Aturan pemberitahuan yang direkomendasikan untuk kluster Kubernetes
Pemberitahuan di Azure Monitor secara proaktif mengidentifikasi masalah yang terkait dengan kesehatan dan performa sumber daya Azure Anda. Artikel ini menjelaskan cara mengaktifkan dan mengedit sekumpulan aturan pemberitahuan metrik yang direkomendasikan yang telah ditentukan sebelumnya untuk kluster Kubernetes Anda.
Jenis aturan pemberitahuan
Ada dua jenis aturan pemberitahuan metrik yang digunakan dengan kluster Kubernetes.
| Jenis aturan pemberitahuan | Deskripsi |
|---|---|
| Aturan pemberitahuan metrik Prometheus | Gunakan data metrik yang dikumpulkan dari kluster Kubernetes Anda dalam layanan terkelola Azure Monitor untuk Prometheus. Aturan ini mengharuskan Prometheus diaktifkan pada kluster Anda dan disimpan dalam grup aturan Prometheus. |
| Aturan pemberitahuan metrik platform | Gunakan metrik yang dikumpulkan secara otomatis dari kluster AKS Anda dan disimpan sebagai aturan pemberitahuan Azure Monitor. |
Mengaktifkan aturan pemberitahuan yang disarankan
Gunakan salah satu metode berikut untuk mengaktifkan aturan pemberitahuan yang direkomendasikan untuk kluster Anda. Anda dapat mengaktifkan aturan pemberitahuan metrik Prometheus dan platform untuk kluster yang sama.
Catatan
Untuk mengaktifkan pemberitahuan yang direkomendasikan pada kluster Kubernetes dengan dukungan Arc, templat ARM adalah satu-satunya metode yang didukung.
Dengan menggunakan portal Azure, grup aturan Prometheus akan dibuat di wilayah yang sama dengan kluster.
Dari menu Pemberitahuan untuk kluster Anda, pilih Siapkan rekomendasi.
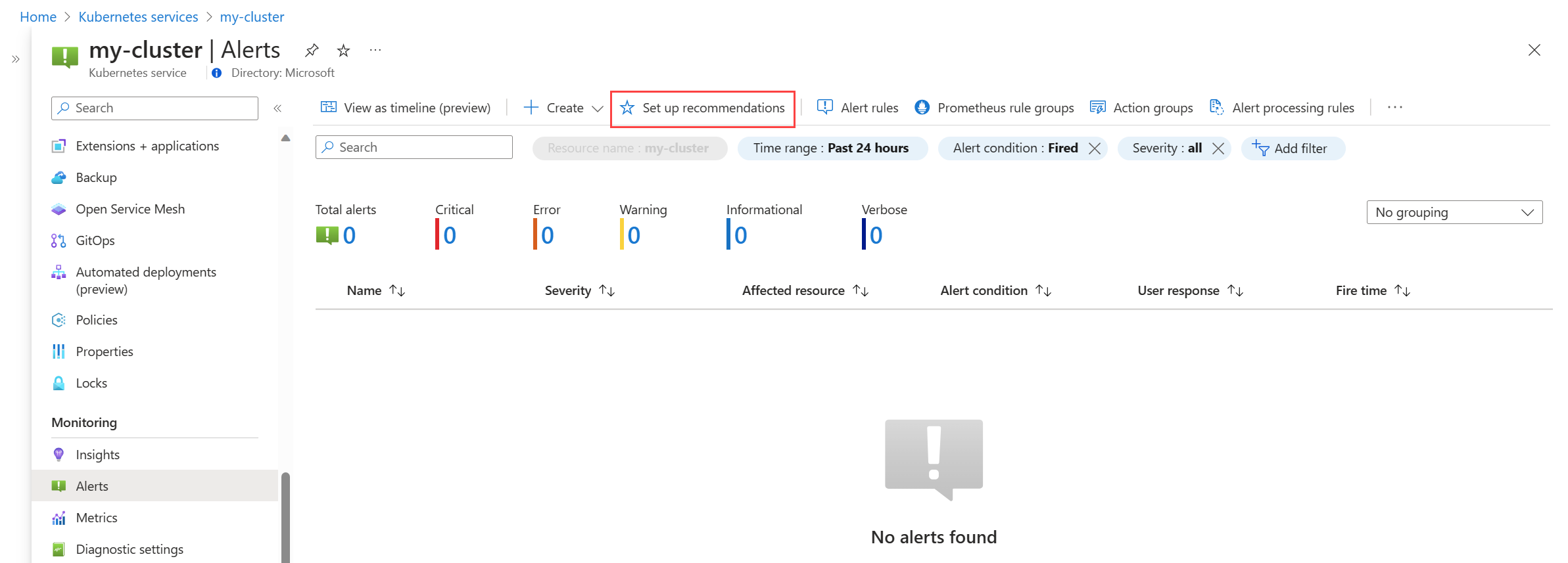
Aturan pemberitahuan Prometheus dan platform yang tersedia ditampilkan dengan aturan Prometheus yang diatur oleh tingkat pod, kluster, dan node. Alihkan sekelompok aturan Prometheus untuk mengaktifkan sekumpulan aturan tersebut. Perluas grup untuk melihat aturan individual. Anda dapat membiarkan default atau menonaktifkan aturan individual dan mengedit nama dan tingkat keparahannya.
