Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk:![]() Azure SQL Database
Azure SQL Database![]() SQL database dalam Fabric
SQL database dalam Fabric
- Azure SQL Database
SQL Server & Azure SQL Managed Instance
Artikel ini memberikan gambaran umum tentang penggunaan opsi kecerdasan buatan (AI), seperti OpenAI dan vektor, untuk membangun aplikasi cerdas dengan SQL Database Engine di Azure SQL Database dan Fabric database SQL.
Tonton video ini dalam seri Azure SQL Database essentials untuk ringkasan singkat tentang membangun aplikasi siap AI:
Untuk sampel dan contoh, kunjungi repositori Sampel SQL AI.
Gambaran Umum
Model bahasa besar (LLM) memungkinkan pengembang untuk membuat aplikasi yang didukung AI dengan pengalaman pengguna yang familier.
Menggunakan LLM dalam aplikasi membawa nilai yang lebih besar dan pengalaman pengguna yang ditingkatkan ketika model dapat mengakses data yang tepat, pada waktu yang tepat, dari database aplikasi Anda. Proses ini dikenal sebagai Generasi Augmentasi Pengambilan (RAG). Azure SQL Database dan Fabric database SQL memiliki banyak fitur yang mendukung pola baru ini, menjadikannya database yang bagus untuk membangun aplikasi cerdas.
Tautan berikut menyediakan kode sampel dari berbagai opsi untuk membangun aplikasi cerdas:
| Opsi AI | Deskripsi |
|---|---|
| SQL MCP Server | Antarmuka yang stabil dan diatur untuk database Anda, menentukan serangkaian alat dan konfigurasi. |
| Azure OpenAI | Hasilkan embedding untuk RAG dan mengintegrasikan dengan model apa pun yang didukung oleh Azure OpenAI. |
| Vektor | Pelajari cara menyimpan vektor dan menggunakan fungsi vektor dalam database. |
| Azure AI Search | Gunakan database Anda bersama Azure AI Search untuk melatih LLM pada data Anda. |
| Aplikasi cerdas | Pelajari cara membuat solusi end-to-end menggunakan pola umum yang dapat direplikasi dalam skenario apa pun. |
| Keterampilan Copilot pada Azure SQL Database | Pelajari tentang serangkaian pengalaman yang dibantu AI yang dirancang untuk menyederhanakan desain, operasi, pengoptimalan, dan kesehatan aplikasi berbasis Azure SQL Database. |
| Copilot keterampilan dalam Fabric database SQL | Pelajari tentang serangkaian pengalaman yang dibantu AI yang dirancang untuk menyederhanakan desain, operasi, pengoptimalan, dan kesehatan aplikasi berbasis database SQL Fabric. |
SQL MCP Server dalam aplikasi AI
SQL MCP Server berada langsung di jalur data untuk agen AI.
- Saat model menghasilkan permintaan, server menyediakan antarmuka yang stabil dan diatur ke database Anda.
- Alih-alih mengekspos skema mentah atau mengandalkan SQL yang dihasilkan, SQL merutekan semua akses melalui serangkaian alat yang ditentukan yang didukung oleh konfigurasi Anda.
Pendekatan ini membuat interaksi tetap dapat diprediksi dan memastikan setiap operasi selaras dengan izin dan struktur yang Anda tentukan. Untuk informasi selengkapnya, lihat aka.ms/sql/mcp.
Dengan memisahkan penalaran dari eksekusi, model berfokus pada niat sementara SQL MCP Server menangani bagaimana niat tersebut menjadi kueri yang valid. Area permukaan tetap dibatasi karena agen dapat menemukan kemampuan yang tersedia, memahami input dan output, dan beroperasi tanpa menebak. Desain ini mengurangi kesalahan dan menghilangkan kebutuhan akan rekayasa prompt yang kompleks untuk mengkompensasi ambiguitas skema.
Bagi pengembang, pendekatan ini berarti AI dapat dengan aman berpartisipasi dalam beban kerja nyata.
Kamu bisa:
- Definisikan entitas satu kali
- Menerapkan peran dan batasan
Platform selanjutnya:
- Memberlakukan entitas, peran, dan batasan secara konsisten
- Membuat fondasi yang andal untuk aplikasi berbasis agen melalui data SQL.
Konfigurasi yang sama yang mendukung REST dan GraphQL juga mengatur MCP, sehingga tidak ada duplikasi aturan atau logika. Untuk informasi selengkapnya, lihat aka.ms/dab/docs.
