.Perbarui
REDIS_ENDPOINTdanREDIS_PASSWORDdengan titik akhir dan nilai kunci dari instans Azure Cache for Redis Anda.Penting
Sebaiknya gunakan variabel lingkungan atau manajer rahasia seperti Azure Key Vault untuk meneruskan informasi kunci API, titik akhir, dan nama penyebaran. Variabel-variabel ini diatur dalam teks biasa di sini demi kesederhanaan.
Jalankan sel kode 2.
Mengimpor himpunan data ke panda dan memproses data
Selanjutnya, Anda akan membaca file csv ke dalam DataFrame pandas.
Tambahkan kode berikut ke sel kode baru:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfJalankan sel kode 3. Anda akan menemukan output berikut:

Selanjutnya, proses data dengan menambahkan indeks, menghapus spasi dari judul kolom, dan memfilter film untuk hanya mengambil film yang
iddibuat setelah 1970 dan dari negara berbahasa Inggris. Langkah pemfilteran ini mengurangi jumlah film dalam himpunan data, yang menurunkan biaya dan waktu yang diperlukan untuk menghasilkan penyematan. Anda bebas mengubah atau menghapus parameter filter berdasarkan preferensi Anda.Untuk memfilter data, tambahkan kode berikut ke sel kode baru:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfJalankan sel kode 4. Anda akan melihat hasil berikut ini:

Buat fungsi untuk membersihkan data dengan menghapus spasi kosong dan tanda baca, lalu gunakan terhadap kerangka data yang berisi plot.
Tambahkan kode berikut ke sel kode baru dan jalankan:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Terakhir, hapus entri apa pun yang berisi deskripsi plot yang terlalu panjang untuk model penyematan. (Dengan kata lain, token memerlukan lebih banyak token daripada batas token 8192.) lalu hitung jumlah token yang diperlukan untuk menghasilkan penyematan. Ini juga berdampak pada harga untuk pembuatan penyematan.
Tambahkan kode berikut ke sel kode baru:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Jalankan sel kode 6. Anda akan melihat output berikut:
Number of movies: 11125 Number of tokens required:7044844Penting
Lihat harga Azure OpenAI Service untuk menghitung biaya pembuatan penyematan berdasarkan jumlah token yang diperlukan.


Memuat DataFrame ke LangChain
Muat DataFrame ke LangChain menggunakan DataFrameLoader kelas . Setelah data berada dalam dokumen LangChain, jauh lebih mudah untuk menggunakan pustaka LangChain untuk menghasilkan penyematan dan melakukan pencarian kesamaan. Atur page_content_column Plot sebagai sehingga penyematan dihasilkan pada kolom ini.
Tambahkan kode berikut ke sel kode baru dan jalankan:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Hasilkan penyematan dan muat ke Redis
Sekarang setelah data difilter dan dimuat ke LangChain, Anda akan membuat penyematan sehingga Anda dapat mengkueri plot untuk setiap film. Kode berikut mengonfigurasi Azure OpenAI, menghasilkan penyematan, dan memuat vektor penyematan ke Azure Cache for Redis.
Tambahkan kode berikut sel kode baru:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Jalankan sel kode 8. Proses ini dapat memakan waktu lebih dari 30 menit untuk diselesaikan. File
redis_schema.yamljuga dihasilkan. File ini berguna jika Anda ingin menyambungkan ke indeks Anda di instans Azure Cache for Redis tanpa membuat ulang penyematan.
Penting
Kecepatan di mana penyematan dihasilkan tergantung pada kuota yang tersedia untuk Model Azure OpenAI. Dengan kuota token 240k per menit, dibutuhkan waktu sekitar 30 menit untuk memproses token 7M dalam himpunan data.
Menjalankan kueri pencarian vektor
Sekarang setelah himpunan data Anda, API layanan Azure OpenAI, dan instans Redis disiapkan, Anda dapat mencari menggunakan vektor. Dalam contoh ini, 10 hasil teratas untuk kueri tertentu dikembalikan.