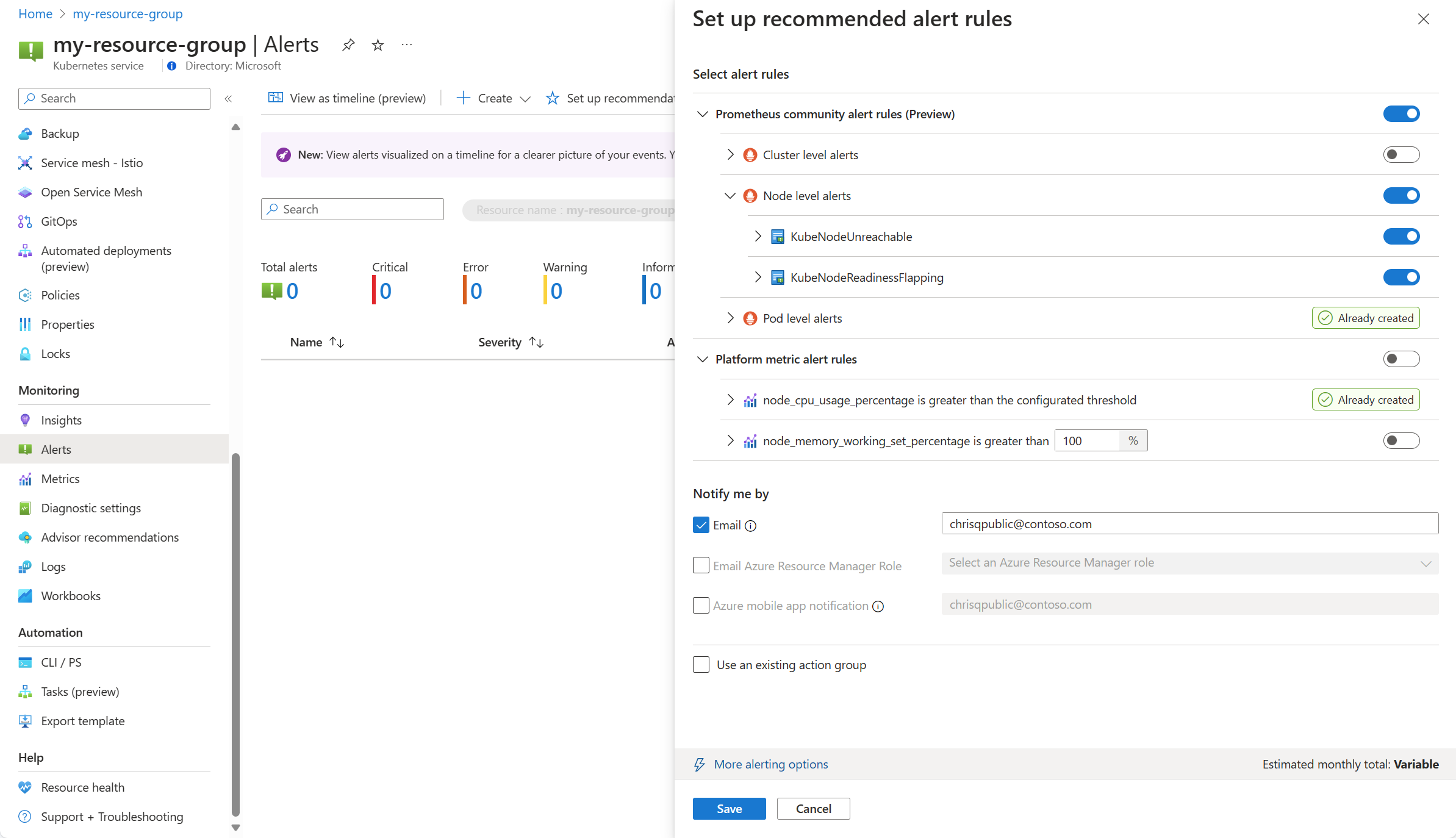
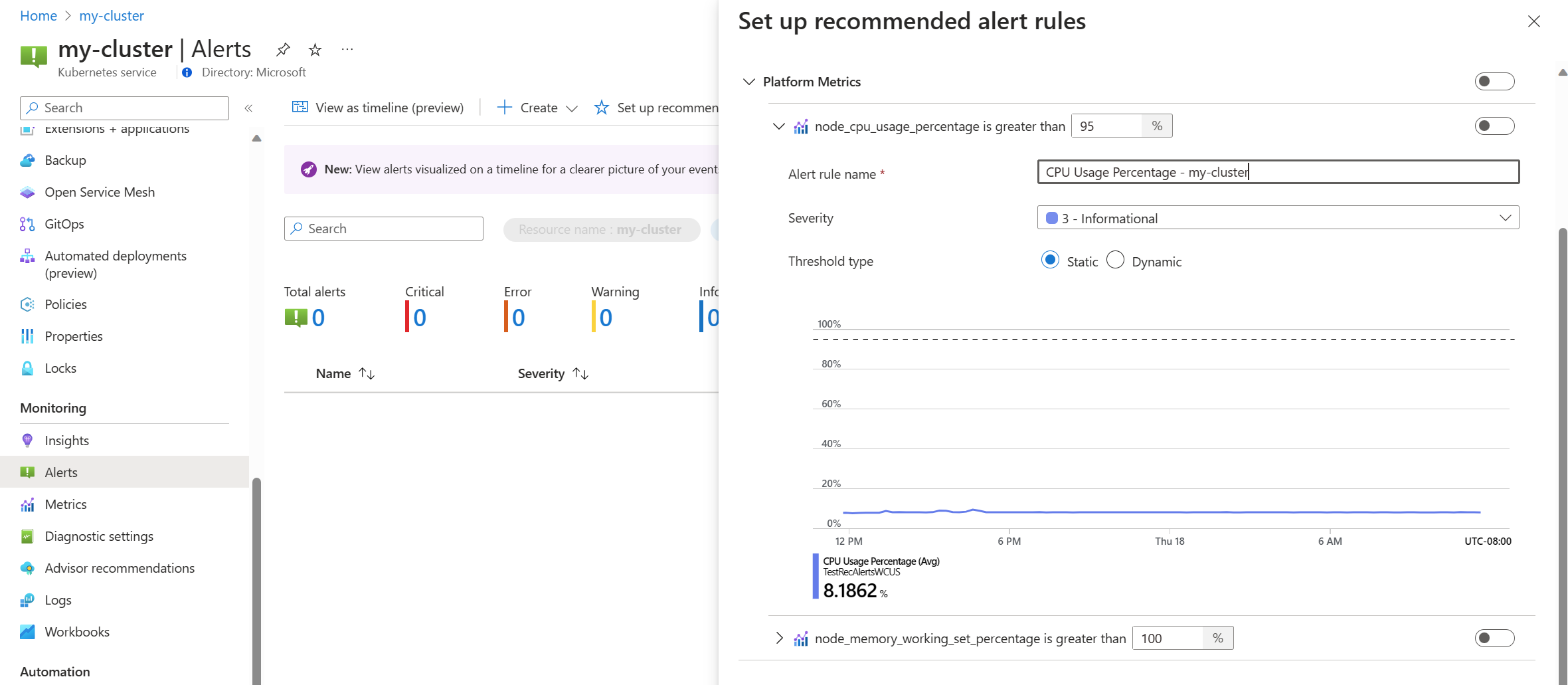
Alihkan aturan metrik platform untuk mengaktifkan aturan tersebut. Anda dapat memperluas aturan untuk mengubah detailnya seperti nama, tingkat keparahan, dan ambang batas.
Pilih satu atau beberapa metode pemberitahuan untuk membuat grup tindakan baru, atau pilih grup tindakan yang sudah ada dengan detail pemberitahuan untuk sekumpulan aturan pemberitahuan ini.
Klik Simpan untuk menyimpan grup aturan.



