Memecahkan masalah pengumpulan metrik Prometheus di Azure Monitor
Ikuti langkah-langkah dalam artikel ini untuk menentukan penyebab metrik Prometheus tidak dikumpulkan seperti yang diharapkan di Azure Monitor.
Pod replika mengikis metrik dari kube-state-metrics, target scrape kustom dalam ama-metrics-prometheus-config target configmap dan scrape kustom yang ditentukan dalam Sumber Daya Kustom. Pod DaemonSet mengikis metrik dari target berikut pada node masing-masing: kubelet, , cAdvisornode-exporter, dan target scrape kustom dalam ama-metrics-prometheus-config-node configmap. Pod yang ingin Anda lihat log dan UI Prometheus untuk itu tergantung pada target scrape mana yang Anda selidiki.
Memecahkan masalah menggunakan skrip PowerShell
Jika Anda mengalami kesalahan saat mencoba mengaktifkan pemantauan untuk kluster AKS Anda, ikuti instruksi berikut untuk menjalankan skrip pemecahan masalah. Skrip ini dirancang untuk melakukan diagnosis dasar untuk masalah konfigurasi apa pun di kluster Anda dan Anda dapat melampirkan file yang dihasilkan sambil membuat permintaan dukungan untuk resolusi yang lebih cepat untuk kasus dukungan Anda.
Pembatasan Metrik
Layanan Terkelola Azure Monitor untuk Prometheus memiliki batas dan kuota default untuk penyerapan. Ketika Anda mencapai batas penyerapan, pembatasan dapat terjadi. Anda dapat meminta peningkatan batas ini. Untuk informasi tentang batas metrik Prometheus, lihat Batas layanan Azure Monitor.
Di portal Azure, navigasikan ke Ruang Kerja Azure Monitor Anda. MetricsBuka , dan pilih metrik Active Time Series % Utilization dan Events Per Minute Received % Utilization. Verifikasi bahwa keduanya di bawah 100%.
Untuk informasi selengkapnya tentang pemantauan dan pemberitahuan pada metrik penyerapan Anda, lihat Memantau penyerapan metrik ruang kerja Azure Monitor.
Celah terputus-terputus dalam pengumpulan data metrik
Selama pembaruan node, Anda mungkin melihat celah 1 hingga 2 menit dalam data metrik untuk metrik yang dikumpulkan dari pengumpul tingkat kluster kami. Kesenjangan ini karena simpul yang dijalankannya sedang diperbarui sebagai bagian dari proses pembaruan normal. Ini mempengaruhi target di seluruh kluster seperti kube-state-metrics dan target aplikasi kustom yang ditentukan. Ini terjadi ketika kluster Anda diperbarui secara manual atau melalui pembaruan otomatis. Perilaku ini diharapkan dan terjadi karena simpul yang dijalankannya saat diperbarui. Tidak ada aturan pemberitahuan yang direkomendasikan yang terpengaruh oleh perilaku ini.
Status Pod
Periksa status pod dengan perintah berikut:
kubectl get pods -n kube-system | grep ama-metrics
Ketika layanan berjalan dengan benar, daftar pod berikut dalam format ama-metrics-xxxxxxxxxx-xxxxx dikembalikan:
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*pod untuk setiap simpul pada kluster.
Setiap status pod harus Running dan memiliki jumlah restart yang sama dengan jumlah perubahan configmap yang telah diterapkan. Pod ama-metrics-operator-targets-* mungkin memiliki restart tambahan di awal dan ini diharapkan:

Jika setiap status pod hanyalah Running satu atau beberapa pod yang telah dimulai ulang, jalankan perintah berikut:
kubectl describe pod <ama-metrics pod name> -n kube-system
- Perintah ini memberikan alasan untuk menghidupkan ulang. Mulai ulang pod diharapkan jika perubahan configmap telah dilakukan. Jika alasan untuk menghidupkan ulang adalah
OOMKilled, pod tidak dapat mengikuti volume metrik. Lihat rekomendasi skala untuk volume metrik.