Tambahkan kode berikut ke file kode Python Anda:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Jalankan sel kode 9. Anda akan menemukan output berikut:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Skor kesamaan dikembalikan bersama dengan peringkat ordinal film berdasarkan kesamaan. Perhatikan bahwa kueri yang lebih spesifik memiliki skor kesamaan menurun lebih cepat ke daftar.
Pencarian hibrid
Karena RediSearch juga menampilkan fungsionalitas pencarian yang kaya di atas pencarian vektor, dimungkinkan untuk memfilter hasil berdasarkan metadata dalam himpunan data, seperti genre film, pemeran, tahun rilis, atau sutradara. Dalam hal ini, filter berdasarkan genre
comedy.Tambahkan kode berikut ke sel kode baru:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Jalankan sel kode 10. Anda akan menemukan output berikut:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Dengan Azure Cache for Redis dan Azure OpenAI Service, Anda dapat menggunakan penyematan dan pencarian vektor untuk menambahkan kemampuan pencarian yang canggih ke aplikasi Anda.
Membersihkan sumber daya
Jika Anda ingin terus menggunakan sumber daya yang Anda buat di artikel ini, simpan grup sumber daya.
Jika tidak, untuk menghindari biaya yang terkait dengan sumber daya, jika Anda selesai menggunakan sumber daya, Anda dapat menghapus grup sumber daya Azure yang Anda buat.
Peringatan
Penghapusan grup sumber daya tidak bisa dipulihkan. Saat Anda menghapus grup sumber daya, semua sumber daya dalam grup sumber daya akan dihapus secara permanen. Pastikan Anda tidak salah menghapus grup sumber daya atau sumber daya secara tidak sengaja. Jika Anda membuat sumber daya di dalam grup sumber daya yang sudah ada yang memiliki sumber daya yang ingin Anda simpan, Anda dapat menghapus setiap sumber daya satu per satu alih-alih menghapus grup sumber daya.
Menghapus grup sumber daya
Masuk ke portal Azure, lalu pilih Grup sumber daya.
Pilih grup sumber daya yang akan dihapus.
Jika ada banyak grup sumber daya, di Filter untuk bidang apa pun, masukkan nama grup sumber daya yang Anda buat untuk menyelesaikan artikel ini. Dalam daftar hasil pencarian, pilih grup sumber daya.
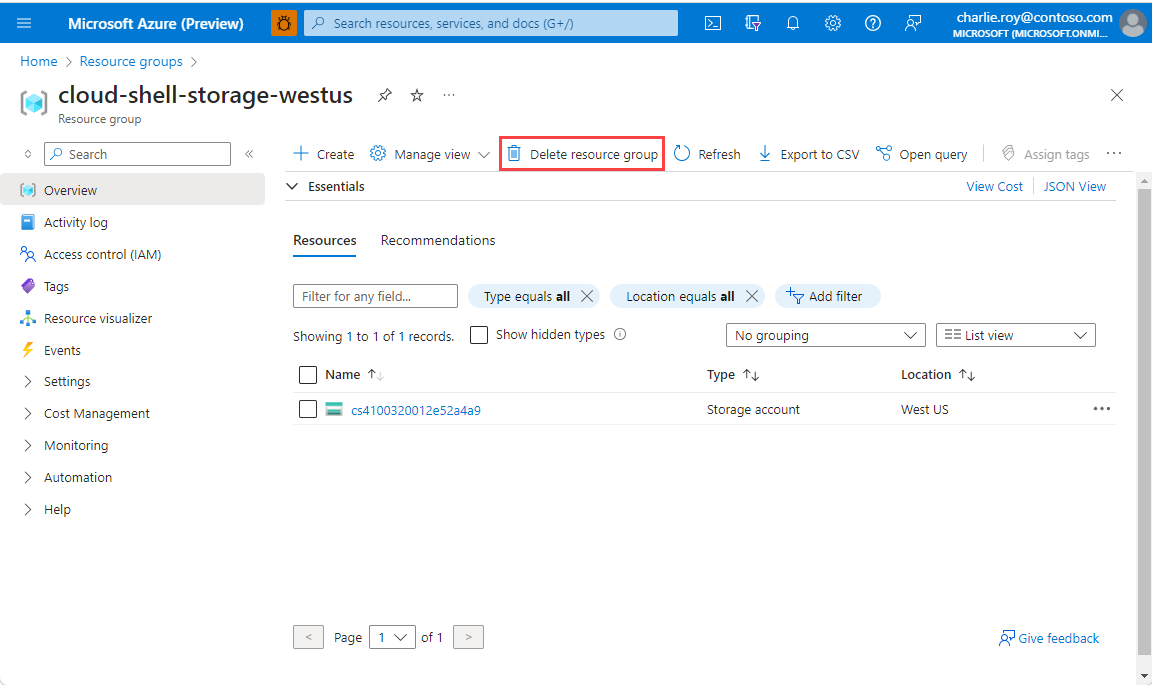
Pilih Hapus grup sumber daya.