Mengedit aturan pemberitahuan yang direkomendasikan
Setelah grup aturan dibuat, Anda tidak dapat menggunakan halaman yang sama di portal untuk mengedit aturan. Untuk metrik Prometheus, Anda harus mengedit grup aturan untuk mengubah aturan apa pun di dalamnya, termasuk mengaktifkan aturan apa pun yang belum diaktifkan. Untuk metrik platform, Anda dapat mengedit setiap aturan pemberitahuan.
Dari menu Pemberitahuan untuk kluster Anda, pilih Siapkan rekomendasi. Aturan atau grup aturan apa pun yang telah dibuat akan diberi label sebagai Sudah dibuat.
Perluas aturan atau grup aturan. Klik Tampilkan grup aturan untuk Prometheus dan Lihat aturan pemberitahuan untuk metrik platform.
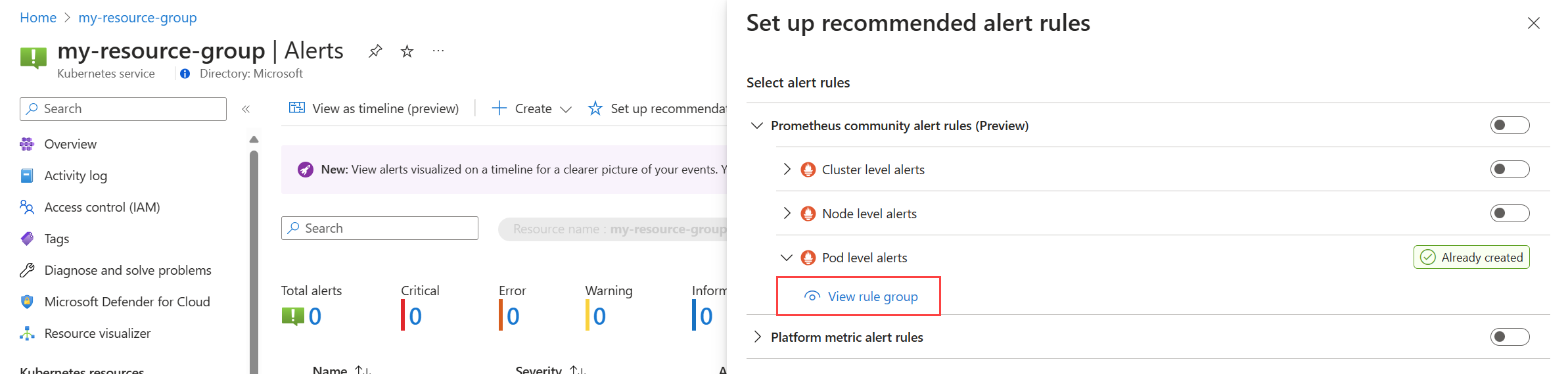
Untuk grup aturan Prometheus:
pilih Aturan untuk melihat aturan pemberitahuan dalam grup.
Klik ikon Edit di samping aturan yang ingin Anda ubah. Gunakan panduan dalam Membuat aturan pemberitahuan untuk mengubah aturan.
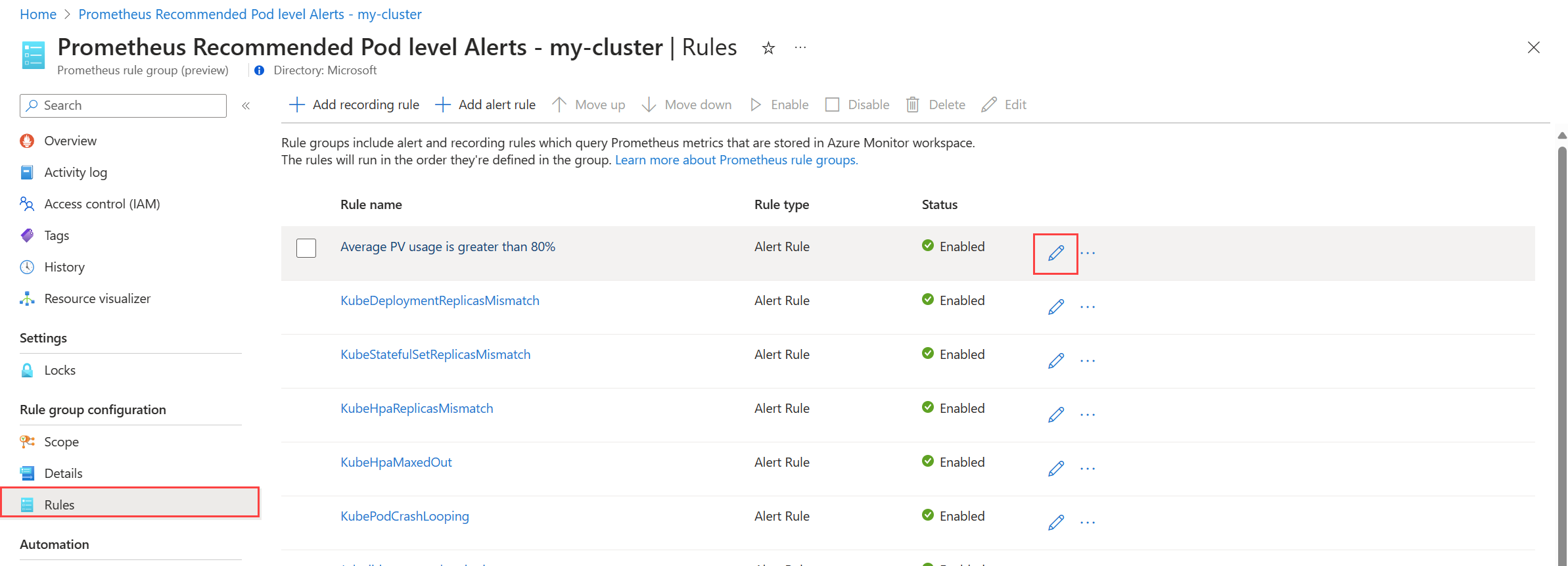
Setelah selesai mengedit aturan dalam grup, klik Simpan untuk menyimpan grup aturan.
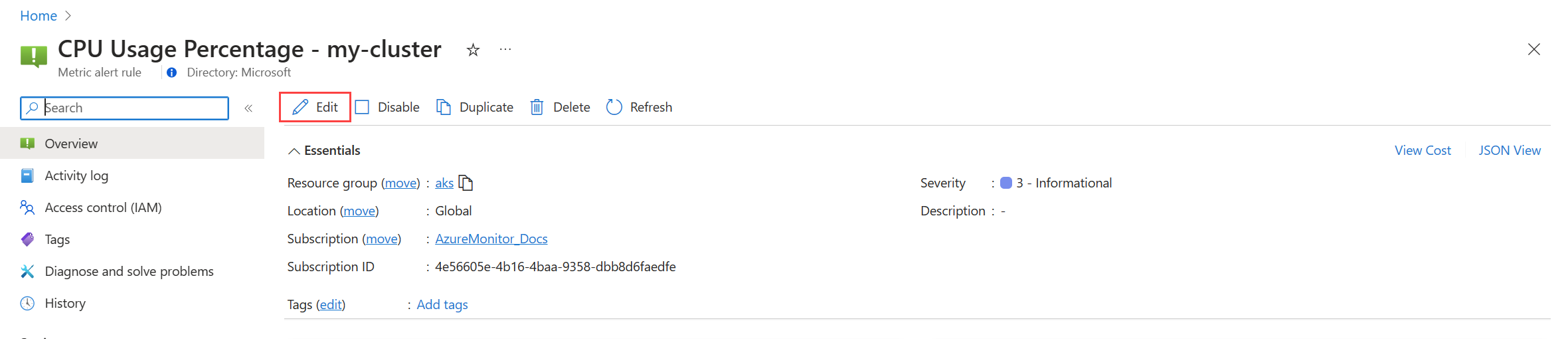
Untuk metrik platform:
klik Edit untuk membuka detail aturan pemberitahuan. Gunakan panduan dalam Membuat aturan pemberitahuan untuk mengubah aturan.



Menonaktifkan grup aturan pemberitahuan
Nonaktifkan grup aturan untuk berhenti menerima pemberitahuan dari aturan di dalamnya.