Jika pod berjalan seperti yang diharapkan, tempat berikutnya untuk memeriksa adalah log kontainer.
Periksa konfigurasi pelabelan ulang
Jika metrik hilang, Anda juga dapat memeriksa apakah Anda memiliki konfigurasi pelabelan ulang. Dengan konfigurasi pelabelan ulang, pastikan bahwa pelabelan ulang tidak memfilter target, dan label yang dikonfigurasi dengan benar cocok dengan target. Untuk informasi selengkapnya, lihat Dokumentasi konfigurasi relabel Prometheus.
Log kontainer
Lihat log kontainer dengan perintah berikut:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
Saat startup, kesalahan awal dicetak dengan warna merah, sementara peringatan dicetak dengan warna kuning. (Menampilkan log berwarna memerlukan setidaknya PowerShell versi 7 atau distribusi linux.)
- Verifikasi apakah ada masalah dengan mendapatkan token autentikasi:
- Pesan Tidak ada konfigurasi untuk sumber daya AKS yang dicatat setiap 5 menit.
- Pod dimulai ulang setiap 15 menit untuk mencoba lagi dengan kesalahan: Tidak ada konfigurasi untuk sumber daya AKS.
- Jika demikian, periksa apakah Aturan Pengumpulan Data dan Titik Akhir Pengumpulan Data ada di grup sumber daya Anda.
- Verifikasi juga bahwa Ruang Kerja Azure Monitor ada.
- Verifikasi bahwa Anda tidak memiliki kluster AKS privat dan tidak ditautkan ke Cakupan Azure Monitor Private Link untuk layanan lain. Skenario ini saat ini tidak didukung.
Pemrosesan Konfigurasi
Lihat log kontainer dengan perintah berikut:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Pastikan tidak ada kesalahan dengan mengurai konfigurasi Prometheus, menggabungkan dengan target scrape default yang diaktifkan, dan memvalidasi konfigurasi lengkap.
- Jika Anda menyertakan konfigurasi Prometheus kustom, verifikasi bahwa konfigurasi tersebut dikenali dalam log. Jika tidak:
- Verifikasi bahwa configmap Anda memiliki nama yang benar:
ama-metrics-prometheus-configdikube-systemnamespace. - Verifikasi bahwa dalam configmap konfigurasi Prometheus Anda berada di bawah bagian yang dipanggil
prometheus-configseperti yang ditunjukkandatadi sini:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- Verifikasi bahwa configmap Anda memiliki nama yang benar:
- Jika Anda membuat Sumber Daya Kustom, Anda seharusnya melihat kesalahan validasi selama pembuatan monitor pod/layanan. Jika Anda masih tidak melihat metrik dari target, pastikan bahwa log tidak menunjukkan kesalahan.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Verifikasi bahwa tidak ada kesalahan
MetricsExtensionterkait autentikasi dengan ruang kerja Azure Monitor. - Verifikasi bahwa tidak ada kesalahan dari
OpenTelemetry collectortentang mengikis target.
Jalankan perintah berikut:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- Perintah ini menunjukkan kesalahan jika ada masalah dengan mengautentikasi dengan ruang kerja Azure Monitor. Contoh di bawah ini menunjukkan log tanpa masalah:
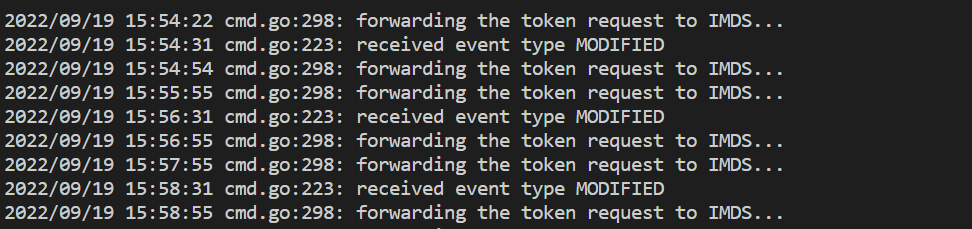

Jika tidak ada kesalahan dalam log, antarmuka Prometheus dapat digunakan untuk penelusuran kesalahan untuk memverifikasi konfigurasi dan target yang diharapkan diekstraksi.