Di panel Hapus grup sumber daya, masukkan nama grup sumber daya Anda untuk mengonfirmasi, lalu pilih Hapus.
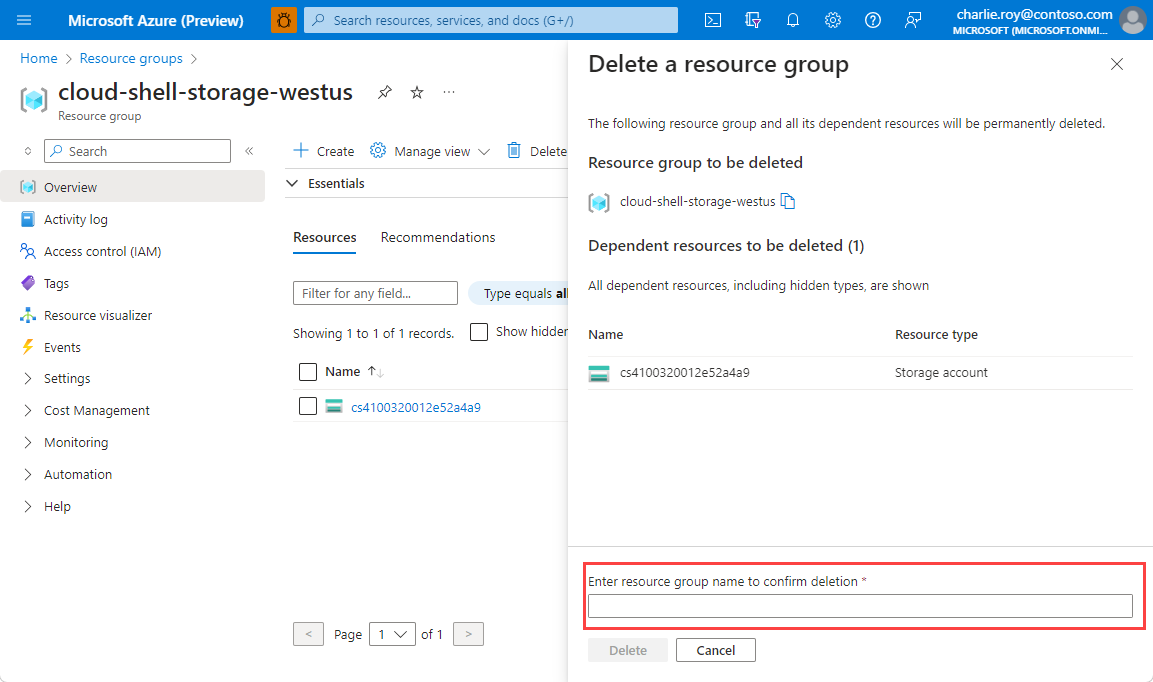
Dalam beberapa saat, grup sumber daya dan semua sumber dayanya dihapus.
Konten Terkait
- Pelajari selengkapnya tentang Azure Cache for Redis
- Pelajari selengkapnya tentang kemampuan pencarian vektor Azure Cache for Redis
- Pelajari selengkapnya tentang penyematan yang dihasilkan oleh Azure OpenAI Service
- Pelajari selengkapnya tentang kesamaan kosinus
- Baca cara membuat aplikasi bertenaga AI dengan OpenAI dan Redis
- Membangun aplikasi Tanya Jawab umum dengan jawaban semantik