Konsep utama untuk menerapkan RAG dengan Azure OpenAI
Bagian ini mencakup konsep utama yang penting untuk menerapkan RAG dengan Azure OpenAI dalam database SQL Azure SQL Database atau Fabric.
Generasi Augmentasi Pengambilan (RAG)
RAG adalah teknik yang meningkatkan kemampuan LLM untuk menghasilkan respons yang relevan dan informatif dengan mengambil data tambahan dari sumber eksternal. Misalnya, RAG dapat mengkueri artikel atau dokumen yang berisi pengetahuan khusus domain yang terkait dengan pertanyaan atau permintaan pengguna. LLM kemudian dapat menggunakan data yang diambil ini sebagai referensi saat menghasilkan responsnya. Misalnya, pola RAG sederhana menggunakan Azure SQL Database dapat berupa:
- Sisipkan data ke dalam tabel.
- Tautkan Azure SQL Database ke Azure AI Search.
- Buat Azure model OpenAI GPT-4 dan sambungkan ke Azure AI Search.
- Berinteraksi dan mengajukan pertanyaan tentang data Anda dengan menggunakan model Azure OpenAI yang terlatih dari aplikasi Anda dan dari Azure SQL Database.
Pola RAG, bersama dengan rekayasa petunjuk, meningkatkan kualitas respons dengan menyajikan informasi yang lebih kontekstual kepada model. RAG memungkinkan model untuk menerapkan basis pengetahuan yang lebih luas dengan menggabungkan sumber eksternal yang relevan ke dalam proses pembuatan, menghasilkan respons yang lebih komprehensif dan terinformasi. Untuk informasi selengkapnya tentang LLM grounding, lihat LLM Grounding - Microsoft Community Hub.
Penggunaan prompt dan rekayasa prompt
Prompt adalah teks atau informasi spesifik yang berfungsi sebagai instruksi untuk model bahasa besar (LLM), atau sebagai data kontekstual yang dapat digunakan LLM untuk membangun lebih lanjut. Sebuah prompt dapat mengambil berbagai bentuk, seperti pertanyaan, pernyataan, atau bahkan cuplikan kode.
Contoh perintah yang dapat Anda gunakan untuk menghasilkan respons dari LLM meliputi:
- Instruksi: memberikan arahan kepada LLM
- Konten utama: memberikan informasi kepada LLM untuk diproses
- Contoh: membantu mengkondisikan model ke tugas atau proses tertentu
- Petunjuk: arahkan output LLM ke arah yang benar
- Konten pendukung: mewakili informasi tambahan yang dapat digunakan LLM untuk menghasilkan output
Proses menghasilkan prompt yang baik untuk skenario disebut rekayasa prompt. Untuk informasi selengkapnya tentang perintah dan praktik terbaik untuk rekayasa cepat, lihat Azure OpenAI Service.
Token
Token adalah potongan kecil teks yang dihasilkan dengan memisahkan teks input menjadi segmen yang lebih kecil. Segmen-segmen ini dapat berupa kata atau grup karakter, bervariasi panjangnya dari satu karakter ke seluruh kata. Misalnya, kata hamburger dibagi menjadi token seperti ham, , burdan ger sementara kata pendek dan umum seperti pear dianggap sebagai token tunggal.
Di Azure OpenAI, API mentokenisasi teks input. Jumlah token yang diproses di setiap permintaan API tergantung pada faktor-faktor seperti panjang parameter input, output, dan permintaan. Kuantitas token yang sedang diproses juga berdampak pada waktu respons dan throughput model. Setiap model memiliki batasan jumlah token yang dapat diambil dalam satu permintaan dan respons dari Azure OpenAI. Untuk mempelajari selengkapnya, lihat kuota dan batas Azure OpenAI Service.
Vektor
Vektor adalah array angka yang diurutkan (biasanya float) yang dapat mewakili informasi tentang beberapa data. Misalnya, gambar dapat direpresentasikan sebagai vektor nilai piksel, atau string teks dapat direpresentasikan sebagai vektor nilai ASCII. Proses untuk mengubah data menjadi vektor disebut vektorisasi. Untuk informasi selengkapnya, lihat Contoh vektor.
Bekerja dengan data vektor lebih mudah dengan pengenalan jenis data vektor dan fungsi vektor.
Penyematan
Pembenaman adalah vektor yang mewakili fitur-fitur penting dari data. Penyematan sering dipelajari dengan menggunakan model pembelajaran mendalam, dan pembelajaran mesin dan model AI menggunakannya sebagai fitur. Penyematan juga dapat menangkap kesamaan semantik antara konsep serupa. Misalnya, saat menghasilkan penyematan untuk kata-kata person dan human, Anda dapat mengharapkan penyematannya (representasi vektor) serupa dalam nilai karena kata-kata juga serupa secara semantik.