Antarmuka Prometheus
Setiap ama-metrics-* pod memiliki Antarmuka Pengguna mode Agen Prometheus yang tersedia pada port 9090.
Konfigurasi kustom dan target Sumber Daya Kustom diekstraksi oleh ama-metrics-* pod dan target simpul oleh ama-metrics-node-* pod.
Port-forward ke dalam pod replika atau salah satu pod set daemon untuk memeriksa konfigurasi, penemuan layanan, dan menargetkan titik akhir seperti yang dijelaskan di sini untuk memverifikasi konfigurasi kustom sudah benar, target yang dimaksudkan telah ditemukan untuk setiap pekerjaan, dan tidak ada kesalahan dengan mengikis target tertentu.
Jalankan perintah kubectl port-forward <ama-metrics pod> -n kube-system 9090.
Buka browser ke alamat
127.0.0.1:9090/config. Antarmuka pengguna ini memiliki konfigurasi scrape penuh. Verifikasi bahwa semua pekerjaan disertakan dalam konfigurasi.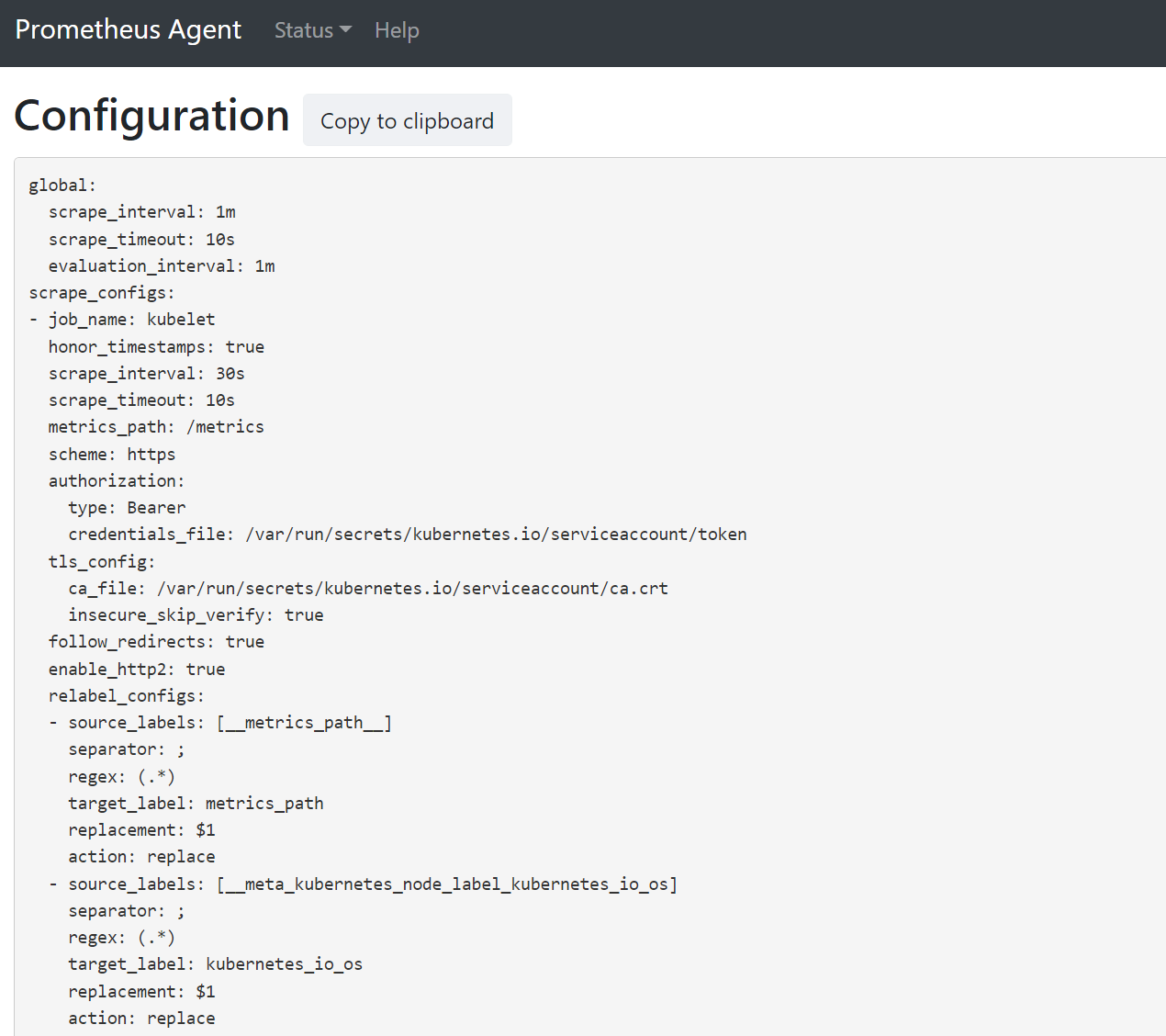
127.0.0.1:9090/service-discoveryBuka untuk melihat target yang ditemukan oleh objek penemuan layanan yang ditentukan dan apa yang telah relabel_configs filter targetnya. Misalnya, ketika metrik yang hilang dari pod tertentu, Anda dapat menemukan apakah pod tersebut ditemukan dan apa URI-nya. Anda kemudian dapat menggunakan URI ini saat melihat target untuk melihat apakah ada kesalahan scrape.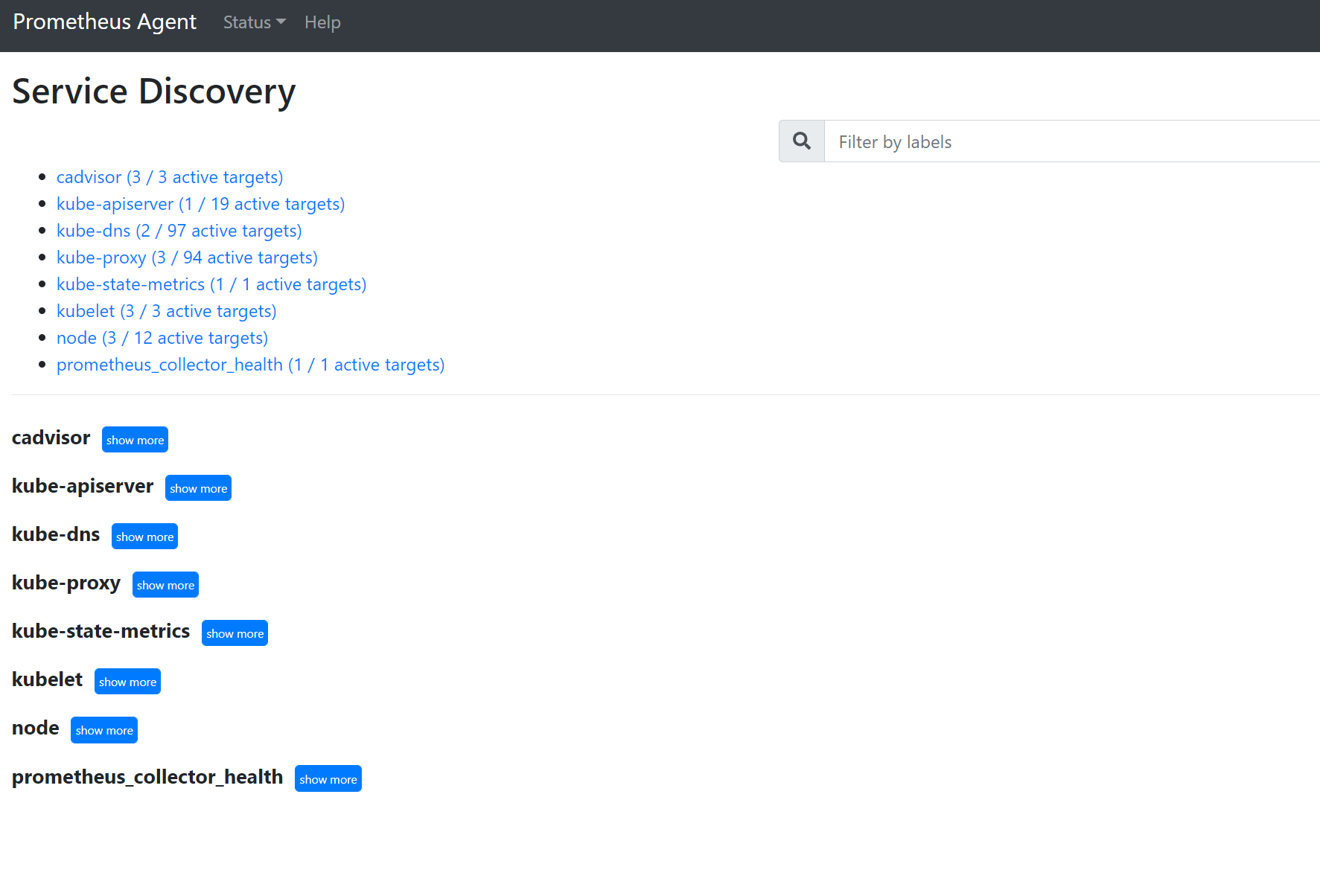
Buka untuk
127.0.0.1:9090/targetsmelihat semua pekerjaan, terakhir kali titik akhir untuk pekerjaan tersebut diekstraksi, dan kesalahan apa pun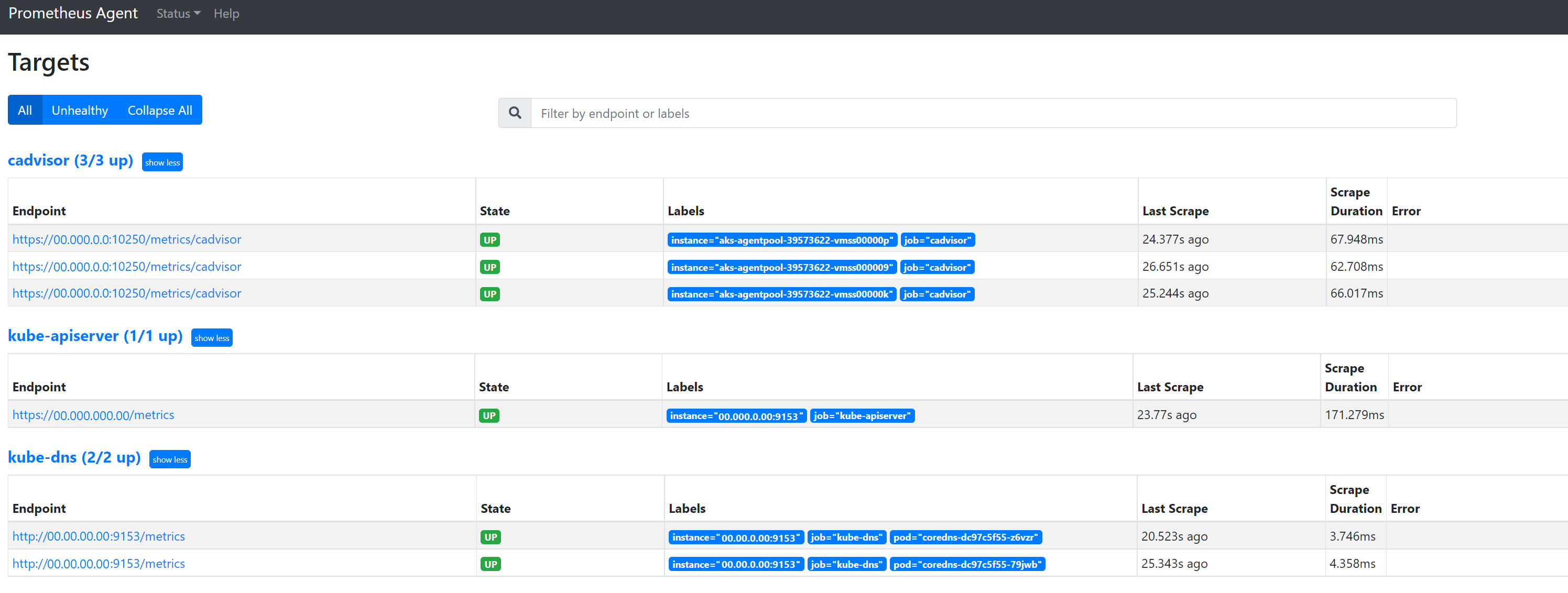