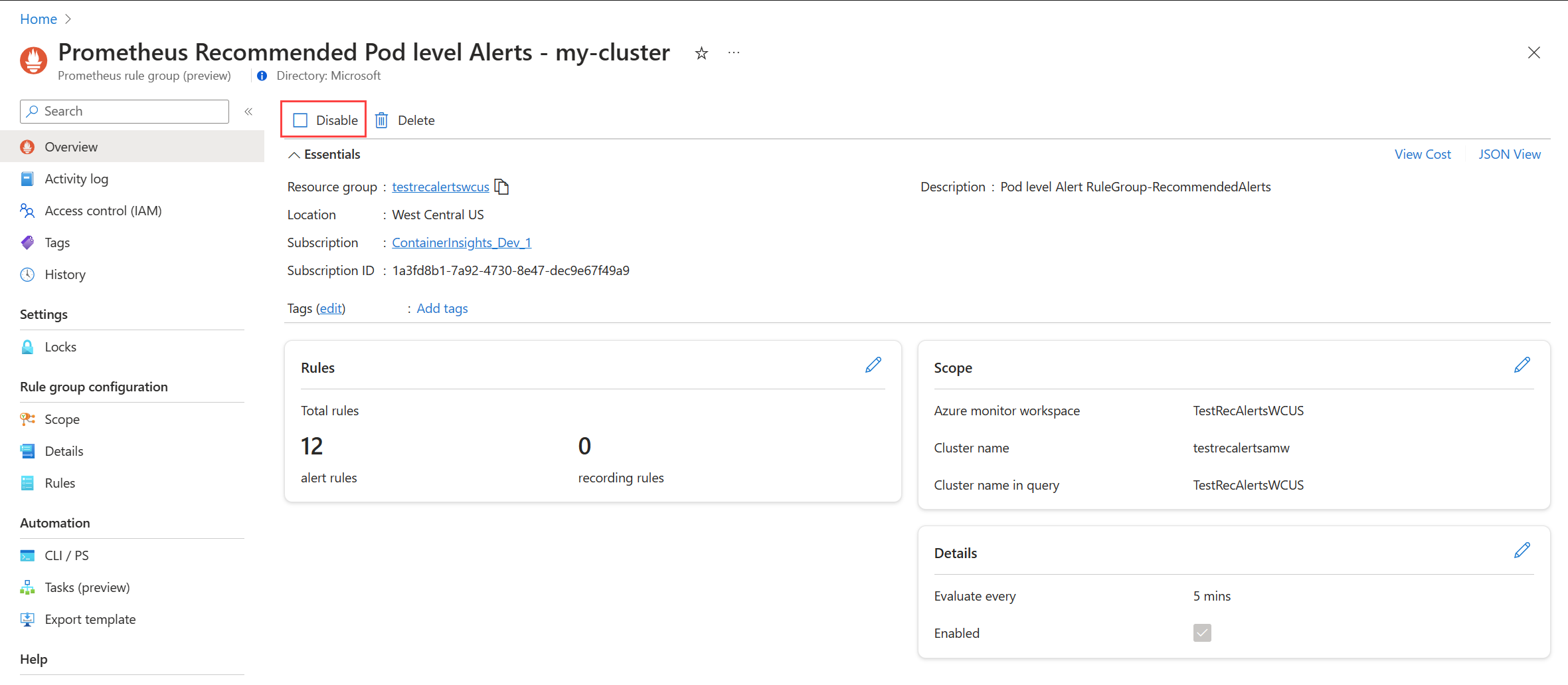
Lihat grup aturan pemberitahuan Prometheus atau aturan pemberitahuan metrik platform seperti yang dijelaskan dalam Edit aturan pemberitahuan yang direkomendasikan.
Dari menu Gambaran Umum , pilih Nonaktifkan.

Detail aturan pemberitahuan yang direkomendasikan
Tabel berikut ini mencantumkan detail setiap aturan pemberitahuan yang direkomendasikan. Kode sumber untuk masing-masing tersedia di GitHub bersama dengan panduan pemecahan masalah dari komunitas Prometheus.