Azure OpenAI menampilkan model untuk membuat penyematan dari data teks. Layanan ini memecah teks menjadi token dan menghasilkan penyematan dengan menggunakan model yang telah dilatih sebelumnya oleh OpenAI. Untuk mempelajari lebih lanjut, lihat Membuat embeddings dengan Azure OpenAI.
Untuk daftar jawaban atas pertanyaan umum tentang vektor dan penyematan, lihat:
Pencarian vektor
Pencarian vektor adalah proses menemukan semua vektor dalam himpunan data yang secara semantik mirip dengan vektor kueri tertentu. Oleh karena itu, vektor kueri untuk kata human mencari seluruh kamus untuk kata yang mirip secara semantik, dan harus menemukan kata person sebagai kecocokan dekat. Metrik kesamaan seperti kesamaan kosinus mengukur kedekatan ini, atau jarak. Vektor yang lebih dekat memiliki kesamaan, semakin kecil jarak di antara mereka.
Pertimbangkan skenario di mana Anda menjalankan kueri lebih dari jutaan dokumen untuk menemukan dokumen yang paling mirip dalam data Anda. Anda dapat membuat embedding untuk data dan dokumen pencarian Anda dengan menggunakan Azure OpenAI. Kemudian, Anda dapat melakukan pencarian vektor untuk menemukan dokumen yang paling mirip dari himpunan data Anda. Namun, melakukan pencarian vektor di beberapa contoh adalah hal sepele. Melakukan pencarian yang sama ini di ribuan, atau jutaan, titik data menjadi suatu tantangan. Ada juga trade-off antara metode pencarian lengkap dan perkiraan metode pencarian tetangga terdekat (ANN), termasuk latensi, throughput, akurasi, dan biaya. Semua trade-off ini tergantung pada persyaratan aplikasi Anda.
Anda dapat menyimpan dan meminta vektor secara efisien di Azure SQL Database, yang memungkinkan pencarian tetangga terdekat yang tepat dengan performa yang hebat. Anda tidak perlu memutuskan antara akurasi dan kecepatan: Anda dapat memiliki keduanya. Menyimpan penyematan vektor bersama data dalam solusi terintegrasi meminimalkan kebutuhan untuk mengelola sinkronisasi data dan mempercepat waktu ke pasar Anda untuk pengembangan aplikasi AI.
Untuk detail selengkapnya tentang vektor dan penyematan, lihat:
Azure OpenAI
Penyematan adalah proses mewakili dunia nyata sebagai data. Anda dapat mengonversi teks, gambar, atau suara menjadi penyematan. Model Azure OpenAI dapat mengubah informasi dunia nyata menjadi embedding. Anda dapat mengakses model sebagai titik akhir REST, sehingga Anda dapat dengan mudah menggunakannya dari Azure SQL Database dengan menggunakan prosedur tersimpan sistem sp_invoke_external_rest_endpoint:
DECLARE @retval INT, @response NVARCHAR(MAX);
DECLARE @payload NVARCHAR(MAX);
SET @payload = JSON_OBJECT('input': @text);
EXEC @retval = sp_invoke_external_rest_endpoint @url = 'https://<openai-url>/openai/deployments/<model-name>/embeddings?api-version=2023-03-15-preview',
@method = 'POST',
@credential = [https://<openai-url>/openai/deployments/<model-name>],
@payload = @payload,
@response = @response OUTPUT;
SELECT CAST([key] AS INT) AS [vector_value_id],
CAST([value] AS FLOAT) AS [vector_value]
FROM OPENJSON(JSON_QUERY(@response, '$.result.data[0].embedding'));
Menggunakan panggilan ke layanan REST untuk mendapatkan embedding hanyalah salah satu opsi integrasi yang Anda miliki saat bekerja dengan SQL Database dan OpenAI. Anda dapat membiarkan salah satu model available mengakses data yang disimpan dalam Azure SQL Database untuk membuat solusi di mana pengguna Anda dapat berinteraksi dengan data, seperti contoh berikut.