Sumber Daya Kustom
- Jika Anda menyertakan Sumber Daya Kustom, pastikan sumber daya tersebut muncul di bawah konfigurasi, penemuan layanan, dan target.
Konfigurasi

Penemuan Layanan

Target

Jika tidak ada masalah dan target yang dimaksudkan sedang diekstraksi, Anda dapat melihat metrik yang tepat sedang diekstraksi dengan mengaktifkan mode debug.
Mode debug
Peringatan
Mode ini dapat memengaruhi performa dan hanya boleh diaktifkan untuk waktu yang singkat untuk tujuan penelusuran kesalahan.
Addon metrik dapat dikonfigurasi untuk dijalankan dalam mode debug dengan mengubah pengaturan enabled configmap di bawah debug-mode ke true dengan mengikuti instruksi di sini.
Saat diaktifkan, semua metrik Prometheus yang digoreskan dihosting di port 9091. Jalankan perintah berikut:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
127.0.0.1:9091/metrics Buka di browser untuk melihat apakah metrik diekstraksi oleh Pengumpul OpenTelemetry. Antarmuka pengguna ini dapat diakses untuk setiap ama-metrics-* pod. Jika metrik tidak ada, mungkin ada masalah dengan metrik atau panjang nama label atau jumlah label. Periksa juga untuk melebihi kuota penyerapan untuk metrik Prometheus seperti yang ditentukan dalam artikel ini.
Nama metrik, nama label & nilai label
Pengikisan metrik saat ini memiliki batasan dalam tabel berikut:
| Properti | Batas |
|---|---|
| Panjang nama label | Kurang dari atau sama dengan 511 karakter. Ketika batas ini terlampaui untuk setiap rangkaian waktu dalam pekerjaan, seluruh pekerjaan scrape gagal, dan metrik dihilangkan dari pekerjaan tersebut sebelum penyerapan. Anda dapat melihat up=0 untuk pekerjaan tersebut dan juga menargetkan Ux menunjukkan alasan untuk up=0. |
| Panjang nilai label | Kurang dari atau sama dengan 1023 karakter. Ketika batas ini terlampaui untuk setiap rangkaian waktu dalam pekerjaan, seluruh scrape gagal, dan metrik dihilangkan dari pekerjaan tersebut sebelum penyerapan. Anda dapat melihat up=0 untuk pekerjaan tersebut dan juga menargetkan Ux menunjukkan alasan untuk up=0. |
| Jumlah label per rangkaian waktu | Kurang dari atau sama dengan 63. Ketika batas ini terlampaui untuk setiap rangkaian waktu dalam pekerjaan, seluruh pekerjaan scrape gagal, dan metrik dihilangkan dari pekerjaan tersebut sebelum penyerapan. Anda dapat melihat up=0 untuk pekerjaan tersebut dan juga menargetkan Ux menunjukkan alasan untuk up=0. |
| Panjang nama metrik | Kurang dari atau sama dengan 511 karakter. Ketika batas ini terlampaui untuk setiap rangkaian waktu dalam pekerjaan, hanya seri tertentu yang dihilangkan. MetricextensionConsoleDebugLog memiliki jejak untuk metrik yang dihilangkan. |
| Nama label dengan casing yang berbeda | Dua label dalam sampel metrik yang sama, dengan casing yang berbeda diperlakukan sebagai memiliki label duplikat dan dihilangkan saat diserap. Misalnya, rangkaian my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} waktu dihilangkan karena label duplikat karena ExampleLabel dan examplelabel dilihat sebagai nama label yang sama. |
Periksa kuota penyerapan di ruang kerja Azure Monitor
Jika metrik terlewatkan, Anda dapat terlebih dahulu memeriksa apakah batas penyerapan terlampaui untuk ruang kerja Azure Monitor Anda. Di portal Azure, Anda dapat memeriksa penggunaan saat ini untuk Ruang Kerja monitor Azure apa pun. Anda dapat melihat metrik penggunaan saat ini di bawah Metrics menu untuk ruang kerja Azure Monitor. Metrik pemanfaatan berikut tersedia sebagai metrik standar untuk setiap ruang kerja Azure Monitor.
- Rangkaian Waktu Aktif - Jumlah rangkaian waktu unik yang baru-baru ini diserap ke ruang kerja selama 12 jam sebelumnya
- Batas Rangkaian Waktu Aktif - Batas jumlah rangkaian waktu unik yang dapat diserap secara aktif ke dalam ruang kerja
- Pemanfaatan % Seri Waktu Aktif - Persentase rangkaian waktu aktif saat ini yang digunakan
- Peristiwa Per Menit Diserap - Jumlah peristiwa (sampel) per menit yang baru saja diterima
- Batas Penyerapan Peristiwa Per Menit - Jumlah maksimum peristiwa per menit yang dapat diserap sebelum dibatasi
- Peristiwa Per Menit Terserap % Pemanfaatan - Persentase batas laju penyerapan metrik saat ini sedang util
Untuk menghindari pembatasan penyerapan metrik, Anda dapat memantau dan menyiapkan pemberitahuan tentang batas penyerapan. Lihat Memantau batas penyerapan.