Aturan pemberitahuan komunitas Prometheus
Pemberitahuan tingkat kluster
| Nama pemberitahuan | Deskripsi | Ambang batas default | Jangka waktu (menit) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | Kuota sumber daya CPU yang dialokasikan untuk namespace melebihi sumber daya CPU yang tersedia pada node kluster lebih dari 50% selama 5 menit terakhir. | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | Kuota sumber daya memori yang dialokasikan untuk namespace melebihi sumber daya memori yang tersedia pada node kluster lebih dari 50% selama 5 menit terakhir. | >1.5 | 5 |
| KubeContainerOOMKilledCount | Satu atau beberapa kontainer dalam pod telah dimatikan karena peristiwa di luar memori (OOM) selama 5 menit terakhir. | >0 | 5 |
| KubeClientErrors | Tingkat kesalahan klien (kode status HTTP yang dimulai dengan 5xx) dalam permintaan API Kubernetes melebihi 1% dari total tingkat permintaan API selama 15 menit terakhir. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Volume persisten terisi dan diharapkan kehabisan ruang yang tersedia yang dievaluasi pada rasio ruang yang tersedia, ruang yang digunakan, dan tren linier yang diprediksi dari ruang yang tersedia selama 6 jam terakhir. Kondisi ini dievaluasi selama 60 menit terakhir. | T/A | 60 |
| KubePersistentVolumeInodesFillingUp | Kurang dari 3% inode dalam volume persisten tersedia selama 15 menit terakhir. | <0.03 | 15 |
| KubePersistentVolumeErrors | Satu atau beberapa volume persisten berada dalam fase gagal atau tertunda selama 5 menit terakhir. | >0 | 5 |
| KubeContainerWaiting | Satu atau beberapa kontainer dalam pod Kubernetes berada dalam status tunggu selama 60 menit terakhir. | >0 | 60 |
| KubeDaemonSetNotScheduled | Satu atau beberapa pod tidak dijadwalkan pada simpul apa pun selama 15 menit terakhir. | >0 | 15 |
| KubeDaemonSetMisScheduled | Satu atau beberapa pod salah dijadwalkan dalam kluster selama 15 menit terakhir. | >0 | 15 |
| KubeQuotaAlmostFull | Pemanfaatan kuota sumber daya Kube adalah antara 90% dan 100% dari batas keras selama 15 menit terakhir. | >0,9 <1 | 15 |
Pemberitahuan tingkat simpul
| Nama pemberitahuan | Deskripsi | Ambang batas default | Jangka waktu (menit) |
|---|---|---|---|
| KubeNodeUnreachable | Simpul tidak dapat dijangkau selama 15 menit terakhir. | 1 | 15 |
| KubeNodeReadinessFlapping | Status kesiapan simpul telah berubah lebih dari 2 kali selama 15 menit terakhir. | 2 | 15 |
Pemberitahuan tingkat pod
| Nama pemberitahuan | Deskripsi | Ambang batas default | Jangka waktu (menit) |
|---|---|---|---|
| KubePVUsageHigh | Penggunaan rata-rata Volume Persisten (PV) pada pod melebihi 80% selama 15 menit terakhir. | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | Ada ketidakcocokan antara jumlah replika yang diinginkan dan jumlah replika yang tersedia selama 10 menit terakhir. | T/A | 10 |
| KubeStatefulSetReplicasMismatch | Jumlah replika siap di StatefulSet tidak cocok dengan jumlah total replika di StatefulSet selama 15 menit terakhir. | T/A | 15 |
| KubeHpaReplicasMismatch | Autoscaler Pod Horizontal dalam kluster belum cocok dengan jumlah replika yang diinginkan selama 15 menit terakhir. | T/A | 15 |
| KubeHpaMaxedOut | Horizontal Pod Autoscaler (HPA) dalam kluster telah berjalan pada replika maksimum selama 15 menit terakhir. | T/A | 15 |
| KubePodCrashLooping | Satu atau beberapa pod berada dalam kondisi CrashLoopBackOff, di mana pod terus crash setelah startup dan gagal pulih dengan sukses selama 15 menit terakhir. | >=1 | 15 |
| KubeJobStale | Setidaknya satu instans Pekerjaan tidak berhasil diselesaikan selama 6 jam terakhir. | >0 | 360 |
| KubePodContainerRestart | Satu atau beberapa kontainer dalam pod di kluster Kubernetes telah dimulai ulang setidaknya sekali dalam satu jam terakhir. | >0 | 15 |
| KubePodReadyStateLow | Persentase pod dalam status siap berada di bawah 80% untuk setiap penyebaran atau daemonset di kluster Kubernetes selama 5 menit terakhir. | <0.8 | 5 |
| KubePodFailedState | Satu atau beberapa pod dalam keadaan gagal selama 5 menit terakhir. | >0 | 5 |
| KubePodNotReadyByController | Satu atau beberapa pod tidak dalam keadaan siap (yaitu, dalam fase "Tertunda" atau "Tidak Diketahui")) selama 15 menit terakhir. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | Generasi yang diamati dari Kubernetes StatefulSet tidak cocok dengan pembuatan metadatanya selama 15 menit terakhir. | T/A | 15 |
| KubeJobFailed | Satu atau beberapa pekerjaan Kubernetes gagal dalam 15 menit terakhir. | >0 | 15 |
| KubeContainerAverageCPUHigh | Penggunaan CPU rata-rata per kontainer melebihi 95% selama 5 menit terakhir. | >0.95 | 5 |
| KubeContainerAverageMemoryHigh | Penggunaan memori rata-rata per kontainer melebihi 95% selama 5 menit terakhir. | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | Persentil ke-99 dari latensi startup pod melebihi 60 detik selama 10 menit terakhir. | >60 | 10 |
Aturan pemberitahuan metrik platform
| Nama pemberitahuan | Deskripsi | Ambang batas default | Jangka waktu (menit) |
|---|---|---|---|
| Persentase cpu node lebih besar dari 95% | Persentase CPU node lebih besar dari 95% selama 5 menit terakhir. | 95 | 5 |
| Persentase set kerja memori node lebih besar dari 100% | Persentase set kerja memori node lebih besar dari 100% selama 5 menit terakhir. | 100 | 5 |
Pemberitahuan metrik wawasan Kontainer Warisan (pratinjau)
Aturan metrik dalam wawasan Kontainer akan dihentikan pada 31 Mei 2024 (sebelumnya diumumkan sebagai 14 Maret 2026). Aturan ini belum tersedia untuk dibuat menggunakan portal sejak 15 Agustus 2023. Aturan ini berada dalam pratinjau publik tetapi akan dihentikan tanpa mencapai ketersediaan umum karena pemberitahuan metrik baru yang direkomendasikan yang dijelaskan dalam artikel ini sekarang tersedia.