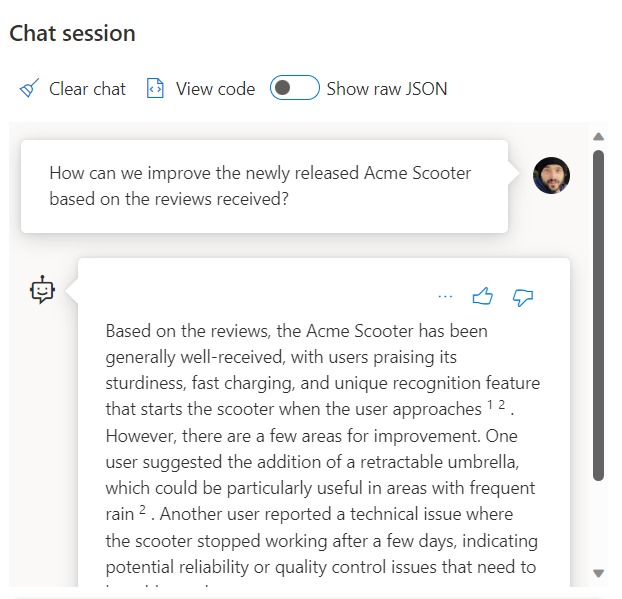
Untuk contoh tambahan tentang menggunakan SQL Database dan OpenAI, lihat artikel berikut ini:
- Buat gambar dengan Azure OpenAI Service (DALL-E) dan Azure SQL Database
- Gunakan Titik Akhir REST OpenAI dengan Azure SQL Database
Contoh vektor
Jenis data vektor khusus memungkinkan penyimpanan data vektor yang efisien dan dioptimalkan. Muncul dengan serangkaian fungsi untuk membantu pengembang merampingkan implementasi pencarian vektor dan kesamaan. Anda dapat menghitung jarak antara dua vektor dalam satu baris kode dengan menggunakan VECTOR_DISTANCE fungsi . Untuk informasi dan contoh selengkapnya, lihat indeks pencarian dan vektor Vector di SQL Database Engine.
Contohnya:
CREATE TABLE [dbo].[wikipedia_articles_embeddings_titles_vector]
(
[article_id] [int] NOT NULL,
[embedding] [vector](1536) NOT NULL,
)
GO
SELECT TOP(10)
*
FROM
[dbo].[wikipedia_articles_embeddings_titles_vector]
ORDER BY
VECTOR_DISTANCE('cosine', @my_reference_vector, embedding)
Pencarian Azure AI
Terapkan pola RAG dengan Azure SQL Database dan Azure AI Search. Anda dapat menjalankan model obrolan yang didukung pada data yang disimpan di Azure SQL Database, tanpa harus melatih atau menyempurnakan model, berkat integrasi Azure AI Search dengan Azure OpenAI dan Azure SQL Database. Dengan menjalankan model pada data Anda, Anda dapat berinteraksi melalui percakapan dan menganalisis data Anda dengan akurasi dan kecepatan yang lebih tinggi.
- Azure OpenAI pada data Anda
- Retrieval Augmented Generation (RAG) dalam Azure AI Search
- Vector Search dengan Azure SQL Database dan Azure AI Search
Aplikasi cerdas
Anda dapat menggunakan Azure SQL Database untuk membangun aplikasi cerdas yang menyertakan fitur AI, seperti pemberi rekomendasi dan Retrieval Augmented Generation (RAG), seperti yang ditunjukkan oleh diagram berikut:

Untuk contoh lengkap dari akhir ke akhir dalam membangun aplikasi yang didukung oleh AI menggunakan abstrak sesi sebagai kumpulan data sampel, lihat:
- Bagaimana saya membangun pemberi rekomendasi sesi dalam 1 jam menggunakan OpenAI.
- Menggunakan Retrieval Augmented Generation untuk membangun asisten sesi konferensi.
Untuk detail selengkapnya tentang aplikasi cerdas, lihat:
Integrasi LangChain
LangChain adalah kerangka kerja terkenal untuk mengembangkan aplikasi yang didukung oleh model bahasa. Untuk contoh yang menunjukkan bagaimana LangChain dapat digunakan untuk membuat chatbot pada data Anda sendiri, lihat:
- langchain-sqlserver Paket PyPI
Beberapa sampel tentang menggunakan Azure SQL dengan LangChain:
Beberapa contoh ujung-ke-ujung:
- Bangun chatbot pada data Anda sendiri dalam 1 jam dengan Azure SQL, Langchain, dan Chainlit: Bangun chatbot menggunakan pola RAG pada data Anda sendiri dengan menggunakan Langchain untuk mengorkestrasi panggilan LLM dan Chainlit untuk antarmuka pengguna.
integrasi Semantic Kernel
Semantic Kernel adalah SDK sumber terbuka yang dapat Anda gunakan untuk membangun agen yang memanggil kode yang ada dengan mudah. Sebagai SDK yang sangat luas, Anda dapat menggunakan Semantic Kernel dengan model dari OpenAI, Azure OpenAI, Hugging Face, dan banyak lagi. Dengan menggabungkan kode C#, Python, dan Java yang ada dengan model ini, Anda dapat membangun agen yang menjawab pertanyaan dan mengotomatiskan proses.
Contoh yang menunjukkan seberapa mudah Semantic Kernel membantu Anda membangun solusi yang mendukung AI ada di sini:
- Chatbot utama?: Bangun chatbot pada data Anda sendiri menggunakan pola NL2SQL dan RAG untuk pengalaman pengguna utama.
Microsoft Copilot kemampuan dalam Azure SQL Database
Microsoft Copilot dalam Azure SQL Database (pratinjau) adalah serangkaian pengalaman yang dibantu AI yang dirancang untuk menyederhanakan desain, operasi, pengoptimalan, dan kesehatan aplikasi berbasis Azure SQL Database.
Copilot memberikan jawaban yang relevan untuk pertanyaan pengguna, menyederhanakan manajemen database dengan menggunakan konteks database, dokumentasi, tampilan manajemen dinamis, Query Store, dan sumber pengetahuan lainnya. Contohnya:
- Administrator database dapat mengelola database secara independen dan mengatasi masalah, atau mempelajari selengkapnya tentang performa dan kemampuan database Anda.
- Pengembang dapat mengajukan pertanyaan tentang data mereka seperti yang mereka lakukan dalam teks atau percakapan untuk menghasilkan kueri T-SQL. Pengembang juga dapat belajar menulis kueri lebih cepat melalui penjelasan terperinci tentang kueri yang dihasilkan.
Catatan
Kemampuan Microsoft Copilot dalam layanan Azure SQL Database saat ini dalam pratinjau untuk pengadopsi awal yang terbatas. Untuk mendaftar program ini, kunjungi Meminta Akses ke Copilot di Azure SQL Database: Versi Pratinjau.
Microsoft Copilot dalam database SQL Fabric (pratinjau)
Copilot untuk database SQL di Microsoft Fabric menyertakan bantuan AI terintegrasi dengan fitur-fitur berikut:
Penyelesaian Kode: Mulai menulis T-SQL di editor kueri SQL, dan Copilot secara otomatis memberikan saran kode untuk membantu menyelesaikan kueri Anda. Tekan Tab untuk menerima saran kode atau terus mengetik untuk mengabaikannya.
Tindakan cepat: Di pita editor kueri SQL, opsi Perbaiki dan Jelaskan adalah tindakan cepat. Sorot kueri SQL dan pilih salah satu tombol tindakan cepat untuk melakukan tindakan yang dipilih pada kueri Anda.
Fix: Copilot memperbaiki kesalahan dalam kode Anda saat pesan kesalahan muncul. Skenario kesalahan dapat mencakup kode T-SQL yang salah atau tidak didukung, ejaan yang salah, dan banyak lagi. Copilot juga memberikan komentar yang menjelaskan perubahan dan menyarankan praktik terbaik SQL.
Explain: Copilot memberikan penjelasan bahasa alami tentang kueri SQL dan skema database Anda dalam format komentar.
panel Chat: Gunakan panel obrolan untuk mengajukan pertanyaan kepada Copilot melalui bahasa alami. Copilot merespons dengan kueri SQL yang dihasilkan atau bahasa alami berdasarkan pertanyaan yang diajukan.
Bahasa Alami ke SQL: Hasilkan kode T-SQL dari permintaan teks biasa, dan dapatkan saran pertanyaan untuk diajukan untuk mempercepat alur kerja Anda.
Tanya Jawab Berbasis Dokumen: Ajukan pertanyaan kepada Copilot tentang kemampuan umum database SQL, dan ia akan merespons dalam bahasa alami. Copilot juga membantu menemukan dokumentasi yang terkait dengan permintaan Anda.
Copilot untuk database SQL menggunakan nama tabel dan tampilan, nama kolom, kunci primer, dan metadata kunci asing untuk menghasilkan kode T-SQL. Copilot untuk database SQL tidak menggunakan data dalam tabel untuk menghasilkan saran T-SQL.
Konten terkait
- Buat dan sebarkan sumber daya Azure OpenAI Service
- Model penyematan
- Sampel dan Contoh SQL AI
- Pertanyaan yang Sering Diajukan tentang keterampilan Microsoft Copilot dalam Azure SQL Database (pratinjau)
- FAQ AI Bertanggung Jawab untuk Microsoft Copilot di Azure (pratinjau)