Lihat kuota dan batas layanan untuk kuota default dan juga untuk memahami apa yang dapat ditingkatkan berdasarkan penggunaan Anda. Anda dapat meminta penambahan kuota untuk ruang kerja Azure Monitor menggunakan Support Request menu untuk ruang kerja Azure Monitor. Pastikan Anda menyertakan ID, ID internal, dan Lokasi/Wilayah untuk ruang kerja Azure Monitor dalam permintaan dukungan, yang dapat Anda temukan di menu 'Properti' untuk ruang kerja Azure Monitor di portal Azure.
Pembuatan Ruang Kerja Azure Monitor gagal karena evaluasi Azure Policy
Jika pembuatan Ruang Kerja Azure Monitor gagal dengan kesalahan yang mengatakan "Sumber Daya 'resource-name-xyz' tidak diizinkan oleh kebijakan", mungkin ada kebijakan Azure yang mencegah sumber daya dibuat. Jika ada kebijakan yang memberlakukan konvensi penamaan untuk sumber daya Azure atau grup sumber daya, Anda harus membuat pengecualian untuk konvensi penamaan untuk pembuatan Ruang Kerja Azure Monitor.
Saat Anda membuat ruang kerja Azure Monitor, secara default aturan pengumpulan data dan titik akhir pengumpulan data dalam bentuk "azure-monitor-workspace-name" akan secara otomatis dibuat dalam grup sumber daya dalam formulir "MA_azure-monitor-workspace-name_location_managed". Saat ini tidak ada cara untuk mengubah nama sumber daya ini, dan Anda harus menetapkan pengecualian pada Azure Policy untuk mengecualikan sumber daya di atas dari evaluasi kebijakan. Lihat Struktur pengecualian Azure Policy.