Jika Anda sudah mengaktifkan aturan pemberitahuan warisan ini, Anda harus menonaktifkannya dan mengaktifkan pengalaman baru.
Menonaktifkan aturan pemberitahuan metrik
- Dari menu Insight untuk kluster Anda, pilih Pemberitahuan yang direkomendasikan (pratinjau).
- Ubah status untuk setiap aturan pemberitahuan menjadi Dinonaktifkan.
Pemetaan pemberitahuan warisan
Tabel berikut memetakan setiap pemberitahuan metrik wawasan Kontainer warisan ke pemberitahuan metrik Prometheus yang setara yang direkomendasikan.
| Pemberitahuan yang direkomendasikan metrik kustom | Pemberitahuan yang direkomendasikan metrik Prometheus/Platform yang setara | Kondisi |
|---|---|---|
| Jumlah pekerjaan yang selesai | KubeJobStale (Pemberitahuan tingkat Pod) | Setidaknya satu instans Pekerjaan tidak berhasil diselesaikan selama 6 jam terakhir. |
| CPU Kontainer % | KubeContainerAverageCPUHigh (Pemberitahuan tingkat Pod) | Penggunaan CPU rata-rata per kontainer melebihi 95% selama 5 menit terakhir. |
| Memori set kerja kontainer % | KubeContainerAverageMemoryHigh (Pemberitahuan tingkat Pod) | Penggunaan memori rata-rata per kontainer melebihi 95% selama 5 menit terakhir. |
| Jumlah Pod yang gagal | KubePodFailedState (Pemberitahuan tingkat pod) | Satu atau beberapa pod dalam keadaan gagal selama 5 menit terakhir. |
| CPU Simpul % | Persentase cpu node lebih besar dari 95% (Metrik platform) | Persentase CPU node lebih besar dari 95% selama 5 menit terakhir. |
| Penggunaan Disk Node % | T/A | Penggunaan disk rata-rata untuk simpul lebih besar dari 80%. |
| Status NotReady simpul | KubeNodeUnreachable (Pemberitahuan tingkat node) | Simpul tidak dapat dijangkau selama 15 menit terakhir. |
| Memori set kerja simpul % | Persentase set kerja memori node lebih besar dari 100% | Persentase set kerja memori node lebih besar dari 100% selama 5 menit terakhir. |
| Kontainer yang Diakhiri OOM | KubeContainerOOMKilledCount (Pemberitahuan tingkat kluster) | Satu atau beberapa kontainer dalam pod telah dimatikan karena peristiwa di luar memori (OOM) selama 5 menit terakhir. |
| Penggunaan Volume Persisten % | KubePVUsageHigh (Pemberitahuan tingkat Pod) | Penggunaan rata-rata Volume Persisten (PV) pada pod melebihi 80% selama 15 menit terakhir. |
| Pod siap % | KubePodReadyStateLow (Pemberitahuan tingkat Pod) | Persentase pod dalam status siap berada di bawah 80% untuk setiap penyebaran atau daemonset di kluster Kubernetes selama 5 menit terakhir. |
| Jumlah kontainer yang dimulai ulang | KubePodContainerRestart (Pemberitahuan tingkat Pod) | Satu atau beberapa kontainer dalam pod di kluster Kubernetes telah dimulai ulang setidaknya sekali dalam satu jam terakhir. |
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk